Shiro权限管理框架(三):Shiro中权限过滤器的初始化流程和实现原理
其实关于Shiro的一些学习笔记很早就该写了,因为懒癌和拖延症晚期一直没有落实,直到今天公司的一个项目碰到了在集群环境的单点登录频繁掉线的问题,为了解决这个问题,Shiro相关的文档和教程没少翻。最后问题解决了,但我觉得我也是时候来做一波Shiro学习笔记了。
本篇是Shiro系列第三篇,Shiro中的过滤器初始化流程和实现原理。Shiro基于URL的权限控制是通过Filter实现的,本篇从我们注入的 ShiroFilterFactoryBean 开始入手,翻看源码追寻Shiro中的过滤器的实现原理。
初始化流程
ShiroFilterFactoryBean实现了FactoryBean接口,那么Spring在初始化的时候必然会调用ShiroFilterFactoryBean的getObject()获取实例,而ShiroFilterFactoryBean也在此时做了一系列初始化操作。
在getObject()中会调用createInstance(),初始化相关的东西都在这里了,代码贴过来去掉了注释和校验相关的代码。
protected AbstractShiroFilter createInstance() throws Exception {
SecurityManager securityManager = getSecurityManager();
FilterChainManager manager = createFilterChainManager();
PathMatchingFilterChainResolver chainResolver = new PathMatchingFilterChainResolver();
chainResolver.setFilterChainManager(manager);
return new SpringShiroFilter((WebSecurityManager) securityManager, chainResolver);
}
这里面首先获取了我们在ShiroConfig中注入好参数的SecurityManager,再次强调,这位是Shiro中的核心组件。然后创建了一个FilterChainManager,这个类看名字就知道是用来管理和操作过滤器执行链的,我们来看它的创建方法createFilterChainManager()。
protected FilterChainManager createFilterChainManager() {
DefaultFilterChainManager manager = new DefaultFilterChainManager();
Map<String, Filter> defaultFilters = manager.getFilters();
for (Filter filter : defaultFilters.values()) {
applyGlobalPropertiesIfNecessary(filter);
}
Map<String, Filter> filters = getFilters();
if (!CollectionUtils.isEmpty(filters)) {
for (Map.Entry<String, Filter> entry : filters.entrySet()) {
String name = entry.getKey();
Filter filter = entry.getValue();
applyGlobalPropertiesIfNecessary(filter);
if (filter instanceof Nameable) {
((Nameable) filter).setName(name);
}
manager.addFilter(name, filter, false);
}
}
Map<String, String> chains = getFilterChainDefinitionMap();
if (!CollectionUtils.isEmpty(chains)) {
for (Map.Entry<String, String> entry : chains.entrySet()) {
String url = entry.getKey();
String chainDefinition = entry.getValue();
manager.createChain(url, chainDefinition);
}
}
return manager;
}
第一步new了一个DefaultFilterChainManager,在它的构造方法中将filters和filterChains两个成员变量都初始化为一个能保持插入顺序的LinkedHashMap了,之后再调用addDefaultFilters()添加Shiro内置的一些过滤器。
public DefaultFilterChainManager() {
this.filters = new LinkedHashMap<String, Filter>();
this.filterChains = new LinkedHashMap<String, NamedFilterList>();
addDefaultFilters(false);
}
protected void addDefaultFilters(boolean init) {
for (DefaultFilter defaultFilter : DefaultFilter.values()) {
addFilter(defaultFilter.name(), defaultFilter.newInstance(), init, false);
}
}
这里用枚举列出了所有Shiro内置过滤器的实例。
public enum DefaultFilter {
anon(AnonymousFilter.class),
authc(FormAuthenticationFilter.class),
authcBasic(BasicHttpAuthenticationFilter.class),
logout(LogoutFilter.class),
noSessionCreation(NoSessionCreationFilter.class),
perms(PermissionsAuthorizationFilter.class),
port(PortFilter.class),
rest(HttpMethodPermissionFilter.class),
roles(RolesAuthorizationFilter.class),
ssl(SslFilter.class),
user(UserFilter.class);
}
以上代码有省略,上面列出的枚举类型正好对应Shiro第一篇提到的Shiro内置的一些过滤器,这些过滤器正好是在这里初始化并添加到过滤器执行链中的,每个过滤器都有不同的功能,我们常用的其实只有前面两个。
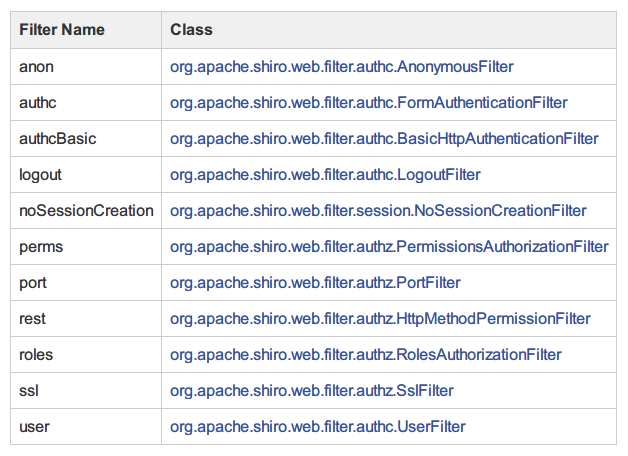
回到上上一步中,DefaultFilterChainManager初始化完成后,遍历了每一个默认的过滤器并调用了applyGlobalPropertiesIfNecessary()设置一些必要的全局属性。
private void applyGlobalPropertiesIfNecessary(Filter filter) {
applyLoginUrlIfNecessary(filter);
applySuccessUrlIfNecessary(filter);
applyUnauthorizedUrlIfNecessary(filter);
}
在这个方法中调用了三个方法,三个方法逻辑是一样的,分别是设置loginUrl、successUrl和unauthorizedUrl,我们就看第一个applyLoginUrlIfNecessary()。
private void applyLoginUrlIfNecessary(Filter filter) {
String loginUrl = getLoginUrl();
if (StringUtils.hasText(loginUrl) && (filter instanceof AccessControlFilter)) {
AccessControlFilter acFilter = (AccessControlFilter) filter;
String existingLoginUrl = acFilter.getLoginUrl();
if (AccessControlFilter.DEFAULT_LOGIN_URL.equals(existingLoginUrl)) {
acFilter.setLoginUrl(loginUrl);
}
}
}
看方法名就知道是要设置loginUrl,如果我们配置了loginUrl,那么会将AccessControlFilter中默认的loginUrl替换为我们设置的值,默认的loginUrl为 /login.jsp 。后面两个方法道理一样,都是将我们设置的参数替换进去,只不过第三个认证失败跳转URL的默认值为null。
继续回到上一步,Map<String, Filter> filters = getFilters(); 这里是获取我们自定义的过滤器,默认是为空的,如果我们配置了自定义的过滤器,那么会将其添加到filters中。至此filters中包含着Shiro内置的过滤器和我们配置的所有过滤器。
下一步,遍历filterChainDefinitionMap,这个filterChainDefinitionMap就是我们在ShiroConfig中注入进去的拦截规则配置。这里是根据我们配置的过滤器规则创建创建过滤器执行链。
public void createChain(String chainName, String chainDefinition) {
String[] filterTokens = splitChainDefinition(chainDefinition);
for (String token : filterTokens) {
String[] nameConfigPair = toNameConfigPair(token);
addToChain(chainName, nameConfigPair[0], nameConfigPair[1]);
}
}
chainName是我们配置的过滤路径,chainDefinition是该路径对应的过滤器,通常我们都是一对一的配置,比如: filterMap.put("/login", "anon"); ,但看到这个方法我们知道了一个过滤路径其实是可以通过传入 ["filter1","filter2"...] 配置多个过滤器的。在这里会根据我们配置的过滤路径和过滤器映射关系一步步配置过滤器执行链。
public void addToChain(String chainName, String filterName, String chainSpecificFilterConfig) {
Filter filter = getFilter(filterName);
applyChainConfig(chainName, filter, chainSpecificFilterConfig);
NamedFilterList chain = ensureChain(chainName);
chain.add(filter);
}
先从filters中根据filterName获取对应过滤器,然后ensureChain()会先从filterChains根据chainName获取NamedFilterList,获取不到就创建一个并添加到filterChains然后返回。
protected NamedFilterList ensureChain(String chainName) {
NamedFilterList chain = getChain(chainName);
if (chain == null) {
chain = new SimpleNamedFilterList(chainName);
this.filterChains.put(chainName, chain);
}
return chain;
}
因为过滤路径和过滤器是一对多的关系,所以ensureChain()返回的NamedFilterList其实就是一个有着name称属性的List<Filter>,这个name保存的就是过滤路径,List保存着我们配置的过滤器。获取到NamedFilterList后在将过滤器加入其中,这样过滤路径和过滤器映射关系就初始化好了。
至此,createInstance()中的createFilterChainManager()才算执行完成,它返回了一个FilterChainManager实例。之后再将这个FilterChainManager注入PathMatchingFilterChainResolver中,它是一个过滤器执行链解析器。
PathMatchingFilterChainResolver中的方法不多,最为重要的是这个getChain()方法。
public FilterChain getChain(ServletRequest request, ServletResponse response, FilterChain originalChain) {
FilterChainManager filterChainManager = getFilterChainManager();
if (!filterChainManager.hasChains()) {
return null;
}
String requestURI = getPathWithinApplication(request);
for (String pathPattern : filterChainManager.getChainNames()) {
if (pathMatches(pathPattern, requestURI)) {
return filterChainManager.proxy(originalChain, pathPattern);
}
}
return null;
}
看到形参中ServletRequest和ServletResponse这两个参数是不是感觉特别亲切,终于看到了点熟悉的东西了,一看就知道肯定跟请求有关。是的,我们每次请求服务器都会调用这个方法,根据请求的URL去匹配过滤器执行链中的过滤路径,匹配上了就返回其对应的过滤器进行过滤。
这个方法中的filterChainManager.getChainNames()返回的是根据我们的配置配置生成的执行链的过滤路径集合,执行链生成的顺序跟我们的配置的顺序相同。从前文中我们也可以看到,在DefaultFilterChainManager的构造方法中将filterChains初始化为一个LinkedHashMap。所以在我的Shiro笔记第一篇中提到要将范围大的过滤器放在后面就是这个道理,如果第一个匹配的过滤路径就是 /** 那后面的过滤器永远也匹配不上。
过滤实现原理
那么这个getChain()是如何被调用的呢?既然是HTTP请求那肯定是从Tomcat过来的,当一个请求到达Tomcat时,Tomcat以责任链的形式调用了一系列Filter,OncePerRequestFilter就是众多Filter中的一个。它所实现的doFilter()方法调用了自身的抽象方法doFilterInternal(),这个方法在它的子类AbstractShiroFilter中被实现了。
PathMatchingFilterChainResolver.getChain()就是被在doFilterInternal()中被一步步调用的调用的。
protected void doFilterInternal(ServletRequest servletRequest, ServletResponse servletResponse,
final FilterChain chain) throws ServletException, IOException {
final ServletRequest request = prepareServletRequest(servletRequest, servletResponse, chain);
final ServletResponse response = prepareServletResponse(request, servletResponse, chain);
final Subject subject = createSubject(request, response);
subject.execute(new Callable() {
public Object call() throws Exception {
updateSessionLastAccessTime(request, response);
executeChain(request, response, chain);
return null;
}
});
}
这里先获获取滤器,然后执行。
protected void executeChain(ServletRequest request, ServletResponse response, FilterChain origChain)
throws IOException, ServletException {
FilterChain chain = getExecutionChain(request, response, origChain);
chain.doFilter(request, response);
}
获取过滤器方法如下。
protected FilterChain getExecutionChain(ServletRequest request, ServletResponse response, FilterChain origChain) {
FilterChain chain = origChain;
FilterChainResolver resolver = getFilterChainResolver();
if (resolver == null) {
return origChain;
}
FilterChain resolved = resolver.getChain(request, response, origChain);
if (resolved != null) {
chain = resolved;
} else {
}
return chain;
}
通过getFilterChainResolver()就拿到了上面提到的过滤器执行链解析器PathMatchingFilterChainResolver,然后再调用它的getChain()匹配获取过滤器,最终过滤器在executeChain()中被执行。
总结
Shiro框架在我们配置的 ShiroFilterFactoryBean 进行初始化的时候就做了很多初始化操作,将我们配置的过滤器规则一步步添加对应的过滤器到过滤器执行链中,这个执行链最终被放入执行链解析器。当有请求到达Tomcat时,通过Tomcat中的Filter责任链执行流程,最终Shiro所定义的AbstractShiroFilter.doFilter()被执行,那么它会去获取执行链解析器,通过解析器拿到执行链中的过滤器并执行,这样就实现了基于URL的权限过滤。
本文结束,这篇也算是浅入了Shiro源码了解了一下Shiro过滤器的初始化以及执行过程,相比Spring的源码Shiro的源码要简单易懂的很多很多,它没有Spring那么绕。每次看源码的时候,我都有下面这种感觉,特别是看Spring源码的时候这种感觉尤为强烈:

对于框架我们所配置和调用的,永远是浮在水面上的那一点点,不点进去,你永远不知道下边是一个怎样的庞然大物。封装的越好的框架,浮现出来的越少,隐藏的部分就越多。
比如SpringBoot,为什么能通过一个main方法就启动一个项目,web.xml呢,application.properties呢;SpringMVC为什么就需要一个@RequestMapping就能实现从URL到方法的调用;Shiro为什么仅需要@RequiresPermissions就能实现方法级别的权限控制。
学到的越多就越是感觉自己知道的越少,这是一个很矛盾却又真实存在的感觉。不说了该学习了,上面的最后一条方法级别权限控制下一篇写,时间待定,因为最近在项目中刚好遇到数据库优化相关问题,想先去看看MySQL。
正文到此结束
- 本文标签: tomcat sql 时间 实例 一对多 ORM HashMap spring servlet 集群 代码 遍历 参数 bean 权限控制 rmi cat 管理 解析 REST Security token 2019 logo 认证 数据库 NSA HTML SpringMVC Authorization springboot tk mysql 源码 数据 App list http id Proxy ssl 拖延症 UI CTO value src MQ 构造方法 服务器 js 配置 CEO key 总结 Collection equals web https map 注释 XML final IO session update
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

