自定义BeanPostProcessor踩坑记
背景
BeanPostProcessor是Spring扩展机制中的其中一种,它在Bean生命周期中的位置如下:
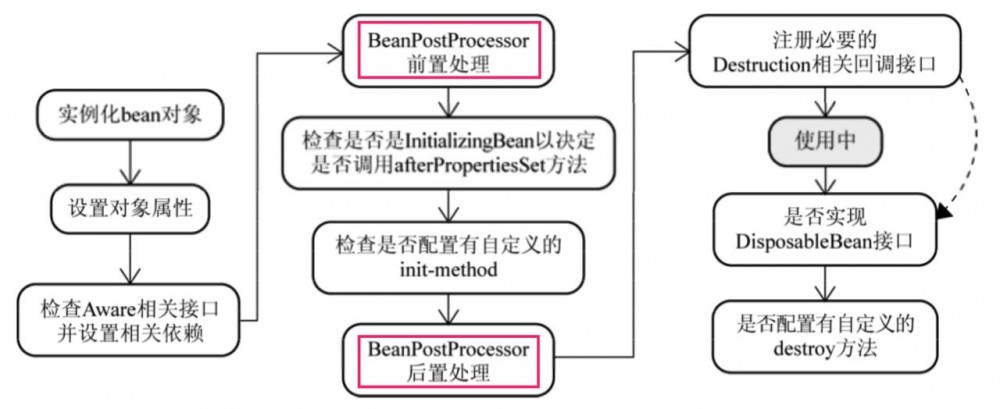
一般我们可以用它来对bean实例化前后做一些处理,如收集并处理自定义注解从而为成员变量赋上值等。
问题
现在有三个类,AnnotationProcessor用于处理自定义注解,Anno为自定义注解,MyProcessor依赖AnnotationProcessor处理结果。
@Component
public class AnnotationProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return null;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Field[] fields = bean.getClass().getDeclaredFields();
for (Field field : fields) {
if (field.getAnnotation(Anno.class) != null) {
//对字段做处理
}
}
return bean;
}
}复制代码
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Anno {
}复制代码
@Component
public class MyProcessor implements BeanPostProcessor {
@Anno
private String str;
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return null;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
//str此时为null
return null;
}
}复制代码
程序运行起来之后,会发现MyProcessor#postProcessAfterInitialization()拿到的str是空的,为什么会这样呢?怎么样才能让str是已经经过AnnotationProcessor处理的?
问题分析
我们可以通过查看源码来看Spring是如何处理BeanPostProcessor。由于MyProcessor 本身也是一个bean,那么我们可以到Spring实例化 MyProcessor 的地方,看看当时对应的BeanPostProcessor集合当中有哪些。
代码到达AbstractAutowireCapableBeanFactory#doCreateBean()位置,BeanPostProcessor的处理是在这里完成:

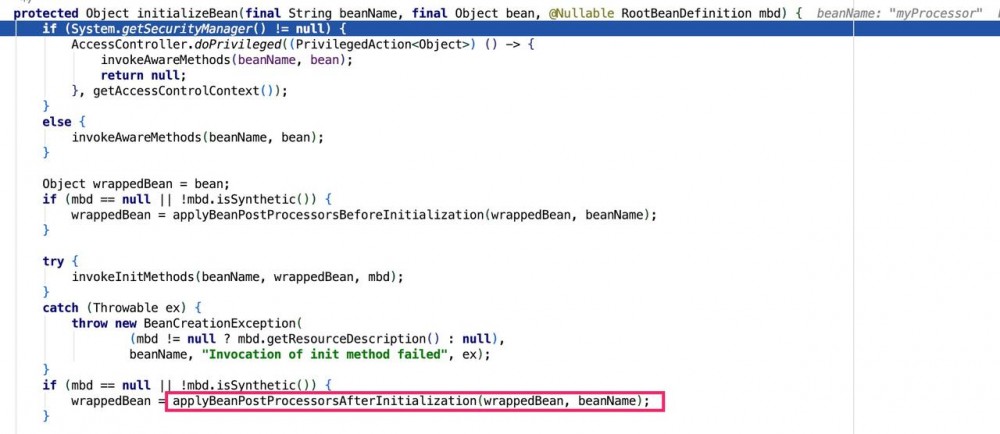
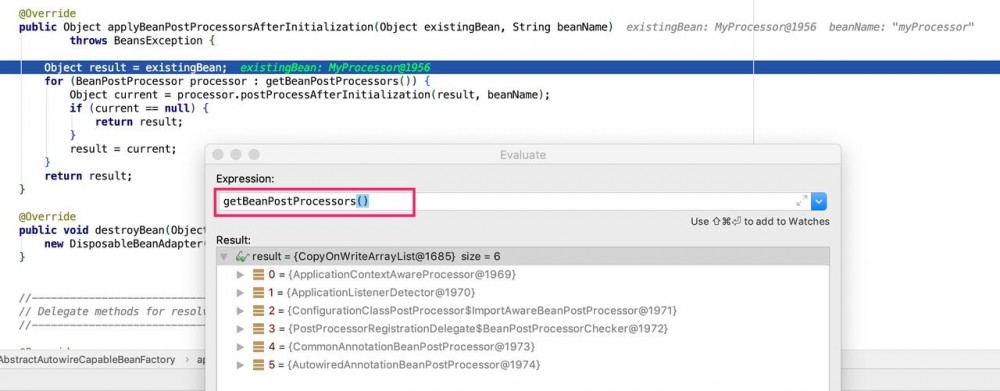
可以看到,在实例化MyProcessor的时候,在当时已经注册到容器的BeanPostProcessor集合中,只有Spring内置的一些BeanPostProcessor,此时并没有任何自定义的BeanPostProcessor
我们再看BeanPostProcessor是如何注册的,代码来到PostProcessorRegistrationDelegate#registerBeanPostProcessors()(部分代码省略)
public static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, AbstractApplicationContext applicationContext) {
// 1、注册实现了PriorityOrdered的BeanPostProcessor
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors);
// 2、注册实现了Ordered接口的BeanPostProcessor
sortPostProcessors(orderedPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, orderedPostProcessors);
//3、注册一般的BeanPostProcessor(即示例中的AnnotationProcessor、MyProcessor) List<BeanPostProcessor> nonOrderedPostProcessors = new ArrayList<BeanPostProcessor>();
for (String ppName : nonOrderedPostProcessorNames) {
//这里会触发AnnotationBeanPostProcessor的实例化,但此时registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors)未执行,AnnotationBeanPostProcessor未注册到BeanFactory中,所以在示例中拿不到AnnotationBeanPostProcessor的处理结果 BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
nonOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors);
//4、注册Spring内部用的BeanPostProcessor
sortPostProcessors(internalPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, internalPostProcessors);
}复制代码
到这里,我们可以看到我们自定义的BeanPostProcess是在第三步被处理,此时会先实例化BeanPostProcess,再注册到容器中,因此我们示例中的MyProcessor是不会被AnnotationProcessor处理的。
那么要如何才能被处理呢?可以看到第三步之前第一步和第二步会先注册实现了PriorityOrdered或Ordered接口的BeanPostProcessor,那么只要我们让AnnotationProcessor实现了这两个接口之一,也能实现我们的目的。
结论
由此可以得出,如果希望中MyProcessor用到的属性是被AnnotationProcessor处理过的,就需要让AnnotationProcessor实现PriorityOrdered或Ordered接口。
最后
Spring对处理BeanPostProcessor的依赖关系有什么优化点?
个人理解:后一个处理的BeanPostProcessor可以依赖于前一个BeanPostProcessor的处理结果。对于带有优先级的BeanPostProcessor,通过优先级可以实现;对于无优先级的BeanPostProcessor来说,就取决于声明的顺序。
emm...这么玩BeanPostProcessor合不合理?
可能Spring设计BeanPostProcessor的初衷就不让BeanPostProcessor依赖于其它BeanPostProcessor的结果,每个BeanPostProcessor处理的逻辑应该都是独立的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

