JVM面试十问
1. JVM运行时划分哪几个区域?哪些区域是线程共享的?哪些区域是线程独占的?
JVM运行时一共划分:程序计数器、虚拟机栈、堆、本地方法栈、方法区。
线程共享的数据区域:堆、方法区。
线程独享的数据区域区域:程序计数器、虚拟机栈、本地方法栈。
2. 这几个内存区域分别存放什么数据?
程序计数器记录当前线程执行的位置;
虚拟机栈存储基本数据类型以及对象的引用等;
堆存储对象实例;
本地方法栈与虚拟机栈类似,它为Native方法服务;
方法区存储被JVM加载的类信息、常量、静态变量等。
3. GC回收算法
(1)标记-清除算法:首先标记出需要回收的对象,标记完成后统一清除。此算法缺点是标记-清楚效率不高,且容易出现大量不连续的碎片空间。
(2)复制算法:将内存空间划分成两部分,每次只使用一个内存空间部分,当一个内存空间使用完,将会把存活的对象复制到另一空间,然后一次性清理掉该部分空间。此算法缺点是内存利用率较低,只有一半。
(3)标记-整理算法:和标记-清楚算法相同也是先标记出需要回收的对象,但在标记完成后不是直接清除而是将存活的对象像一侧进行移动,再清除边界之外的内存。
4. 这三种GC回收算法在JVM中是如何应用的?
GC主要发生在JVM的堆内存中,堆内存分为"新生代"和"老年代",新生代的GC称为"Minor GC",老年代的GC称为"Major GC"。
新生代中的GC算法使用复制算法:新生代中分为了Eden区和Survivor区(Survivor from和Survivor to),新产生的对象实例先在Eden区,Eden区满了过后再在Survivor from区,如果Survivor from区也满了后,将进行Minor GC(复制算法),将存活的对象复制到Survivor to区,此时清除Eden区和Survivor from区,此时Survivor from成为新的Survivor to。新的对象又将在Eden区域进行分配,周而复始。
老年代中的GC算法使用标记-清除算法/标记-整理算法,视具体的GC回收器而定。
5. 频繁的Full GC会带来什么问题?
CPU占用率过高,系统出现卡顿。
6. 什么是OOM内存溢出,它发生在哪块内存区域
OOM通常发生在堆内存上,指的是内存对象没有及时回收,造成没有多余的内存分配给新的对象,此时应该定位程序中是否在频繁创建对象而没有及时回收,或者设置JVM的参数-Xms、-Xmx。
但OOM还有一种情况发生在虚拟机栈,此时虚拟机栈并不是因为递归太深造成StackOverflow,而是的的确确发生了OOM。首先,虚拟机栈作为线程独享的内存区域,总的虚拟机栈内存大小有限,也就是可分配的线程大小有限,当每个虚拟机栈设置的内存大小过大时,此时可分配的线程大小就变少,继续创建过多的线程可能会导致无法再分配内存空间,造成虚拟机栈的OOM。此时的解决办法时,适当设置虚拟机栈的内存大小-Xss,以便能创建更多的线程。
7.常用的GC回收器有哪些,有什么特点?
CMS:通常对老年代的对象进行GC,基于标记-清除算法,是一个低停顿、并发收集的GC回收器。它的GC过程一共分为4个步骤:
①初始标记,标记GC Roots能关联的对象(即存活的对象),会停止用户线程。
②并发标记,不会停止用户线程,和用户线程一起工作标记可达对象。
③重新标记,标记因为在“并发标记”阶段新产生的对象。
④并发清除,同用户线程一起工作,清理需要清理的对象。
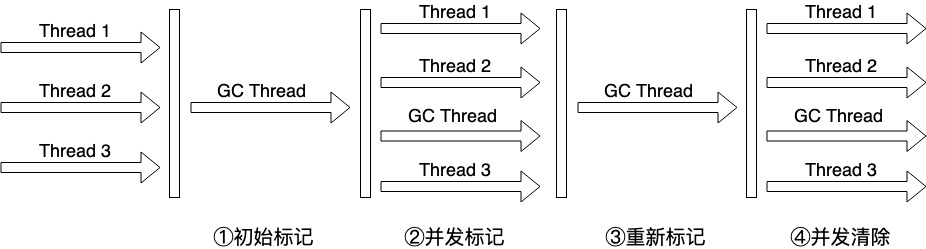
缺点:
①占用CPU资源
②无法处理并发标记期间产生的浮动垃圾
③由于采用标记-清楚算法,会产生大量的内存碎片
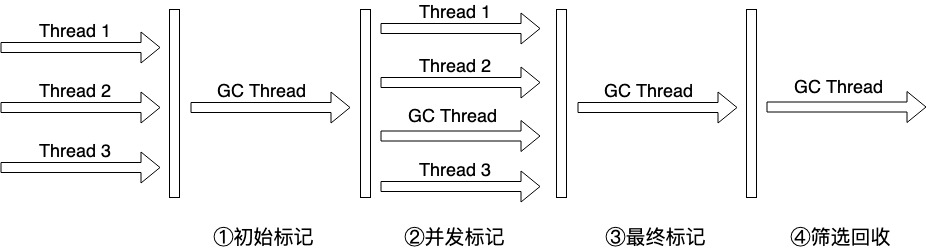
G1:应用于整个堆上的内存,物理上不再划分年轻代与老年代,只做逻辑保留,采用标记-整理算法,是一个可对停顿时间预测的低停顿、并发收集的GC回收器。它的GC过程同CMS类似,一共分为4个步骤:
①初始标记,同CMS回收器一致,标记出存活的对象。
②并发标记,同CMS回收器一致,和用户线程并发标记出存活的对象。
③最终标记,同CMS回收器一致,修正在并发标记将期间用户线程新产生的对象。
④筛选回收,这个阶段可根据用户期望的GC停顿时间制定回收计划。
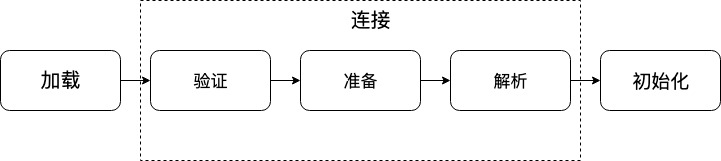
8. 类在JVM中的加载过程
Java文件被编译为Class字节码文件后被加载到JVM中,主要分为三步:加载 -> 连接 -> 初始化。连接过程又分为:验证 -> 准备 -> 解析。
9. 类是如何被加载到JVM中的
Java文件被编译成Class字节码文件后,通过类加载器被加载到JVM中。类加载器从上往下一共有:启动类加载器、扩展类加载器、应用程序类加载器、自定义类加载器。类先从自定义类加载器开始,逐层向上传递到启动类加载器,当启动类加载器不能加载时,再向扩展类加载器加载,这称为双亲委派模型。
10. 类加载器的双亲委派模型有什么好处
假设一个类首先被自定义类加载器加载,我们写Object类时,系统中就会出现不同的Object类。为了保证在系统中始终都只有一个Object类,方法就是它们都通过启动类加载器加载。
这是一个能给程序员加buff的公众号 (CoderBuff)

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

