JVM_即时编译器
Java源代码的执行流程
Java源代码转换成硬件能执行的机器码的过程如下图:
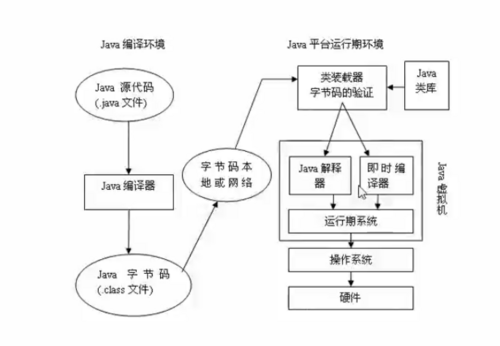
从图中可以看到Java源代码先是经过Java编译器编译成class文件,然后这些class文件经过类加载过程加载到内存中,再由Java虚拟机转换成操作系统能执行的机器码。
两种执行方式的区别及分工方式
字节码转换成机器码有两种方式:1.通过解释器进行动态解释执行,2.通过即时编译器进行动态编译执行。这两种方式有什么区别呢。
解释执行:逐条将字节码翻译成机器码并执行
优点:当程序需要迅速启动的时候,解释器可以首先发挥作用,省去了编译的时间,立即执行。解释执行占用更小的内存空间。
即时编译(Just-in-time ,JIT):将一个方法中包含的所有字节码编译成机器码后再执行。
优点:在程序运行时,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获得更高的执行效率。
Java解释器和即时编译器按照如下规则进行分工:
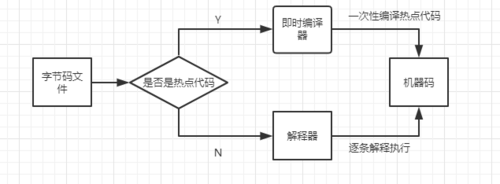
Java虚拟机会根据代码是否是热点代码选择不同的执行方式。热点代码有下面两类:
- 被多次调用的方法
- 被多次执行的循环体
对于第一种,编译器会将整个方法作为编译对象,这也是标准的JIT 编译方式。对于第二种是由循环体出发的,但是编译器依然会以整个方法作为编译对象,因为发生在方法执行过程中,称为栈上替换。
怎么判断热点代码
判断一段代码是否是热点代码,是不是需要出发即时编译,这样的行为称为热点探测(Hot Spot Detection),探测算法有两种,分别为。
- 基于采样的热点探测(Sample Based Hot Spot Detection):虚拟机会周期的对各个线程栈顶进行检查,如果某些方法经常出现在栈顶,这个方法就是“热点方法”。好处是实现简单、高效,很容易获取方法调用关系。缺点是很难确认方法的reduce,容易受到线程阻塞或其他外因扰乱。
- 基于计数器的热点探测(Counter Based Hot Spot Detection):为每个方法(甚至是代码块)建立计数器,执行次数超过阈值就认为是“热点方法”。优点是统计结果精确严谨。缺点是实现麻烦,不能直接获取方法的调用关系。
HotSpot 使用的是第二种-基于技术其的热点探测,并且有两类计数器:方法调用计数器(Invocation Counter )和回边计数器(Back Edge Counter )。这两个计数器都有一个确定的阈值,超过后便会触发 JIT 编译。
- 方法调用计数器。Client 模式下默认阈值是 1500 次,在 Server 模式下是 10000次,这个阈值可以通过 -XX:CompileThreadhold 来人为设定。如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内的方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那么这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就成为此方法的统计的半衰周期( Counter Half Life Time)。进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数 -XX:CounterHalfLifeTime 参数设置半衰周期的时间,单位是秒。
- 回边计数器,作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”( Back Edge ),建立回边计数器统的目的就是为了触发 OSR 编译。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

