JVM解剖乐园

1、JVM锁粗化和循环
原文标题:JVM Anatomy Quark #1: Lock Coarsening and Loops
众所周知Hotsport编译器会进行JVM锁粗化和优化,它将相邻的锁区块进行合并,有效减少锁的的占用成本,类似
synchronized (obj) {
// statements 1
}
synchronized (obj) {
// statements 2
}
优化成
synchronized (obj) {
// statements 1
// statements 2
}
那么在循环体中是否也会进行相同的优化?类似
for (...) {
synchronized (obj) {
// something
}
}
优化成
synchronized (this) {
for (...) {
// something
}
}
实际上是不会的,理论上来说是可以的,这有点像针对锁的循环无关代码外提。然而如此优化的缺点是将锁的粒度增加太多,线程在执行循环时将会长时间独占锁
翻译修改摘录自:
https://shipilev.net/jvm/anat...
2、透明大页
原文标题:JVM Anatomy Quark #2: Transparent Huge Pages
进程都拥有自己的虚拟内存空间,虚拟内存空间会映射到实际内存。例如,两个进程可以在相同的虚拟地址 0x42424242 中存储不同数据,这些数据实际存放在不同的物理内存中。当程序访问该地址时,通过某种机制会把虚拟地址转换成实际物理地址
这个过程一般通过由操作系统维护的页表实现,硬件通过"遍历页表"进行地址转换。虽然以页面为单位进行地址转换更容易,但由于每次访问内存都会发生地址转换会带来不小开销。为此,引入TLB(转换查找缓冲)缓存最近的转换记录。TLB要求至少要与 L1 缓存一样快,因此通常缓存少于100条。对工作负载较大的情况,TLB缺失和由此引发的页表遍历需要很多时间
TLB容量比较小,但是我们可以将地址转换的页面容量增大,这个可以借助系统内核的透明大页机制轻松做到,那这样是否会对性能有所帮助呢?
实际上它能有效提高应用程序性能,特别是当程序拥有大量数据和堆栈时
翻译修改摘录自:
https://shipilev.net/jvm/anat...
3、GC设计和停顿
原文标题:JVM Anatomy Quark #3: GC Design and Pauses
常见GC算法如下所示,其中黄色为stop-the-world阶段,绿色为并发阶段
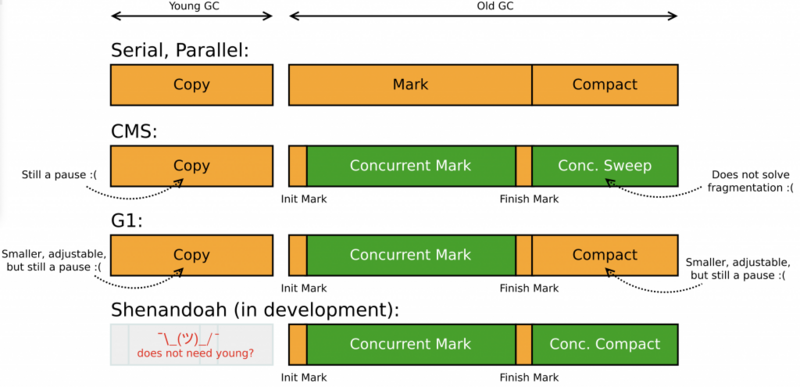
需要注意不同收集器在常规GC循环中何时会暂停
翻译修改摘录自:
https://shipilev.net/jvm/anat...
4、TLAB内存分配
原文标题:JVM Anatomy Quark #4: TLAB allocation
本小节将揭晓,什么是Bump-the-pointer技术跟踪?什么是TLAB内存分配?
Bump-the-pointer技术跟踪在eden区创建的最后一件对象,最后该对象会放在eden顶部,之后再创建对象时,只需要检查最后一个对象就可以知道eden空间容量是否足够,但是在多线程环境中就会出现问题,不过加锁同步开销太大,于是提出TLAB
TLAB(Thread-local allocation buffer)缓冲区,特点是每个线程独享一份,也就意味着不存在数据共享也就不需要加锁同步,同时它结合了Bump-the-pointer跟踪技术实现快速的对象分配
翻译修改摘录自:
https://shipilev.net/jvm/anat...
5、TLAB与堆可解析性
原文标题:JVM Anatomy Quark #5: TLABs and Heap Parsability
好的垃圾回收器通常会保证堆的可解析性,意味着它不需要复杂的数据结构也能以某种方式解析成对象或者字段。虽然严格来说,它在分配周期中并不是始终以对象流的方式存在,但是它使得GC实现、测试、调戏变得轻易
翻译修改摘录自:
https://shipilev.net/jvm/anat...
6、创建对象阶段
原文标题:JVM Anatomy Quark #6: New Object Stages
你可能听说过分配并不是初始化。但是 Java 有构造方法!构造方法是分配?还是初始化?
Java语言中的new对应很多字节码指令,比如
public Object t() {
return new Object();
}
编译为
public java.lang.Object t();
descriptor: ()Ljava/lang/Object;
flags: (0x0001) ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: new #4 // class java/lang/Object
3: dup
4: invokespecial #1 // Method java/lang/Object."<init>":()V
7: areturn
给人感觉是,new关键会执行分配资源和系统初始化,同时调用构造方法执行用户初始化,但是聪明的虚拟机会进行优化,比如在构造方法执行完成之前观察对象使用情况然后选择性合并任务
翻译修改摘录自:
https://shipilev.net/jvm/anat...
7、初始化开销
原文标题:JVM Anatomy Quark #7: Initialization Costs
初始化对象或者数组是实例化过程中最主要的开销,使用TLAB分配,对象或者数据初始化的开销取决于元数据写入和内容的初始化
翻译修改摘录自:
https://shipilev.net/jvm/anat...
8、局部变量可用性
原文标题:JVM Anatomy Quark #8: Local Variable Reachability
离开了当前作用域,存储在局部变量中的引用才会被回收,这种说法正确吗?在Java中并非如此,Java局部变量的可用性不由代码块决定,而与最后一次使用有关,并且可能会持续到最后一次使用为止。使用像finalizer、强引用、弱引用、虚引用这样的方法通知对象不可达,会受到“提前检查”优化带来的影响,使得代码块还没有结束变量可能已不可用,这是一种很好的特性,使得GC能提前回收掉本地分配的大量缓存
当然如果想获得C++编程那种代码块结束时才释放的特性,你可以使用try-finally
翻译修改摘录自:
https://shipilev.net/jvm/anat...
9、JNI 临界区 与 GC 锁
原文标题:JVM Anatomy Quark #9: JNI Critical and GC Locker
10、String中的intern方法
原文标题:JVM Anatomy Quark #10: String.intern()
我们知道intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中,从而使得字符串对象被缓存了一样
JAVA使用JNI调用c++实现的StringTable的intern方法, StringTable的intern方法跟Java中的HashMap的实现是差不多的, 只是不能自动扩容。默认大小是1009
要注意的是,String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接造成的影响就是调用String.intern时性能会大幅下降
翻译修改摘录自:
https://shipilev.net/jvm/anat...
11、移动GC与局部性
原文标题:JVM Anatomy Quark #11: Moving GC and Locality
标记-压缩回收器可以保持堆中对象的分配顺序,也可以对其任意重排。虽然任意顺序能够比其他标记-压缩回收器速度更快,也不会带来空间开销,但是会破坏应用线程的局部性
翻译修改摘录自:
https://shipilev.net/jvm/anat...
12、本地内存跟踪
原文标题:JVM Anatomy Quark #12: Native Memory Tracking
JVM的默认配置通常是为长时间运行的服务器应用准备的,包括GC、内部数据结构的初始大小、堆栈大小等也是如此,而通过NMT探索虚拟机内存分配情况能让我们立刻知道从哪里入手优化应用占用的内存,同时非常有助于在应用实际生产环境中调整JVM参数
翻译修改摘录自:
https://shipilev.net/jvm/anat...
13、屏障
原文标题:JVM Anatomy Quark #13: Intergenerational Barriers
GC通常会有屏障组,即使没有实际发生回收,这些屏障也会影响应用程序的性能。即使串行、并行这样非常基本的分代收集器,也至少有一个引用存储屏障,而像G1这样更高级的回收器会有更复杂的屏障跟踪不同区域间的引用。某些情况下,这种开销让人非常痛苦
翻译修改摘录自:
https://shipilev.net/jvm/anat...
14、常量变量
原文标题:JVM Anatomy Quark #14: Constant Variables
停留2秒思考下面的代码块会输出什么
import java.lang.reflect.Field;
public class ConstantValues {
final int fieldInit = 42;
final int instanceInit;
final int constructor;
{
instanceInit = 42;
}
public ConstantValues() {
constructor = 42;
}
static void set(ConstantValues p, String field) throws Exception {
Field f = ConstantValues.class.getDeclaredField(field);
f.setAccessible(true);
f.setInt(p, 9000);
}
public static void main(String... args) throws Exception {
ConstantValues p = new ConstantValues();
set(p, "fieldInit");
set(p, "instanceInit");
set(p, "constructor");
System.out.println(p.fieldInit + " " + p.instanceInit + " " + p.constructor);
}
}
正常会打印出42 9000 9000,也就是说即使通过反射重写了fieldInt字段的值,我们也无法观察到最新的值,而更新另外两个字段生效了,这个奇怪结果的解释是方法内联
翻译修改摘录自:
https://shipilev.net/jvm/anat...
15、即时常量
编译器信任static final字段,因为这个值不依赖特定对象,而且是不能改变的
https://shipilev.net/jvm/anat...
16、超多态虚调用
https://shipilev.net/jvm/anat...17、信任非静态Final字段
原文标题:JVM Anatomy Quark #17: Trust Nonstatic Final Fields
class M {
final int x;
M(int x) { this.x = x; }
}
static final M KNOWN_M = new M(1337);
void work() {
// We know exactly the slot that holds the variable, can we just
// inline the value 1337 here?
return KNOWN_M.x;
}
上面这段代码是否会进行方法内联优化呢?实际上是不会的,如果要信任实例final字段,那么必须知道当前操作的对象,然而上面那段代码是引用关系
翻译修改摘录自:
https://shipilev.net/jvm/anat...
18、字面量替换
原文标题:JVM Anatomy Quark #18: Scalar Replacement
利用逃逸分析然后编译器优化可以实现在栈上分配而不是堆上分配,方法退出后直接弹出释放,无助借助垃圾回收器处理,很神奇,对吗?
不过一旦发生了逃逸现象,我们需要将实体对象完整地复制到堆中。而且由于实现起来需要更改大量假设了"对象只能在堆上分配"的代码,因为HotSpot虚拟机并没有采用栈上分配,而是标量替换这么一项技术。这个优化技术,可以看到将原本对对象的字段访问,替换为一个局部变量的访问。该对象没有被实际分配,因此和栈上分配一样,它同样可以减轻垃圾回收的压力
翻译修改摘录自:
https://shipilev.net/jvm/anat...
19、锁消除
原文标题:JVM Anatomy Quark #19: Lock Elision
目前的内存模型中,对不共享的对象进行加锁操作是无效的,编译器不会对它做任何事情。由于其他线程不能获取该锁对象,因此也无法基于该锁对象构造两个线程之间的happens-before规则。那么编译器只需证明锁对象不会发生逃逸,便可以进行锁消除
翻译修改摘录自:
https://shipilev.net/jvm/anat...
20、FPU溢出
原文标题:JVM Anatomy Quark #20: FPU Spills
寄存器分配器的职责是,维护在特定的编译单元中程序需要的所有操作数的程序表示,并且映射这些虚操作数到实际的机器寄存器,也就是为它们分配寄存器。在许多真实的程序中,在给定程序位置,虚操作数的数量会大于可用机器寄存器的数量,那么寄存器分配器就需要将某些操作数放到寄存器之外的其它位置比如放到栈上,这种就称为FPU溢出,有效缓解了寄存器压力
翻译修改摘录自:
https://shipilev.net/jvm/anat...
21、堆内存归还
原文标题:JVM Anatomy Quark #21: Heap Uncommit
许多GC已经实现了在合适的时机归还堆内存:Shenandoah异步执行堆内存归还,即使没有GC请求;G1在显式GC请求中执行堆内存归还;Serial和Parallel在某些条件下也会执行。不过归还内存可能会耗费一些时间,所以实际的实现会在归还内存之前会增加一个超时时间
翻译修改摘录自:
https://shipilev.net/jvm/anat...
22、安全点检查
原文标题:JVM Anatomy Quark #22: Safepoint Polls
在大部分机器上停止运行的线程实际上是很简单的:向线程发送一个信号,强制处理器中断,停止线程正在执行的操作,将控制权转交给别处。然而,这还不足以让Java线程在任意位置停止,特别是如果你需要精确的垃圾回收。在这种情况下,你需要知道寄存器和栈中的内容,这些内容可能是你需要处理的对象引用。或者如果你想要取消偏向锁,你需要精确的知道线程的状态和获取的锁
因此Hotspot实现了协作机制:线程经常询问是否应该将控制权交给VM,在线程生命周期中某些已知的位置,线程的状态是已知的。当所有线程都在已知的位置停止的时候,VM 被认为是到达了安全点。检查安全点请求的代码片段因此被称为安全点检查
翻译修改摘录自:
https://shipilev.net/jvm/anat...
23、压缩引用
原文标题:JVM Anatomy Quark #23: Compressed References
大部分JVM实现将Java引用转换为机器指针,没有额外的迂回,这简化了性能问题,不过通常情况下会使得引用的表示比机器指针的宽度小,也就是进行压缩引用,比如你可以使用XX:+UseCompressedOops选项,使得在64位系统中对象指针可以使用32bit的Compressed版本。压缩方法可以是比特右移,称为“基于零的压缩普通对象指针”,但是基于零的压缩引用仍然依赖堆内存映射在较低地址的假设。如果不是,我们可以使用非零的堆内存起始地址来解码
翻译修改摘录自:
https://shipilev.net/jvm/anat...
24、对象对齐
原文标题:JVM Anatomy Quark #24: Object Alignment
许多硬件实现要求对数据的访问是对齐的,也就是N字节宽度数据的访问地址总是N的倍数,否则会直接拒绝操作,产生SIGBUS信号或者其他硬件异常
在Hotspot中最小的对象对齐是8字节,我们可以通过-XX:ObjectAlignmentInBytes选项进行调整,不过会有正面和负面的后果
负面的后果是每个对象平均的内存空间浪费将会增加,如果启用压缩引用,这个增加会变得不那么明显,不过内存对齐会导致压缩引用阈值被移动,因为它依赖引用中有多少低位比特是零,这很有趣,总之,利器当慎用
翻译修改摘录自:
https://shipilev.net/jvm/anat...
文章来源: www.liangsonghua.me
作者介绍:京东资深工程师-梁松华,在稳定性保障、敏捷开发、JAVA高级、微服务架构方面有深入的理解
正文到此结束
- 本文标签: 实例 性能问题 scala 模型 构造方法 ip 标题 内存模型 遍历 final Atom id 字节码 tab cat 多线程 解析 锁 文章 物理内存 JVM tag 测试 压力 数据 App 开发 ACE 虚拟内存 HashTable 并发 翻译 进程 UI CTO 操作系统 生命 垃圾回收 HashMap 微服务 编译 线程 配置 空间 参数 http IO java线程 缓存 服务器 map 时间 敏捷 src constant bus Statement java https 安全 value 同步 处理器 工程师 synchronized struct 京东 代码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

