Spring Boot-甜蜜的整合MyBatis&注解方式&配置方式
建军节快乐各位~
个人博客:aaatao66.github.io/
掘金: juejin.im/user/5d1873…
优先更新个人博客, 其次是掘金。
整合Mybtis对于Spring Boot来说,是非常简单的, 通过这一篇文章, 你可以无压力快速入门,不过开始之前我要说一下我的版本信息:
- maven 3.2.5
- jdk 1.8
- Spring Boot 2.1.6
创建项目
依然是使用idea的自动化配置, 不过这里,我们需要勾选以下依赖:
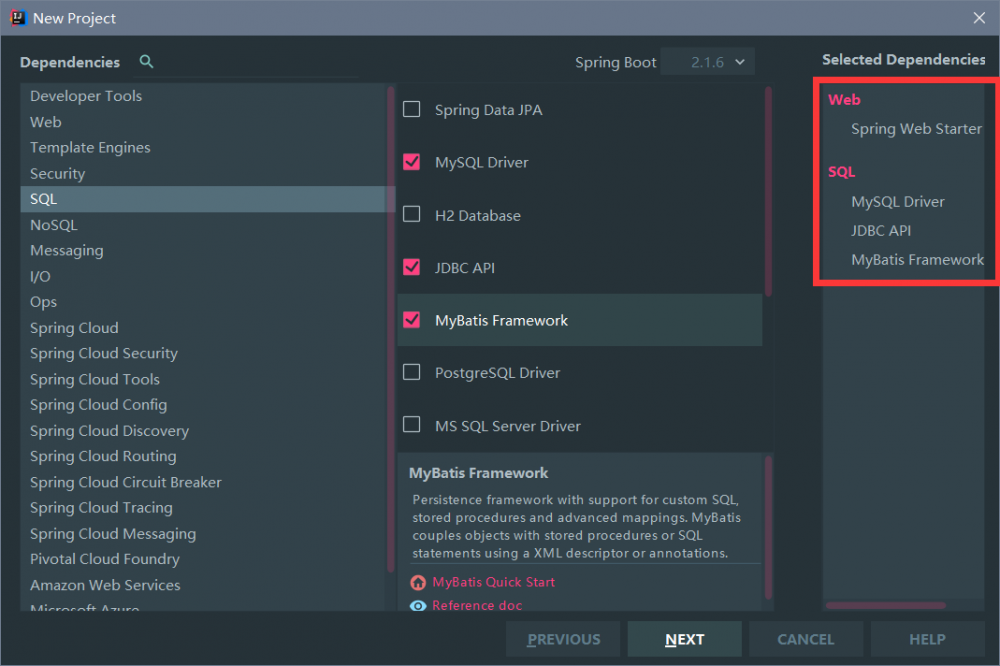
如果你勾选了 MyBatis , 你会发现你的pom文件里有 :
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
复制代码
这条依赖
只要是带 *-spring-boot-starter的,都是Spring Boot官方推荐的, 这里的mybatis就是, 让我们来看一下mybatis包下的所有包:
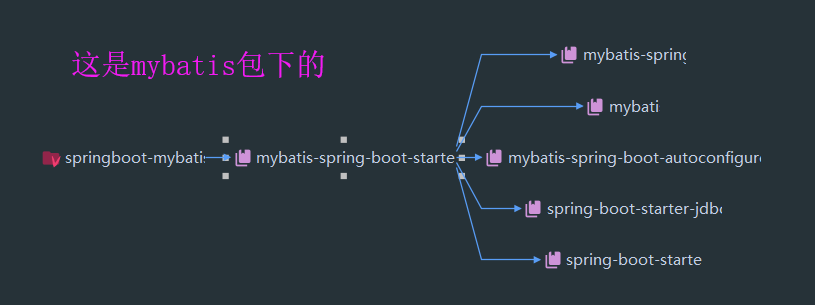
我们发现它引入了, mybatis-spring 的包等等,以及还有mybatis-spring-boot-autoconfigure, 这个是自动配置的意思, 对于Spring Boot来说,自动配置是一大特点
配置Druid数据源
Spring Boot2.x的数据源 hikari 的, 而1.x则是 Tomcat的, 所以我们要配置以下自己的数据源
我的上一篇文章介绍了Druid: aaatao66.github.io/2019/07/30/…
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
复制代码
引入这个依赖就好了
然后在 application.yml 配置文件下:
spring:
datasource:
password: root
username: root
url: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
复制代码
我在上一篇文章说过, 下面这一堆的属性是不生效的, 如果想要生效, 需要特殊配置一下, 并且我把上一章说的 Druid监控也配置了:
package com.carson.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid() {
return new DruidDataSource();
}
// 配置 Druid 监控
//1) 配置一个管理后台的Servlet
@Bean
public ServletRegistrationBean statViewServlet() {
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map<String, String> initParams = new HashMap<>();
// 这里是 druid monitor(监视器)的 账号密码, 可以任意设置
initParams.put("loginUsername", "admin");
initParams.put("loginPassword", "123456");
initParams.put("allow", "");
initParams.put("deny", "192.123.11.11");
// 设置初始化参数
bean.setInitParameters(initParams);
return bean;
}
// 2)配置一个监控的 filter
@Bean
public FilterRegistrationBean webStatFilter() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
复制代码
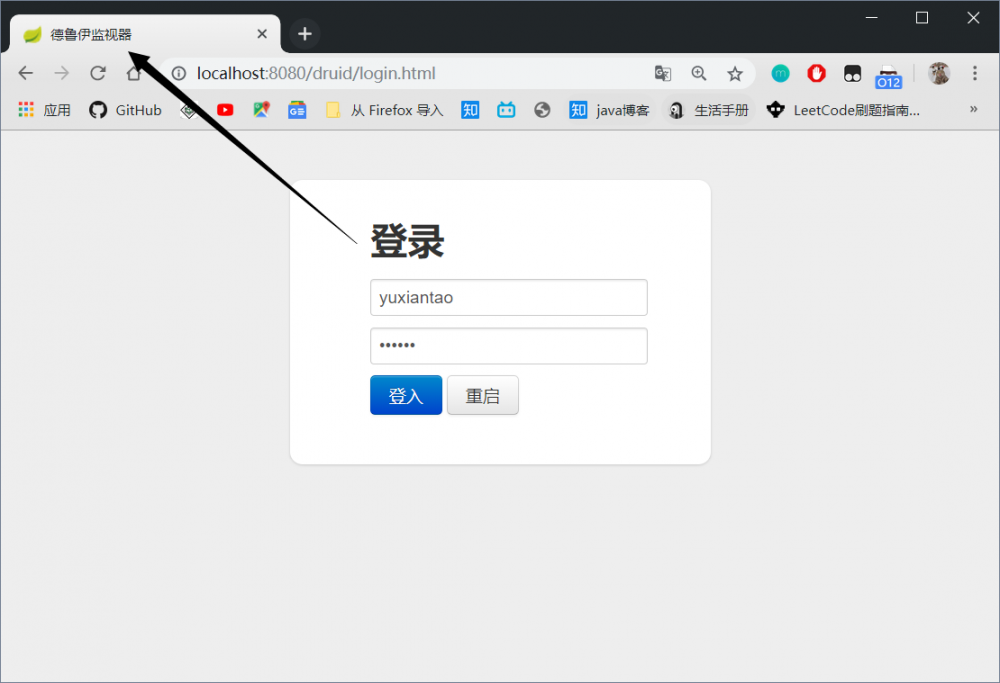
启动主类, 查看是否可以进入到 德鲁伊监视器 , 如果你报错了请添加 log4j 依赖:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!--我也不清楚为什么, 不加log4j的话就会报错-->
复制代码
查看效果:
利用SpringBoot建表
然后在 resources/sql 下引入两个建表的sql文件:
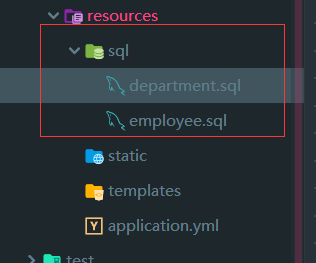
- department.sql :
SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for department -- ---------------------------- DROP TABLE IF EXISTS `department`; CREATE TABLE `department` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `departmentName` VARCHAR(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8; 复制代码
- employee.sql:
SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for employee -- ---------------------------- DROP TABLE IF EXISTS `employee`; CREATE TABLE `employee` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `lastName` VARCHAR(255) DEFAULT NULL, `email` VARCHAR(255) DEFAULT NULL, `gender` INT(2) DEFAULT NULL, `d_id` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8; 复制代码
并且在 application.yml 文件下写入:
schema:
- classpath:sql/department.sql
- classpath:sql/employee.sql
initialization-mode: always
复制代码
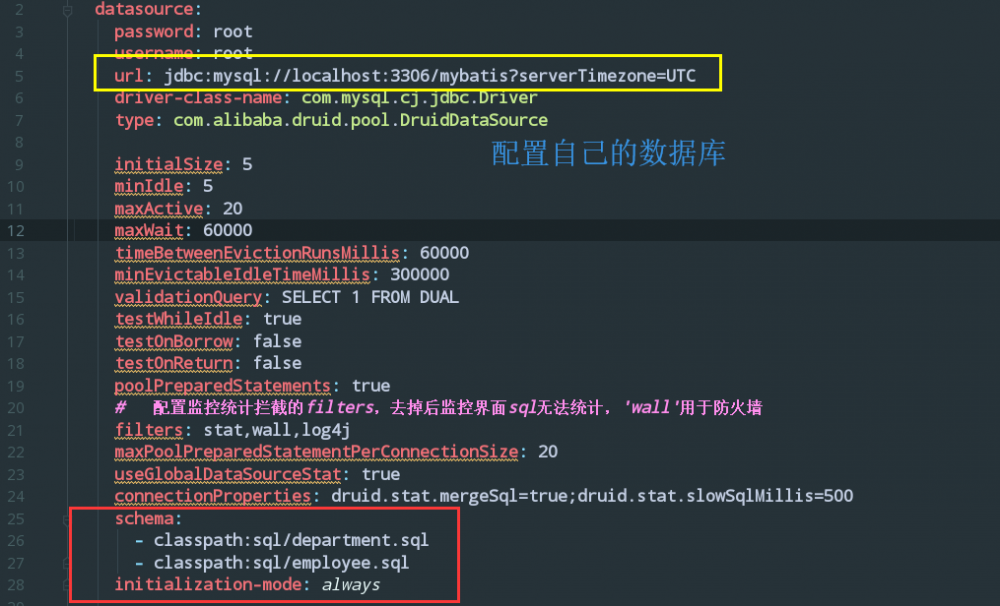
schema`是与 password/username 等等同级的, 如果你不懂yml文件与properties的区别, 那么你可以看我以前的文章: aaatao66.github.io/2019/06/30/…
哦对了, 如果你是 springboot 2.x版本以上的, 你可能需要加上 initialization-mode 这个属性。
运行主类, 查看是否建表成功, 我的数据库中已经生成了这两张表 ,这里我就不截图了
如果你的程序在设置sql文件后 启动报错了:
-
重启 idea (重启大法好啊!)
-
查看
schema是否配置对了 sql文件的名字 -
schema:
-(空格)classpath:sql/xxx.sql
注意格式
对应数据库实体类
- Employee.java
package com.carson.domain;
public class Employee {
private Integer id;
private String lastName;
private Integer gender;
private String email;
private Integer dId;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public Integer getGender() {
return gender;
}
public void setGender(Integer gender) {
this.gender = gender;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Integer getdId() {
return dId;
}
public void setdId(Integer dId) {
this.dId = dId;
}
}
复制代码
- Department.java
package com.carson.domain;
public class Department {
private Integer id;
private String departmentName;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getDepartmentName() {
return departmentName;
}
public void setDepartmentName(String departmentName) {
this.departmentName = departmentName;
}
}
复制代码
记得把刚才我配置文件的 schema 属性全部注释掉, 我们不希望下次运行的时候会再次创建表
数据库交互
- 注解版
- 建立一个 Mapper, 把sql语句直接写在上面
package com.carson.mapper;
import com.carson.domain.Department;
import org.apache.ibatis.annotations.*;
// 指定这是一个 mapper
@Mapper
public interface DepartmentMapper {
@Select("select * from department where id=#{id}")
public Department getDepById(Integer id);
@Delete("delete from department where id=#{id}")
public int deleteDepById(Integer id);
@Insert("insert into department(departmentName) values(#{departmentName})")
public int insertDept(Department department);
@Update("update department set departmentName=#{departmentName} where id=#{id}")
public int updateDept(Department department);
}
复制代码
然后写一个Controller :
package com.carson.controller;
import com.carson.domain.Department;
import com.carson.mapper.DepartmentMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController // 代表返回 json 数据的 controller
public class DeptController {
@Autowired
DepartmentMapper departmentMapper;
@GetMapping("/dept/{id}")
public Department getDept(@PathVariable("id") Integer id) {
return departmentMapper.getDepById(id);
}
@GetMapping
public Department inserDept(Department department) {
departmentMapper.insertDept(department);
return department;
}
}
复制代码
- 通过 @PathVariable 可以将 URL 中占位符参数绑定到控制器处理方法的入参中:URL 中的 { xxx } 占位符可以通过@PathVariable(“ xxx “) 绑定到操作方法的入参中。
启动主类, 输入这个: localhost:8080/dept?departmentName=AA , 这是往数据库增加一条数据:
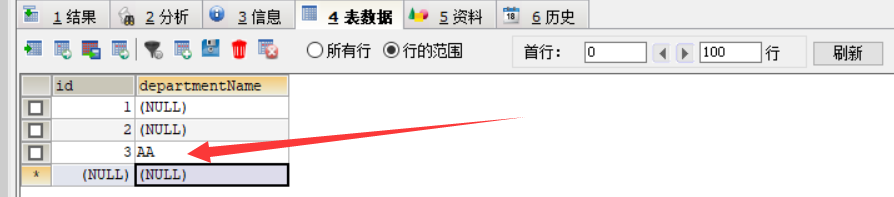
然后查询: localhost:8080/dept/3 , 我数据库id是3, 所以我要查询3:
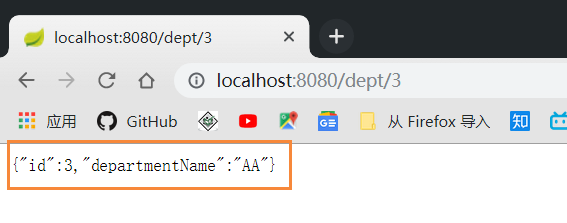
不过发现一个问题, 在插入数据的时候获取不到 id:
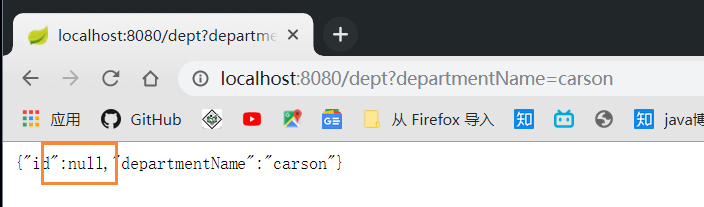
所以我们要使用一个 @Options 注解:
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into department(departmentName) values(#{departmentName})")
public int insertDept(Department department);
复制代码
添加到刚才 mapper中insert 的 @value 注解上面
-
useGeneratedKeys: 使用生成的主键 -
keyProperty: 意思是 Department 里面的哪个属性是主键, 就是我们的id
试着插入一条数据:
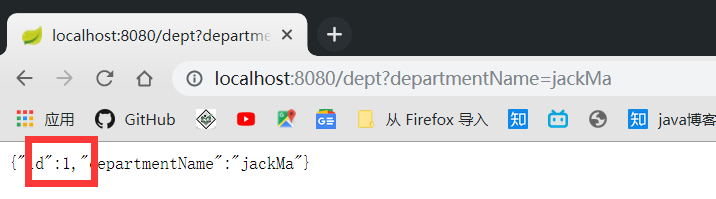
我之前在文章里写了,但是实际忘记注释掉 schema , 导致每次运行都会重新创建数据库, 各位要注意
还有一个问题
我们把数据库的字段名改成 department_name 而实体类是 departmentName ;
并且把sql语句也改正
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into department(department_name) values(#{departmentName})")
public int insertDept(Department department);
@Update("update department set department_name=#{departmentName} where id=#{id}")
public int updateDept(Department department);
复制代码
然后在进行查询操作的话:
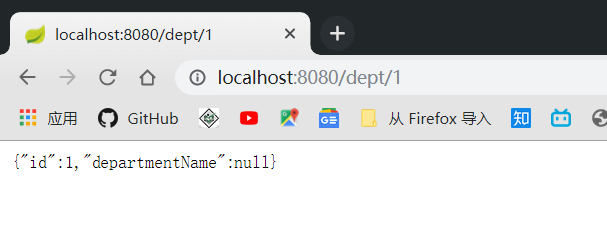
我们发现获取不到 departmentName 了, 以前Spring 我们是使用配置文件来应对这种情况的, 但是我们现在没有了xml文件,我们该怎么办呢?
世上无难事
创建自定义配置类:
package com.carson.config;
import org.mybatis.spring.boot.autoconfigure.ConfigurationCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MyBatisConfig {
@Bean
public ConfigurationCustomizer configurationCustomizer() {
return new ConfigurationCustomizer() {
@Override
public void customize(org.apache.ibatis.session.Configuration configuration) {
configuration.setMapUnderscoreToCamelCase(true);
}
};
}
}
复制代码
注意这里面的 setMapUnderscoreToCamelCase ,意思是:

翻译大法好啊, 我的英文太差了, 再次访问 http://localhost:8080/dept/1 查询操作, 我发现已经不是 null了:
{"id":1,"departmentName":"jackMa"}
复制代码
马总正确的展现出来了!
MapperScan 注解
扫描器, 用来扫描mapper接口的
我把它标记到 启动类 上(你可以标记在任何地方):
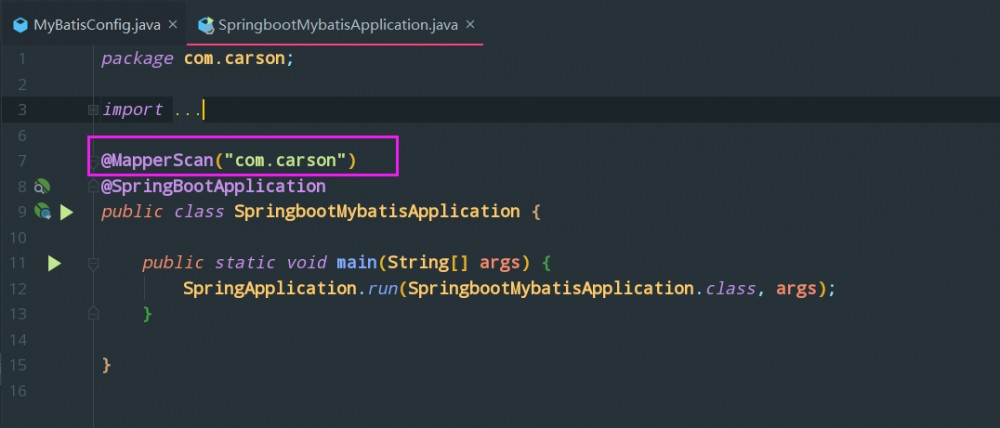
指定一个包,它会扫描这个包下所有的 mapper 接口, 防止你的mapper文件太多, 并且忘记加 @mapper 注解, 这样可以提高正确性
- 配置文件版
注解版貌似很方便, 但是如果遇到复杂的sql , 比如动态sql等等, 还是需要用 xml 配置文件的;
创建一个 Employee 的Mapper接口:
package com.carson.mapper;
import com.carson.domain.Employee;
public interface EmployeeMapper {
public Employee getEmpById(Integer id);
public void insertEmp(Employee employee);
}
复制代码
在 resources/mybatis 下创建一个 mybatis-config.xml 全局配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
</configuration>
复制代码
在 resources/mybatis/mapper 包下创建 EmployeeMapper.xml 映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 绑定接口 并且写两条 SQL 语句-->
<mapper namespace="com.carson.mapper.EmployeeMapper">
<select id="getEmpById" resultType="com.carson.domain.Employee">
select * from employee where id = #{id}
</select>
<insert id="insertEmp">
insert into employee(lastName,email,gender,d_id) values (#{lastName}, #{email},#{gender},#{d_id})
</insert>
</mapper>
复制代码
然后再 application.yml 配置文件下添加一条配置:
# mybatis属性是跟 spring 属性平级的, 千万不要把格式搞错 mybatis: # 指定全局配置文件 config-location: classpath:mybatis/mybatis-config.xml # 指定 mapper 映射文件, * 代表所有 mapper-locations: classpath:mybatis/mapper/*.xml 复制代码
让我们在刚才的DeptController类里添加一段 Controller :
@Autowired
EmployeeMapper employeeMapper
@GetMapping("emp/{id}")
public Employee getEmp(@PathVariable("id") Integer id) {
return employeeMapper.getEmpById(id);
}
复制代码
启动主类访问一下 localhost:8080/emp/1 , 查看结果:
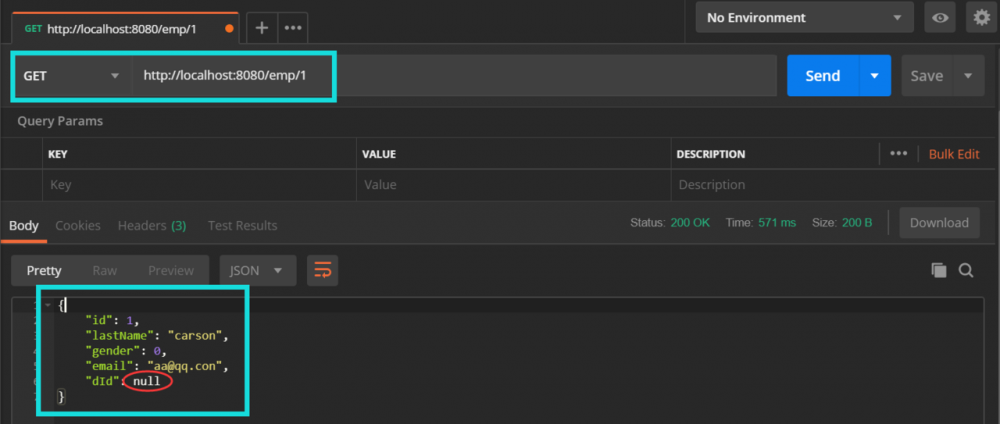
我们发现 dId没有查询出来, 这是因为 数据库字段是 d_id , 而java里是 dId , 所以我们要像刚才注解版一样, 配置一样东西, 让我们打开 mapper全局配置文件添加:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
</configuration>
复制代码
mapUnderscoreToCamelCase : 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。
再次试验:
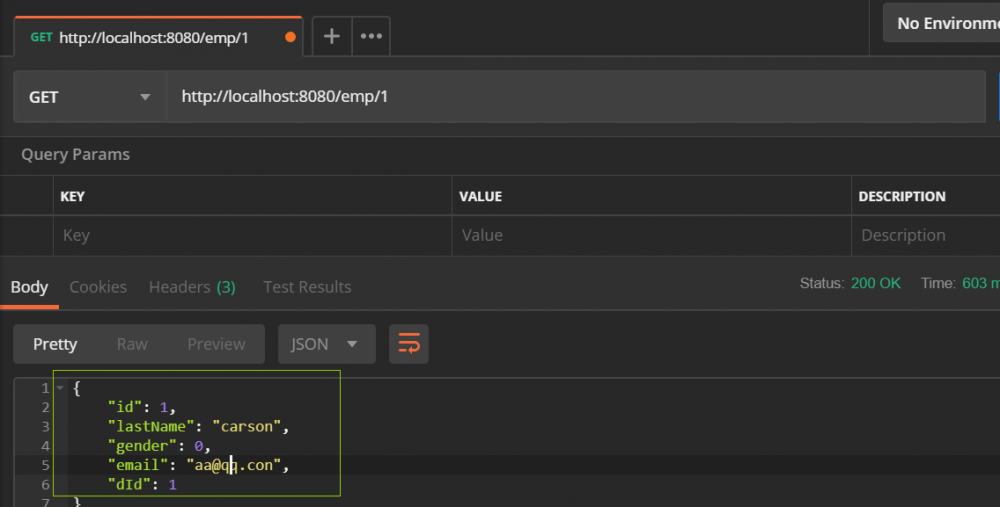
可以看出已经成功了
无论是哪种版本. 要根据自己的实际情况来定, 注解虽然方便, 但是复杂业务的就不行了
再见,谢谢~
正文到此结束
- 本文标签: 博客 cat iBATIS java GitHub druid 自动化 key lib js Property UI springboot root App mybatis servlet http 压力 IO spring 管理 Statement db XML schema https 文章 配置 Spring Boot web CTO mail REST 统计 数据库 动态SQL mysql CSS JDBC tab json Connection git ACE map id apache 注释 2019 pom list core tar mapper IDE session classpath Select dataSource struct Word sql 希望 update 代码 UTC maven value src bean 数据 HashMap 翻译 DOM 参数 tomcat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

