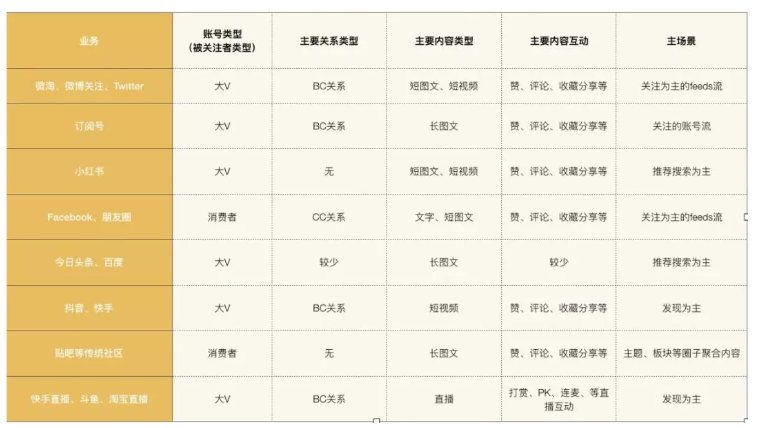
技术架构演进|0到千万DAU,微淘如何走过?

导读: 大家经常看到手淘里面的第二个TAB 就是微淘了!目前有几千万 DAU,几百亿关注关系,每天几十万的商家生产内容,对系统的挑战较大。产品形态上目前以关注 feeds 流为主,是商家非常重要的获取流量阵地(自运营阵地),下面和小编一起看看微淘技术演进史。
内容生态对淘宝的价值
1.辅助购物,即帮助消费者做更好的购物决策:
比如搜索、猜你喜欢透出内容辅助你挑选哪个商品好,宝贝详情的主图视频、买家秀、大咖点评、客服直播等等帮助你该不该下单。用户在淘宝购物过程中总会出现各自各样的需求(痛点),我们就会尝试用内容的形式解决这些需求,这是大家在手淘里面看到最多的内容,也是内容对零售最基础的价值,技术上我们构建了新零售内容平台,以平台化的方式支撑各种各样的场景。
2.探索生活消费社区:
目前淘宝的心智主要是购物,大部分用户都是想买什么才来,所以有“万能的淘宝”“只有想不到、没有买不到”的消费者心智,如何结合购物延展心智,服务更多消费者对淘宝是非常重要的。如果能有“想不到买什么,有事没事空闲的时候来淘宝逛一逛” “解决上亿中产阶级有钱没的花,找不到好东西”类似这样的心智形成,那么我们离生活消费社区就更近一步了,微淘、洋桃社区等业务就在这方面做探索。
微淘的技术挑战
内容消费业务通用的模型
基本上就这些模型,非常简单,但一些细微差别会带来的产品的心智完全不同,但大体上从工程架构看可以抽象为一套。
账号:大V、机构、店铺、消费者
内容类型:短图文、长图文、短视频、直播
关系:BC 关系,CC 关系、单向双向
内容互动:赞、收藏、评论、弹幕、负反馈(不感兴趣)、举报、拉黑。还有直播特有的连麦等实时互动
场景:关注流、发现流、热门、附近等
当时做微淘时,也负责手淘的主要社区,对工程来说很类似,同时手淘其他社区场景的同学也希望能复用我们的服务,所以第一件事情是我们构建了。
淘宝社区 API 集
结合 PD ,统一了手淘所有的内容互动 API 以及关系、账号 API ,完成了 “社区平台雏形”为什么是雏形,因为这个平台只有基础 API ,当时思考是具体每个社区场景呈现都不一样,所以上层业务需要基于 API 各自组织业务。整体研发效率上提升不少,用户相关的内容互动、内容数据完成了统一。
timeline 引擎
微淘是基于关系的,几年前 feeds 引擎业内是很火的,基本上 Facebook 、 Twitter 、微博等大公司都在探索,我们也伴随着业务沉淀了一套,微淘业务与 timeline 引擎的关系如下:
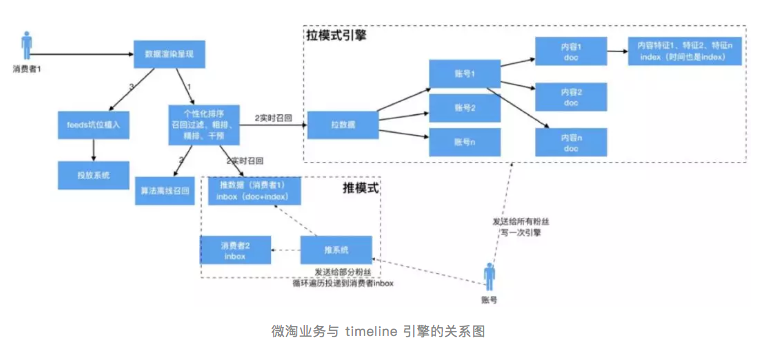
拉引擎我们内部也叫 基于关系的搜索引擎 。
拉模式的适合场景是关注数和粉丝数数严重不对等的情况,比如微淘的场景,部分店铺的粉丝数过千万,但是用户的关注上限是几千,这里面如果一个大 V 发一条 feed ,走推模式要更新千万的用户 inbox ,显然是不合理的。
但是对于关注数和粉丝数差不多的情况,不建议走拉模式。比如朋友圈,关注上限大概是500,粉丝数大概也是500,那么推模式更有效。
下面介绍下拉引擎(关系搜索引擎)的实现原理:
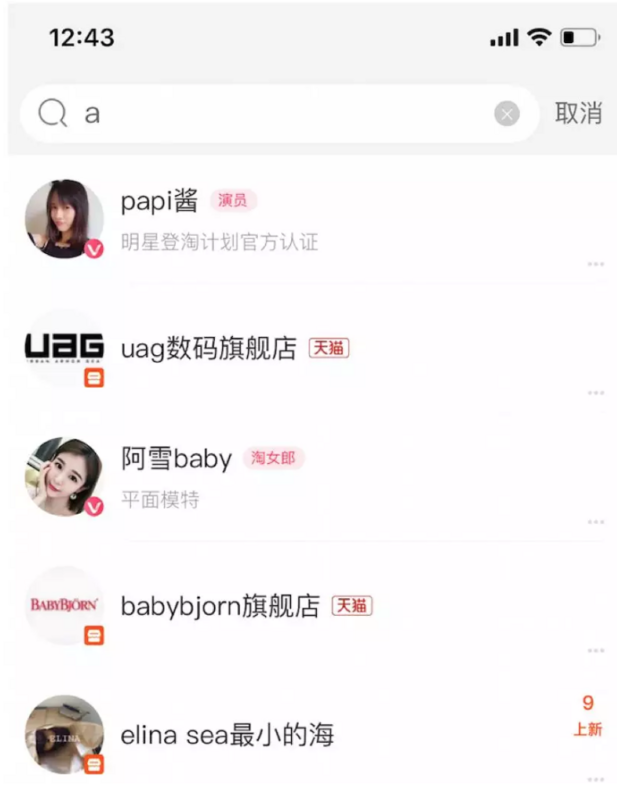
举例:比如我的淘宝--店铺关注列表里面对店铺名称的实时搜索。

从这里进去
对店铺的标题建索引,输入 a 可以查到有这么多关注的店铺。
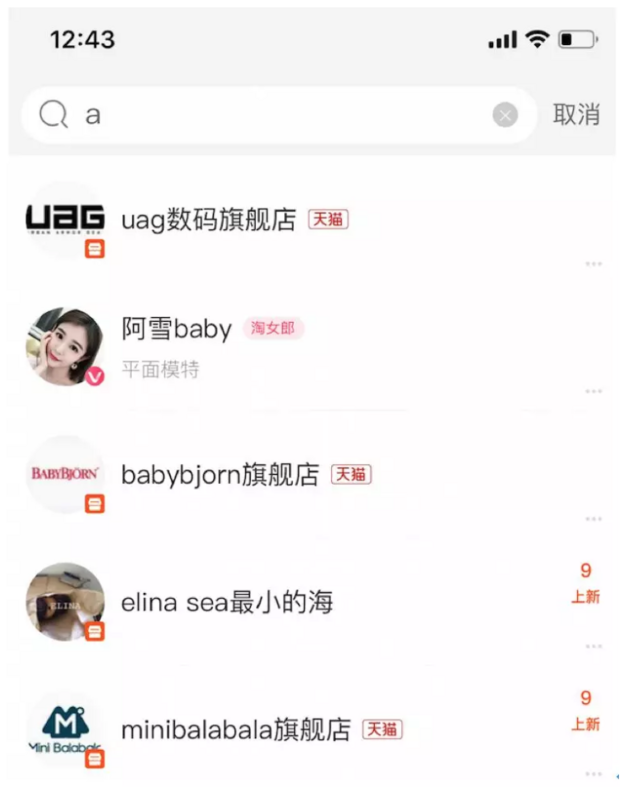
去取消关注后,再输入 a 查询,可以看到结果实时变化了~
术语:inbox 用户的收件箱,outbox 用户的发件箱
两者数据结构是一样的,类似邮件,收件箱发件箱里面存了很多封邮件, 每封邮件就是 doc ,邮件有标题、副标题就是索引 index 。我们可以根据 index 来快速查找一个用户有多少匹配的邮件,这个就是 inbox 的内部搜索;
邮件系统是用推模式实现的, 如果用拉模式来翻译的话。
我关注了很多人,我想一次性根据某些索引查询这些人的发件箱中满足匹配的邮件,并且按照一定排序规则来汇总。
以上面的关注搜索店铺名称为例,店铺的标题、认证、简介等都是不同的 doc ,索引是标题字符串;
所以 outbox 就是 doc 数组。doc 则由 doc_id+index 数组 组成。
假设只有店铺标题一个doc。
我们调用引擎把店铺 id,doc [“xxx旗舰店”]写入到引擎里面
对于每一个店铺,我们把 doc 数据先更新到 db ,然后更新到分布式缓存店铺的 outbox ,然后失效每台机器的本地缓存 outbox 。(考虑到性能和时效性,我们对 outbox 的 doc 数量做了上限,doc 数量超过 3000 ,远满足一般性需求)
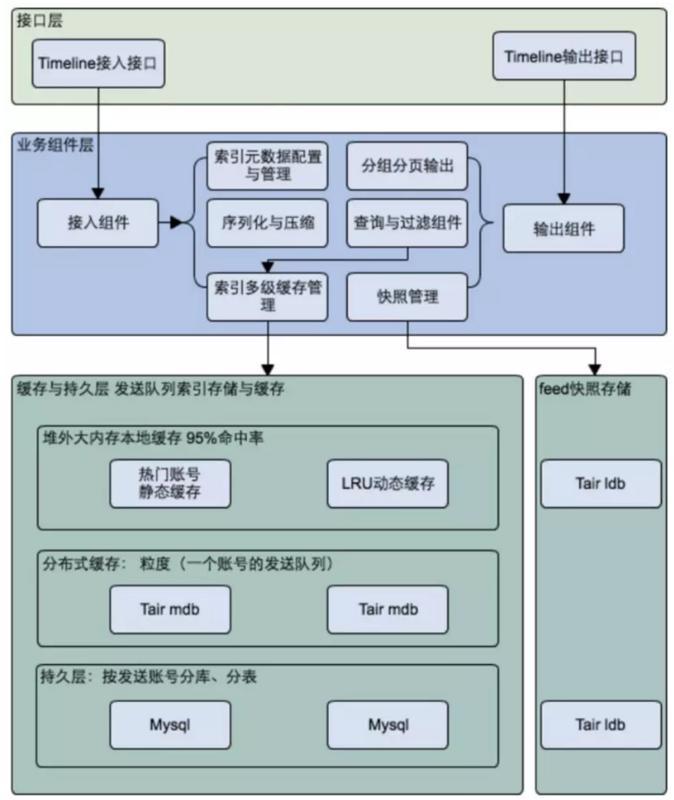
当店铺的 outbox 第一次被访问时,如果非热门店铺本地的堆外 LRU 缓存加载,如果是热门店铺,加载到静态缓存区域。
热门店铺的判断逻辑是:离线计算粉丝数最高的 TOP N 店铺,然后定期更新名单库,这里面由于大号的粉丝特别多,基本上热门店铺的关系数量占用全部的关系 50% 以上。
整个查询逻辑如下:
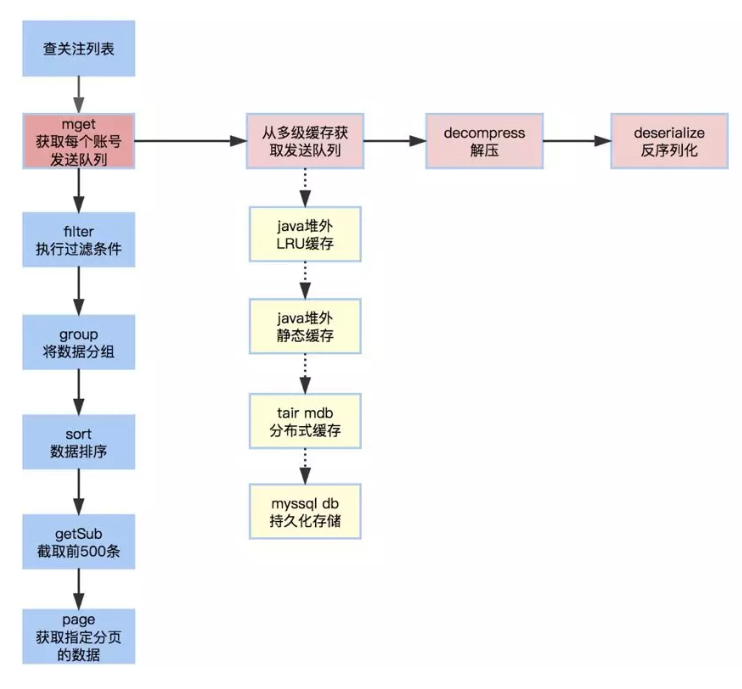
整体本地内存命中率 95%,本地加远程命中率 99.9%,未来改为持久化缓存则 100%;
堆外缓存可以大大减少FullGC概率。
另外 outbox 的压缩和解压缩非常关键,索引字段全部采用原生类型,先采用 Kyro 序列化,然后 ZIP 压缩;
端测渲染引擎
业界内容业务的特点总是交互体验创新层出不穷,在微淘也不例外。
微淘又是手淘一个 tab ,对性能要求更高,尤其低端机型的性能。
对业务方来说交互体验差是无法接受的,对于隔一个月发一次版本勉强是可以的,但对于技术来说,研发效率提升是我们要不断追求的。
所以整体微淘的端测渲染技术策略是体验为主、效率为辅。
在今天如果端测的 UI 渲染技术同时能满足体验和效率,那就不用折腾了,但是很遗憾目前没见到过。
下面是 2017 年初的现状,灰色部分当时还没有。
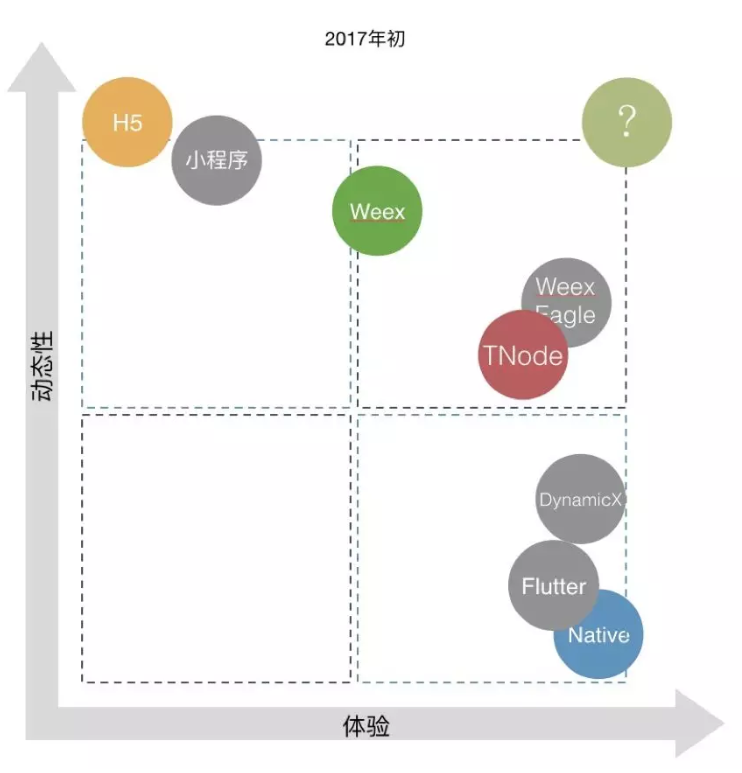
在以体验为主,效率为辅的策略下,微淘端测动态化的几个阶段:
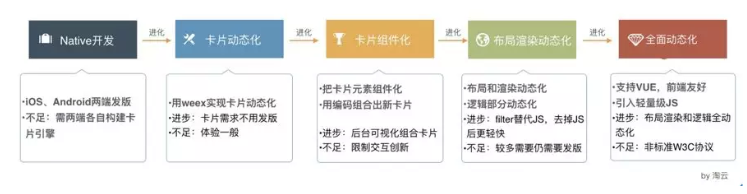
当时卡片组件化最大的问题是,限制了 UED 同学的视觉交互创新,往往一个细微的创新看似很简单却发现组件化改动很大。比如给整个内容大卡片套一个外框,则要求每个小卡片都做修改。过程中与 PD、UED 组件化的约定做了几次,但是在创新面前还是败了。
我们在 2017 年开始打造以体验为主效率为辅的 TNode 引擎,DSL 从最初的客户端语言到最后与前端共建升级到了 VUE ,有效的解决了端测研发效率问题,同时微淘性能在手淘主链路中保持中位数。
Tnode 的技术架构
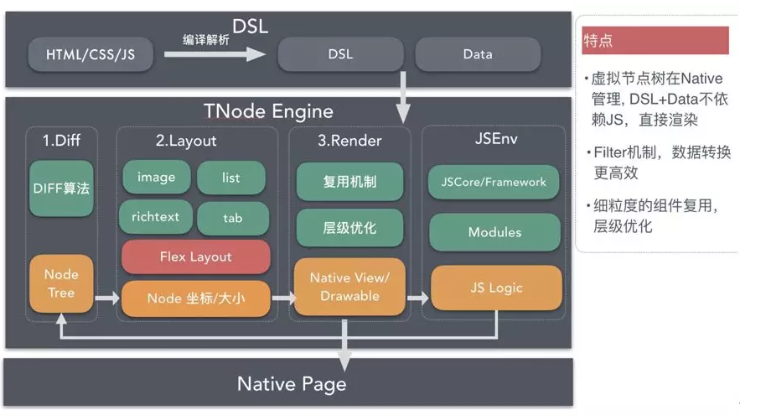
这块主要是淘云、重哥、水军等同学实现,我简单介绍下:
1、首屏性能优化,Duktape 引擎替换 WebView ,低内存高性能。提供端测表达式引擎,常规逻辑处理采用 Native 函数。

2、页面完成渲染后,所有事件异步js驱动
3、DSL 二进制减少网络、解析大小。DSL 中表达式预编译。
4、Flex 层级优化,如采用虚拟节点等方式
目前 TNode 是前端开发,因为是效率为辅,他仍然存在很多效率问题,最大的两个问题是:
不能完全满足 W3C 协议(换句话来说以前端思维看这个还是很坑,像是早些年前端同学兼容 IE6 感觉一样)。
与手淘前端主流的 RAX 以及封装的 Weex Native 模块不融合,这意味着没有生态。
但 TNode 确实解决了那些以体验为主效率为辅的场景,架构组在了解 TNode 架构后,基于 WEEX 生态,在 2019 年初基本完成了 WEEX-EAGLE,与微淘同学一起试点,试图解决问题 2。
TNode 最大的价值是加速了整个手淘动态化演进的进程,如果把当前的动态化技术比作混合电动车时代,那他在市场上还是会存在一段时间,但是最终一定会过渡到电动车,让所有消费者无顾虑的接受。对于当前动态化技术是一样的,在体验为主效率为辅的场景, 与在效率为主体验要求不高的场景是两种不同的方案。然后最终有一天会融为一体,甚至加上 BFF 三端一体,未来都是大前端领域范畴。
内容分发平台
前面提到了我们构建了大量的社区基础 API ,但是每个场景业务逻辑都不太一样,场景层都要定制开发。
我们遇到了几个问题:
1、系统比开发多:内容分发(社区)的场景是非常非常多的,前面提到我们要试图解决用户在购物路径中的各种需求,而且业务升级频率高,以往为了隔离都是一个业务一个系统,业务大升级又得来一个系统,久而久之业务系统比开发还多。
2、不同客户端版本兼容成本高:客户端老版本兼容,bug 修复带来了大量的 ifelse ,而且好几年内都不能下线,写完后代码过几天自己也看不懂了,也不敢动了,也不想看到了。
3、业务代码生命周期短、系统频繁重构怪圈:徘徊于代码复制和复用的纠结,如果新老业务代码复用,复用代码改变则要回归很多历史版本,在手淘开发中回归历史版本是一个很痛苦很低效率的事情,如果复制一堆重复的代码则更乱。更进一步思考任何一个新系统在业务频繁升级的情况下,代码就会堆积,马上就变得难以维护,然后系统启动很慢然后又开始进入重构的循环,这个周期取决于业务需求数量,一般也就两年左右就很臃肿了。
4、另一个背景是端测效率提升后,客户端部分同学希望能更加的了解业务,能全栈,但是服务端的单元化、运维等很多东西很重,希望能给全栈同学更轻松的更高效的研发环境。
5、还有 AB 实验效率问题,目前业务侧的 AB 主要是新业务功能的 ab ,不是算法策略的 ab ,新功能的 ab 核心还是研发效率问题。比如微淘的页面,坑位, Tab 新需求改动都要 ab 对比效果,都要有多份数据存储;
为了解决上述问题,我们把业务代码打包成一个业务 bundle ,做到业务和历史业务隔离,业务和平台隔离,结合内容分发业务现状,集成 AB 、内容、分发策略、社区 API ,整体构建了内容分发平台。
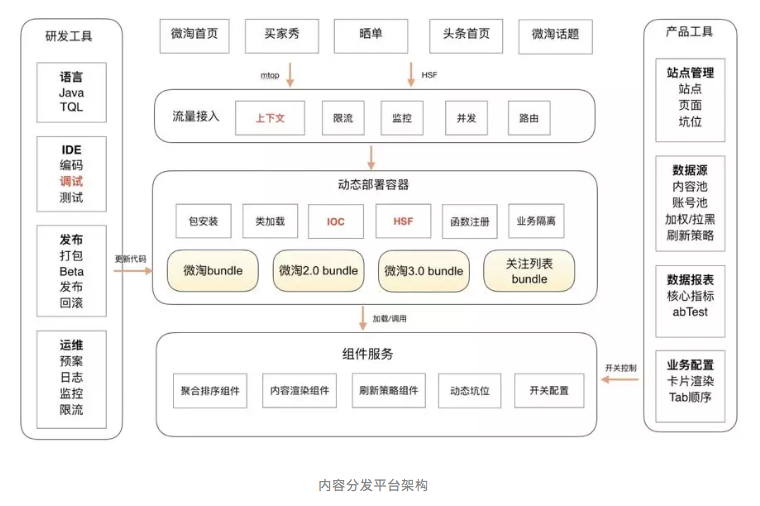
未来:定位上仍然是解决内容消费场景的数据展示需求,是一个业务平台。主要核心是为了解决1、2、3的问题,第4点与现在流行的serverless有那么一点点关系,后面看serverless演进成熟度再看结合点。
抢阿里云新用户专属优惠权益,致电95187-1 !
本文作者:金争争(大鹏)
阅读原文
本文为云栖社区原创内容,未经允许不得转载。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

