聊聊 Java 并发——基石篇(上)
导读
声明:本文所有的分析内容基于 OpenDK 的 java 11 版本的 HotSpot JVM 源代码。
由于知乎专栏的字数限制,本文分为:上、中、下三部分:
createchance:Java 并发——基石篇(上)
createchance:Java 并发——基石篇(中)
createchance:Java 并发——基石篇(下)
在阅读本文之前,你需要:
- 了解 Java 中的基本的线程使用方式以及注意点
- 了解 Java 中的基本线程间通讯的方式
- 了解 Java 中的 volatile 的基本语义
- 了解 C/C++ 编程
- 了解 JNI 的相关开发知识
- 了解一些 x86 的汇编(仅仅是很简单的内容,要求能读懂)
本文重点分析内容:
- 共享内存多核系统基本架构与设计
- Java 内存模型设计
- Java Thread 的创建与停止
- Java synchonized 的实现机制
- Java Object 的 wait 和 notify/notifyAll 实现机制
- Java volatile 关键字的实现方式
阅读建议:
- 下载一份 HotSpot JVM 11 的代码,了解基本代码架构,并且本地能够编译和调试,如何编译或者调试可以参考 OpenJDK wiki 或者 周志明的《深入理解 Java 虚拟机:第二版》一书
- 使用你熟悉的 IDE 导入 JVM 的源码,建议使用 eclipse CDT,其他的 IDE 笔者都觉得不是很方便
- 在阅读的过程中,不能仅仅看本文的分析,需要结合起来,自己下断点或者打印日志调试,并且不断反复尝试,反复理解核心代码片段
- 最后一点建议,现代 JVM 的实现非常复杂,会涉及到很多的操作系统、算法、硬件、统设计以及性能调优等等方面的知识,所以在阅读源码的时候千万不要深入无关代码的细节部分,否则你会陷于无边无际的代码海洋而无法自拔~
本文非常长,笔者写了一个多星期,纯属手打,文中的观点和分析均是本人经过反复的试验和分析得出的,同时借鉴了很多网络上的文章,这些借鉴的内容已经放到文末的参考资料中,在此非常感谢这些作者的分享。真心希望你可以认真读完,我敢保证,只要你认真读完,肯定收获很多,加油~
概要
并行是这个时代的主旋律,也是很多现代操作系统需要提供的必备功能。在过去摩尔定律催生下,单个 CPU 核心计算的速度越来越快。但是随着产业的发展,单个 CPU 核心的计算上限已经难以突破,传统的加强单核的思维模式已经不能满足需求。在古代,人们需要强大的战马驱动战车,为了能够使得战斗力越来越强,人们驯化出了越来越强劲的战马,但是单匹马的力量始终是有限的,因此人们发明了多马并驾的战车结构,大量出现的多乘战车产催生了强大的万乘之国。同样地,在现代计算机领域,人们在单个 CPU 核心能力有限的情况下,使用多个核心的 CPU 进行并行计算,以驱动强大的算力。
但是,多 CPU 和多战马是远远不同的,在现实世界中的计算任务大多需要互相协调,其根本原因是人类的思维方式就是线性串行的,设计一个完全并行的计算逻辑体系还是有相当大难度的。
如何设计一个高并发的程序,不仅仅是工程界的难题,在计算机学术界也是一个需要不断突破的研究领域。从学术理论提出,到算法设计,再到工程实施,再到产业验证调优,整个流程都需要比较长的时间来进行迭代,究其根本,并行计算本身就是非常复杂、不确定的、不可预测的逻辑系统。
多核系统中的一致性
号称一次编写,到处运行的 Java,其本身也是构建在不同的系统之上的,以其运行时 JVM 来屏蔽系统底层的差异。因此,在介绍 Java 并发体系之间,有必要简要介绍下计算机系统层面上的并发,以及面对的问题。
我们的目的其实很简单,就是让计算机在同一时刻,能够运行更多的任务。而并行计算,提供了非常不错的解决方案。虽然这看起来很自然,但实际上面临着众多的问题,其中一个重大的问题就是绝大多数的计算不仅仅是 CPU 一个人的事,而是需要很多计算机系统部件共同参与。但是我们知道,计算机系统中运行速度最快就是 CPU,其他部件例如:内存、磁盘、网络等等都是及其缓慢的,同时这些操作在目前的计算机体系中是很难消除的,因为我们不可能仅仅靠寄存器就完成所有的计算任务。面对高速 CPU 和低速存储之间的鸿沟,如果想要实现高效数据通讯,一个良好的解决方案就是在它们之间添加一个 cache 层,这个 cache 层的速度和整体的速度关系如下:
复制代码
CPU-->cache-->存储
通过 cache 这个缓冲地带,实现 CPU 和存储之间的高效「对话」。这是计算机和软件领域通用的一个问题解决方案:增加中间层。没有什么问题是一个中间层解决不了的,如果有,那就两层。在运算的时候,CPU 将需要使用到的数据复制到 Cache 中,以后每次获取数据都从较为快速的 cache 中获取,加快访问速度。
所谓理想很丰面,现实很骨感。这种计算体系有一个重要的问题需要解决,那就是:缓存一致性(cache coherence)问题。在现代的计算机系统中,主要都是多核系统为主。在这些计算机系统中,每一个 CPU 都拥有自己独立的高速缓存,但是因为主存只有一个,因此它们之间只能共享,这种系统也称为:共享内存多核系统(Shared-Memory multiprocessors System),如下图所示:
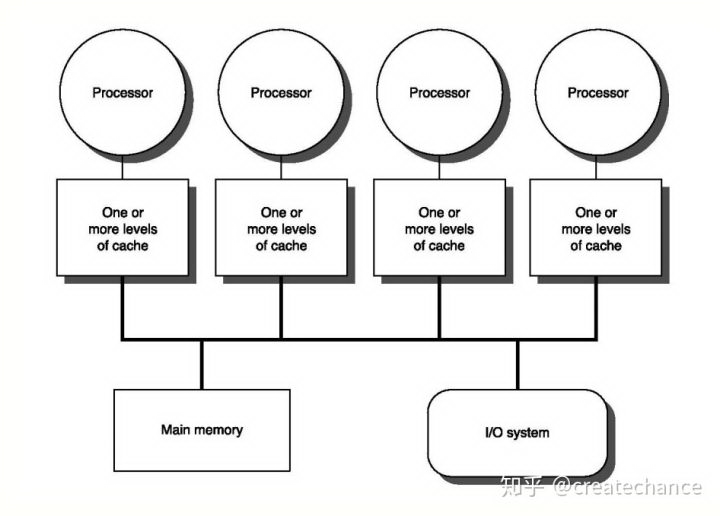
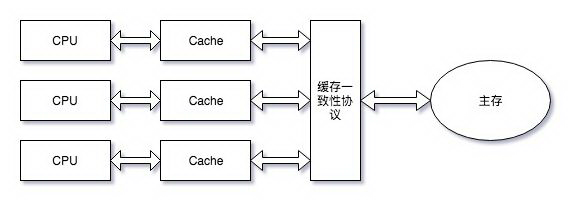
因此,当多个处理器同时需要访问同一个内存区域的数据时,首先回去访问 CPU 的 cache 区域中的数据,但是 cache 中的数据也是从共享内存中获取的,此时如果别的 CPU 修改了 cache 中的数据,那么就造成了数据不一致的问题了。因此,如果发生了这种「数据竞态」的问题,到底该以哪个数据为准呢?此时,我们需要一个一致性协议来保证。各个 CPU 在操作的时候都需要遵守缓存一致性协议来进行操作,这类型的协议有很多,例如:MSI、MESI、MOSI、Synapse、Firefly 以及 Dragon Protocol 等等。所以,通常情况下,共享内存多核系统的架构如下所示:
除了使用高速 cache 来缓和 CPU 和存储设备之间的速度鸿沟,为了能够充分利用多核 CPU 的处理性能,处理在实际执行机器指令时并不一定会按照程序设定的指令顺序执行,可能存在代码乱序执行(Out-Of-Order Execution)优化。注意,这里虽然乱序执行了,但是系统会保证执行的结果逻辑上的正确的,从宏观上看就好像是顺序执行一样。举个例子,比如我们有如下代码:
复制代码
int a= value1; int b= value2;
这两句话实际的执行顺序可能是先赋值 a 然后赋值 b,但是也可能反过来,反正这两句话执行完毕之后 a 和 b 的值都被赋值上了就可以,这里对外表现为顺序串行执行,这其实就是 as-serial 协议保证的。为什么需要这样?一方面这两句话本身并没有什么逻辑上的依赖性,完全可以并行执行;另一方面,如果我们傻傻地按照顺序执行的话,在执行第一句话的时候,我们可能需要从主存中读取 value1 的值,这种操作对于 CPU 来讲是及其缓慢的操作,如果我们顺序执行的话,那么就只能等待 value1 值读取成功之后才能继续执行下面的指令,这样就造成了 CPU 的空等待,白白浪费了资源。
Java 内存模型
上面我们探讨了共享内存多核系统的内存模型,我们提到了高速缓存以及缓存一致性问题,同时还介绍了指令乱序执行的问题。其实,这些概念在 Java 中也是存在的。因为 Java 的目标是:一次编写,到处运行。每一个计算机系统或者操作系统都会有自己特殊的内存模型,如果 Java 想要实现一次编写到处运行的目标,就必须在 JVM 层面上将系统之间的差异屏蔽掉。面对如此多的系统,最好的方式就是定义一套 Java 自己的内存访问模型,然后在不同的硬件平台和操作系统上分别利用本地接口来实现。这里的思想其实和增加 cache 是一样的,通过增加中间层来解决系统差异带来的协作问题。
Java 在 1.5 版本中引入了 JSR 133 标准 ,这个标准提出了 Java 中的并发内存模型和线程规范,这个标准的发布标志着 Java 拥有独立于系统平台的并发内存模型。和 C/C++ 不同的是,Java 并没有直接操作系统平台中的内存模型,而是自己定义了一套机制,这套机制包含了并发访问机制、缓存一致性协议以及指令重排序解决方案等内容。在 JSR 133 标准中,定义了如下的 Java 并发内存模型:
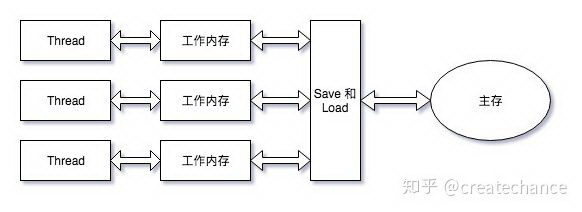
可以看到,这里的内存模型和上面讲到的计算机系统中的内存模型是十分类似的。在 JVM 中,并发的最小单位是 Thread,在不考虑 JVM 线程实现细节上,可以简单认为一个 Thread 对应一个内核线程,这样就可以进而认为 Thread 对应一个 CPU 核心。这里需要注意的是,工作内存和 Java 内存区域中的堆、栈或者方法区(java 和 native)等并不是一个层面上的东西,它们之间也没有直接的对应关系。同时,很多人会误以为这里的工作内存其实就是 TLAB (thread local allocation buffers),字面上看起来很像,但是没有任何关系的。
从上面的图中,可以看出每个线程的工作内存和主存之间的一致性保证是通过 save 和 load 等等一系列的操作完成的。JSR 133 早期版本中定义了 8 种操作(早期版本的描述可以参考: Thread and Locks ),但是后来处于描述简化以及方便不同 JVM 实现修为了 4 种操作,但是只是描述上的修改,内存模型基本设计并没有改变(周志明的书中有描述,感谢这本书的指点)。这里我们采用最新版本的 4 种操作来描述,这种方式比较清晰易懂。这 4 种操作和 Java 内存模型的对应关系如下图:
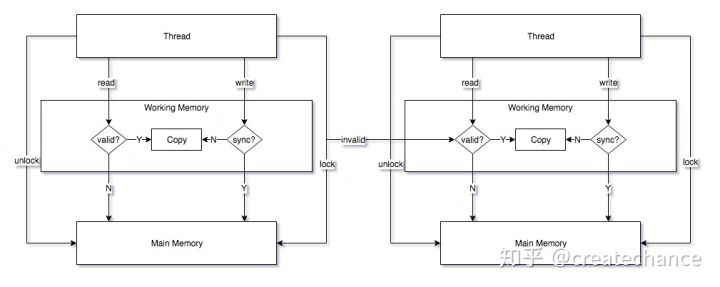
下面分别介绍下上面图中涉及的 4 种操作:
- read:Java 执行引擎访问本地工作内存中的变量副本,如果变量副本无效(变量副本不存在也是无效的一种),那就去主存中获取,同时在本地工作内存中缓存一份
- write:Java 执行引擎将最新的变量值赋值给工作内存中的变量副本,同时需要判断是否需要将这个新的值立即同步给主内存,如果需要同步的话,还需要配合 lock 操作
- lock:Java 执行引擎将主内存中的变量锁定,锁定的含义有:其他的线程在此之后不能访问这个变量直到本线程 unlock;一旦锁定,其他线程针对这个变量的操作必须等待
- unlock:Java 执行引擎将主内存中的变量解锁,解锁之后才能:各个线程并发访问这个变量;某个线程再次锁定
Java Thread 创建
在 Java 中,我们都知道,一个线程直接对应了一个 Thread 类对象。创建和启动一个线程是比较容易的,我们只需要创建一个 Thread 对象,然后调用对象的 start 方法即可。但是在创建一个 Thread 对象和启动线程 JVM 中究竟发生了什么?本节我们就来看下。
如果你仔细看过 Thread 类的源码就知道,在创建一个 Thread 对象的时候,除了一些初始化设置之外就没有什么实质性的操作,真正的工作其实是在 start 方法调用中产生的。也就是说,只是创建了一个 Thread 对象和创建一个普通的 Java 对象没什么实质性的差异。因此我们需要看下在 HotSpot 11 中的 Thread start 实现,那么怎么找实现的代码呢?打开 Thread 类的代码,在这个类开始的地方我们看到了如下的代码:
复制代码
/* Make sure registerNatives is the first thing <clinit> does. */
privatestaticnativevoidregisterNatives();
static{
registerNatives();
}
如果你熟悉 JNI 的话,就知道这里的 registerNatives 方法就是将 Thread 类中的 java 方法和一个本地的 C/C++ 函数进行对应,同时由于这个方法是类加载的时候调用的,因此在类首次加载的时候(Bootstrap 类加载)就会注册这些 native 方法,那么 Thread 中都有哪些 native 方法呢?看下 Thread 类的结尾处(JDK 源码中一般都是将 native 方法声明在类的结尾处,方便查找):
复制代码
publicstaticnativeThreadcurrentThread(); publicstaticnativevoidyield(); publicstaticnativevoidsleep(longmillis)throwsInterruptedException; privatenativevoidstart0(); privatenativebooleanisInterrupted(booleanClearInterrupted); publicfinalnativebooleanisAlive(); publicnativeintcountStackFrames(); publicstaticnativebooleanholdsLock(Object obj); privatestaticnativeStackTraceElement[][] dumpThreads(Thread[] threads); privatestaticnativeThread[] getThreads(); privatenativevoidsetPriority0(intnewPriority); privatenativevoidstop0(Object o); privatenativevoidsuspend0(); privatenativevoidresume0(); privatenativevoidinterrupt0(); privatenativevoidsetNativeName(String name);
这些方法,不用说你肯定非常熟悉,这里就不赘述了。
在进入代码量及其巨大且复杂的 OpenJDK 之前有几点想说明下:
- 所有用的源代码都是从 OpenJDK 官方下载的 HotSpot JVM 代码,版本 11
- 分析的时候我会将代码中的注释一起放上来,方便大家阅读
- 分析的时候,我们只关注重点的代码,也就是核心功能代码,细节暂时不会关心
好的,现在我们打开 OpenJDK 11 的代码(至于下载源码,请参考 OpenJDK wiki ;使用什么 IDE 打开全看你的心情,我是使用 eclipse cdt),全局搜索如下内容:
复制代码
java_lang_Thread_registerNatives
什么?你问我为啥搜这个?如果你有这个疑问的话,可以先看下 JNI 的内容 ~这里简单地说下,这种内容是 JNI 默认的 java 方法和 native 方法对应的方式,JVM 运行的时候会通过这种方式查找本地符号表中的符号的符号,然后直接跳转过去~
我们搜索之后可以看到在 src/java.base/share/native/libjava/Thread.c 中定了这个函数:
复制代码
staticJNINativeMethodmethods[] = {
{"start0","()V", (void *)&JVM_StartThread},
{"stop0","("OBJ")V", (void *)&JVM_StopThread},
{"isAlive","()Z", (void *)&JVM_IsThreadAlive},
{"suspend0","()V", (void *)&JVM_SuspendThread},
{"resume0","()V", (void *)&JVM_ResumeThread},
{"setPriority0","(I)V", (void *)&JVM_SetThreadPriority},
{"yield","()V", (void *)&JVM_Yield},
{"sleep","(J)V", (void *)&JVM_Sleep},
{"currentThread","()"THD, (void *)&JVM_CurrentThread},
{"countStackFrames","()I", (void *)&JVM_CountStackFrames},
{"interrupt0","()V", (void *)&JVM_Interrupt},
{"isInterrupted","(Z)Z", (void *)&JVM_IsInterrupted},
{"holdsLock","("OBJ")Z", (void *)&JVM_HoldsLock},
{"getThreads","()["THD, (void *)&JVM_GetAllThreads},
{"dumpThreads","(["THD")[["STE, (void *)&JVM_DumpThreads},
{"setNativeName","("STR")V", (void *)&JVM_SetNativeThreadName},
};
JNIEXPORTvoidJNICALL
Java_java_lang_Thread_registerNatives(JNIEnv*env,jclasscls)
{
(*env)->RegisterNatives(env, cls, methods, ARRAY_LENGTH(methods));
}
可以看到,在 registerNatives 函数中,向虚拟机注册了很多的本地方法,基本就是上面我们提到的 Thread 中的所有 native 方法。JNINativeMethod 这是个函数指针,定义在 JNI 中,内容如下:
复制代码
/*
* usedinRegisterNativestodescribe nativemethodname, signature,
*andfunctionpointer.
*/
typedefstruct{
char*name;
char*signature;
void *fnPtr;
}JNINativeMethod;
现在,我们知道了,第一列是 Java 中定义的 native 方法名称,第二列是 Java 方法签名,第三列是本地方法对应函数。因此,Java 中的 start 方法就是对应 native 的 JVM_StartThread 函数:
复制代码
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JVMWrapper("JVM_StartThread");
JavaThread *native_thread =NULL;
// We cannot hold the Threads_lock when we throw an exception,
// due to rank ordering issues. Example: we might need to grab the
// Heap_lock while we construct the exception.
bool throw_illegal_thread_state =false;
// We must release the Threads_lock before we can post a jvmti event
// in Thread::start.
{
// Ensure that the C++ Thread and OSThread structures aren't freed before
// we operate.
MutexLocker mu(Threads_lock);
// Since JDK 5 the java.lang.Thread threadStatus is used to prevent
// re-starting an already started thread, so we should usually find
// that the JavaThread is null. However for a JNI attached thread
// there is a small window between the Thread object being created
// (with its JavaThread set) and the update to its threadStatus, so we
// have to check for this
if(java_lang_Thread::thread(JNIHandles::resolve_non_null(jthread)) !=NULL) {
throw_illegal_thread_state =true;
}else{
// We could also check the stillborn flag to see if this thread was already stopped, but
// for historical reasons we let the thread detect that itself when it starts running
jlong size =
java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread));
// Allocate the C++ Thread structure and create the native thread. The
// stack size retrieved from java is 64-bit signed, but the constructor takes
// size_t (an unsigned type), which may be 32 or 64-bit depending on the platform.
// - Avoid truncating on 32-bit platforms if size is greater than UINT_MAX.
// - Avoid passing negative values which would result in really large stacks.
NOT_LP64(if(size > SIZE_MAX) size = SIZE_MAX;)
size_t sz = size >0? (size_t) size :0;
// 重点看这里!!!
native_thread =newJavaThread(&thread_entry, sz);
// At this point it may be possible that no osthread was created for the
// JavaThread due to lack of memory. Check for this situation and throw
// an exception if necessary. Eventually we may want to change this so
// that we only grab the lock if the thread was created successfully -
// then we can also do this check and throw the exception in the
// JavaThread constructor.
if(native_thread->osthread() !=NULL) {
//Note:the current thread is not being used within "prepare".
native_thread->prepare(jthread);
}
}
}
if(throw_illegal_thread_state) {
THROW(vmSymbols::java_lang_IllegalThreadStateException());
}
assert(native_thread !=NULL,"Starting null thread?");
if(native_thread->osthread() ==NULL) {
// No one should hold a reference to the 'native_thread'.
native_thread->smr_delete();
if(JvmtiExport::should_post_resource_exhausted()) {
JvmtiExport::post_resource_exhausted(
JVMTI_RESOURCE_EXHAUSTED_OOM_ERROR | JVMTI_RESOURCE_EXHAUSTED_THREADS,
os::native_thread_creation_failed_msg());
}
THROW_MSG(vmSymbols::java_lang_OutOfMemoryError(),
os::native_thread_creation_failed_msg());
}
Thread::start(native_thread);
JVM_END
上面代码本身并不多,并且有很多的注释,这样我们就能很好地理解这段代码了。我们要关注的重点是这一行:
复制代码
native_thread =newJavaThread(&thread_entry,sz);
这里创建了一个 JavaThread 对象,并且给了两个参数,第一个暂且不管,后面我们会重点说明,第二个是 stack size,也就是每一个线程的栈大小,这个参数可以在创建 Thread 对象的时候指定,也可以添加 JVM 启动参数:-XSS。进去看下:
复制代码
JavaThread::JavaThread(ThreadFunctionentry_point,size_tstack_sz):
Thread(){
initialize();
_jni_attach_state = _not_attaching_via_jni;
set_entry_point(entry_point);
// Create the native thread itself.
// %note runtime_23
os::ThreadType thr_type = os::java_thread;
thr_type = entry_point==&compiler_thread_entry ? os::compiler_thread :
os::java_thread;
// 通过 os 类的 create_thread 函数来创建一个线程
os::create_thread(this,thr_type,stack_sz);
// The _osthread may be NULL here because we ran out of memory (too many threads active).
// We need to throw and OutOfMemoryError - however we cannot do this here because the caller
// may hold a lock and all locks must be unlocked before throwing the exception (throwing
// the exception consists of creating the exception object & initializing it, initialization
// will leave the VM via a JavaCall and then all locks must be unlocked).
//
// The thread is still suspended when we reach here. Thread must be explicit started
// by creator! Furthermore, the thread must also explicitly be added to the Threads list
// by calling Threads:add. The reason why this is not done here, is because the thread
// object must be fully initialized (take a look at JVM_Start)
}
可以看到,重点是通过 os 类的 create_thread 函数来创建一个线程,因为 JVM 是跨平台的,并且不同操作系统上的线程实现机制可能是不一样的,因此这里的 create_thread 肯定会有多个针对不同平台的实现,我们查看这个函数的实现就知道了:

可以看到,HotSpot 提供了主要的操作系统上的实现,因为在服务器上,linux 的占比是很高的,因此我们这里就看下 linux 上的实现即可:
复制代码
bool os::create_thread(Thread*thread, ThreadType thr_type,
size_t req_stack_size) {
...
// init thread attributes
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
// Calculate stack size if it's not specified by caller.
size_t stack_size = os::Posix::get_initial_stack_size(thr_type, req_stack_size);
// In the Linux NPTL pthread implementation the guard size mechanism
// is not implemented properly. The posix standard requires adding
// the size of the guard pages to the stack size, instead Linux
// takes the space out of 'stacksize'. Thus we adapt the requested
// stack_size by the size of the guard pages to mimick proper
// behaviour. However, be careful not to end up with a size
// of zero due to overflow. Don't add the guard page in that case.
size_t guard_size = os::Linux::default_guard_size(thr_type);
if(stack_size <= SIZE_MAX - guard_size) {
stack_size += guard_size;
}
assert(is_aligned(stack_size, os::vm_page_size()),"stack_size not aligned");
int status = pthread_attr_setstacksize(&attr, stack_size);
assert_status(status ==0, status,"pthread_attr_setstacksize");
// Configure glibc guard page.
pthread_attr_setguardsize(&attr, os::Linux::default_guard_size(thr_type));
...
pthread_t tid;
// 创建并启动线程
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) thread_native_entry,thread);
...
}
这个函数比较长,这里就省略部分,只保留和线程创建启动相关的部分。可以看到,在 linux 平台上,JVM 的线程是通过大名鼎鼎的 pthread 库来创建启动线程的,这里需要注意下的是,在指定线程栈大小的时候,并不是程序员指定多少就实际是多少的,而是要根据系统平台的限制来综合决定的。
到这里,我们大致上明白了,Java Thread 在底层是对应到一个 pthread 线程。这里有一个问题,就是底层是如果执行我们指定的 run 方法的呢?我们先看下创建并且启动线程的这一行:
复制代码
pthread_t tid; // 创建并启动线程 int ret = pthread_create(&tid, &attr, (void*(*)(void*)) thread_native_entry, thread);
这里通过 pthread_create 来创建并且启动线程,我们看下这个接口的定义:
复制代码
int pthread_create(pthread_t *thread,constpthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
第一个是 pthread_t 结构体数据指针,存放线程信息的,第二个是线程的属性,第三个是线程体,也就是线程实际执行的函数,第四个是线程体的参数列表。
上面调用这个接口的地方,我们指定了线程体函数是 thread_native_entry,参数是 thread 指针。我们先看下 thread_native_entry 这个函数的定义:
复制代码
// Thread start routine for all newly created threads
staticvoid*thread_native_entry(Thread*thread) {
...
// call one more level start routine
thread->run();
...
}
同样地,这里省略了很多代码,只保留的重点代码。通过注释我们可以知道,thread->run() 这一行是最可能执行我们 run 方法的地方。所以问题的重点是,thread 指针指向了谁?并且 run 函数的实现是怎样的?我们知道 thread 指针是我们传递进来的,因此通过往回寻找代码我们发现在创建线程的时候我们执行了如下调用(如果你还记得的话):
复制代码
os::create_thread(this,thr_type,stack_sz);
这里我们将 thread 指针赋值为 this,this 就是 JavaThread 对象,还记得吗?我们前面就是通过创建 JavaThread 对象来创建和启动线程的。所以,我们现在看下 JavaThread 类的 run 函数:
复制代码
// The first routine called by a new Java thread
voidJavaThread::run() {
...
// We call another function to do the rest so we are sure that the stack addresses used
// from there will be lower than the stack base just computed
thread_main_inner();
}
这里重点是调用了 thread_main_inner 函数:
复制代码
void JavaThread::thread_main_inner() {
assert(JavaThread::current() ==this,"sanity check");
assert(this->threadObj() != NULL,"just checking");
// Execute thread entry point unless this thread has a pending exception
// or has been stopped before starting.
// Note: Due to JVM_StopThread we can have pending exceptions already!
if(!this->has_pending_exception() &&
!java_lang_Thread::is_stillborn(this->threadObj())) {
{
ResourceMark rm(this);
this->set_native_thread_name(this->get_thread_name());
}
HandleMark hm(this);
// 这里开始调用 java thread 的 run 方法啦~~~
this->entry_point()(this,this);
}
DTRACE_THREAD_PROBE(stop,this);
// java 中的 run 方法执行完毕了,这里需要退出线程并清理资源
this->exit(false);
// delete cpp 的对象
this->smr_delete();
}
这里就是我们的函数执行体了!!Java Thread 中的 run 方法是在 this->entry_point()(this, this); 这里调用的。看这里的调用方式就知道,entry_point() 返回的是一个函数指针,然后直接执行了调用。entry_point 函数实现如下:
复制代码
ThreadFunctionentry_point()const{return_entry_point; }
这里直接放回了 _entry_point 的 ThreadFunction 类型指针,ThreadFunction 类型其实就是函数指针:
复制代码
typedef void (*ThreadFunction)(JavaThread*,TRAPS);
因此,重点就是这里的 _entry_point 是哪里赋值的?这里就需要提到前面埋下的一个坑,在创建 JavaThread 对象的时候,我们传递了一个函数指针 thread_entry:
复制代码
native_thread =newJavaThread(&thread_entry,sz);
现在我们在来看 JavaThread 中对 thread_entry 的处理:
复制代码
JavaThread::JavaThread(ThreadFunctionentry_point,size_tstack_sz):
Thread(){
...
set_entry_point(entry_point);
...
}
ok,看到这里,我们明白了上面我们需要寻找的 _entry_point 其实就是 thread_entry 指针!
现在看下 thread_entry 指针指向的函数:
复制代码
staticvoidthread_entry(JavaThread*thread, TRAPS) {
HandleMark hm(THREAD);
Handleobj(THREAD,thread->threadObj());
JavaValue result(T_VOID);
JavaCalls::call_virtual(&result,
obj,
SystemDictionary::Thread_klass(),
vmSymbols::run_method_name(),
vmSymbols::void_method_signature(),
THREAD);
}
这里就是调用我们 java 中 run 方法的地方,但是好像不能很直观的看出来。我们需要解释一下 call_virtual 函数调用的几个参数,第一个是存放函数执行结果的,因为 java Thread 中的 run 是 void 型的,所以不必关心;第二个是 java thread object 对象;第三个是 java Thread class 对象;第四个就是我们 run 方法的名称,其实就是字符串“run”,第五个是方法的签名,最后一个是当前执行线程的宏,通过这个宏可以获得到当前执行线程的指针,指向 JavaThread 对象。现在我们首先看下 run_method_name 定义:
复制代码
#defineVM_SYMBOL_DECLARE(name, ignore) /
staticSymbol* name() { /
return_symbols[VM_SYMBOL_ENUM_NAME(name)]; /
}
VM_SYMBOLS_DO(VM_SYMBOL_DECLARE, VM_SYMBOL_DECLARE)
#undefVM_SYMBOL_DECLARE
这里是通过宏定义的方式指定的,我们直接搜索这个宏扩展的地方:
复制代码
template(run_method_name,"run")/
这里通过 cpp 模版方式定义,现在我们知道了 run_method_name 这个宏定义展开之后会变成 “run” 的 Symbol 指针。同时 void_method_signature 可以看到定义:
复制代码
template(void_method_signature,"()V")/
这里就是 public void run() 方法的签名啦~
好的,现在我们知道了参数的信息,至于 call_virtual 函数是怎样调用到 java 方法的,这里我只能说是通过 JVM call_stub 函数指针指向的指针函数跳转到 vtable 实现的。关于 call_stub 实现机制,是 JVM 中非常复杂的一个独立模块,这个模块涉及到 Java 中众多 invoke* 类的字节码执行细节逻辑。这些内容绝对不是一篇文章能够讲完的,因此这里挖一个坑后面专门写文介绍这块的实现(剧透一下,内容涉及汇编,不过只是简单的几条汇编),如果你急于了解这块的内容,可以参考 HotSpot 技术专家的 文章 。好吧,又挖了一个坑~
到这里,我们梳理清楚了 java 中 thread 的创建和启动过程,以及 run 方法执行的过程。下面总结下:
Java 线程创建和启动过程如下:
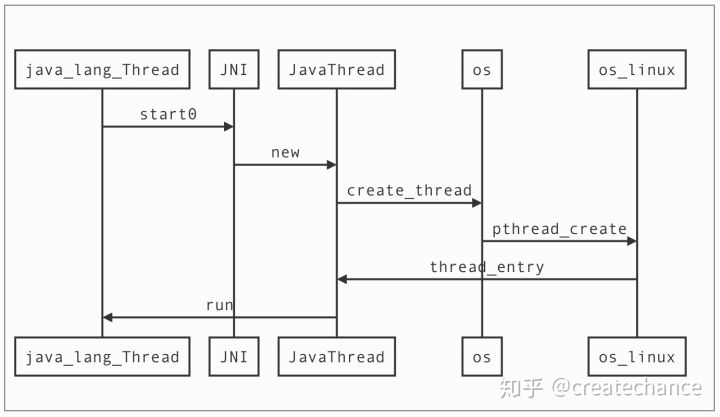
本文转载自知乎。
原文链接:
https://zhuanlan.zhihu.com/p/75532011
正文到此结束
- 本文标签: 源码 开发 src tar IO 内存模型 缓存 update list struct final 下载 UI 模型 注释 启动过程 操作系统 lib cache Bootstrap 字节码 java value ip 锁 文章 cat 高并发 时间 协议 参数 突破 example ORM IDE JVM linux 程序员 eclipse volatile ACE 线程 id 需求 CST 编译 REST js 同步 处理器 数据 EXHAUSTED App tab 重排序 http find 希望 代码 并发 服务器 软件 https 总结 Job 调试 一致性 CTO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

