SRE重案调查组 第二集 | 挖掘应用处理变慢的“真相”

供稿 | eBay Infrastructure Engineering
翻译&编辑 | 顾欣怡
本文共1942字,预计阅读时间6分钟
更多干货请关注“eBay技术荟”公众号
导读
eBay SRE部门经常处理生产环境中各种各样的疑难杂症, 此次探究的是应用处理变慢问题。 从监控系统入手,到 找出 根本原因是锁形成的顺序队列 ,不仅完美解决该问题,还为本部门积累了一笔宝贵的经验。
一、发现问题
一个风和日丽的下午,服务于 亿级 用户电商平台的监控系统 Sherlock.IO 上,突然出现了 黄色告警 。发出告警的是一个包裹配送相关的应用, 几分钟之内这个应用前端的负载均衡服务器(Load Balancer)上连接数量陡增 ,这引起了SRE团队稍微的不安和浓厚的兴趣。
二、初步分析
针对这种情况, 第一反应是:难道又是一波外部攻击 ? 经过初步排查,情况貌似没有那么糟糕。
首先,通过内部的追踪工具可以看出, 这些新增加的连接很有可能来自于内部。
其次,该应用十几台机器平均分布在 三个 数据中心,其中 两个 数据中心的应用还是一片岁月静好, 只有 一个 数据中心的应用看上去有些异常 。
整个电商平台的监控系统非常完备,从硬件到操作系统,再到应用内部各种指标数据一应俱全,且均是实时监控数据。查看该应用每个数据中心的处理请求数, 能明显看到 出问题的这个数据中心有更多的业务请求,并且是某个时间点突然增加。
尽管该应用在每个数据中心服务器的数量差别不大,可出问题的数据中心之前的处理业务请求数本来就偏多。
但是在请求增加之前, 三个 数据中心的事务处理时间(transaction time)和服务器繁忙线程数(server busy threads)数量相差无几。 出问题的这个数据中心事务处理时间明显变长,Tomcat繁忙线程数直线跃升,也给问题的查找指明了方向。
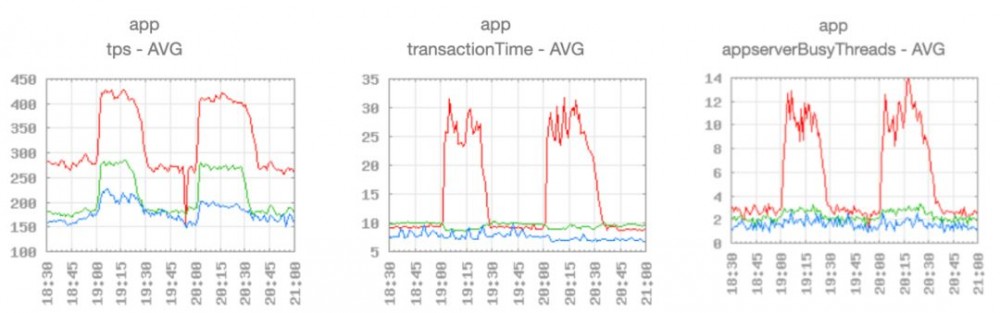
图1(点击查看大图)
从图1数据可以看出, 红线 代表的数据中心在 TPS(Transaction Per Second,每秒时间内能够处理的事务) 从平均 270 左右 增加到 420 左右 时( 1.56倍 ),平均的事务处理时间从 10毫秒 增加到原来的 2.7倍 左右。之前 TPS 270 左右时,只要平均 3个 Tomcat 线程 来处理,而现在平均繁忙线程需要 11个 左右( 3.2倍 )。
那么是什么原因让它在请求增加到原来 1.56倍 的时候,平均事务处理时间增加到原来的 2.7倍 呢?
三、深入探究
要回答这个问题,首先可能要问的是,增加的请求有什么特殊的地方?
带着这个问题,我们查看了这个应用处理的服务类型:它是微服务的一个组件,只处理一个特殊的请求,并且对时间延迟的要求也挺高(问题出现之前平均的延迟只有 10毫秒 左右)。
那么是不是新增加的请求有不一样的参数或者不同的有效负荷(payload)呢?
我们根据系统整体的指标数据,无法回答这个问题。不过既然是延迟增加,那就可以从 CAL ( eBay的集中式日志系统 ,能查看每个应用、服务及事务的详细日志)中去找一些线索。
仔细查看这些变长的业务日志,我们发现在两行日志中间,有一些可疑的时间间隔。出问题之前,这两行日志之间大概只有不到 1毫秒 左右时间差,出问题之后,却出现了 80毫秒 左右的延迟。
那么这两行之间到底出了什么问题? 是由于特殊的代码路径还是出于其他原因?
阅读这段源代码,并没有发现特殊的路径, 唯一值得怀疑的是:其中有些代码通过log4j输出日志 ,而不是由集中式的日志客户端写日志。正常情况下,所有的日志都应该写入这个集中式日志系统。 除此之外,这些log4j的日志是通过logger.debug() 打印的。
那么问题有没有可能是跟这些日志相关呢?
首先我们查找了服务器上的文件系统,并没有找到log4j的相关配置文件。log4j在默认的情况下,如果没有代码更改日志的级别,就会默认打印所有级别。 查看系统打印的日志文件,发现另一个与之相关并可疑的地方:日志内容正以每秒 3M 的速度产生。 日志文件里正是之前看到的debug打印的内容。
日志文件以这么快的速度写入,很值得怀疑, 因为log4j 1.* 版本是同步日志,写入文件会加锁,导致各个线程锁竞争。 为了验证这个问题,我们添加了一个 log4j 的配置文件,设置日志级别为 ERROR , 单独重启某台服务器之后,便看到了立竿见影的效果。
从下面图2和图3中的对比图可以看到,修改并重启之后,被修改的机器在流量比较大的时候,处理能力更强了,但事务处理时间并没有变长。
说明这个log4j的debug就是导致服务变差的根本原因。
图2及图3分别为TPS(每秒时间内能够处理的事务) 对比图 和 事务处理时间 对比图 , 绿线 代表修改配置的服务器, 红线 代表没有更改的服务器:
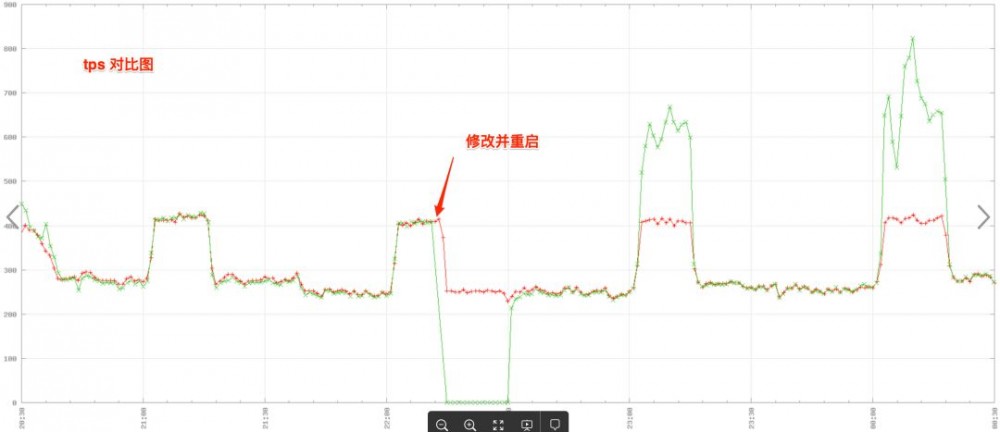
图2 TPS 对比图 (点击查看大图)
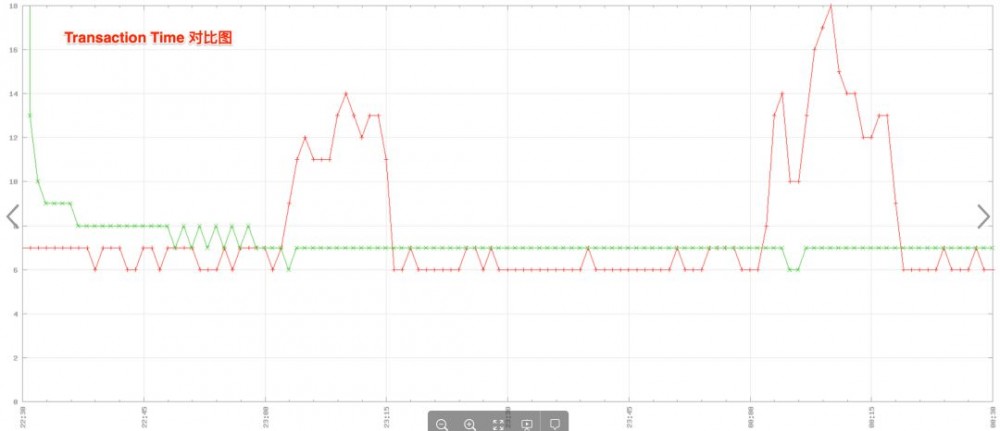
图3 事务处理时间 对比图(点击查看大图)
四、解决问题
问题确认之后,真正的元凶就很容易从源代码中弄清楚了。
出问题的代码是一个第三方代码库(jar lib),它使用log4j1.*版本去打印日志。该应用默认没有设置 log4j 的配置文件,所以debug信息也是打印出来的。且默认这些 debug 信息打印到了 System.out 里面。System.out是一个 PrintStream 对象,PrintStream的println方法里面使用了 synchronized 关键字去竞争锁 。
在并发比较低的时候,JVM使用偏向锁或者自旋锁,化解了重量级的同步操作。 在并发竞争比较激烈的情况下 ,JVM对synchronized的优化就无法发挥效果了,所以形成了一个同步顺序队列。 竞争越激烈,应用处理越慢。把日志级别设置成 ERROR 之后,就不打印这些debug信息了,这部分的锁也就被消除了。
五、总结
从这次事件中的数据可以看出,尽管一开始有锁存在,但在达到临界点之前,这个锁都不会造成太大影响。这也是 JVM对synchronized的优化 在起作用。而一旦超过临界点,变慢的效果就会被很快放大。
因此,当我们发现应用的事务处理时间变长的时候,不妨去看一下是不是某些锁导致系统形成一个顺序队列,让系统的处理能力变差。
下集预告:
不好!
某应用 80% 服务器上
GC overhead 频发 告警 !
JVM CPU 使用率 陡然升高!
ScheduledFutureTask竟达 4万多 ?
问题究竟出在哪里?
SRE 重案组
出动!
8月23日 下周五 ,敬请关注:
SRE重案调查组 第三集
一起 探索 HTTP 异步请求 的奥秘吧!
不见不散!
上集回顾:
SRE重案调查组 第一集 | 高延迟问题的罪魁祸首System.gc()

eBay2020校招 现已正式启动!详情点击下方链接:
2020校招 | 你想要的eBay全都有! eBay校园招聘正式启动!
你还可以:
↓点击 阅读原文 ,直接开启网申之旅!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

