java算法(4)---静态内部类实现雪花算法
静态内部类单例模式实现雪花算法
在生成表主键ID时,我们可以考虑 主键自增 或者 UUID ,但它们都有很明显的缺点
主键自增
: 1、自增ID容易被爬虫遍历数据。2、分表分库会有ID冲突。
UUID
: 1、太长,并且有索引碎片,索引多占用空间的问题 2、无序。
雪花算法就很适合在分布式场景下生成唯一ID, 它既可以保证唯一又可以排序 。为了提高生产雪花ID的效率,
在这里面数据的运算都采用的是位运算,如果对位运算不了解可以参考博客: 【java提高】(17)---Java 位运算符
一、概念
1、原理
SnowFlake算法生成ID的结果是一个64bit大小的整数,它的结构如下图:
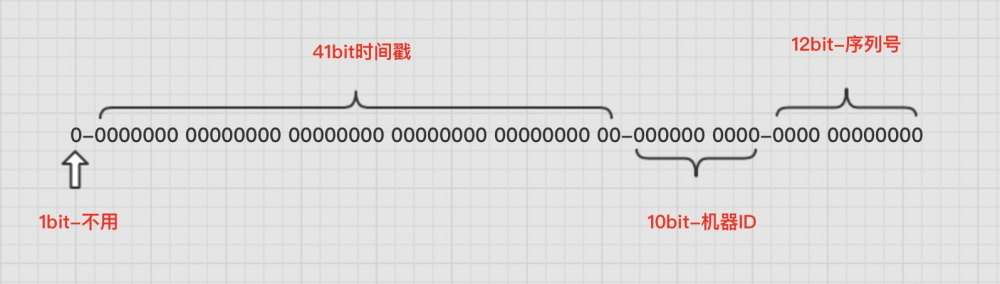
算法描述:
-
1bit因为二进制中最高位是符号位,1表示负数,0表示正数。生成的ID都是正整数,所以最高位固定为0。
-
41bit-时间戳精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
-
10bit-工作机器id10位的机器标识,10位的长度最多支持部署1024个节点。
-
12bit-序列号序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号。
12位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
说明
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
二、静态类部类单例模式生产雪花ID代码
下面生成雪花ID的代码可以用于线上分布式项目中来生成分布式主键ID,因为设计采用的 静态内部类的单例模式
,通过加 synchronized
锁来保证在
同一个服务器线程安全。至于不同服务器其实是不相关的,因为它们的机器码是不一致的,所以就算同一时刻两台服务器都产生了雪花ID,那也不会一样的。
1、代码
/**
* @author xub
* @Description: 雪花算法
* @date 2019/8/14 下午8:22
*/
@Slf4j
public class SnowIdUtils {
/**
* 私有的 静态内部类
*/
private static class SnowFlake {
/**
* 内部类对象(单例模式)
*/
private static final SnowIdUtils.SnowFlake SNOW_FLAKE = new SnowIdUtils.SnowFlake();
/**
* 起始的时间戳
*/
private final long START_TIMESTAMP = 1557489395327L;
/**
* 序列号占用位数
*/
private final long SEQUENCE_BIT = 12;
/**
* 机器标识占用位数
*/
private final long MACHINE_BIT = 10;
/**
* 时间戳位移位数
*/
private final long TIMESTAMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
/**
* 最大序列号 (4095)
*/
private final long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/**
* 最大机器编号 (1023)
*/
private final long MAX_MACHINE_ID = ~(-1L << MACHINE_BIT);
/**
* 生成id机器标识部分
*/
private long machineIdPart;
/**
* 序列号
*/
private long sequence = 0L;
/**
* 上一次时间戳
*/
private long lastStamp = -1L;
/**
* 构造函数初始化机器编码
*/
private SnowFlake() {
//模拟这里获得本机机器编码
long localIp = 4321;
//localIp & MAX_MACHINE_ID最大不会超过1023,在左位移12位
machineIdPart = (localIp & MAX_MACHINE_ID) << SEQUENCE_BIT;
}
/**
* 获取雪花ID
*/
public synchronized long nextId() {
long currentStamp = timeGen();
//避免机器时钟回拨
while (currentStamp < lastStamp) {
// //服务器时钟被调整了,ID生成器停止服务.
throw new RuntimeException(String.format("时钟已经回拨. Refusing to generate id for %d milliseconds", lastStamp - currentStamp));
}
if (currentStamp == lastStamp) {
// 每次+1
sequence = (sequence + 1) & MAX_SEQUENCE;
// 毫秒内序列溢出
if (sequence == 0) {
// 阻塞到下一个毫秒,获得新的时间戳
currentStamp = getNextMill();
}
} else {
//不同毫秒内,序列号置0
sequence = 0L;
}
lastStamp = currentStamp;
//时间戳部分+机器标识部分+序列号部分
return (currentStamp - START_TIMESTAMP) << TIMESTAMP_LEFT | machineIdPart | sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*/
private long getNextMill() {
long mill = timeGen();
//
while (mill <= lastStamp) {
mill = timeGen();
}
return mill;
}
/**
* 返回以毫秒为单位的当前时间
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
/**
* 获取long类型雪花ID
*/
public static long uniqueLong() {
return SnowIdUtils.SnowFlake.SNOW_FLAKE.nextId();
}
/**
* 获取String类型雪花ID
*/
public static String uniqueLongHex() {
return String.format("%016x", uniqueLong());
}
/**
* 测试
*/
public static void main(String[] args) throws InterruptedException {
//计时开始时间
long start = System.currentTimeMillis();
//让100个线程同时进行
final CountDownLatch latch = new CountDownLatch(100);
//判断生成的20万条记录是否有重复记录
final Map<Long, Integer> map = new ConcurrentHashMap();
for (int i = 0; i < 100; i++) {
//创建100个线程
new Thread(() -> {
for (int s = 0; s < 2000; s++) {
long snowID = SnowIdUtils.uniqueLong();
log.info("生成雪花ID={}",snowID);
Integer put = map.put(snowID, 1);
if (put != null) {
throw new RuntimeException("主键重复");
}
}
latch.countDown();
}).start();
}
//让上面100个线程执行结束后,在走下面输出信息
latch.await();
log.info("生成20万条雪花ID总用时={}", System.currentTimeMillis() - start);
}
}
2、测试结果
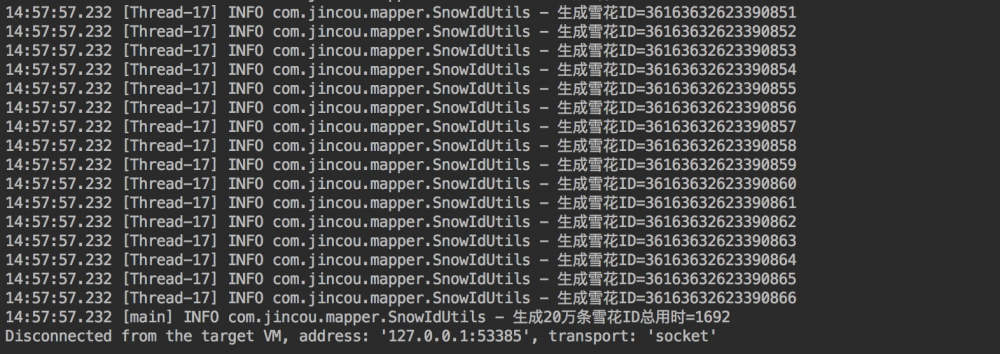
从图中我们可以得出
1、在100个线程并发下,生成20万条雪花ID的时间大概在1.6秒左右,所有所性能还是蛮ok的。 2、生成20万条雪花ID并没有一条相同的ID,因为有一条就会抛出异常了。
3、为什么说41位时间戳最长只能有69年
我们思考41的二进制,最大值也就41位都是1,也就是也就是说41位可以表示
个毫秒的值,转化成单位年则是
年
我们可以通过代码泡一下就知道了。
public static void main(String[] args) {
//41位二进制最小值
String minTimeStampStr = "00000000000000000000000000000000000000000";
//41位二进制最大值
String maxTimeStampStr = "11111111111111111111111111111111111111111";
//转10进制
long minTimeStamp = new BigInteger(minTimeStampStr, 2).longValue();
long maxTimeStamp = new BigInteger(maxTimeStampStr, 2).longValue();
//一年总共多少毫秒
long oneYearMills = 1L * 1000 * 60 * 60 * 24 * 365;
//算出最大可以多少年
System.out.println((maxTimeStamp - minTimeStamp) / oneYearMills);
}
运行结果

所以说雪花算法生成的ID,只能保证69年内不会重复,如果超过69年的话,那就考虑换个服务器部署吧,并且要保证该服务器的ID和之前都没有重复过。
只要自己变优秀了,其他的事情才会跟着好起来(上将15)
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

