
死磕 Java 集合之 HashMap 源码分析
简介
HashMap采用key/value存储结构,每个key对应唯一的value,查询和修改的速度都很快,能达到O(1)的平均时间复杂度。它是非线程安全的,且不保证元素存储的顺序。
继承体系
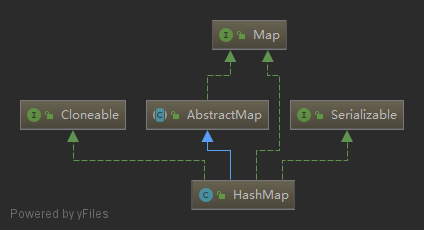
HashMap实现了Cloneable,可以被克隆。
HashMap实现了Serializable,可以被序列化。
HashMap继承自AbstractMap,实现了Map接口,具有Map的所有功能。
存储结构
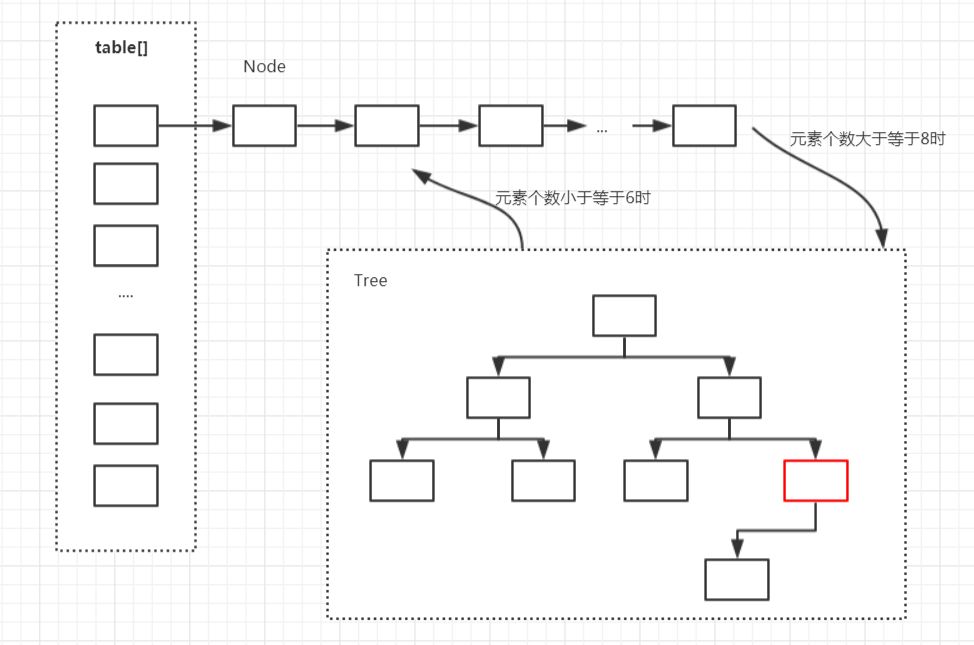
在Java中,HashMap的实现采用了(数组 + 链表 + 红黑树)的复杂结构,数组的一个元素又称作桶。
在添加元素时,会根据hash值算出元素在数组中的位置,如果该位置没有元素,则直接把元素放置在此处,如果该位置有元素了,则把元素以链表的形式放置在链表的尾部。
当一个链表的元素个数达到一定的数量(且数组的长度达到一定的长度)后,则把链表转化为红黑树,从而提高效率。
数组的查询效率为O(1),链表的查询效率是O(k),红黑树的查询效率是O(log k),k为桶中的元素个数,所以当元素数量非常多的时候,转化为红黑树能极大地提高效率。
源码解析
属性
(1)容量
容量为数组的长度,亦即桶的个数,默认为16,最大为2的30次方,当容量达到64时才可以树化。
(2)装载因子
装载因子用来计算容量达到多少时才进行扩容,默认装载因子为0.75。
(3)树化
树化,当容量达到64且链表的长度达到8时进行树化,当链表的长度小于6时反树化。
Node内部类
Node是一个典型的单链表节点,其中,hash用来存储key计算得来的hash值。
TreeNode内部类
这是一个神奇的类,它继承自LinkedHashMap中的Entry类,关于LInkedHashMap.Entry这个类我们后面再讲。
TreeNode是一个典型的树型节点,其中,prev是链表中的节点,用于在删除元素的时候可以快速找到它的前置节点。
HashMap()构造方法
空参构造方法,全部使用默认值。
HashMap(int initialCapacity)构造方法
调用HashMap(int initialCapacity, float loadFactor)构造方法,传入默认装载因子。
HashMap(int initialCapacity)构造方法
判断传入的初始容量和装载因子是否合法,并计算扩容门槛,扩容门槛为传入的初始容量往上取最近的2的n次方。
put(K key, V value)方法
添加元素的入口。
(1)计算key的hash值;
(2)如果桶(数组)数量为0,则初始化桶;
(3)如果key所在的桶没有元素,则直接插入;
(4)如果key所在的桶中的第一个元素的key与待插入的key相同,说明找到了元素,转后续流程(9)处理;
(5)如果第一个元素是树节点,则调用树节点的putTreeVal()寻找元素或插入树节点;
(6)如果不是以上三种情况,则遍历桶对应的链表查找key是否存在于链表中;
(7)如果找到了对应key的元素,则转后续流程(9)处理;
(8)如果没找到对应key的元素,则在链表最后插入一个新节点并判断是否需要树化;
(9)如果找到了对应key的元素,则判断是否需要替换旧值,并直接返回旧值;
(10)如果插入了元素,则数量加1并判断是否需要扩容;
resize()方法
扩容方法。
(1)如果使用是默认构造方法,则第一次插入元素时初始化为默认值,容量为16,扩容门槛为12;
(2)如果使用的是非默认构造方法,则第一次插入元素时初始化容量等于扩容门槛,扩容门槛在构造方法里等于传入容量向上最近的2的n次方;
(3)如果旧容量大于0,则新容量等于旧容量的2倍,但不超过最大容量2的30次方,新扩容门槛为旧扩容门槛的2倍;
(4)创建一个新容量的桶;
(5)搬移元素,原链表分化成两个链表,低位链表存储在原来桶的位置,高位链表搬移到原来桶的位置加旧容量的位置;
TreeNode.putTreeVal(...)方法
插入元素到红黑树中的方法。
(1)寻找根节点;
(2)从根节点开始查找;
(3)比较hash值及key值,如果都相同,直接返回,在putVal()方法中决定是否要替换value值;
(4)根据hash值及key值确定在树的左子树还是右子树查找,找到了直接返回;
(5)如果最后没有找到则在树的相应位置插入元素,并做平衡;
treeifyBin()方法
如果插入元素后链表的长度大于等于8则判断是否需要树化。
TreeNode.treeify()方法
真正树化的方法。
(1)从链表的第一个元素开始遍历;
(2)将第一个元素作为根节点;
(3)其它元素依次插入到红黑树中,再做平衡;
(4)将根节点移到链表第一元素的位置(因为平衡的时候根节点会改变);
get(Object key)方法
(1)计算key的hash值;
(2)找到key所在的桶及其第一个元素;
(3)如果第一个元素的key等于待查找的key,直接返回;
(4)如果第一个元素是树节点就按树的方式来查找,否则按链表方式查找;
TreeNode.getTreeNode(int h, Object k)方法
经典二叉查找树的查找过程,先根据hash值比较,再根据key值比较决定是查左子树还是右子树。
remove(Object key)方法
(1)先查找元素所在的节点;
(2)如果找到的节点是树节点,则按树的移除节点处理;
(3)如果找到的节点是桶中的第一个节点,则把第二个节点移到第一的位置;
(4)否则按链表删除节点处理;
(5)修改size,调用移除节点后置处理等;
TreeNode.removeTreeNode(...)方法
(1)TreeNode本身既是链表节点也是红黑树节点;
(2)先删除链表节点;
(3)再删除红黑树节点并做平衡;
总结
(1)HashMap是一种散列表,采用(数组 + 链表 + 红黑树)的存储结构;
(2)HashMap的默认初始容量为16(1<<4),默认装载因子为0.75f,容量总是2的n次方;
(3)HashMap扩容时每次容量变为原来的两倍;
(4)当桶的数量小于64时不会进行树化,只会扩容;
(5)当桶的数量大于64且单个桶中元素的数量大于8时,进行树化;
(6)当单个桶中元素数量小于6时,进行反树化;
(7)HashMap是非线程安全的容器;
(8)HashMap查找添加元素的时间复杂度都为O(1);
带详细注释的源码地址
https://gitee.com/alan-tang-tt/yuan/blob/master/%E6%AD%BB%E7%A3%95%20java%E9%9B%86%E5%90%88%E7%B3%BB%E5%88%97/code/HashMap.java
彩蛋
红黑树知多少?
红黑树具有以下5种性质:
(1)节点是红色或黑色。
(2)根节点是黑色。
(3)每个叶节点(NIL节点,空节点)是黑色的。
(4)每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
(5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
红黑树的时间复杂度为O(log n),与树的高度成正比。
红黑树每次的插入、删除操作都需要做平衡,平衡时有可能会改变根节点的位置,颜色转换,左旋,右旋等。
欢迎关注公众号“ 彤哥读源码 ”,查看有很多源码系列文章, 与彤哥一起畅游源码的海洋。

喜欢这篇文章
就点下在看哦 ▼
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

