sbt 打包 scala 项目
大数据开发,一直都用java spring boot框架,加载scala,spark,scala兼容包等,spark开发用scala,其他的开发用java,打包用mvn,感觉还是挺不错的。
如果只是开spark,scala就足够了,没必要在用spring boot。这样感觉不会那么怪。
1,什么sbt
sbt是类似ANT、MAVEN的构建工具,全称为Simple build tool,是Scala事实上的标准构建工具。
主要特性:
原生支持编译Scala代码和与诸多Scala测试框架进行交互;
使用Scala编写的DSL(领域特定语言)构建描述
使用Ivy作为库管理工具
持续编译、测试和部署
整合scala解释器快速迭代和调试
支持Java与Scala混合的项目
2,创建scala项目,并引入spark包
name := "scalatest"
version := "0.1"
scalaVersion := "2.11.8"
//加载包
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "2.3.0",
"org.apache.spark" % "spark-sql_2.11" % "2.3.0",
"com.alibaba" % "fastjson" % "1.2.49"
)
//多版本冲突解决
assemblyMergeStrategy in assembly := {
case PathList("javax", "inject", xs @ _*) => MergeStrategy.first
case PathList("org", "apache", xs @ _*) => MergeStrategy.first
case "application.conf" => MergeStrategy.concat
case "git.properties" => MergeStrategy.first
case PathList("org", "aopalliance", xs @ _*) => MergeStrategy.first
case "unwanted.txt" => MergeStrategy.discard
case m if m.toLowerCase.endsWith("manifest.mf") => MergeStrategy.discard
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x =>
val oldStrategy = (assemblyMergeStrategy in assembly).value
oldStrategy(x)
}
MergeStrategy.deduplicate 是上面描述的默认值
MergeStrategy.first 选择classpath顺序中的第一个匹配文件
MergeStrategy.last 挑选最后一个
MergeStrategy.singleOrError 在冲突时出现错误消息
MergeStrategy.concat 简单地连接所有匹配的文件并包含结果
MergeStrategy.filterDistinctLines 也可以连接,但在此过程中会留下重复的内容
MergeStrategy.rename 重命名源自jar文件的文件
MergeStrategy.discard 只是丢弃匹配的文件
3,安装sbt-assembly
MacBook-Pro:scalatest zhangying$ cat project/plugins.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.9")
在项目,根目录/project/下创建一下plugins.sbt文件,添加以上内容 。IDEA会重新加载包。
注意, 高版本的sbt,build.sbt不需要import AssemblyKeys._ ,如果加了会报错如下:
import AssemblyKeys._
^
[error] Type error in expression
我用的sbt是:
MacBook-Pro:scalatest zhangying$ cat project/build.properties sbt.version = 1.2.8
为什么要引入assembly呢? 因为sbt package的时候,包依赖并不能被打包,包依赖并不能被打包,包依赖并不能被打包 ,这样打出来的包是不能直接运行的,感觉有点坑。
4,sbt 打包 scala 项目
MacBook-Pro:scalatest zhangying$ sbt clean compile assembly
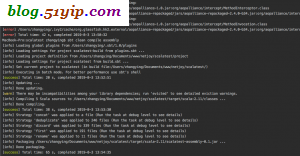
sbt打包成功
也可以进入sbt的命令行下打包。
在打包过程中遇到的多版本问题
[error] deduplicate: different file contents found in the following:
[error] /Users/zhangying/.ivy2/cache/org.apache.spark/spark-core_2.11/jars/spark-core_2.11-2.3.0.jar: org/apache /spark/unused/UnusedStubClass.class
[error] /Users/zhangying/.ivy2/cache/org.apache.arrow/arrow-vector/jars/arrow-vector-0.8.0.jar: git.properties
[error] /Users/zhangying/.ivy2/cache/aopalliance/aopalliance/jars/aopalliance-1.0.jar: org/aopalliance /intercept/Invocation.class
[error] /Users/zhangying/.ivy2/cache/javax.inject/javax.inject/jars/javax.inject-1.jar: javax/inject /Inject.class
[error] /Users/zhangying/.ivy2/cache/org.glassfish.hk2.external/aopalliance-repackaged/jars/aopalliance-repackaged-2.4.0-b34.jar: org/aopalliance /aop/AspectException.class
MacBook-Pro:org.apache.spark zhangying$ ll total 0 drwxr-xr-x 26 zhangying staff 884 7 31 16:19 ./ drwxr-xr-x 209 zhangying staff 7106 8 1 21:37 ../ drwxr-xr-x 10 zhangying staff 340 7 31 16:22 spark-catalyst_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:34 spark-catalyst_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-core_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:34 spark-core_2.12/ drwxr-xr-x 7 zhangying staff 238 7 31 15:30 spark-graphx_2.11/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-kvstore_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:35 spark-kvstore_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-launcher_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:35 spark-launcher_2.12/ drwxr-xr-x 7 zhangying staff 238 7 31 15:30 spark-mllib-local_2.11/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-network-common_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:34 spark-network-common_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-network-shuffle_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:35 spark-network-shuffle_2.12/ drwxr-xr-x 8 zhangying staff 272 7 31 16:19 spark-parent_2.11/ drwxr-xr-x 5 zhangying staff 170 7 31 15:32 spark-parent_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:22 spark-sketch_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:35 spark-sketch_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:21 spark-sql_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:34 spark-sql_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-tags_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:34 spark-tags_2.12/ drwxr-xr-x 10 zhangying staff 340 7 31 16:19 spark-unsafe_2.11/ drwxr-xr-x 7 zhangying staff 238 7 31 15:34 spark-unsafe_2.12/
解决办法: 1,可以删除多余版本;2,解决多版本冲突
//多版本冲突解决
assemblyMergeStrategy in assembly := {
case PathList("javax", "inject", xs @ _*) => MergeStrategy.first
case PathList("org", "apache", xs @ _*) => MergeStrategy.first
case "application.conf" => MergeStrategy.concat
case "git.properties" => MergeStrategy.first
case PathList("org", "aopalliance", xs @ _*) => MergeStrategy.first
case "unwanted.txt" => MergeStrategy.discard
case m if m.toLowerCase.endsWith("manifest.mf") => MergeStrategy.discard
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x =>
val oldStrategy = (assemblyMergeStrategy in assembly).value
oldStrategy(x)
}
注意:
匹配规则在:后面,而不是开头,上面的红色字体标识。
匹配规则在:后面,而不是开头,上面的红色字体标识。
匹配规则在:后面,而不是开头,上面的红色字体标识。
正文到此结束
- 本文标签: CTO java build https cache IDE key classpath core sql Spring Boot 代码 spring 开发 git plugin 数据 json 测试 src cat id 管理 dependencies 目录 ip scala 调试 HTML 编译 lib AOP 大数据 list maven 删除 UI 部署 App apache dist js IO NSA value Hadoop http 安装 tag
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

