我是如何理解Java8 Stream
之前看了许多介绍Java8 Stream的文章,但是初次接触真的是难以理解(我悟性比较低),没办法只能"死记硬背",但是昨天我打王者荣耀(那一局我赢了,牛魔全场MVP)的时候,突然迸发了灵感,感觉之前没有理解透彻的一下子就理解透彻了。所以决定用简单的方式来回忆下我认为的java8 Stream.
lambda表达式
语法
lambda表达式是Stream API的基石,所以想要学会Stream API的使用,必须先要理解lambda表达式,这里对lambda做一个简单回顾。
我们常常会看到这样的代码
Arrays.sort(new Integer[]{1, 8, 7, 4}, new Comparator<Integer>() {
@Override
public int compare(Integer first, Integer second) {
return first.compareTo(second);
}
});
复制代码
上面这种写法就是使用了匿名类,我们经常会使用匿名类的方式,因为我们只运行一次,不想它一直存在。虽然说lambda表达式是为了什么所谓的函数式编程,也是大家在社区千呼万唤才出来的,但是在我看来就是为了方(偷)便(懒)。
上面的代码写着麻烦,但是转换成下面这样的呢?
Arrays.sort(new Integer[]{1, 8, 7, 4},
(first,second) -> first.compareTo(second));
复制代码
这样看着多清爽,而且把一些不必要的细节都屏蔽了。对于这种只包含一个抽象方法的接口,你可以通过lambda接口来创建该接口的对象,这种接口被称为函数式接口。
lambda表达式引入了一个新的操作符: -> ,它把lambda表达式分为了2部分
(n) -> n*n 复制代码
左侧指定表达式所需的参数,如果不需要参数,也可以为空。右侧是lambda代码块,它指定lambda表达式的动作。
需要注意的是如果方法中只有一个返回的时候不用声明,默认会返回。如果有分支返回的时候需要都进行声明。
(n) -> {
if( n <= 10)
return n*n;
return n * 10;
}
复制代码
方法引用以及构造器引用
方法引用
有些时候,先要传递给其他代码的操作已经有实现的方法了。比如GUI中先要在按钮被点击时打印event对象,那么可以这样调用
button.setOnAction(event -> System.out.println(event)); 复制代码
这个时候我想偷懒,我不想写event参数,因为只有一个参数,jvm不能帮帮我吗?下面是修改好的代码
button.setOnAction(System.out::println); 复制代码
表达式 System.out::println 是一个方法引用,等同于lambda表达式 x -> System.out.println(x) 。**::**操作符将方法名和对象或类的名字分割开来,以下是三种主要的使用情况:
- 对象::实例方法
- 类::静态方法
- 类::实例方法
前两种情况,方法引用等同于提供方法参数的lambda表达式。比如 Math::pow ==== (x,y) -> Math.pow(x,y) 。
第三种情况,第一个参数会称为执行方法的对象。比如 String::compareToIgnoreCase ==== (x,y) -> x.compareToIgnoreCase(y) 。
还有 this::equals ==== x -> this.equals(x) , super::equals ==== super.equals(x) 。
构造器引用
List<String> strList = Arrays.asList("1","2","3");
Stream<Integer> stream = strList.stream().map(Integer::new);
复制代码
上面代码的 Integer::new 就是构造器引用,不同的是在构造器引用中方法名是new。如果存在多个构造器,编译器会从上下文推断并找出合适的那一个。
StreamAPI
Stream这个单词翻译过来就是流的意思,溪流的流,水流的流。
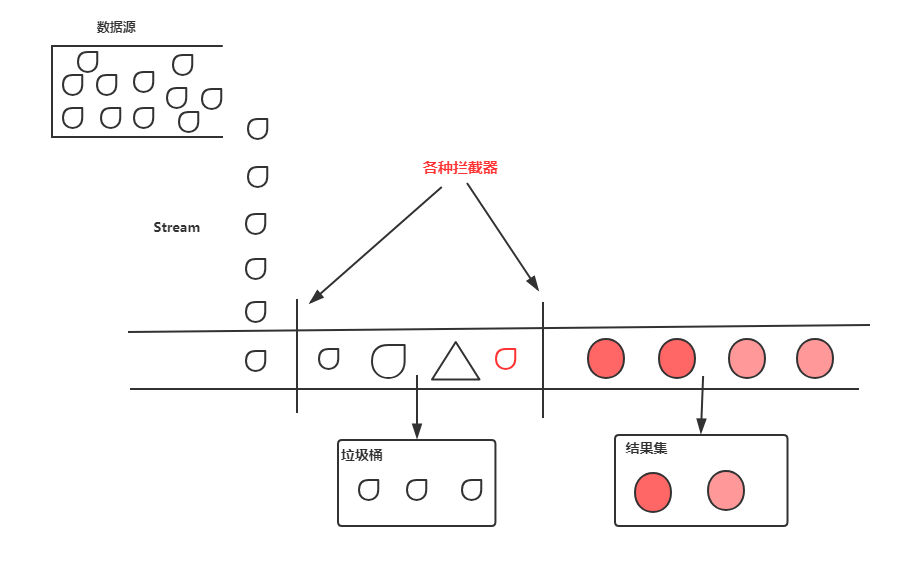
在我看来stream就像是上面的图一样,最开始的数据就是小水滴,它经过各种"拦截器"的处理之后,有的小水滴被丢弃,有的变大了,有的加上了颜色,有的变成了三角形。最后它们都变成了带有颜色的圆。最后被我们放到结果集中。我们很多时候写的代码是这样的:遍历一个集合,然后对集合的元素进行判断或者转换,满足条件的加入到新的集合里面去,这种处理方式就和上面的图是一样的。先来看一段代码
Map<String,Map<String,Integer>> resultMap = new HashMap<>();
Map<String,Integer> maleMap = new HashMap<>();
Map<String,Integer> femaleMap = new HashMap<>();
resultMap.put("male", maleMap);
resultMap.put("female",femaleMap);
for(int i = 0; i < list.size(); i++) {
Person person = list.get(i);
String gender = person.getGender();
String level = person.getLevel();
switch (gender) {
case "male":
Integer maleCount;
if("gold".equals(level)) {
maleCount = maleMap.get("gold");
maleMap.put("gold", null != maleCount ? maleCount + 1 : 1);
} else if("soliver".equals(level)){
maleCount = maleMap.get("soliver");
maleMap.put("soliver", null != maleCount ? maleCount + 1 : 1);
}
break;
case "female":
Integer femaleCount;
if("gold".equals(level)) {
femaleCount = femaleMap.get("gold");
femaleMap.put("gold", null != femaleCount ? femaleCount + 1 : 1);
} else if("soliver".equals(level)){
femaleCount = femaleMap.get("soliver");
femaleMap.put("soliver", null != femaleCount ? femaleCount + 1 : 1);
}
break;
}
}
复制代码
上面的代码作用是统计不同性别的工程师职级的人数,在Java StreamAPI出来之前,这样类似的业务代码在系统中应该是随处可见的,手打上面的代码我大概花了两分钟,有了Stream之后,我偷了个懒
Map<String,Map<String,Integer>> result = list.stream().collect(
Collectors.toMap(
person -> person.getGender(),
person -> Collections.singletonMap(person.getLevel(), 1),
(existValue,newValue) -> {
HashMap<String,Integer> newMap = new HashMap<>(existValue);
newValue.forEach((key,value) ->{
if(newMap.containsKey(key)) {
newMap.put(key, newMap.get(key) + 1);
} else {
newMap.put(key, value);
}
});
return newMap;
})
);
复制代码
或者改成这样的代码
Map<String,Map<String,Integer>> result = stream.collect(
Collectors.groupingBy(
Person::getGender,
Collectors.toMap(
person->person.getLevel(),
person -> 1,
(existValue,newValue) -> existValue + newValue
)
)
);
复制代码
不仅代码块减少了许多,甚至逻辑也更清晰了。真的是用stream一时爽,一直用一直爽呀。
Stream作为流,它可以是有限的可以是无限的,当然我们用得最多的还是有限的流(for循环就是有限的流),如上面那张图一样,我们可以对流中的元素做各种各样常见的处理。比如求和,过滤,分组,最大值,最小值等常见处理,所以现在就开始使用Stream吧
Stream的特性
- Stream自己不会存储元素,元素可能被存储在底层集合中,或者被生产出来。
- Stream操作符不会改变源对象,相反,他们会返回一个持有新对象的stream
- Stream操作符是延迟执行的,可能会等到需要结果的时候才去执行。
Stream API
| 函数式接口 | 参数类型 | 返回类型 | 抽象方法名 | 描述 | 其他方法 |
|---|---|---|---|---|---|
| Runnable | 无 | void | run | 执行一个没有参数和返回值的操作 | 无 |
| Supplier<T> | 无 | T | get | 提供一个T类型的值 | |
| Counsumer<T> | T | void | accept | 处理一个T类型的值 | chain |
| BiConsumer<T,U> | T,U | void | accept | 处理T类型和U类型的值 | chain |
| Function<T,R> | T | R | apply | 一个参数类型为T的函数 | compose,andThen,identity |
| BiFunction<T,U,R> | T,U | R | apply | 一个参数类型为T和U的函数 | andThen |
| UnaryOperator<T> | T | T | apply | 对类型T进行的一元操作 | compose,andThen,identity |
| BinaryOperator<T> | T,T | T | apply | 对类型T进行二元操作 | andThen |
| Predicate<T> | T | boolean | test | 一个计算boolean值的函数 | And,or,negate,isEqual |
| BiPredicate<T,U> | T,U | boolean | test | 一个含有两个参数,计算boolean值的函数 | and,or,negate |
map()和flatMap()的区别
使用map方法的时候,相当于对每个元素应用一个函数,并将返回的值收集到新的Stream中。
Stream<String[]> -> flatMap -> Stream<String>
Stream<Set<String>> -> flatMap -> Stream<String>
Stream<List<String>> -> flatMap -> Stream<String>
Stream<List<Object>> -> flatMap -> Stream<Object>
{{1,2}, {3,4}, {5,6} } -> flatMap -> {1,2,3,4,5,6}
复制代码
中间操作以及结束操作
Stream上的所有操作分为两类:中间操作和结束操作,中间操作只是一种标记(调用到这类方法,并没有真正开始流的遍历。),只有结束操作才会触发实际计算。简单的说就是API返回值仍然是Stream的就是中间操作,否则就是结束操作。
如何debug
IntStream.of(1,2,3,4,5).fiter(i -> {return i%2 == 0;})
IntStream.of(1,2,3,4,5).fiter(MyMath::isDouble)
那些不好理解的API
- reduce() 我们以前做累加是如何完成的呢?
int sum = 0;
for(int value in values) {
sum = sum + value;
}
复制代码
现在改成stream的方式来实现
values.stream().reduce(Integer::sum); 复制代码
这个reduce()方法就是一个二元函数:从流的前两个元素开始,不断将它应用到流中的其他元素上。
如何写好Stream代码
stream API就是为了方便而设计的,在sql层面并不方便处理的数据可以通过stream来实现分组,聚合,最大值,最小值,排序,求和等等操作。所以不要把它想得太复杂,只管写就好了。总有那么一天你熟练了就可以写出简洁得代码。或者从现在开始把你项目中的大量for循环改造成stream方式。
代码示例
本来想写大段代码来样式到stream API的转换,但是想了想完全没有必要,github上找了hutool工具类的部分代码来完成转换示例。(可以通过这种方式来提高stream api的能力)
- 计算每个元素出现的次数(请先想象下jdk7怎么实现)
代码效果:[a,b,c,c,c] -> a:1,b:1,c:3
Arrays.asList("a","b","c","c","c").stream().collect(Collectors.groupingBy(str->str, Collectors.counting()));
复制代码
- 以特定分隔符将集合转换为字符串,并添加前缀和后缀(请先想象下jdk7怎么实现)
List<String> myList = Arrays.asList("a","b","c","c","c");
myList.stream().collect(Collectors.joining(",","{","}"));
复制代码
- 判断列表不全为空(请先想象下jdk7怎么实现)
myList.stream().anyMatch(s -> !s.isEmpty()); 复制代码
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

