走进JavaWeb技术世界2:JSP与Servlet的曾经与现在
微信公众号【黄小斜】大厂程序员,互联网行业新知,终身学习践行者。关注后回复「Java」、「Python」、「C++」、「大数据」、「机器学习」、「算法」、「AI」、「Android」、「前端」、「iOS」、「考研」、「BAT」、「校招」、「笔试」、「面试」、「面经」、「计算机基础」、「LeetCode」 等关键字可以获取对应的免费学习资料。

转自:微信公众号 码农翻身
这个问题来自于QQ网友,一句两句说不清楚,索性写个文章。
我刚开始做Web开发的时候,根本没有前端,后端之说。
原因很简单,那个时候服务器端的代码就是一切:接受浏览器的请求,实现业务逻辑,访问数据库,用JSP生成HTML,然后发送给浏览器。
即使后来Javascript在浏览器中添加了一些AJAX的效果,那也是锦上添花,绝对不敢造次。因为页面的HTML主要还是用所谓“套模板”的方式生成:美工生成HTML模板,程序员用JSP,Veloctiy,FreeMaker等技术把动态的内容添加上去,仅此而已。
那个时候最流行的图是这个样子:

在最初的J2EE体系中,这个表示层可不仅仅是浏览器中运行的页面,还包括Java写的桌面端,只是Java在桌面端太不争气, 没有发展起来。
每个程序员都是所谓“全栈”工程师,不仅要搞定HTML, JavaScript, CSS,还要实现业务逻辑,编写访问数据库的代码。等到部署的时候,就把所有的代码打成一个WAR包,往Tomcat指定的目录一扔,测试一下没问题,收工回家!
不差钱的公司会把程序部署到Weblogic,Websphere这样的应用服务器中,还会用上高大上的EJB。
虽然看起来生活“简单”又“惬意”,但实际上也需要实现那些多变的、不讲逻辑的业务需求,苦逼的本质并没有改变。
1前后端的分离
随着大家对浏览器页面的视觉和交互要求越来越高,“套模板”的方式渐渐无法满足要求,这个所谓的表示层慢慢地迁移到浏览器当中去了,一大批像Angular, ReactJS之类的框架崛起,前后端分离了!
后端的工程师只负责提供接口和数据,专注于业务逻辑的实现,前端取到数据后在浏览器中展示,各司其职。
像Java这样的语言很适合去实现复杂的业务逻辑,尤其是一些MIS系统,行业软件如税务、电力、烟草、金融,通信等等。 所以剥离表示层,只做后端挺合适的。
但是如果仅仅是实现业务逻辑,那后端也不会需要这么多技术了,搞定SSH/SSM就行了。
2后端技术
互联网,尤其是移动互联网开始兴起以后,海量的用户呼啸而来,一个单机部署的小小War包肯定是撑不住了,必须得做分布式。
原来的单个Tomcat得变成Tomcat的集群,前边弄个Web服务器做请求的负载均衡,不仅如此,还得考虑状态问题,session的一致性。
(老刘注:参见文章《 小白科普:分布式和集群 》)
业务越来越复杂,我们不得不把某些业务放到一个机器(或集群)上,把另外一部分业务放到另外一个机器(或集群)上,虽然系统的计算能力,处理能力大大增强,但是这些系统之间的通信就变成了头疼的问题,消息队列(MQ),RPC框架(如Dubbo)应运而生,为了提高通信效率,各种序列化的工具(如Protobuf)也争先空后地问世。
单个数据库也撑不住了,那就做数据库的读写分离,如果还不行,就做分库和分表,把原有的数据库垂直地切一切,或者水平地切一切, 但不管怎么切,都会让应用程序的访问非常麻烦,因为数据要跨库做Join/排序,还需要事务,为了解决这个问题,又有各种各样“数据访问中间件”的工具和产品诞生。
为了最大程度地提高性能,缓存肯定少不了,可以在本机做缓存(如Ehcache),也可以做分布式缓存(如Redis),如何搞数据分片,数据迁移,失效转移,这又是一个超级大的主题了。
互联网用户喜欢上传图片和文件,还得搞一个分布式的文件系统(如FastDFS),要求高可用,高可靠。
数据量大了,搜索的需求就自然而然地浮出水面,你得弄一个支持全文索引的搜索引擎(如Elasticsearch ,Solr)出来。
林子大了,什么鸟都有,必须得考虑安全,数据的加密/解密,签名、证书,防止SQL注入,XSS/CSRF等各种攻击。
3“大后端”
前面提到了这么多的系统,还都是分布式的,每次上线,运维的同学说:把这么多系统协调好,把老子都累死了。
得把持续集成做好,能自动化地部署,自动化测试(其实前端也是如此),后来出现了一个革命化的技术docker, 能够让开发、测试、生成环境保持一致,系统原来只是在环境(如Ngnix, JVM,Tomcat,MySQL等)上部署代码,现在把代码和环境一并打包, 运维的工作一下子就简化了。
公司自己购买服务器比较贵,维护也很麻烦,又难于弹性地增长,那就搞点虚拟的服务器吧,硬盘、内存都可以动态扩展(反正是虚拟的), 访问量大的时候多用点,没啥访问量了就释放一点,按需分配,很方便,这就是云计算的一个场景。
随着时间的推移,各个公司和系统收集的数据越来越多,都堆成一座大山了,难道就放在那里白白地浪费硬盘空间吗?
有人就惊奇地发现,咦,我们利用这些数据搞点事情啊, 比如把数据好好分析一下,预测一下这个用户的购买/阅读/浏览习惯,给他推荐一点东西嘛。
可是这么多数据,用传统的方式计算好几天甚至好几个月才能出个结果,到时候黄花菜都凉了,所以也得利用分布式的技术,想办法把计算分到各个计算机去,然后再把计算结果收回来, 时势造英雄,Hadoop及其生态系统就应运而生了。
之前听说过一个大前端的概念,把移动端和网页端都归结为“前端”,我这里造个词“大后端”,把那些用户直接接触不到的、发生在服务器端的都归结进来。
4怎么学?
现在无论是前端还是后端,技术领域多如牛毛,都严重地细分了,所以我认为真正的全栈工程师根本不存在,因为一个人精力有限,不可能搞定这么多技术领域,太难了。
培训机构所说的“全栈”,我认为就是前后端还在拉拉扯扯,藕断丝连,没有彻底分离的时候的“全栈”工程师。
那么问题来了, 后端这么多东西,我该怎么学?
之前写过一篇文章叫做《 上天还是入地 》,说了学习的广度和深度,在这里也是相通的。
往深度挖掘,可以成为某个技术领域的专家,如搜索方面的专家、安全方面的专家,分布式文件的专家等等,不管是哪个领域,重点都不是学会使用某个工具和框架, 而是保证你可以自己的知识和技术去搞定这个领域的顶尖问题。
往广度发展,各个技术领域都要了解,对于某种需求,能够选取合适的软件和技术架构来实现它,把需求转化成合适的技术组件,让这些组件以合适的方式连接、部署、运行,这也需要持续地学习和不断的经验积累。
最后,以一张漫画来结束吧!

(完)
我为什么对后端编程情有独钟?
转自: 老刘 码农翻身 2017-05-10
这几年前端很热闹,发展也很快, Angular, React, Vue ... 等各种各样的新技术层出不穷, 并且不断地抢后端的饭碗。 比如说著名的Model - View -Controller , 原来前端只负责View层,展示数据,现在前后端分离, 前端把控制层Controller 也给抢走了, 可怜的后端程序猿只剩下RESTful服务提供的数据了, 再加上Node.js趁火打劫,入侵服务器端, 有木有危机感?
但我还是对后端编程情有独钟, 原因很简单, 相比GUI编程, 我更喜欢API编程, 有点费解? 听我慢慢道来。
1 单机时代的GUI
最早的时候我其实也是挺喜欢GUI编程的, 谁愿意只在命令行下折腾呢?
作为“初恋”的C语言,虽然功能强大、效率高, 但是只能在命令行窗口写点小程序, 很无趣。
后来遇到VB, 不由的眼前一亮: 哇塞, 还能这么写程序! 创建一个窗体,把各种各样的控件拖动上去, 摆好位置, 设好属性,然后双击,在onClick方法中写下代码就ok了。
号称VB杀手的Delphi 也类似, 都是所谓的RAD(Rapid Application Development) 。
当时的控件多如牛毛,上了年纪的程序员应该还记得CSDN出的《程序员大本营》, 里边有张光盘,全是程序猿们开发的VB控件, 你想发送邮件, 拖动一个不可见的SMTP控件过来, 设定邮箱服务器和端口, 直接就可以发信, 非常简单。 你想用一个定时器功能, 没问题,那里有个定时器控件,可以直接使用 , 这才是真正的组件化开发。
由于开发出来的应用只能在PC上, 在Windows上运行, 不会出现如今手机端各种各样的适配问题,垄断在某些时候也是好处啊。
虽然这些桌面应用程序不像Web页面那样美轮美奂, 但对于我这个缺乏艺术细胞的人来说, 这是GUI编程的黄金时代。
2 Web GUI
好景不长, 技术变迁很快, Web时代来临了。
于是开始学HTML, CSS, Javascript, 忙着折腾个人主页, 做了没多久就意识到, 用HTML产生页面布局怎么这么麻烦,当时CSS还不普及 , 页面布局全靠一个表格套一个表格来做, 如果没有Dreamweaver, Frontpage 这样的软件帮忙, 这些<tr><td>标签绝对会把人淹死。
光有布局还不行,还得弄图片, 调颜色, 我在大学还学了photoshop , 想着自己设计。后来看到一本书上的例子, 在photoshop中不使用任何外界图片, 从零开始做出一个可口可乐易拉罐出来, 那光影效果当时就把我震撼了, 立刻意识到自己不是搞艺术的这块料, 还是老老实实的回去写程序去吧。
个人主页怎么办? 我就Copy了一个别人的网站, 改了改,变成了这个样子(图片没有显示):
忘了Copy谁的网站了, 向原作者表示歉意,当时是学生,知识产权意识不够,搁现在肯定得掏钱去买。
现在一般的开发团队都配有美工, 可以设计界面,设计完还能“切图”,形成漂亮的html+css的静态页面, 接下来的问题就是怎么把静态的网页变成动态的网页, 这就八仙过海,各显神通了。
传统的方式就是在服务器端完成, 利用各种各样的模板技术, 在静态页面中加上动态内容, 直接生成HTML UI元素。
最近流行的就是让浏览器来负责, 通过js 调用后端API,把数据变成HTML UI元素后展示出来。
不管是那种方式, CSS都是不可或缺的。因为它控制了页面的布局结构, 又是布局,快逃!
3 Java GUI
上了Java的贼船以后, 也做了一些GUI的工作, 相比于VB/Delphi拖放控件的便捷, 用Java写界面简直就是地狱!
虽然也有图形化的界面编辑器, 也可以拖放控件, 但是自动生成的代码那叫一个惨不忍睹。 更悲催的是,稍微手工改动一下, 那个界面编辑器就可能不认了。 绝大多数情况下还是直接写代码来生成界面。 (再次大声疾呼:不要再Swing和AWT上浪费精力,用的极少。 )
这里必须说一下Java和VB在界面编程的区别, Java 的界面全是用代码来生成的,就是说你需要写代码创建一个按钮, 写代码把这个按钮放到什么地方去, 所以即使是GUI程序, 最终的表现形式也只是Java 文件而已。
VB则不同,它专门有个.frm文件, 里边存储所有界面控件和布局的信息, 最终也需要把.frm打包发布。 所以在编辑界面这一点, VB和Dephi 是非常方便的。
程序员们这么痛苦, 那些大牛肯定会来解救我们的, 比方说能不能用XML来描述界面啊, 在XML中把各个控件及其布局关系都给描述好, 由系统读取,创建界面,就像原来的.frm文件一样。 Android 不就是这么干的吗?
但是XML文件读起来也够痛苦的, 为了灵活性, 这个XML文件还不能隐藏起来,有时候还要手工去改, 改完还不容易看到真正的效果, 唉,想想就头大。
更不用说Android的适配问题了, 不同屏幕尺寸,不同的分辨率, 不同的像素密度给程序员带来了极大的工作量。
(每个矩形代表一种设备)
4 后端编程
啰嗦了这么多, 其实就想表达一个中心思想: 我是有点害怕GUI编程。 而Web 前端和App前端都是在和GUI打交道。
我甚至想,这可能和内向的性格有关系, 擅长和机器打交道, 不擅长和人打交道。 前端需要琢磨用户的心理、使用习惯、用户体验, 这不是我的优势。
在软件编程领域, 与其费力不讨好的补上短板, 不如把自己的长处发挥到极致。
既然如此,那就呆在后端编程吧, 这里没有GUI, 只有API。 悄悄地躲在电脑的背后, 给Web前端和App前端提供服务, 让他们调用。
有人会说: 前端把Controller和View都拿走了, 后端就是个API的提供者,能折腾啥啊。
别小看后端编程,后端是非常有技术含量的,像什么高并发、缓存、负载均衡、分布式、消息队列、安全、搜索、数据复制.... 每个方向都值得静下心来去深挖。
不管前端技术怎么变化, 作为提供服务的后端总是要存在的,这是一大优势。
后端编程还有一个优势就是相对稳定, 比起大爆炸的前端,后端技术的变化要缓慢一些, 心思不会那么浮躁, 有很多知识可以慢慢的沉淀。
对于那些不喜欢做GUI的同学,不妨考虑下后端编程。
J2EE到底是何方神圣
一、J2EE历史
前言:
昨天下午有同学问我Java EE是干什么用的,能开发什么系统, 我在QQ中敲了很多字,掰扯了半天,终于给他整明白了。
我突然意识在其实很多初学者对Java EE的来龙去脉并去清楚, 大家并不知道为什么会出现这个技术, 要解决什么问题。 所以就写了这篇文章介绍下Java EE的历史。
-----------------------------------------------------------------------
先把时间扯的远一点, 94年我上高中的时候, 见过亲戚家有过电脑, 很好奇, 虽然上面都是一些单机桌面程序, 根本上不了网, 但是一个小小的扫雷程序就足以吸引很多眼球了。
后来上了大学, 接触电脑越来越多, 局域网已经普及, 互联网开始抬头,这时候C/S (Client-Server )结构的程序开始出现了,例如QQ,游戏, 还有著名的PowerBuilder 开发的MIS(管理信息系统), 都是典型的客户端-服务器结构, 程序运行在个人的电脑上,和服务器通信。
C/S 软件界面可以整的很漂亮, 用户体验很好, 但是缺点也很明显, 就是用户必须要安装客户端, 并且需要升级客户端来用新功能, 这样就带来两个问题
(1) 服务器端发生变化, 一定要能兼容很多客户端版本,要不然有的客户端软件就运行不了了, 因为客户不一定升级。
(2) 可能会出现DLL 地狱问题 -- 自己百度下啥是DLL 地狱。
再后来Web速度快了, 带宽也够了, 大家发现, Web页面也能做的很漂亮了, 把程序放到服务器端, 用浏览器访问多好, 用户也不用安装,所有功能都是即时更新。
但是html只是静态的,怎么才能变成动态的, 可交互的呢?
CGI 技术出现了, CGI 允许web服务器调用外部的程序, 并把结果输出到Web浏览器, 这样就能根据用户的操作生产不同的动态页面了。
在我读大学的年代, CGI 最常见的就是实现一个计数器, 看着自己的主页访问量慢慢的增长,那种感觉是很爽的。
当然,使用CGI 最苦逼的就是需要用程序输出html , 那可是整个网页的html , 不是其中的一个片段 !
换句话说, 程序员只能在代码里写html, 而不能在html里写代码 。 你可以想象一下用C 语言或者Perl 写CGI脚本的程序员那种咬牙切齿的感觉。
举个例子, 通过浏览器提交了用户名/ 密码, cgi 会这么做:
if (name=="liuxin" and password == "xxxx" ) {
println ("<html>");
println ("<head>");
println ("<title>欢迎</title>");
println ("</title>");
println("<body>")
println("<table>")
println("<tr><td>") ..... 我实在是写不下去了,太崩溃了, 这是伪码, 不要和我较劲...............
println("</td></tr>")
println("</table>")
println("</body>")
print("</html>")
}
这个时候我们赖以糊口的Java 在干嘛?
Java是Sun 发明的, 当然Sun 现在已经被Oracle 收购了。
Java 其实是依靠Applet ,依靠互联网才起家发达的, 大家在简陋的页面上突然看到当时极为炫目的Applet 小动画, 立刻就震惊了。
但悲剧的是大家发现Applet 除了用来演示以外, 似乎没有找到真正的用武之地。
浏览器还必须得装个java 插件, 后来微软为了阻止Java 还在自己浏览器IE中使坏 :-) , 这个插件运行一直不太稳定。
Java 看到CGI 技术发展的不错, 自己也搞一个类似的吧, 这就是Servlet , 由于提供了一个request, response, session等支持, 用起来比CGI方便多了。
但是输出html这一块没有任何改进, 还得程序员一句一句的输出html.
06年我进IBM的时候发现有个项目是在用servlet 输出页面html ,完全没用jsp, 我也就见怪不怪了, 这肯定是个90年代的遗留应用。
最后大家都受不了这种极为痛苦的输出方式, 于是Sun 就弄了个JSP , 微软也不甘示弱, 出了个ASP。
这下子Web开发出现了跃进,因为不管是JSP还是ASP, 都是所谓的 Server Page , 也就是说程序员终于可以把逻辑代码和html混在一起了! 在也不用一行一行的输出html了。
当然现在老师教导你, jsp中不要有逻辑代码, 但在当时,这可是了不起的突破 。
我们可以先让美工把页面设计好, 然后把程序嵌入进去就行了。
再后来出现了Struts, 使用MVC解决了职责划分问题, Web 应用迈向了新的台阶, 开始飞速发展, 对于这种应用,我们称为 B/S 结构, 即Browser(浏览器)-Server (服务器) 。
C/S结构的程序当然不会消亡, 因为像聊天,视频,游戏等对性能, 界面,用户体验要求很高, 天然适合桌面程序实现。
为了支持更大,更复杂的应用开发, 微软为ASP 添加了实现业务逻辑的COM, COM+ ,访问数据库的ADO 等技术。
而Sun和Java 社区有更大的野心,他们提出了一套更大的, 不同于传统应用开发的架构,专门用于满足企业级开发的需求。
这些需求包括数据库, 邮件, 消息,事务处理, Java 对这些通用的需求做了抽象,形成了一些规范和标准,除了Servelt 和 JSP ,还有EJB, JMS , JDBC 等等。
这些东西,Sun 把他们称为J2EE 。
为啥不是Java EE ? 那个2是怎么回事?
这完全是一种市场策略, 原来Java 的版本是1.1 , 从1.2开始, Sun 称之为为Java 2 平台 , 以便告诉大家,这是一个突破性的技术平台。 实际上也确实有所突破, Java 被分成了 J2SE (标准版) , J2EE(企业版) 和J2ME(移动版) , 当然移动版在手机上一直没有发展起来, 直到Android的出现--这是后话了。
到了2005年, Sun 又取消了那个 “2” , 于是就变成了 Java SE, Java EE, Java ME 了。
J2EE需要运行在一个叫应用服务器的东西里, 这就是Weblogic, websphere , jboss, 也称为应用中间件。
J2EE发展的非常迅猛, 迅速统治了Web应用开发市场, 微软的ASP只能偏居一隅了, 后来推出.NET 才算扳回一城。
我们走了漫长的路, 终于来到你的面前, 现在你知道Java EE 是干啥的了吧 :-)
在后来的故事估计很多人都听过了,Java EE远远没有宣传的那么美好, EJB, 尤其是Entity Bean 极为难用, 对业务代码侵入性极强, 在大家想抛弃而又没有替代品的时候, 有一位大牛Rod Johnson如约而至,他说我们不要这种臃肿,低效,脱离现实的J2EE, 我们要灵活,轻便,轻量级的框架, 这就是Spring, 我们就有了依赖注入,AOP....
有位叫Gavin King的澳大利亚小伙子也是在忍受不了EJB的O/R Mapping , 自己整了一个Hibernate 。
再加上更早出现的Struts, 我们Java 程序员终于过起了幸福的SSH生活。
二、J2EE入门指南
前言
这是写给零基础小白的一系列文章。
为啥叫生存指南呢, 因为Java发展了20年, 现在已经不仅仅是一个单纯的语言了, 而是一套完整的生态系统, 其中的术语像 HTML, XML, CSS, Javascript , AJAX, JQuery,Prototype, HTTP, Tomcat, JBoss, Nginx , Memecached , Redis, MVC ,Servlet, JSP, Struts, Hibernate, myBatis , Spring, JFinal, MySql, JDBC, EJB, JMS, Swing , AWT, Reflection, OSGi... 铺面而来, 搞的你头晕脑胀, 无所适从,很容易就Lost了。
所以写这个文章的目的就是帮助小白能在Java 的汪洋大海里生存, 时不时的能冒出水面喘口气, 看看空中的生存指南, 把握自己的方向继续向前。
-------------------------------------------------------------
先回答一个问题? 为什么要学习Java ?
我想原因无非有这么几点
1. 我周围的人都在学, 所以我也学
2. Java 好找工作啊, 确实是,在中国,软件行业还处于模仿、学习美国鬼子的阶段, 做系统级编程的不是没有, 像BAT就会用到。 不过绝大部分公司还都是搞应用级程序的开发, 所以Java, 尤其是Java EE 工作机会是非常多的。
3. Java 看起来挺简单的。
Java 语言本身看起来确实挺简单的, 不像C语言, 一个指针就把你搞迷糊了;
也不像C++, 语法复杂而诡异, new 了一个对象以后还得记住 释放内存,确实是挺悲催的;
Java 即使加上了面向对象(封装,继承,多态), 也是简单的令人发指, 不用上大学,高中生,甚至初中生都能看明白。
可是你会发现学了基本的Java 以后, 除了能写个水仙花数, 九九乘法表,还是啥也干不了,更别说月薪过万了。
人家公司至少要求精通SSH,AJAX,JQuery ,CSS,mysql , 这条路走起来就不那么容易了。
再看第二个问题: Java 到底能干什么?
一句话, Java 最擅长的就是Web 应用开发(通俗的讲就是网站开发),不善长桌面应用开发。
你想想你开发一个Java 桌面应用, 还得让用户下载一个Java 虚拟机, 甚至要设置环境变量, 一般人是搞不定的。 此外Java 内置的Swing ,AWT确实不怎么样, 开发出来的界面距离操作系统原生界面差了很远, 所以除了特殊情况, 奉劝那些还在孜孜不倦的研究Java 界面编程(Swing, AWT)的同学还是不要浪费精力了, 不要硬逼着Java干他不擅长也不不愿意做的事情。
所以咱们就聊聊Java Web 开发中用到的那些技术和术语。
先来说说HTML, 咱们想象一个场景, 互联网还没有出现, 你是个球迷+程序员, 电脑里有很多的记录足球的文件例如 足球.txt, 巴塞罗那.txt , 曼联.txt .....
其中足球.txt 中有一个词"巴萨罗那" , 为了方便, 你想点这4个字就打开另外一个文件“巴赛罗那.txt” 立刻就能看看球队的介绍 ,这该怎么办?
你冥思苦想,终于顿悟了, 可以这么干: 定义一个协议 巴塞罗那 , 然后开发一个软件, 把所有的文本都管理起来, 遇到像这样的东西, 软件就认为这是一个链接, 点击后就打开另外一个文件 !
这的确是个好主意,其实在1989年, 万维网的发明人蒂姆·伯纳斯·李也是这么干的, 你看你要是早出生20年,估计也是WWW的发明人了。
加了链接以后, 文本就不是不同的文本了, 而升级为超文本 (Hypertext)了 !
但是如果你的“足球.txt”还有“广州恒大”几个字, 但是广州恒大的介绍是在你哥们的电脑上, 而他也想把他的文本能链接到你的电脑文件上,这怎么办?
一个单机运行的软件就不行的, 必须得有网络 , 有网络还不够,你得解决通信的问题。
你就想:既然上面的文本是超文本,并且需要把你好哥们的文本传输到你的电脑上才能看, 那通信方法就叫做超文本传输协议吧 HyperText Transfer Protocol , 简称Http。
于是你又扩展上一个程序, 不但把你的文本文件都管理起来,还允许通过网络访问, 别人要想通过网络看你的文件, 得发个这样的命令给你的软件:
http://192.168.0.10/football/... 。 你的程序就会找到football 目录下的 巴萨罗那.txt , 读出内容, 发给对方, 并且给他说: 200 成功
如果找不到, 软件就告诉他: 404 对不起,找不到 。
如果你的软件在处理过程中出了错 , 软件就说: 500 唉, 服务器出错了。
这个软件功能强大,专门在网络上别人服务,就叫网络服务器吧,可以起个名字叫Apache 。
可是只看文字太不爽了, 你还想看表格,列表,图片,甚至视频。 干脆自己定义一个描述界面的语言吧, 像这样:
<table> ---表示表格
<li> --- 表示列表
<image> -- 表示图片。
这些都称为标记(markup) , 所以现在你的超文本就更加丰富了, 这个语言就叫做 Hyper Text Markup Language , 简称为 HTML。
原来的软件只能显示文本和处理链接, 现在还需要能处理这些标签, 遇到不同的标签, 就显示相应的内容 。
现在你把你的文本全部用html改写了一遍, 放到了Apache 服务器中, 你的哥们也把他的html放到了他的Apache服务器上, 当然你们的html之间还保持着链接 。 然后你们就可以用新的软件对这些html进行浏览了, 对了,可以把这个软件称为浏览器。
由于方便,快捷,能发布图文并茂的信息, 更关键的是可以把散布在全世界各个角落中的计算机连接在一起, HTML , HTTP, 网络服务器,浏览器 迅速普及, 人们上网在也不用使用那些难用的telnet , ftp 了。 网络就变成了这样:
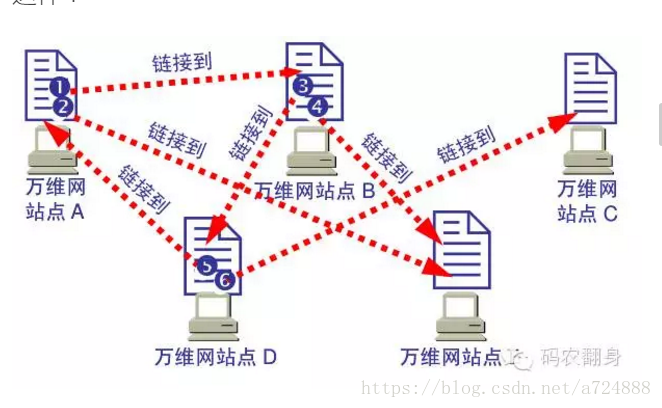
下面的文字来源于百度百科:
因为在互联网技术上的杰出贡献,伯纳斯·李被业界公认为“互联网之父”。他的发明改变了全球信息化的传统模式,带来了一个信息交流的全新时代。然而比他的发明更伟大的是,伯纳斯·李并没有像其他人那样为“WWW”申请专利或限制它的使用,而是无偿的向全世界开放。伯纳斯·李本来可以在金钱上与盖茨一比高低,但他的这一举措却为互联网的全球化普及翻开了里程碑式的篇章,让所有人都有机会接触到互联网,也圆了那些。com公司创建者们的富翁梦。即便如此,伯纳斯·李仍然十分谦虚,总是以一种平静的口气回应:“我想,我没有发明互联网,我只是找到了一种更好的方法。”

互联网之父 伯纳斯·李
接上篇《给小白的Java EE生存指南》 , 你可以通过公共号的消息历史中查看。 今天继续聊Web的事情。
上次说到你发明了html , http, 浏览器, web服务器, 这下子把整个世界的信息都链接成了一个了一个大网: world wide web
可是你注意到一个问题没有, 这些html都是静态的 , 也就是说你除了浏览你的网站和别人的网站之外,什么都做不成。 用你发明的HTTP术语来讲, 就是现在的互联网, 只支持 “GET”
比如说, 你看了哥们的网站,知道广州恒大夺得了2015亚冠冠军, 想给他留个言表示一下兴奋之情,这就做不到了。
这是不能令你满意的, 对互联网做扩展吧
先扩展HTML ,加上一堆新标签 像<form>了, 了 什么type=text, radio, textarea,checkbox 。。。 这样你就可以在html中支持输入各式各样的信息了。
你还得扩展HTTP协议, 引入一个“POST”这样可以把数据发到Web服务器。
Web 服务器当然也得扩展, 接收到POST过来的留言数据以后, 肯定得想办法处理啊 ,怎么处理?
无非就是新生成一个html , 除了把原有的数据保留以外,还要把新的留言相关的数据“动态”的加上去, 这就是所谓的动态页面。
必须得有程序来办这件事情, 你马上就面临两个问题:
(1) 用什么语言来写, 毕竟有那么多语言像C, Perl , Python, 甚至Java 都在虎视眈眈呢
(2) 这个程序怎么和 Web 服务器交互
解决方法也很简单, 你弄了了一个叫做 Common Gateway Interface (简称CGI) 的东西, 定义了标准的输入(STDIN)和输出(STDOUT), 所有的程序都可以从STDIN 读入数据,处理后形成html, 然后向STDOUT 输出 。
这下子任何语言都可以写cgi程序了, 网页也变成了“可交互式”的, 整个互联网又向前推进了一大步, 各种各样的商业网站如雨后春笋一般发展起来。
( ps : 现在CGI 技术已经过时了, ASP, JSP, PHP等技术是主流。
在Java的世界里, 把Apache ,Ngnix 这样的服务器称为静态内容服务器, 主要处理像图片/文件件这样不变的,只读的静态资源,性能非常好; 把Tomcat, JBoss ,Websphere, Weblogic等称为动态内容服务器, 主要产生动态内容。
一般的设计会把Apache/Ngnix 放的前边,接收所有的Http 请求,如果是静态资源,就直接处理掉, 如果是动态资源,就转发到Tomcat/Jboss 去处理。 )
等等,还有个小问题, 我的留言我能看到, 别人的留言我也想看到改怎么办? 很明显, 每个人通过浏览器提交的留言都需要保存起来, 在生成页面的时候动态的读取他们,形成html 。
可以把所有的用户留言都存放到一个文件当中,读取文件形成html没有任何压力, 但是你要非常小心处理同步的问题:你提交留言的时候,别人也在提交, 可不能相互覆盖啊 !
这也是为什么Web程序都有一个数据库的原因, 数据库帮我们解决了这些乱七八糟的同步问题, 我们只需要向数据库发出 Select, Insert, Upate ,Delete 就好了。数据库的历史要比WWW久远的多, 早在大机时代就出现了, 现在已经发展的非常成熟 , 直接拿过来用就可以了。
解决了用户留言的问题, 你接下来要写一个网上售票的应用, 让大家在网上买球票, 买票的时候需要一个购物车, 大家可以把票暂时放到购物车里。
开发购物车的时候发现了你设计的HTTP一个非常严重的缺陷 : 没有状态 , 因为用户往购物车里加了一个球票, 一刷新页面购物车就空了,里边的所有东西都丢失了。
假设用户A在操作, 用户B也在操作, 你的Apache服务器实际上根本区分不出来谁是用户A, 谁是用户B, 只是看到了一个个毫无关联的GET和POST 。 根本记录不下来同一个用户在过去一段时间内做了什么事情。
你想改一下HTTP协议, 可是悲催的是数以亿计的网站已经在用了, 你想改都改不了了。
于是你想了个办法, HTTP 协议不是有个header吗, 在里边做做手脚 :
浏览器A第一次给服务器发送请求时, 服务器通过header告诉它一个编号number_a,浏览器A需要记住这个编号, 然后下次请求的时候(以及后续所有请求的时候)也通过header 把number_a 发给服务器。 这样服务器一看, 奥,原来你是浏览器A 啊, 就可以把浏览器A相关的购物车数据从内存中取出来, 形成html 发回浏览器A了。
浏览器A和服务器的这个通过这个编号来交互, 这个过程就称为 : session
用了这一个小伎俩, 这样服务器就把各个浏览器(各个用户)给区分开了。
到目前为止,构建一个Web系统最基础的工作可以说已经完成了, 我想起来高中时物理老师说的一句话: 牛顿三定律出来以后 ,经典物理学的大厦已经建立起来了, 后人的工作无非是刷刷墙, 装饰装饰而已。
对于互联网也是: HTTP + HTML + Web服务器 + 数据库 就是WWW的基石, 后续的工作都是为了提高生产率做的包装和装饰。
最后简单做一个总结: 其实发明创造并没有那么难, 马云说过, 哪里有抱怨,哪里就有机会, 所以找一找现在你感觉最不爽的地方, 也许能发明下一代互联网呢。
前两篇文章 《给小白的Java EE生存指南(1)》 和《给小白的Java EE生存指南(2)》 (注:回复关键字“小白”即可查看)基本上把Web编程所依赖的基础技术(HTTP,HTML, WEB服务器,浏览器)的来龙去脉介绍完了, 从这篇开始 ,正式开始进入应用程序的开发领域。
其实Web应用程序开发也有个极为常见的技术: XML . 很多小白在问,为什么有XML, 要XML干嘛?不是有HTML了吗 ? 晕倒
对一项技术我的风格是喜欢刨根问底, 不但要知道how, 还要知道why , 了解了一个技术的成因, 才能真正掌握。
假设你用Java 写了一个很棒的Web应用, 这个程序可以在线购书, 在互联网刚起步的时代这个应用火的一塌糊涂 , 后来有个出版社看到了机遇, 就想和你搞合作: 我这儿也有个Web应用,可以给你提供很多书籍的资源, 你能不能开发个程序把这些书的信息读出来,放到你的网站上?
这没啥难的, 首先得定义一下你的应用和出版社的应用中间怎么进行数据交换, 你要定义一个格式,像这样:
[isbn|书名|作者|简介|价格]
例如: [978-7-229-03093-3|三体|刘慈欣|中国最牛的科幻书|38.00]
数据虽然紧凑, 但是每个字段是什么含义,不好理解, 你想起了HTML的标签好像不错,不如学习HTML改进一下:
<book>
<isbn>978-7-229-03093-3</isbn>
<name>三体</name>
作者
<introduction>中国最牛的科幻书</introduction>
<price>38.00</price>
</book>
由于HTML的标签<head>,<title>,<tr><td>...... 是有限的,而你的标签确实可以随意扩展的,想写什么写什么 所以你就把它称为 Extensible Markup Language, 简称XML
现在每个字段的含义很明确, 人读起来也很爽了, 但是毕竟是程序在处理出版社发过来的数据, 万一他们的数据里少了一些重要字段该怎么办, 能不能自动的检测出来?
所以你需要设计一套校验规则, 能让程序自动校验一段xml 文本是不是你期望的, 这个规则可以像这样:
<!ELEMENT book (isbn, name, author, introduction, price)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT isbn (#PCDATA)>
<!ELEMENT introduction (#PCDATA)>
<!ELEMENT author (#PCDATA)>
其中第一行的意思是 xml 需要有个 book 标签(元素), 它包含了几个子标签 , 并且这几个标签必须都得有,并且按次序出现。
其他行表示每个标签都是文本就可以了。
你把这个东西起名为文档类型定义 Document Type Definition, 简称DTD 。
这样就不怕出版社使坏了, 对他们发过来的数据, 在真正的处理之前, 你写了个程序, 调用用DTD一验证就知道是不是合法的, 少了个字段什么的一下子就能查出来,巨爽。
后来又有人发明了DTD的改进版XML Schema ,那就是后话了。
慢慢的你就发现,XML极为灵活,描述一个东西非常方便, 除了应用之间交互数据之外,用来描述你的系统的配置信息也大有永无之地。
原来你为了让代码有可移植性(说白了就是在别人的机器上安装时不用费那么大劲),把数据库的ip , 用户名, 密码 都写在了一个文本文件中, 这样就可以只改配置而不用改动代码了
ip=192.168.0.1
name=test
user=liuxin
password=liuxin
但是碰到复杂的,尤其是层次化的配置用文本文件就捉襟见肘了,例如:
form1.name=login
form1.class=com.test.login
form1.property1.name=ok
form1.property1.type=java.lang.String
form1.property2.name=failure
form1.property2.type=java.lang.String
form2.name=logout
form2.class=com.test.logout
form2.property1.name=ok
form2.property1.type=java.lang.String
form2.property2.name=failure
form2.property2.type=java.lang.String
是不是看的头大?
改成xml 描述看看, 是不是就容易理解多了:
<form name="login" >
<property name="ok" type="java.lang.String" />
<property name="failure" type="java.lang.String" />
</form>
<form name="logout" >
<property name="ok" type="java.lang.String" />
<property name="failure" type="java.lang.String" />
</form>
其实不光是你, 现在绝大多数Java 应用程序的配置文件都是xml , 已经成为事实的标准了。
总结:XML主要用于程序之间的数据交换, 以及描述程序的配置信息。
历史知识:
早在1969年,IBM公司就开发了一种文档描述语言GML用来解决不同系统中文档格式不同的问题,这个语言在1986年演变成一个国际标准(ISO8879),并被称为SGML,SGML是很多大型组织,比如飞机、汽车公司和军队的文档标准,它是语言无关的、结构化的、可扩展的语言,这些特点使它在很多公司受到欢迎,被用来创建、处理和发布大量的文本信息。
在1989年,在CERN欧洲粒子物理研究中心的研究人员开发了基于SGML的超文本版本,被称为HTML。HTML继承了SGML的许多重要的特点,比如结构化、实现独立和可描述性,但是同时它也存在很多缺陷:比如它只能使用固定的有限的标记,而且它只侧重于对内容的显示。
同时随着Web上数据的增多,这些HTML存在的缺点就变的不可被忽略。W3C提供了HTML的几个扩展用来解决这些问题,最后,它决定开发一个新的SGML的子集,称为XML。
本文是给小白的Java EE生存指南的第4篇, 讲一下几乎100%Java 开发人员都要用的 Tomcat。
为什么有Tomcat ? 其实需要从Servlet 说起。
记得《给小白的Java EE生存指南(2)》 (回复“小白”查看) 提到的动态网页吗? 常见的实现动态网页的技术就是CGI。
但是作为Java 的发明人, Sun肯定要搞一个超越CGI的技术出来, 之前Sun 通过Applet出了一个超级大风头, 让整个世界一下子认识了Java , 不过很快发现悲催的Applet其实用途不大, 眼看着互联网开始起势, 一定要搭上千载难逢的快车啊。
于是Servlet 就应运而生了, Servlet 其实就是Sun为了让Java 能实现动态的可交互的网页, 从而进入Web编程的领域而定义的一套标准。
这套标准说了:
你想用Java 开发动态网页,可以定义一个自己的"Servlet"(名字很怪,不知道怎么翻译) , 但一定要是实现我的HttpServlet接口, 然后重载doGet(), doPost()等方法。
用户从浏览器GET的时候, 调用doGet()方法, 从浏览器向服务器发送表单数据的时候, 调用doPost()方法。
(参见 《给小白的Java EE生存指南(1)》,回复“小白”查看) 。
如果你想访问用户从浏览器传递过来的参数, 没问题, 用HttpServletRequest 对象就好了, 里边有getParameter() ,getQueryString()方法。
如果你处理完了, 想向浏览器返回数据, 用HttpServletResponse 调用getPrintWriter() 就可以输出数据了。
如果你想实现一个购物车, 需要session, 很简单, 从HttpServletRequest 调用getSession() 就好了。
你写了一个"Servlet",接下来要运行, 你就发现没法通过java 直接运行了, 你需要一个能够运行Servlet的容器 , 这个容器Sun 最早实现了一个,叫Java Web Server, 1999年捐给了Apache Software foundation , 就改名叫Tomcat 。
所以Tomcat 就是一个Servlet容器, 能接收用户从浏览器发来的请求, 然后转发给Servlet处理, 把处理完的响应数据发回浏览器。
但是Servlet 输出html ,还是采用了老的CGI 方式,是一句一句输出,所以,编写和修改 HTML 非常不方便。
于是 Java Server Pages(JSP) 就来救急了,JSP 并没有增加任何本质上不能用 Servlet 实现的功能。
实际上JSP在运行之前,需要先编译成servlet , 然后才执行的。
但是,在 JSP 中编写静态HTML 更加方便,不必再用 println语 句来输出每一行 HTML 代码。更重要的是,借助内容和外观的分离,页面制作中不同性质的任务可以方便地分开:比如,由页面设计者进行 HTML设计,同时留出供 Java 程序员插入动态内容的空间。
Tomcat 能运行Servlet, 当然运行JSP肯定也是易如反掌。
既然是Web 服务器, Tomcat除了能运行Servlet和JSP之外, 也能像Apache/nginx 那样,支持静态html, 图片,文档的访问, 只是性能要差一些, 在实际的应用中, 一般是这么使用他们的:

Nginx 作为负载均衡服务器 和静态资源服务器放在最前端, 后面是tomcat组成的集群。
如果用户请求的是静态资源, Nginx直接搞定, 不用麻烦后面的tomcat了。
如果是动态资源(如xxx.jsp) , Nginix 就会按照一定的算法转发到某个Tomcat上, 达到负载均衡的目的。
本文是给小白的Java EE生存指南的第5篇, 讲一下前端工程师必备的AJAX的来龙去脉。
回到2001年, 当时的老刘还是小刘, 在计算所跟着老板和四川的一个公司合作,做一个类似于OA(办公自动化)的项目。
当时小刘刚毕业,写过一些asp的程序,在小刘的意识当中, 还是觉得只要你通过浏览器向服务器发出请求, 服务器处理以后, 需要刷新整个网页才能看到服务器处理的结果。
但是有一天我突然看到项目中大牛写的一个页面,这个页面上面是菜单,中间是一个树形结构,代表了一个公司的各个部门。
点击了菜单以后, 整个页面没有刷新, 神奇的是那个部门的树形机构竟然发生了变化! 也就是说整个页面没有刷新, 只是页面的局部发生了刷新。
太不可思议了 ! 我赶紧打开那个普通的asp程序, 看看到底是什么情况。
原来点了菜单以后, 执行了一段javascript, 其中创建了一个叫XMLHttpRequest的东西;
var xhr;
if (window.XMLHttpRequest){
xhr=new XMLHttpRequest(); //非IE浏览器
}else{
xhr=new ActiveXObject("Microsoft.XMLHTTP"); //IE 浏览器
}
//放置一个回调函数: state_change, 当http的状态发生变化时会调用
xhr.onreadystatechange=state_change
xhr.open("GET","http://xxxxxx.xxx/xxx.asp",true); // true 表示异步调用
xhr.send(); //这是一个耗时的操作
//具体的回调函数定义
function state_change()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200){
//获取到服务器返回的xml
xmlRes = xhr.responseXML;
//对xml进行处理,更新部门的树形结构, 代码略
document.getElementById('deptTree').innerHTML = xxxxxxx
}
}
//其他代码, 略
你可以想象我第一次看到这样的处理时那种震惊的表情。 原来页面可以这么写, javascript 可以这么用!
其实这里体现的思想有两点:
1. 异步调用
异步的意思是说, 调用一个耗时的函数(上例中的xhr.send()) 以后, 不等到它返回,就直接执行后续的代码了。
当然在调用它之前会放置一个回调的函数callback(上例中的state_change),等到这个耗时的函数完成以后,再来调用callback 。
为什么要这么做呢? 主要是网络操作太耗时了, 你在浏览器中的一个点击可能访问是地球那一边的服务器, 如果是同步操作, 即等待网络操作完成以后再进行下一步, 就可能阻塞当前线程, 甚至会导致浏览器卡死的情况。
异步调用在编程中是个非常常用的手段, 后来服务器端的javascript Node.js 几乎全是基于事件的异步调用。
2. 用XML做浏览器端和服务器端的数据交换
这点毋庸解释, 参见《给小白的Java EE指南(3): XML》 ,看看xml 的作用。
3. 局部刷新
Javascript 取到从服务器端返回的XML以后, 解析该XML, 然后通过DOM对象只更新整个页面html的一部分,例如更新一个table, 一个div ....
document.getElementById('deptTree').innerHTML = xxxxxxx
异步的JavaScript和XML(Asynchronous Javascript And XML) 就简称AJAX, 你看这些缩写其实没什么神秘的。
AJAX这个词2005才出现,之前已经出现了大量的“AJAX”Web应用, 我认为其中最著名的就是Google Maps 它使用XMLHttpRequest异步调用服务器端来获取数据,并将数据应用在客户端,实现了无刷新的效果,极好的用户体验让Google Maps获取了巨大的成功。
【XML VS JSON】
但是在javascript中使用XML有两个问题:
1. XML 要求有开始标签和结束标签, 如<name>liuxin</name> ,name出现了两次, 这在网络传输中其实是一种冗余浪费。
2. javascript 需要解析xml , 然后展示到浏览器中。
第二点尤其不爽, 所以就有人发展了一个叫JSON(JavaScript Object Notation) 的一个轻量级的数据格式。 JSON其实就是javascript 语法的子集, 就是javascript中的对象和数组。
对象在js中表示为“{}”括起来的内容,数据结构为 {key:value,key:value,...}的键值对的结构。
数组在js中是中括号“[]”括起来的内容,数据结构为 ["java","javascript","vb",...]。
这两种结构虽然很简单, 但是递归组合起来能表达任意的数据结构, 这就是简单的力量, 下面就是一个例子:
{
"programmers":
[{
"firstName": "Brett",
"lastName": "McLaughlin",
"email": "aaaa"
}, {
"firstName": "Jason",
"lastName": "Hunter",
"email": "bbbb"
}],
"authors":
[{
"firstName": "Isaac",
"lastName": "Asimov",
"genre": "sciencefiction"
}, {
"firstName": "Tad",
"lastName": "Williams",
"genre": "fantasy"
}],
"musicians":
[{
"firstName": "Eric",
"lastName": "Clapton",
"instrument": "guitar"
}, {
"firstName": "Sergei",
"lastName": "Rachmaninoff",
"instrument": "piano"
}]
}
由于JSON本身就是Javascript 语法的一部分, javascipt代码可以直接把他们当成对象来处理, 根本不用解析XML了。
再加上JSON结构很紧凑, 很快就流行开来了, 现在AJAX 基本上都是在用JSON来传递数据了。
题外话:第一次看到AJAX这个词的时候, 作为球迷的我脑海里第一反应是荷兰的阿贾克斯足球俱乐部, 在90年代, 阿贾克斯足球号称青年近卫军, 一帮小孩在欧冠决赛中把如日中天的AC米兰都搞定了, 后来由于《博斯曼法案》的实施,球员可以自由转会, 阿贾克斯就没落了。
本文是给小白的Java EE生存指南的第6篇, 讲点稍微有深度的:反射。
这里不定义什么叫反射,先来看个例子,假设我给你一个Java 类:
package com.example;
public class HelloWorld {
public HelloWorld(){
}
public void sayHello(){
System.out.println("hello world!");
}
}
现在要求:
(1) 你不能使用 HelloWorld hw = new HelloWorld() , 但是要构建一个HelloWorld的实例来.
(2) 调用sayHello() 方法, 但是不能直接用 HelloWorld实例的 hw.sayHello()方法 , 说起来怪拗口的 :-)
用Java的反射功能, 可以很轻松的完成上面的要求:
//第一步, 先把HelloWorld的类装载进来
Class cls = Class.forName("com.example.HelloWorld");
//第二步, 创建一个HelloWorld的实例, 注意, 这里并没有用强制转型把obj转成HelloWorld
Object obj = cls.newInstance();
//第三步, 得到这个类的方法, 注意, 一个类的方法也是对象啊
Method m = cls.getDeclaredMethod("sayHello");
//第四部, 方法调用, 输出"hello world"
m.invoke(obj);
可能有人要问了, 为什么不直接new 出来呢? 通过反射来创建对象,调用方法多费劲啊 ?
这是个好问题,关键点就是: 很多时候我们并不能事先知道要new 什么对象, 相反,我们可能只知道一个类的名称和方法名, 很多时候这些名称都是写在XML配置当中的。
为了更好的说明问题, 来看看几个SSH的例子:
【Struts的例子】
1. 在XML配置文件中定义Action
<result>/hello.jsp</result>
2. 定义Java 类
public class HelloWorld extends ExampleSupport {
public String execute() throws Exception {
......
return SUCCESS;
}
.......
}
Struts 框架的作者事先肯定不知道你会配置一个HelloWorld的Action 。
不过他可以这么做, Struts 在启动以后,解析你配置XML配置文件, 发现名称为HelloWorld的Action, 找到相对于的类名example.HelloWorld, 然后就可以通过反射去实例化这个类。 等到有人调用这个action 的时候, 可以通过反射来调用HelloWorld的execute() 方法。
【Hibernate的例子】
1. 定义Java类和表之间映射, 类名叫Event, 对应的表名是EVENTS 。
<hibernate-mapping package="org.hibernate.tutorial.hbm">
<class name="Event" table="EVENTS">
<id name="id" column="EVENT_ID">
<generator />
</id>
<property name="date" type="timestamp" column="EVENT_DATE"/>
<property name="title"/>
</class>
</hibernate-mapping>
2. 定义Event 类,如下所示:
public class Event {
private Long id;
private String title;
private Date date;
...... 为了节省篇幅, 每个属性的getter /setter 方法略...
}
3. 查询, 你可以用Hibernate 这么查询表中的数据了:
List result = session.createQuery( "from Event" ).list();
for ( Event event : (List<Event>) result ) {
System.out.println( "Event (" + event.getDate() + ") : " + event.getTitle() );
}
Struts 的作者事先也不知道你会配置一个叫Event的类。
不过他会这么处理: 类名(Event)-> 数据库表名(EVENTS) -> 发出SELECT查询表数据 -> 通过反射创建Event的实例 -> 通过反射调用实例的setter方法把数据库的值设置进去
【Spring的例子】
1. 配置一个Bean
<beanid="helloWorld">
<propertyname="message"value="Hello World!"/>
</bean>
2. 写一个Java 文件
public class HelloWorld
{
private String message;
public void setMessage(String message){
this.message = message;
}
public void getMessage(){
System.out.println("My Message : "+ message);
}
}
3. 调用
ApplicationContext context =newClassPathXmlApplicationContext("Beans.xml");
HelloWorld hw=(HelloWorld) context.getBean("helloWorld");
hw.getMessage();
我都懒得解释了, 无非是根据类的名称通过反射创建一个类HelloWorld的实例, 然后再通过反射调用setMessage方法, 这样当你getMessage就有值了。
所以反射是很重要的, 在Java EE世界里, 反射最大的用途就是支持以声明式的方法(在XML中)来描述应用的行为, 是Struts, Hibernate , Spring 的最核心的技术之一。
简单的来讲, 反射能让你在运行时而不是编程时做下面的事情:
(1) 获取一个类的内部结构信息(或者成为元数据), 包括包名,类名, 类所有的方法,
(2) 运行时对一个Java对象进行操作, 包括创建这个类的实例, 设置一个属性的值, 调用这个类的方法等等。
这篇文章只是介绍了反射的一点皮毛和用途, 具体的细节还是等待你自己去发掘吧。
三、J2EE要死了?
最近有人问我说: 欣哥, 我们现在都用Spring, Hibernate, SpringMVC了,这Java EE是不是已经死掉了?
这个问题让我哭笑不得,因为他似乎还没有搞清楚Java EE到底是怎么回事,就给Java EE判了死刑。
Java EE是什么呢?
简单来讲Java EE 就是一个技术规范的集合,一些核心的技术规范包括:JDBC, Servlet, JSP, JNDI, EJB, RMI, XML , JMS , JTA, JPA,JavaMail 等等。 这些规范的目标很美好, 就是帮助程序员开发大规模的、分布式的、高可用的“企业级”应用, 只是实际的效果可能就没那么美好了。
我们先来看一看这些核心的技术规范都是干嘛的,然后再来评判Java EE是不是快要死掉了。
JDBC : Java程序访问数据库的核心技术,不管是使用Hibernate , MyBatis, EJB, 还是自己写类库, 只要你访问数据库, JDBC是绕不过去的, 我还没见过在Java 中用其他技术读取数据库的案例。
(参见文章:《 JDBC的诞生 》)
Servlet : 简单地说,Servlet就是Web应用让外界访问的入口。 当然现在直接写Servlet的越来越少, 因为在框架的包装下,应用程序只需要直接写Action 或者 Controller就可以了, 但这并不能否定Servlet的核心和基石地位。
JSP & JSTL: 由于前后端的分离和其他更优秀的替代技术,现在用JSP当做视图层也是凤毛麟角了, 更多的是在遗留系统中在使用, JSP确实在走向没落。
JSTL 是JSP Standard Tag Library, 一套标准的标签库, JSP不受人待见,JSTL就更不行了。
(扩展阅读: 《 JSP:一个装配工的没落 》)
EJB : 曾经最为热门的技术, 寄托了大家最美好的期望,但事实证明EJB 1.x 2.x 简直就是灾难, EJB3.x 虽然吸收了Hibernate的很多优秀特性,奈何大家使用轻量级类库和框架的习惯已经养成, 无法翻身了。
更要命的是使用EJB需要昂贵、复杂、笨重的应用服务器(如Weblogic, Websphere等), 这也是使用它的巨大障碍,再加上Spring 这个轻量级框架的崛起, EJB被彻底打入冷宫。
a.EJB实现原理: 就是把原来放到客户端实现的代码放到服务器端,并依靠RMI进行通信。
b.RMI实现原理 :就是通过Java对象可序列化机制实现分布计算。
RMI : 远程方法调用, 让Java程序可以像访问本地对象一样来访问远程对象的方法, 早期和EJB搭配用的最多, 因为EJB会被部署在分布式的应用服务器中, 一个机器上的程序需要访问远程的EJB,RMI是个基础的技术。 随着EJB的失宠, RMI似乎也用的很少了。
RMI应该是RPC的一种实现,只能在Java 世界中使用, 相对于被广泛使用的基于Web、 基于HTTP的RPC调用, RMI更不受待见。
(参见文章《 我是一个函数 》)
JNDI: 这是一个基础性的技术, 可以把名称和对象进行绑定,最常见的就是通过一个名称来访问数据源,而不用关心这个数据源到底在什么地方。 依然在广泛使用。
JAXP: XML在Java 中无处不在,Java EE 通过Java API for XML Processing(JAXP)来读取/解析XML文件,只是这个接口实在是不太好用,学院派气息过浓, 所以现在大家都用民间开源的JDOM,DOM4J 了。
等到JSON开始流行, “悲剧”又重演了,大家都在用民间的fastjson, jackson , 似乎选择性的忘记了 官方的 Java API for JSON Processing。
官方的不如民间的,也是Java世界的一大特色。
JMS: Java世界访问消息队列的标准方式, 各大消息队列产品都支持, 没有理由不用它。
(扩展阅读《 Java帝国之JMS的诞生 》)
JavaMail : 在Java中发送邮件,又一个基础性的技术。
JTA: Java Transaction API, 主要是为了在多个数据源之间实现分布式事务, 但是JTA在在高并发和高性能的场景下表现不佳, 很多时候并没有用JTA, 而是用异步的方式来解决问题。
(扩展阅读:《 Java帝国之宫廷内斗(上) 》 《 Java帝国之宫廷内斗(下) 》)
除了上面列举的,Java EE还有很多规范
Java API for WebSocket
Java Persistence
Concurrency Utilities for Java EE
Java EE Connector Architecture
Java API for RESTful Web Services (JAX-RS)
Java API for XML-Based RPC (JAX-RPC)
Java Management Extensions (JMX)
JavaBeans Activation Framework (JAF)
......
这些规范在日常的Web开发中可能用的更少,SSH/SSM 中也可以找到对应物, 给大家的感觉就是这Java EE的规范没用了, 要死掉了。
我倒是觉得应该是Websphere , Weblogic这些应用服务器不行了, 从上面的描述中可以看到,活得最滋润的几个是JDBC, Servlet, JMS, 最不如意的就是EJB了, 而EJB恰恰是昂贵的商业应用服务器Weblogic , Websphere 的一个核心功能。
在云计算的环境下, 在容器技术、微服务当道的情况下, 那种集中式的、繁琐的、笨重的部署注定要走向消失。 现在很多后端开发,用Tomcat这种主要支持Servlet/JSP的Web服务器,再配上轻量级的SSH,或者SSM就足够了。
说了这么多,可能有人想到这个问题: 这些规范是怎么制定的的呢?
答案是JCP(Java Community Process), 在这个组织中,一些特定的成员(Full Memeber)如果想把某个技术如JDBC变成Java 规范,就需要发起一个叫做Java Specification Request (JSR) 东西,公开让大家进行评判, 最后由执行委员会投票,决定是否可以发布成为正式规范。
理论上每个人都能够成为JCP的成员, 但是有发言权的, 能上桌玩牌的还是一些巨头,如Oracle, Google, IBM, SAP等等,所以有很多人认为JCP制定出来的Java EE规范只是考虑大厂商的利益, 不顾普罗大众的死活, 这种脱离人民群众的规范是没人用的, 是要死掉的。
这么说确实有一定的道理, 我个人觉得Java EE规范中有一些精华会保留下来,被一直使用,直到Java退出历史舞台。 至于其他的Java EE规范, 就让他们自生自灭去吧。
(完)
正文到此结束
- 本文标签: PowerBuilder 互联网 免费 map Dreamweaver IDE 高通 Google 文件系统 地球 专注 Android JDBC 消息队列 云 部署 插件 PHP 开发 Hadoop Ajax mail lib ACE 压力 2015 sql JavaScript redis cache API MQ 全栈工程师 谦虚 HTML memecache Docker logo 递归 SpringMVC web 操作系统 classpath 同步 自动化 client 负载均衡 Word 线程 下载 安全 Persistence 数据 自动生成 RESTful FastDFS 时间 一致性 初学者 JVM json mysql freemaker 组织 apache 解决方法 测试 Java类 db build 突破 http 学生 黄金时代 集群 message UI ORM 管理 HTTP协议 需求 Elasticsearch 程序员 索引 实例 tag list ssh 参数 翻译 dubbo node example js W3C 美国 文章 搜索引擎 JMS jquery bean 大数据 AOP 代码 高可用 App session Select 加密 value java mybatis 协议 开源 端口 schema https 马云 数据库 汽车 网站 微信公众号 金融 Service NSA IO 网站开发 高并发 CTO 回答 DOM 并发 key spring 程序猿 编译 百度 windows solr ip Oracle python cat IOS 配置 Action 微软 野心 Node.js 分布式 空间 本质 Document 微服务 XML rmi REST 服务器 总结 IBM ftp tomcat entity Architect 产品 JPA 安装 Property CSS 图片 SDN id Apple 工程师 解析 缓存 分布式事务 目录 软件 Nginx final tab 企业 servlet src tar
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

