Java并发之线程池的使用浅析
背景
当系统并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要消耗大量的系统资源。
所以需要一个办法使得线程可以复用,即当线程执行完一个任务,并不被销毁,而是可以继续执行其他的任务。在Java中就可以通过线程池来实现这样的效果。 本文讲述了Java中的线程池类以及如何使用线程池。
一、java中的线程池ThreadPoolExecutor
ThreadPoolExecutor是线程池中基础类也是最为核心的类。想要了解和合理使用线程池绕不开ThreadPoolExecutor类。下面介绍一下此类。
该类的构造函数如下
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//...
}
线程池有这么几个重要的参数
-
corePoolSize: 线程池里的核心线程数量 -
maximumPoolSize: 线程池里允许有的最大线程数量 -
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。 默认情况下,如果当前线程数量>corePoolSize,多出来的线程会在keepAliveTime之后就被释放掉,直到线程池中的线程数不大于corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0 -
unit: keepAliveTime的时间单位,有7种单位-
TimeUnit.DAYS; //天 TimeUnit.HOURS; //小时 TimeUnit.MINUTES; //分钟 TimeUnit.SECONDS; //秒 TimeUnit.MILLISECONDS; //毫秒 TimeUnit.MICROSECONDS; //微妙 TimeUnit.NANOSECONDS; //月
-
-
workQueue: 队列 workQueue的类型为BlockingQueue<Runnable>,通常可以取下面三种类型:- 有界任务队列ArrayBlockingQueue:基于数组的先进先出队列,此队列创建时必须指定大小;
- 无界任务队列LinkedBlockingQueue:基于链表的先进先出队列,如果创建时没有指定此队列大小,则默认为Integer.MAX_VALUE;
- 直接提交队列synchronousQueue:这个队列比较特殊,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务。如果进程数量已经达到最大值,则执行拒绝策略。因此使用该队列需要设置很大的maximumPoolSize,否则很容易执行拒绝策略。
-
threadFactory: 每当需要创建新的线程放入线程池的时候,就是通过这个线程工厂来创建的 -
handler: 就是说当线程,队列都满了,之后采取的策略,比如抛出异常等策略- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,不做任何处理
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
二、 线程池中重要的方法
线程池有两个重要的操作,提交任务和关闭线程池。在讲述这两个操作之前先了解一下线程池的状态。注意!!!,线程池的状态而不是线程状态。
在ThreadPoolExecutor中定义了一个volatile变量,另外定义了几个static final变量表示线程池的各个状态:
//当前线程池的状态,voliate 保证了线程之间的可见 volatile int runState; //创建线程池后,初始时,线程池处于此状态 static final int RUNNING = 0; /*调用了shutdown()方法,则线程池处于SHUTDOWN状态,此时线程池不能够接受新的任务,它会等待所有任务执行完毕*/ static final int SHUTDOWN = 1; /*调用了shutdownNow()方法,则线程池处于STOP状态,此时线程池不能接受新的任务,并且会去尝试终止正在执行的任务*/ static final int STOP = 2; /*线程池处于SHUTDOWN或STOP状态,并且所有工作线程已经销毁,任务缓存队列已经清空或执行结束后,线程池被设置为TERMINATED状态*/ static final int TERMINATED = 3;
2.1 线程池提交任务
ThreadPoolExecutor的提交操作可以使用submit和execute这两种方法
2.1.1 excute
最核心的任务提交方法是execute()方法,虽然通过submit也可以提交任务,但是实际上submit方法里面最终调用的还是execute()方法 并且ExecutorService中的invokeAll(),invokeAny()都是调用的execute方法。execute提交的任务无返回值,因此无法判断任务是否执行成功。但是如果出现线程错误可以显示 部分异常堆栈信息
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 1.当前线程数量小于corePoolSize,则创建并启动线程。
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
// 成功,则返回
return;
c = ctl.get();
}
// 2.步骤1创建线程失败,则尝试把任务加入阻塞队列,
if (isRunning(c) && workQueue.offer(command)) {
// 入队列成功,检查线程池状态,如果状态部署RUNNING而且remove成功,则拒绝任务
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果当前worker数量为0,通过addWorker(null, false)创建一个线程,其任务为null
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3. 步骤1和2失败,则尝试将线程池的数量由corePoolSize扩充至maxPoolSize,如果失败,则拒绝任务
else if (!addWorker(command, false))
reject(command);
}
}
详细流程解读
- workerCountOf方法根据ctl的低29位,得到线程池的当前线程数,如果线程数小于corePoolSize,则执行addWorker方法创建新的线程执行任务;否则执行步骤(2);
- 如果线程池处于RUNNING状态,且把提交的任务成功放入阻塞队列中,则执行步骤(3),否则执行步骤(4)
- 再次检查线程池的状态,如果线程池没有RUNNING,且成功从阻塞队列中删除任务,则执行reject方法处理任务
- 执行addWorker方法 尝试将线程池的数量由corePoolSize扩充至maxPoolSize,如果addWoker执行失败,则执行reject方法处理任务;
2.1.2 sumbit
如果使用submit 方法来提交任务,它会返回一个future,那么我们可以通过这个future来判断任务是否执行成功,通过future的get方法来获取返回值,get方法会阻塞住直到任务完成,而使用 get(long timeout, TimeUnit unit) 方法则会阻塞一段时间后立即返回,这时有可能任务没有执行完。可以通过以下方式改造submit获得部分异常堆栈信息
try {
Future re = pools.submit(Task);
re.get();
} catch (InterruptedException e) {
// 处理中断异常
} catch (ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池
executor.shutdown();
}
2.2 线程池的关闭
使用线程池时,我们可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池,但是它们的实现原理不同。
-
- shutdown的原理是只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
- shutdownNow的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。shutdownNow会首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表。
只要调用了这两个关闭方法的其中一个,isShutdown方法就会返回true。当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回true。至于我们应该调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性决定,通常调用shutdown来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow。
三、线程池种类
常见的五种线程池
- newFixedThreadPool: 固定数量线程池,这个比较常用.可以指定线程池的大小,该线程池corePoolSize和maximumPoolSize相等,阻塞队列使用的是LinkedBlockingQueue,大小为整数最大值
- newSingleThreadExecutor: 单线程线程池,一般很少使用.
- newCachedThreadPool:缓存线程池,缓存的线程默认存活60秒,线程的核心池corePoolSize大小为0,核心池最大为Integer.MAX_VALUE,阻塞队列使用的是SynchronousQueue。
- newScheduledThreadPool:定时线程池,该线程池可用于周期性地去执行任务,通常用于周期性的同步数据。
- newWorkStealingPool:工作窃取线程池,该线程为jdk1.8版新增。
1. newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
这里思考一个问题为什么newFixedThreadPool的 corePoolSize 和 mamximumPoolSize设计为一样的?
答案可以从execute的源码中找到,首先线程池提交任务时是先判断 corePoolSize ,再判断 workQueue , 最后判断 mamximumPoolSize , 然而 LinkedBlockingQueue 是无界队列,所以它是达不到判断 mamximumPoolSize 这一步的,所以 mamximumPoolSize 成多少,并没有多大所谓。
下边简单的介绍一下newFixedThreadPool的使用
public class ThreadPoolDemo {
public static class MyTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ":ThreadID:" + Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask task = new MyTask();
ExecutorService es = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; ++i) {
es.submit(task);
}
}
}
这里创建了固定大小为5的线程,然后依次向线程池提交了10个任务。此后线程池就会安排调度这10个任务。每个任务都会将自己的执行时间和执行任务线程的Id打印出来,并且每一个任务执行时间为1秒
执行代码,输出如下
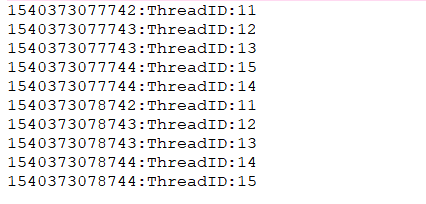
可以看出,前5个任务和后5个任务执行时间相差1秒,并且前五个和后五个ID是一致的。这说明任务是分两个批次执行。这也符合一个只有5个线程的线程池行为
2. newCachedThreadPool
该方法返回一个可根据实际情况调整线程数量大小的线程池,线程池的数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程,如果所有线程均在工作,又有新的任务被提交,
则会创建新的线程执行任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
这里可以看到 CachedThreadExecutor 的 mamximumPoolSize被 设计成接近无限大。
原因就是和synchronousQueue相关,上边已经简单介绍过该队列了,该队列的每个 put 必须等待一个 take,反之亦然。同步队列没有任何内部容量,甚至连一个队列的容量都没有。如果 mamximumPoolSize 不设计得很大,那么就很容易抛出异常。
所以,使用该线程池时,一定要注意控制并发的任务数,否则创建大量的线程可能导致严重的性能问题 。
3. newScheduledThreadPool
计划任务,和其他线程池不同,该线程池并不一定会立即安排任务,主要是起计划任务的作用。他会在指定时间、对任务进行调度。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize, ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue(), threadFactory);
}
- scheduleAtFixedRate:是以固定的频率去执行任务,周期是指每次执行任务成功执行之间的间隔。
- schedultWithFixedDelay:是以固定的延时去执行任务,延时是指上一次执行成功之后和下一次开始执行的之前的时间
4. newSingleThreadExecutor
单个线程线程池,只有一个线程的线程池,阻塞队列使用的是LinkedBlockingQueue,若有多余的任务提交到线程池中,则会被暂存到阻塞队列,待空闲时再去执行。按照先入先出的顺序执行任务。
public static ExecutorService newSingleThreadExecutor() {
return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory var0) {
return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), var0));
}
5. newWorkStealingPool
会根据所需的并行层次来动态创建一个拥有足够的线程数目的线程池。通过使用多个队列来降低竞争。并行的层次是和运行的最大线程数目相关。运行过程中实际的线程数目或许会动态地增长和收缩。
其本质是一个一个工作窃取的线程池,所以对于提交的任务不能保证是顺序执行的。底层用的ForkJoinPool来实现的。ForkJoinPool的优势在于,可以充分利用多cpu,多核cpu的优势,
把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器核心上并行执行;当多个“小任务”执行完成之后,再将这些执行结果合并起来即可。分治的思想。下面是newWorkStealingPool的构造函数
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool (parallelism,ForkJoinPool.defaultForkJoinWorkerThreadFactory,null, true);
}
//使用一个无限队列来保存需要执行的任务,可以传入线程的数量,不传入,则默认使用当前计算机中可用的cpu数量,使用分治法来解决问题,使用fork()和join()来进行调用
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler,boolean asyncMode) {
this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode ? FIFO_QUEUE : LIFO_QUEUE,"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
假设有3个线程A、B、C在运行,workStealing可以简单这么认为,每个线程都维护自己的一个队列,线程A的队列里头积累了3个任务,线程B的队列里2个任务,C的队列里1个任务;那么当线程C执行完任务之后,它会去别的线程池所维护的队列里面把任务偷过来继续执行,主动的找活干。
我们看一下newWorkStealingPool的使用案例
/**
* WorkStealingPool(任务窃取,都是守护线程)
* 每个线程都有要处理的队列中的任务,如果其中的线程完成自己队列中的任务,
* 那么它可以去其他线程中获取其他线程的任务去执行
*/
public class TestWorkStealingPool {
public static void main(String[] args) throws IOException {
// 根据cpu是几核来开启几个线程
ExecutorService service = Executors.newWorkStealingPool();
// 查看当前计算机是几核
System.out.println(Runtime.getRuntime().availableProcessors());
service.execute(new R(1000));
service.execute(new R(3000));
service.execute(new R(4000));
service.execute(new R(2000));
service.execute(new R(3000));
service.execute(new R(3000));
service.execute(new R(3000));
service.execute(new R(3000));
// WorkStealing是精灵线程(守护线程、后台线程),主线程不阻塞,看不到输出。
// 虚拟机不停止,守护线程不停止
System.in.read();
}
static class R implements Runnable {
int time;
public R(int time) {
this.time = time;
}
@Override
public void run() {
System.out.println(time + ":" + Thread.currentThread().getName() + "执行时间为:" + System.currentTimeMillis());
try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
结果输出

可以看到newWorkStealingPool执行时根据cpu核心分配线程数量,这里打印显示cpu核心数为4,明显的可以看出线程将前4 个任务扔给了1-4号线程,后四个任务在排队等待。当1-4号线程中某个线程最先执行完毕后
会自动窃取未执行的任务,这里可以看到1号线程最先执行完毕用时1000ms,然后就窃取第五个任务。第0号线程执行完毕后,又紧接着执行第六个任务....。依次类推,直到所有任务执行完毕。
四、线程池的使用建议
建议根据自己的需要手动创建线程池( new ThreadPoolExecutor(......) ),这样可以灵活使用线程池,并且可可以加深自己对线程池的理解。阿里巴巴开发手册和 Dubbo线程池的开发手册也是这样建议
Dubbo线程池的开发手册如下

阿里巴巴开发手册建议如下

我们可以看一下Dubbo怎么创建线程池的
@SPI("fixed")
public interface ThreadPool {
/**
* 线程池
*
* @param url 线程参数
* @return 线程池
*/
@Adaptive({Constants.THREADPOOL_KEY})
Executor getExecutor(URL url);
}
public class FixedThreadPool implements ThreadPool {
public Executor getExecutor(URL url) {
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
默认情况下,Dubbo的 FixedThreadPool 中, maximumPoolSize = 200 ,队列是容量很小的 SynchronousQueue .所以当线程超过200的时候,线程池就会抛出异常.
Linux公社的RSS地址 : https://www.linuxidc.com/rssFeed.aspx
本文永久更新链接地址: https://www.linuxidc.com/Linux/2019-08/159809.htm
正文到此结束
- 本文标签: 源码 阿里巴巴 key 同步 ACE IO 2019 ssh cat 遍历 dubbo 删除 executor 部署 java 进程 CTO 性能问题 http cache 并发 rmi 线程 时间 final ask constant zab linux 代码 volatile 进程数 Service 缓存 https IDE 开发 core 处理器 拒绝策略 mina 数据 参数 src queue 本质 db UI value ThreadPoolExecutor 线程池 id
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

