ZooKeeper分布式专题(六)-- Dubbo入门到重构服务
本文将以原理+实战的方式,首先对“微服务”相关的概念进行知识点扫盲,然后开始手把手教你搭建这一整套的微服务系统。
微服务
微服务一次近几年相当火,成为程序猿饭前便后装逼热门词汇,你不对它有所了解如何在程序猿装逼圈子里混?下面我用最为通俗易懂的语言介绍它。
要讲清楚微服务,我先要从一个系统架构的演进过程讲起。
单机结构
我想大家最最最熟悉的就是单机结构,一个系统业务量很小的时候所有的代码都放在一个项目中就好了,然后这个项目部署在一台服务器上就好了。整个项目所有的服务都由这台服务器提供。这就是单机结构。 那么,单机结构有啥缺点呢?我想缺点是显而易见的,单机的处理能力毕竟是有限的,当你的业务增长到一定程度的时候,单机的硬件资源将无法满足你的业务需求。此时便出现了集群模式,往下接着看。
集群结构
集群模式在程序猿界由各种装逼解释,有的让你根本无法理解,其实就是一个很简单的玩意儿,且听我一一道来。
单机处理到达瓶颈的时候,你就把单机复制几份,这样就构成了一个“集群”。集群中每台服务器就叫做这个集群的一个“节点”,所有节点构成了一个集群。每个节点都提供相同的服务,那么这样系统的处理能力就相当于提升了好几倍(有几个节点就相当于提升了这么多倍)。
但问题是用户的请求究竟由哪个节点来处理呢?最好能够让此时此刻负载较小的节点来处理,这样使得每个节点的压力都比较平均。要实现这个功能,就需要在所有节点之前增加一个“调度者”的角色,用户的所有请求都先交给它,然后它根据当前所有节点的负载情况,决定将这个请求交给哪个节点处理。这个“调度者”有个牛逼了名字——负载均衡服务器。
集群结构的好处就是系统扩展非常容易。如果随着你们系统业务的发展,当前的系统又支撑不住了,那么给这个集群再增加节点就行了。但是,当你的业务发展到一定程度的时候,你会发现一个问题——无论怎么增加节点,貌似整个集群性能的提升效果并不明显了。这时候,你就需要使用微服务结构了。
微服务结构
先来对前面的知识点做个总结。 从单机结构到集群结构,你的代码基本无需要作任何修改,你要做的仅仅是多部署几台服务器,没太服务器上运行相同的代码就行了。但是,当你要从集群结构演进到微服务结构的时候,之前的那套代码就需要发生较大的改动了。所以对于新系统我们建议,系统设计之初就采用微服务架构,这样后期运维的成本更低。但如果一套老系统需要升级成微服务结构的话,那就得对代码大动干戈了。所以,对于老系统而言,究竟是继续保持集群模式,还是升级成微服务架构,这需要你们的架构师深思熟虑、权衡投入产出比。
OK,下面开始介绍所谓的微服务。 微服务就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在微服务结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC方式通信。
举个例子,假设需要开发一个在线商城。按照微服务的思想,我们需要按照功能模块拆分成多个独立的服务,如:用户服务、产品服务、订单服务、后台管理服务、数据分析服务等等。这一个个服务都是一个个独立的项目,可以独立运行。如果服务之间有依赖关系,那么通过RPC方式调用。
这样的好处有很多:
- 系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
- 系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务。假设这个商城要搞一次大促,下单量可能会大大提升,因此我们可以针对性地提升订单系统、产品系统的节点数量,而对于后台管理系统、数据分析系统而言,节点数量维持原有水平即可。
- 服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以使用该系统作为用户系统,无需重复开发。
那么问题来了,当采用微服务结构后,一个完整的系统可能有很多独立的子系统组成,当业务量渐渐发展起来之后,而这些子系统之间的关系将错综复杂,而且为了能够针对性地增加某些服务的处理能力,某些服务的背后可能是一个集群模式,由多个节点构成,这无疑大大增加了运维的难度。微服务的想法好是好,但开发、运维的复杂度实在是太高。为了解决这些问题,阿里巴巴的Dubbo就横空出世了。
Dubbo
Dubbo是一套微服务系统的协调者,在它这套体系中,一共有三种角色,分别是:服务提供者(下面简称提供者)、服务消费者(下面简称消费者)、注册中心。
你在使用的时候需要将Dubbo的jar包引入到你的项目中,也就是每个服务都要引入Dubbo的jar包。然后当这些服务初始化的时候,Dubbo就会将当前系统需要发布的服务、以及当前系统的IP和端口号发送给注册中心,注册中心便会将其记录下来。这就是服务发布的过程。与此同时,也是在系统初始化的时候,Dubbo还会扫描一下当前系统所需要引用的服务,然后向注册中心请求这些服务所在的IP和端口号。接下来系统就可以正常运行了。当系统A需要调用系统B的服务的时候,A就会与B建立起一条RPC信道,然后再调用B系统上相应的服务。
这,就是Dubbo的作用。
创建项目的组织结构
- 创建一个Maven Project,命名为 microserver-dubbo-learning, 这个Project由多个Module构成,每个Module对应着“微服务”的一个子系统,可独立运行,是一个独立的项目。 这也是目前主流的项目组织形式,即多模块项目。
- 在这个项目下创建各个子模块, 每个子模块都是一个独立的SpringBoot项目:
- micro-user 用户服务
- micro-order 订单服务
- micro-product 商品服务
- micro-analysis 数据分析服务
- micro-controller 本系统的控制层,和以往三层结构中的Controller层的作用一样,都是用作请求调度,只不过在微服务架构中,我们将它抽象成一个单独的系统,可以独立运行。
- micro-common 它处于本系统的最底层,被所有模块依赖,一些公用的类库都放在这里。
- micro-api 接口服务,
- micro-redis 我们将Redis封装成一个单独的服务,运行在独立的容器中,当哪一个模块需要使用Redis的时候,仅需要引入该服务即可,就免去了各种繁琐的、重复的配置。而这些配置均在micro-redis系统中完成了。
下面我们开始动手创建项目
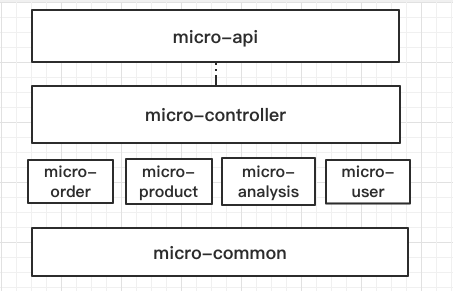
1,new 一个 Project
groupId:cn.haoxy.micro.server.dubbo artifactId:microserver-dubbo-learning version:v1.0.0
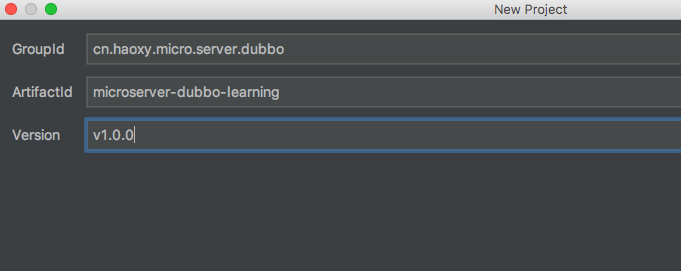
2,创建Model,在Project上创建model
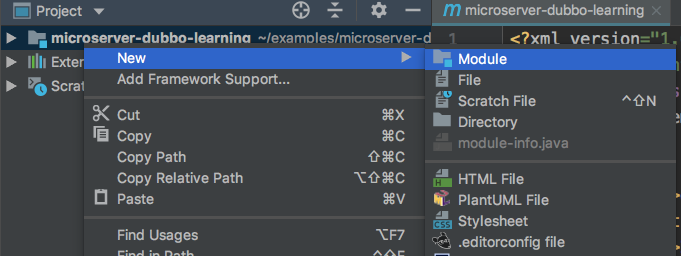
依次创建好所有的model,如图所示:
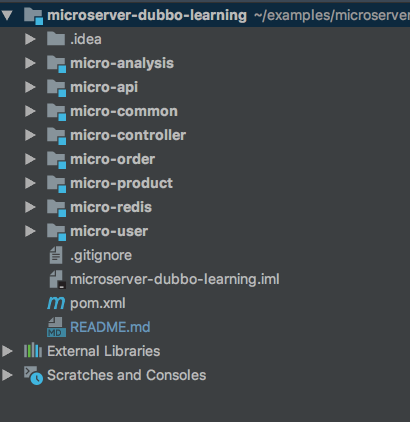
3,构建模块之间的依赖关系:
目前为止,模块之间没有任何联系,下面我们要通过pom文件来指定它们之间的依赖关系,依赖关系如下图所示:
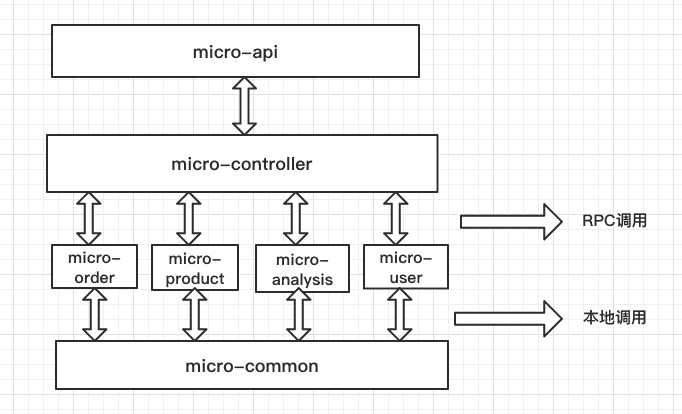
micro-user、micro-analysis、micro-product、micro-order这四个系统相当于以往三层结构的Service层,提供系统的业务逻辑,只不过在微服务结构中,Service层的各个模块都被抽象成一个个单独的子系统,它们提供RPC接口供上面的micro-controller调用。它们之间的调用由Dubbo来完成,所以它们的pom文件中并不需要作任何配置。而这些模块和micro-common之间是本地调用,因此需要将micro-common打成jar包,并让这些模块依赖这个jar,因此就需要在所有模块的pom中配置和micro-common的依赖关系。
此外,为了简化各个模块的配置,我们将所有模块的通用依赖放在Project的pom文件中,然后让所有模块作为Project的子模块。这样子模块就可以从父模块中继承所有的依赖,而不需要自己再配置了。
- 首先将micro-common的打包方式设成jar,当打包这个模块的时候,Maven会将它打包成jar,并安装在本地仓库中。这样其他模块打包的时候就可以引用这个jar。
<dependency>
<artifactId>micro-common</artifactId>
<groupId>cn.haoxy.micro.server.dubbo.common</groupId>
<version>v1.0.0</version>
<packaging>jar</packaging>
</dependency>
复制代码
- 将其他模块的打包方式设为war,除了micro-common外,其他模块都是一个个可独立运行的子系统,需要在web容器中运行,所以我们需要将这些模块的打包方式设成war
<artifactId>micro-user</artifactId>
<groupId>cn.haoxy.micro.server.dubbo.user</groupId>
<version>v1.0.0</version>
<packaging>war</packaging>
复制代码
- 在总pom中指定子模块modules标签指定了当前模块的子模块是谁,但是仅在父模块的pom文件中指定子模块还不够,还需要在子模块的pom文件中指定父模块是谁。
<modules> <module>micro-user</module> <module>micro-order</module> <module>micro-product</module> <module>micro-api</module> <module>micro-controller</module> <module>micro-analysis</module> <module>micro-common</module> <module>micro-redis</module> </modules> 复制代码
- 在子模块中指定父模块
例如在 micro-user子模块中的 pom.xml中指定父模块
<parent> <artifactId>microserver-dubbo-learning</artifactId> <groupId>cn.haoxy.micro.server.dubbo</groupId> <version>v1.0.0</version> </parent> 复制代码
到此为止,模块的依赖关系配置完毕!但要注意模块打包的顺序。由于所有模块都依赖于micro-common模块,因此在构建模块时,首先需要编译、打包、安装micro-common,将它打包进本地仓库中,这样上层模块才能引用到。当该模块安装完毕后,再构建上层模块。否则在构建上层模块的时候会出现找不到micro-common中类库的问题。
4,在父模块的pom中添加所有子模块公用的依赖
<dependencies>
<dependency>
<artifactId>micro-common</artifactId>
<groupId>cn.haoxy.micro.server.dubbo.common</groupId>
<version>v1.0.0</version>
</dependency>
<!--Spring MVC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--Test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- MyBatis -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.11</version>
</dependency>
<!-- AOP -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.3-jre</version>
</dependency>
<!--fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.31</version>
</dependency>
</dependencies>
复制代码
当父模块的pom中配置了公用依赖后,子模块的pom文件将非常简洁,如下所示:
<modelVersion>4.0.0</modelVersion> <parent> <artifactId>microserver-dubbo-learning</artifactId> <groupId>cn.haoxy.micro.server.dubbo</groupId> <version>v1.0.0</version> </parent> <artifactId>micro-user</artifactId> <groupId>cn.haoxy.micro.server.dubbo.user</groupId> <version>v1.0.0</version> 复制代码
5,整合dubbo
Dubbo一共定义了三种角色,分别是:服务提供者、服务消费者、注册中心。注册中心是服务提供者和服务消费者的桥梁,服务消费者会在初始化的时候将自己的IP和端口号发送给注册中心,而服务消费者通过注册中心知道服务提供者的IP和端口号。
在Dubbo中,注册中心有多种选择,Dubbo最为推荐的即为ZooKeeper,本文采用ZooKeepeer作为Dubbo的注册中心。
dubbo官网
- 父pom文件中引入dubbo依赖
<dependency> <groupId>com.alibaba.boot</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <version>0.2.0</version> </dependency> 复制代码
- 发布服务
假设,我们需要将micro-user项目中的UserService发布成一项RPC服务,供其他系统远程调用,那么我们究竟该如何借助Dubbo来实现这一功能呢?
在micro-common中定义UserService的接口,由于服务的发布和引用都依赖于接口,但服务的发布方和引用方在微服务架构中往往不在同一个系统中,所以需要将需要发布和引用的接口放在公共类库中,从而双方都能够引用。接口如下所示:
public interface UserService {
UserEntity login(LoginReq loginReq);
}
复制代码
在micro-user中定义接口的实现,在实现类上需要加上Dubbo的@Service注解,从而Dubbo会在项目启动的时候扫描到该注解,将它发布成一项RPC服务。
@Service(version = "v1.0.0")
@org.springframework.stereotype.Service
public class UserServiceImpl implements UserService {
@Autowired
UserDAO userDAO;
@Override
public UserEntity login(LoginReq loginReq) {
// do something ....
}
}
复制代码
配置服务提供者(micro-user、micro-analysis、micro-product、micro-order)
## Dubbo 服务提供者配置 dubbo.application.name=user-provider # 本服务的名称 dubbo.registry.address=127.0.0.1:2181 # ZooKeeper所在服务器的IP和端口号 dubbo.registry.protocol=zookeeper dubbo.protocol.name=dubbo # RPC通信所采用的协议 dubbo.protocol.port=20880 # 本服务对外暴露的端口号 dubbo.scan.base-packages=cn.haoxy.micro.server.dubbo.user.service # 服务实现类所在的路径 复制代码
按照上面配置完成后,当micro-user系统初始化的时候,就会扫描dubbo.scan.base-packages所指定的路径下的@Service注解,该注解标识了需要发布成RPC服务的类。Dubbo会将这些类的接口信息+本服务器的IP+dubbo.protocol.port所指定的端口号发送给Zookeeper,Zookeeper会将这些信息存储起来。 这就是服务发布的过程,下面来看如何引用一项RPC服务。
- 引用服务
假设,micro-controller需要调用micro-user 提供的登录功能,此时它就需要引用UserService这项远程服务。下面来介绍服务引用的方法。
声明需要引用的服务,引用服务非常简单,你只需要在引用的类中声明一项服务,然后用@Reference标识,如下所示:
@RestController
public class UserControllerImpl implements UserController {
@Reference(version = "v1.0.0")
UserService userService;
@PostMapping(value = "login")
@Override
public Result login(@RequestBody LoginReq loginReq, HttpServletResponse httpRsp) {
UserEntity userEntity = userService.login(loginReq);
return Result.newSuccessResult(userEntity);
}
}
复制代码
注意: @Reference(version = "v1.0.0")和@Service(version = "v1.0.0")的version的值一定要一致;
配置服务消费者(micro-controller)
## Dubbo 服务消费者配置 dubbo.application.name=controller-consumer # 本服务的名称 dubbo.registry.address=zookeeper://127.0.0.1:2181 # zookeeper所在服务器的IP和端口号 dubbo.scan.base-packages=cn.haoxy.micro.server.dubbo # 引用服务的路径 复制代码
上述操作完成后,当micro-controller初始化的时候,Dubbo就会扫描dubbo.scan.base-packages所指定的路径,并找到所有被@Reference修饰的成员变量;然后向Zookeeper请求该服务所在的IP和端口号。当调用userService.login()的时候,Dubbo就会向micro-user发起请求,完成调用的过程。这个调用过程是一次RPC调用,但作为程序猿来说,这和调用一个本地函数没有任何区别,远程调用的一切都由Dubbo来帮你完成。这就是Dubbo的作用。
正文到此结束
- 本文标签: tar map 管理 XML 总结 ACE 架构师 spring maven sql IDE json 开发 http 注册中心 mysql 端口 负载均衡 zookeeper redis App dependencies entity springboot 测试 js 阿里巴巴 数据 CTO mybatis src 分布式 协议 https 集群 UI 需求 程序猿 lib id 部署 编译 ip cat 系统架构 代码 REST consumer AOP druid 服务器 产品 配置 Google 组织 provider IO 微服务 web servlet 压力 安装 API value dubbo Service zab java pom
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

