订单队列架构思想
前序
一般的订单流程
思考瓶颈点
订单队列
第一种订单队列流程图:
第二种订单队列流程图:
总结
实现队列的选择
解答
第二种队列的 Go 版本例子代码
前序
本文所要分享的思路就是电商应用中常用的订单队列。
一般的订单流程
电商应用中,简单直观的用户从下单到付款,最终完成整个流程的步骤可以用下图表示:
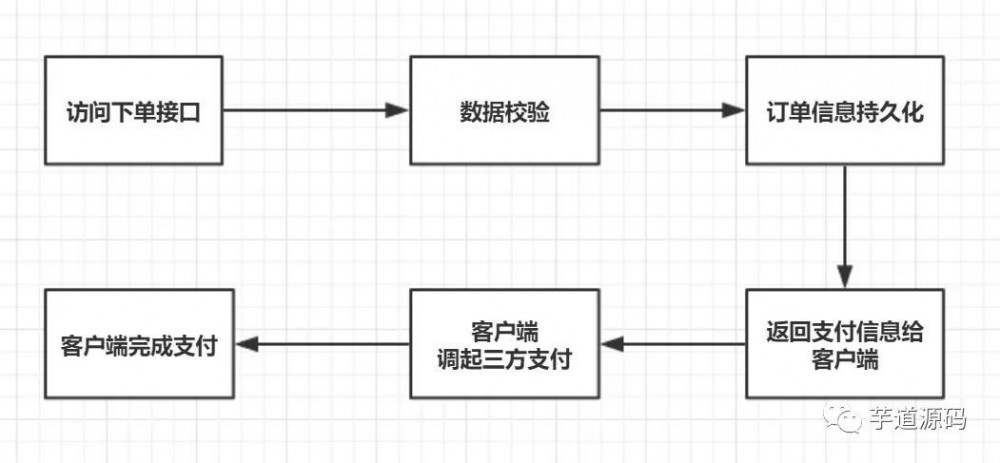
其中,订单信息持久化,就是存储数据到数据库中。而最终客户端完成支付后的更新订单状态的操作是由第三方支付平台进行回调设置好的回调链接 NotifyUrl,来进行的。
补全订单状态的更新流程,如下图表示:
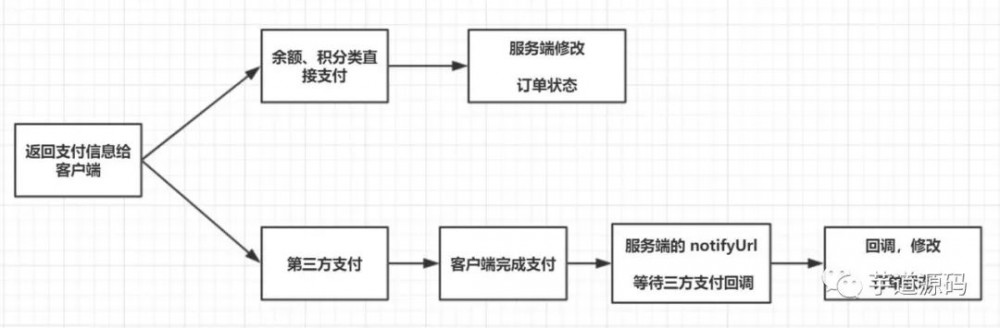
思考瓶颈点
服务端的直接瓶颈点,首先要考虑 TPS。去除细分点,我们主要看订单信息持久化瓶颈点。
在高并发业务场景中,例如 秒杀、优惠价抢购等。短时间内的下单请求数会很多,如果订单信息持久化 部分,不做优化,而是直接对数据库层进行频繁的读写操作,数据库会承受不了,容易成为第一个垮掉的服务,比如下图的所示的常规写单流程:
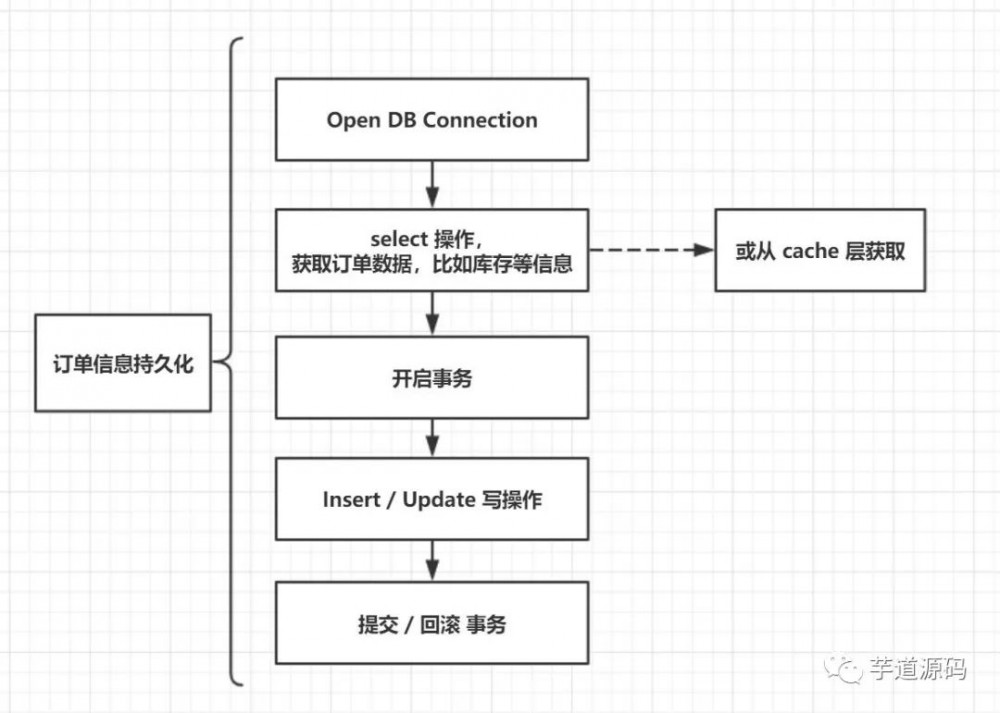
可以看到,每持久化一个订单信息,一般要经历网络连接操作(链接数据库),以及多个 I/O 操作。
得益于连接池技术,我们可以在链接数据库的时候,不用每次都重新发起一次完整的HTTP请求,而可以直接从池中获取已打开了的连接句柄,而直接使用,这点和线程池的原理差不多。
此外,我们还可以在上面的流程中加入更多的优化,例如对于一些需要读取的信息,可以事先存置到内存缓存层,并加于更新维护,这样在使用的时候,可以快速读取。
即使我们都具备了上述的一些优化手段,但是对于写操作的I/O阻塞耗时,在高并发请求的时候,依然容易导致数据库承受不住,容易出现链接多开异常,操作超时等问题。
在该层进行优化的操作,除了上面谈到的之外,还有下面一些手段:
数据库集群,采用读写分离,减少写时压力
分库,不同业务的表放到不同的数据库,会引入分布式事务问题
采用队列模型削峰
每种方式有各自的特点,因为本文谈的是订单队列的架构思想,所以下面我们来看下如何在订单系统中引入订单队列。
订单队列
网上有不少文章谈到订单队列的做法,大部分都漏了说明请求与响应的一致性问题。
第一种订单队列流程图:
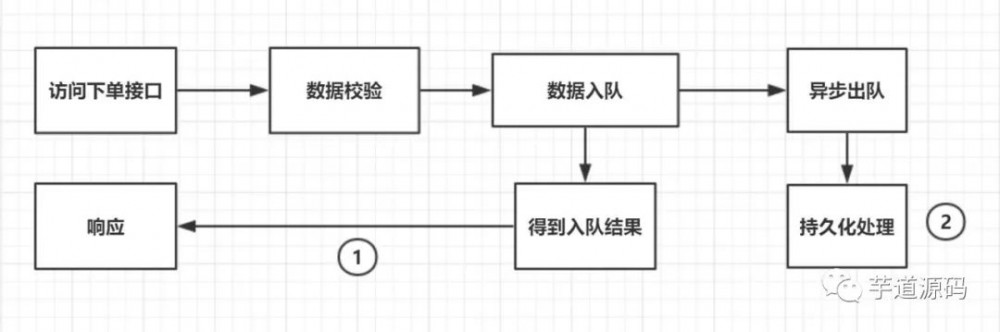
上图是大多文章提到的队列模型,有两个没有解析的问题:
如果订单存在第三方支付情况,① 和 ② 的一致性如何保证,比如其中一处处理失败;
如果订单存在第三方支付情况,① 完成了支付,且三方支付平台回调了notifyUrl,而此时 ② 还在排队等待处理,这种情况又如何处理。
首先,要肯定的是,上面的订单流程图是没有问题的。它有下面的优缺点,所提到的两个问题也是有解决方案的。
优点:
用户无需等待订单持久化处理,而能直接获得响应,实现快速下单
持久化处理,采用排队的先来先处理,不会像上面谈到的高并发请求一起冲击数据库层面的情况。
可变性强,搭配中间件的组合性强。
缺点:
多订单入队时,② 步骤的处理速度跟不上。从而导致第二点问题。
实现较复杂
上面谈及的问题点,我后面都会给出解决方案。下面我们来看下另外一种订单队列流程图。
第二种订单队列流程图:
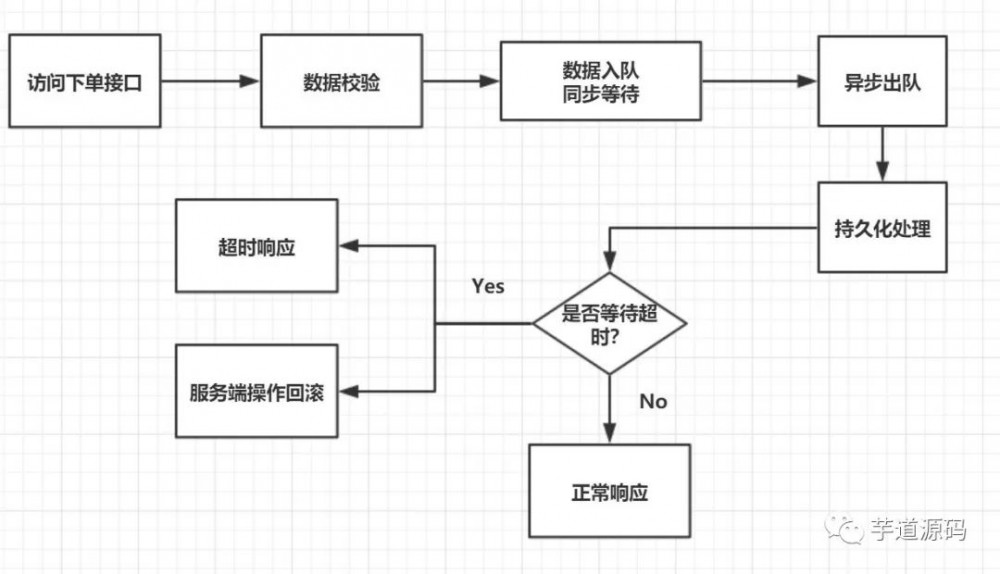
第二种订单队列的设计模型,注意它的同步等待持久化处理的结果,解决了持久化与响应的一致性问题,但是有个严重的耗时等待问题,它的优缺点如下:
优点:
持久化与响应的强一致性。
持久化处理,采用排队的先来先处理,不会像上面谈到的高并发请求一起冲击数据库层面的情况。
实现简单
缺点:
多订单入队时,持久化单元处理速度跟不上,造成客户端同步等待响应。
这类订单队列,我下面会放出 Golang 实现的版本代码。
总结
对比上面两种常见的订单模型,如果从用户体验的角度去优先考虑,第一种不需要用户等待持久化处理结果的是明显优于第二种的。如果技术团队完善,且技术过硬,也应该考虑第一种的实现方式。
如果仅仅想要达到宁愿用户等待到超时也不愿意存储层服务被冲垮,那么有限考虑第二种。
实现队列的选择
在这里,我们进一步细分一下,实现队列模块的功能有哪些选择。
相信很多后端开发经验比较老道的同志已经想到了,使用现有的中间件,比如知名的 Redis、RocketMQ,以及 Kafka 等,它们都是一种选择。
此外地,我们还可以直接编写代码,在当前的服务系统中实现一个消息队列来达到目的,下面我用图来分类下队列类型。
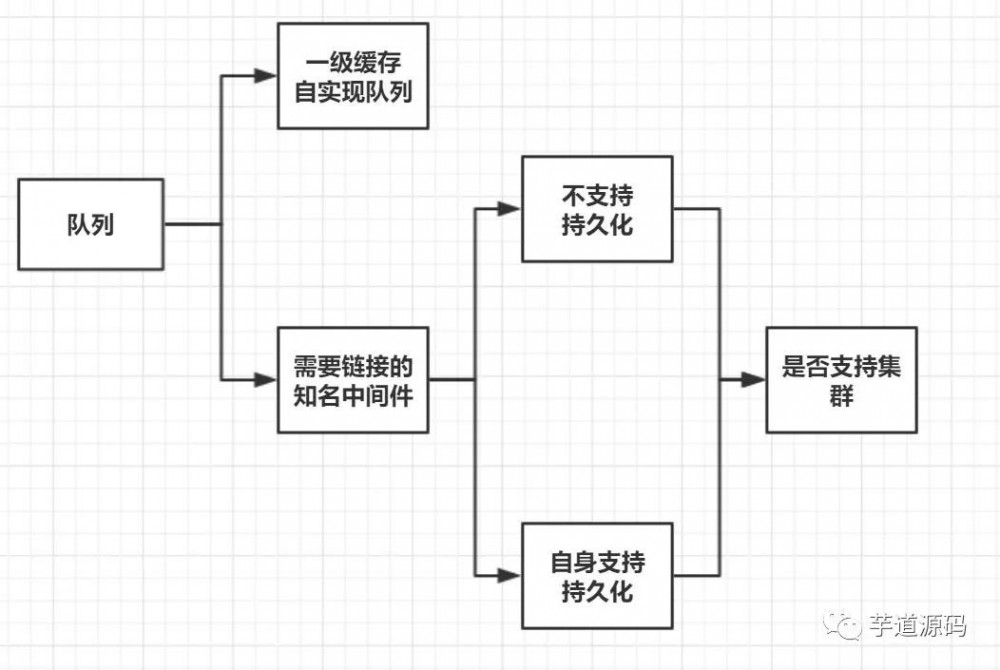
不同的队列实现方式,能直接导致不同的功能,也有不同的优缺点:
一级缓存优点:
一级缓存,最快。无需链接,直接从内存层获取;
如果不考虑持久化和集群,那么它实现简单。
一级缓存缺点:
如果考虑持久化和集群,那么它实现比较复杂。
不考虑持久化情况下,如果服务器断电或其它原因导致服务中断,那么排队中的订单信息将丢失
中间件的优点:
软件成熟,一般出名的消息中间件都是经过实践使用的,文档丰富;
支持多种持久化的策略,比如 Redis 有增量持久化,能最大程度减少因不可预料的崩溃导致订单信息丢失;
支持集群,主从同步,这对于分布式系统来说,是必不可少的要求。
中间件的缺点:
分布式部署时,需要建立链接通讯,导致读写操作需要走网络通讯。
解答
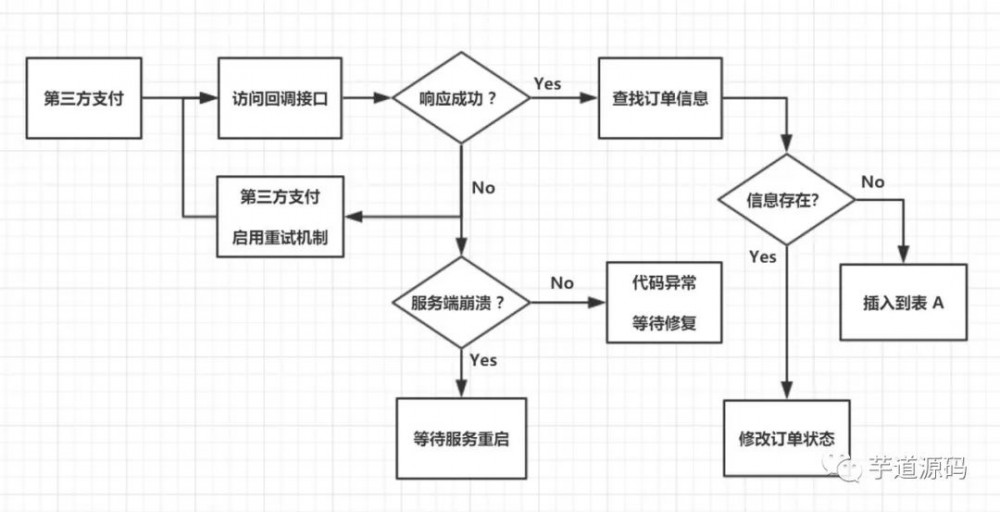
回到第一种订单模型中:

问题1:
如果订单存在第三方支付情况,① 和 ② 的一致性如何保证?
首先我们看下,不一致性的时候,会产生什么结果:
① 失败,用户因为网络原因或返回其它页面,不能获取结果。而 ② 成功,那么最终该订单的状态是待支付。用户进入到个人订单中心完成订单支付即可;
① 和 ② 都失败,那么下单失败;
① 成功,② 失败,此时用户在响应页面完成了支付动作,用户查看订单信息为空白。
上述的情况,明显地,只有 3 是需要恢复订单信息的,应对的方案有:
当服务端支付回调接口被第三方支付平台访问时,无法找到对应的订单信息。那么先将这类支付了却没订单信息的数据存储起来先,比如存储到表A。同时启动一个定时任务B专门遍历表A,然后去订单列表寻找是否已经有了对应的订单信息,有则更新,没则继续,或跟随制定的检测策略走。
当 ② 是由于服务端的`非崩溃性原因而导致失败时:
失败的时候同时将原始订单数据重新插入到队列头部,等待下一次的重新持久化处理。
当 ② 因服务端的`崩溃性原因而导致失败时:
定时任务B在进行了多次检测无果后,那么根据第三方支付平台在回调时候传递过来的订单附属信息对订单进行恢复。
整个过程订单恢复的过程,用户查看订单信息为空白。
定时任务B 所在服务最好和回调链接 notifyUrl 所在的接口服务一致,这样能保证当 B 挂掉的时候,回调服务也跟随挂掉,然后第三方支付平台在调用回调失败的情况下,他们会有重试逻辑,依赖这个,在回调服务重启时,可以完成订单信息恢复。
问题2:
如果订单存在第三方支付情况,① 完成了支付,且三方支付平台回调了 notifyUrl,而此时 ② 还在排队等待处理,这种情况又如何处理?
应对的方案参考 问题1 的 定时任务B 检测修改机制,或者是另加一个定时任务主动发起查询的机制。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

