Gubernator 开源:高性能分布式限速微服务项目
近日,Mailgun 将 Gubernator 开源,这是一个高性能的分布式限速微服务。
Gubernator 的特性
- Gubernator 在整个集群中均匀地分布速率限制请求,这样用户就可以添加更多的节点来扩展系统。
- Gubernator 不依赖于 Memcache 或 Redis 等外部缓存,因此部署时不存在服务依赖。这使得在诸如 kubernetes 或 nomad 的编排系统中能动态增长或缩小集群。
- Gubernator 在磁盘上不保存状态,它的配置是由客户机根据每个请求传递给它的。
- Gubernator 提供了对其 API 的 GRPC 和 HTTP 访问。可以根据需要限制速率的陪伴服务运行,也可以作为独立的服务运行。
- 可以用作库来实现特定领域的限速服务。
- 支持对高吞吐量环境进行定制化的一致速率限制服务。
- Gubernator 是 俄语中 governor 的英文发音 ,听起来也很酷。
在正式开始讨论 Gubernator 的工作原理之前,先来回答大家关心最多的几个问题:
为什么不用 Redis 呢?
在评估 Redis 时,我们思考了很多东西:
- 即使使用 管道 ,使用基本的 Redis 速率限 制实现也会导致额外的网络往返。
- 我们可以使用 https://redis.io/commands/eval 和一个 LUA 脚本来减少往返,但我们需要为实现的每个算法维护这个脚本。
- 每一个独立的请求将导致至少一次往返于 Redis。再加上至少一次到我们微服务的往返,这意味着每个到我们服务的请求至少要两次往返。
Redis 的最优解决方案是编写一个 LUA 脚本来实现速率限制算法。然后,该脚本存储在 Redis 服务器上,并为每个速率限制请求调用。在这个场景中,大部分工作由 Redis 完成,而我们的微服务基本上是访问 Redis 的代理。在这种情况下,我们有两个选择:
- 创建 Gubernator 作为速率限制库,提供对 Redis 的访问,这个库将被所有需要限制速率的服务使用。
- 弃用 Redis,并在每个服务都使用瘦 GRPC 客户机的限速微服务中实现分布式、缓存和限制算法。
为什么用微服务?
Mailgun 是一家擅长多种开发语言的公司,我们的代码大部分都是用 python 和 golang 写的。如果我们选择将速率限制实现为一个库,这至少需要一个 python 和一个 golang 版本的库。我们以前在内部使用同一个库的 python 和 golang 版本时也采用过这种方法。根据我们的经验,跨服务共享库有以下缺点:
- 对库的 Bug 和特性更新最多可能导致对依赖项的更新。在最坏的情况下,它需要对所有使用库的服务进行修改,这些服务使用库中支持的所有语言。
- 开发人员很少希望用两种语言维护或编写新特性。假如两个并行的话,通常导致一个版本的库具有更多的特性,或者比另一个版本维护得更好。
随着微服务和语言应用数量在我们的生态系统中的不断增长,这些问题变得越来越复杂,也更糟糕。相比之下,GRPC 和 HTTP 库很容易为需要访问 Gubernator 的每种语言创建和维护。
对于微服务,可以添加 bug 更新和新特性,而不会破坏依赖的服务。只要不允许 API 中断更改,依赖服务就可以选择新特性,而不需要更新所有依赖服务。
Gubernator 作为微服务的主要特性是,它为进入系统的许多请求创建了一个同步点。在几微秒内接收到的请求可以被优化并协调成批,从而减少服务在重载下使用的总带宽和往返延迟。多个服务都运行在单个主机上,并且所有服务都在各自的进程中运行相同的库,但它们没有此功能。
为什么 Gubernator 是无状态的?
Gubernator 是无状态的,因为它不需要磁盘空间来操作。不需要任何配置或缓存数据同步到磁盘,这是因为对 Gubernator 的每个请求都包含速率限制的配置。
首先,你可能认为这对每个请求都是不必要的开销。然而,实际上,速率限制配置仅由 4 个 64 位整数组成。配置由限制、持续时间、算法和行为组成 (有关工作原理的详细信息,请参阅下面)。正是由于这种简单的配置,Gubernator 可以用来提供客户端可以使用的各种速率限制用例。其中一些用例如下:
- 入口限制:典型的基于 HTTP 的 402 多请求类型限制。
- 流量减少:当 API 处于不佳状态时,只拒绝新的或未经身份验证的请求。
- 出口限制:用数百万条消息轰炸外部 SMTP 服务器并非易事。
- 队列处理:知道何时可以立即处理请求,或者应该按照接收请求的顺序排队和处理请求。
- API 容量管理:对一个集合 API 系统能够处理的请求总数设置全局限制。拒绝或对违反系统正常操作能力的请求进行排队。
除了上面提到的用例,无配置设计对微服务的设计和部署有重要的影响:
- 部署时不用配置同步。当使用 Gubernator 的服务被部署时,不用预先部署到 Gubernator 的速率限制配置。
- 使用 Gubernator 的服务拥有其问题空间的速率极限域模型。这使得 Gubernator 无法获得领域特定的知识,因此 Gubernator 可以专注于它最擅长的事情——速率限制!
在这些问题之外,下面就从 Gubernator 的工作原理开始,讨论更多关于 Gubernator 的内容。
Gubernator 的工作原理
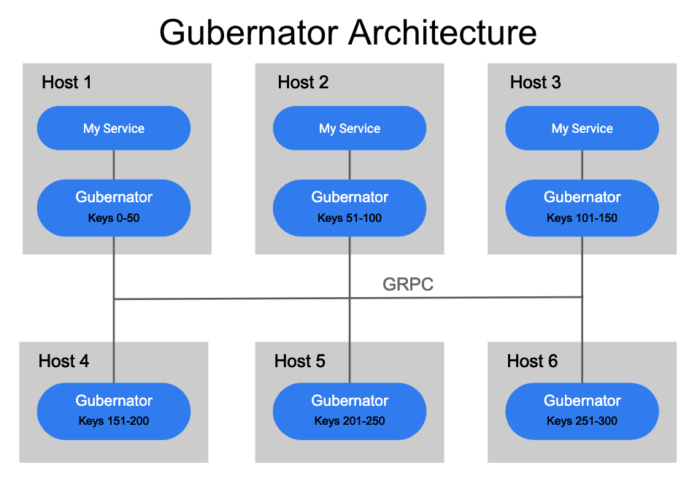
Gubernator 被设计成一个分布式的对等点集群,它利用了内存中所有当前活动速率限制的缓存,因为不用将数据同步到磁盘。由于大多数基于网络的速率限制持续时间只有几秒钟,因此在重启或计划停机期间丢失内存缓存并不是什么大问题。对于 Gubernator,我们选择性能而不是精度,因为在缓存丢失的情况下,一小部分流量在短时间内 (通常是几秒钟) 超过请求是可以接受的。
当向 Gubernator 发出速率限制请求时,将键入该请求并应用一致的哈希算法来确定哪个对等点将是速率限制请求的所有者。为速率限制选择单个所有者可以使计数的原子增量非常快,并且避免了在对等集群中一致地分布计数所涉及的复杂性和延迟。
尽管简单且性能良好,但是这种设计可能会受到一大堆请求的影响,因为一个协调器可能要处理成千上万个请求,而且速度有限。
为了解决这个问题,客户机可以请求 Behaviour=BATCHING,它允许对等点在指定的窗口内接受多个请求 (缺省值为 500 微秒),并将请求批处理为单个对等点请求,从而极大地减少了通过网络向单个 Gubernator 对等点发送请求的总数。
为了确保集群中的每个对等点准确地计算速率限制键的正确散列,必须以及时和一致的方式将集群中的对等点列表分发给集群中的每个对等点。目前,Gubernator 支持使用 etcd 或 kubernetes 端点 API 来发现 Gubernator 对等点。
Gubernator 操作
当客户机或服务向 Gubernator 发出请求时,客户机将为每个请求提供速率限制配置。然后,速率限制配置与当前速率限制状态一起存储在速率限制所有者的本地缓存中。存储在本地缓存中的速率限制及其配置仅在速率限制配置的指定持续时间内存在。
在持续时间过期之后,如果在此期间没有再次请求速率限制,则从缓存中删除它。对相同名称和 unique_key 对的后续请求将在缓存中重新创建配置和速率限制,这个循环将重复。另一方面,具有不同配置的后续请求将覆盖以前的配置并立即应用新配置。
通过 GRPC 发送的速率限制请求示例如下所示:
复制代码
rate_limits: # Scopes the request to a specific rate limit - name:requests_per_sec # A unique_key that identifies this rate limit request unique_key:account_id=123|source_ip=172.0.0.1 # The number of hits we are requesting hits:1 # The total number of requests allowed for this rate limit limit:100 # The duration of the rate limit in milliseconds duration:1000 # The algorithm used to calculate the rate limit # 0 = Token Bucket # 1 = Leaky Bucket algorithm:0 # The behavior of the rate limit in gubernator. # 0 = BATCHING (Enables batching of requests to peers) # 1 = NO_BATCHING (Disables batching) # 2 = GLOBAL (Enable global caching for this rate limit) behavior:0
下面是一个例子:
复制代码
rate_limits: # The status of the rate limit. OK = 0, OVER_LIMIT = 1 - status:0, # The current configured limit limit:10, # The number of requests remaining remaining:7, # A unix timestamp in milliseconds of when the rate limit will reset, # or if OVER_LIMIT is set it is the time at which the rate limit # will no longer return OVER_LIMIT. reset_time:1551309219226, # Additional metadata about the request the client might find useful metadata: # This is the name of the node that owns this request "owner":"api-n03.staging.us-east-1.mailgun.org:9041"
Global Behavior
由于 Gubernator 速率限制是由集群中的单个对等点哈希和处理的,所以适用于数据中心中的每个请求的速率限制将导致单个对等点处理整个数据中心的速率限制请求。
例如,考虑 name=requests_per_datacenter 和 unique_id=us-east-1 的速率限制。现在,假设对每个进入 us-east-1 数据中心的 HTTP 请求都使用这个速率限制向 Gubernator 发出请求。这可能是每秒数十万个请求,甚至可能是数百万个请求,这些请求都由集群中的一个对等点哈希并处理。由于这个潜在的可伸缩性问题,Gubernator 引入了一个名为 GLOBAL 的可配置 behavior。
当速率限制配置为 behavior=GLOBAL 时,从客户机接收到的速率限制请求将不会转发给拥有它的对等方。相反,它将从接收请求的对等方处理的内部缓存中得到响应。Hits 速率限制的点击率将由接收对等点批量处理,并异步发送到拥有该点击率的对等点,在该对等点上,点击率将被总计并得出 OVER_LIMIT。然后,拥有节点的节点有责任用速率限制的当前状态更新集群中的每个节点,这样,节点内部缓存就会定期从所有者那里获得最新速率限制状态的更新。
Global Behavior 的其他影响
由于 Hits 是批量处理并异步转发给拥有它的对等点的,所以对客户机的即时响应将不包括最精确的 remaining 计数。只有在对所有者对等点的异步调用完成并且拥有对等点有时间更新集群中的所有对等点之后,该计数才会得到更新。因此,使用 GLOBAL 允许更大的集群规模,但要以一致性为代价。如果集群足够大,使用 GLOBAL 可以增加每速率限制请求的通信量。 GLOBAL 应该只用于与传统的非 GLOBAL 行为不兼容的高容量速率限制。
Gubernator 性能
在我们的生产环境中,每向我们的 API 发送一个请求,我们就向 Gubernator 发送两个速率限制请求来评估速率限制;一个用于对 HTTP 请求进行评级,另一个用于对用户在特定时间内也可以发送电子邮件的收件人数量进行评级。在这种设置下,一个 Gubernator 节点每秒处理超过 2000 个请求,大多数批量响应在 1 毫秒内返回。
转发给拥有节点的对等请求通常在 30 微秒内响应。
- NOTE
- The
- above
- graphs
- only report
- the slowest
- request
- within the
- 1 second
- sample
- time. So
- you are
- seeing the
- slowest
- requests
- that
- Gubernator
- fields to
- clients.
由于许多面向公众的 API 都是用 python 编写的,所以我们在一个节点上运行许多 python 解释器实例。这些 python 实例将本地请求转发给 Gubernator 实例,然后 Gubernator 实例将请求批处理并转发给拥有节点的节点。
Gubernator 允许用户选择非批处理行为,这将进一步减少客户机速率限制请求的延迟。但是,由于吞吐量需求,我们的生产环境使用默认的 500 微秒窗口使用 Behaviour=BATCHING。在生产中,我们观察到在 API 使用高峰期间,批处理大小为 1000。其他不具有相同高流量需求的用户可以禁用批处理,并以吞吐量为代价降低延迟。
Gubernator 用作库
如果使用 Golang,可以使用 Gubernator 作为库。如果你希望在顶部实现一个公司特有模型的速率限制服务,这是非常有用的。我们在 Mailgun 内部有一项名为“ratelimits”的服务,专门跟踪每个账户的限额。通过这种方式,你可以利用 Gubernator 的强大功能和速度,同时可以分层业务逻辑,并将特定领域的问题集成到速率限制服务中。
使用库后,你的服务将成为集群的正式成员,与独立的 Gubernator 服务器一样参与一致的散列和缓存。你所需要做的就是提供 GRPC 服务器实例,并告诉 Gubernator 集群中的对等点位于何处。
结论
使用 Gubernator 作为通用的速率限制服务,允许我们依赖于微服务体系结构,而不会损害服务独立性和公共速率限制解决方案所需的重复工作。我们希望通过开源这个项目,与其他人共同合作,也让他们从中受益。
原文链接:
Gubernator: Cloud-Native Distributed Rate Limiting For Microservices正文到此结束
- 本文标签: dist cache 一致性 微服务 定制 find 管理 key client Service 模型 缓存 服务器 IDE 实例 Uber python 分布式 哈希算法 https redis Kubernetes 同步 ACE id 回答 ip 数据 空间 删除 希望 token mail UI 时间 http MQ Lua db 配置 需求 开源 主机 工作原理 bug 部署 node 集群 代码 开发 src IO 专注 tag unix 进程 API 缩小
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

