Java内存管理-一文掌握虚拟机创建对象的秘密(九)
分享一位老师的人工智能教程。零基础!通俗易懂!风趣幽默!大家可以看看是否对自己有帮助, 点击这里查看【人工智能教程】 。接下来进入正文。
勿在流沙筑高台,出来混迟早要还的。
回顾一下:
本文是接着上一篇内容: Java内存管理-愚人节new一个对象送给你(八) ,继续整理!主要内容讲解HotSpot虚拟机在Java堆中对象是如何创建、内存分配布局和访问方式。
本文地图:
一、给你创建一个对象
如果你是一直从第一季看过来的,那一定知道前面有个地方讲过类的整个生命周期,之前只是讲到了 初始化阶段
,类是如何使用和类是如何被卸载还没有进行讲解!那本文就简单介绍一下类的使用,我们 new
一个 “如花” 似玉的 girl
!
这里再回顾一下,类从被加载到虚拟机内存中开始,到卸载出内存为止,它的生命周期包括了七个阶段:
- 加载(Loading)
- 验证(Verification)
- 准备(Preparation)
- 解析(Resolution)
- 初始化(Initialization)
- 使用(Using)
- 卸载(Unloading)
在Java中我们用使用一个类,很多时候是创建这个类的一个实例,也就是常说的创建一个对象。其实在Java程序运行过程中,无时无刻都有对象被创建出来。创建对象(如克隆、反序列化)通常仅仅是一个 new
关键字而已。但是在Java虚拟机中一个对象(只是普通的java对象,不包括数组和Class对象等)的创建是怎么一个过程呢?
第一:虚拟机遇到一条 new
指令时,首先会去检查这个指令的参数是否能够在 常量池
中定位到一个类的符号引用。然后检查这个符号引用代表的类是否已经被加载、解析和初始化过。如果没有进行类加载则执行相应的类加载的过程。记住:要new对象,要先加载类!
第二:类加载检查通过后,虚拟机将为新生的对象分配内存。对象所需的内存大小在类加载的时候便可以完全确定(如何确定对象的下文说明) 。为对象分配内存的任务等同于把一块确定大小的内存从Java堆中划分出来。分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择那种分配方式由 Java 堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定(对象在堆上的划分,这是个复杂的问题,后文继续探讨,这里只要明白是在对象是在堆上分配内存即可)。记住:要new对象,要有先分配内存空间!
第三:内存分配完成,虚拟机需要将分配的内存空间都初始化为 零值 (零值这个概念之前文章也介绍过,这里就不再说明),这一步的操作保证了对象的实例字段在Java代码中可以不赋初始值就直接使用,因为程序能访问这些字段的数据类型对应的零值。记住:要new对象,虚拟机会帮你为对象的实例字段自动赋予零值!
第四:虚拟机要对对象进行必要的设置,如这个对象是哪个类的实例、如何才能找到类的元数据信息(JDK7是方法区保存)、对象的哈希码、对象的GC分代年龄等信息。这些信息都存放在对象的对象头(Object Header)中。
上面工作都完成之后,在虚拟机看来,一个对象就已经产生了。但是从Java程序的角度看,对象的创建才刚刚开始,因为 new
指令之后会接着执行
记住:对象不是你想new,想new就可以new的!
下面用通过图解的例子简单说明( 版本jdk1.7 ):
第一: 一个PrettyGirl类!
public class PrettyGirl {
/**
* 姑娘姓字名谁
*/
String name;
/**
* 芳龄几何
*/
int age;
/**
* 家住何方
*/
static String address;
/**
* 可曾婚配否
*/
boolean marry;
void sayHello(){
System.out.println("Hello...");
}
@Override
public String toString() {
return "PrettyGirl{" +
"name='" + name + '/'' +
", age=" + age +
", marry=" + marry +
'}';
}
}
复制代码
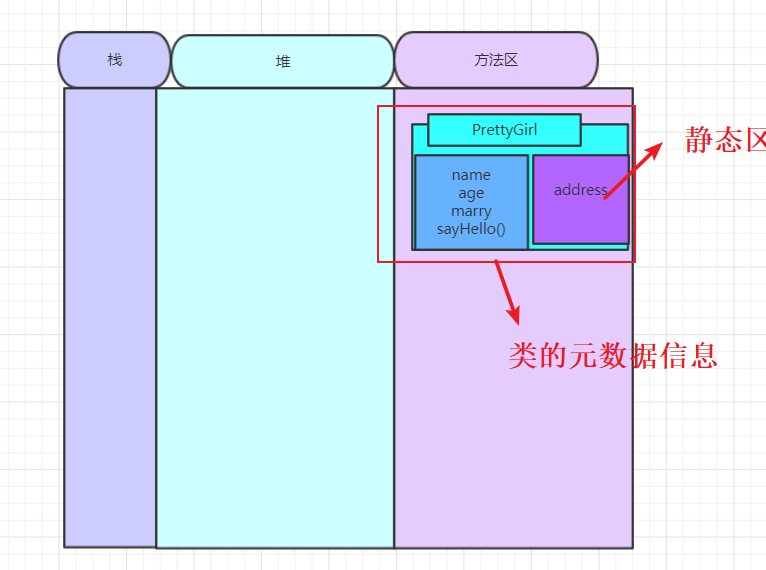
方法区除了保存类的结构,还保存静态属性与静态方法。编写中小型程序时,一般不会造成方法区的内存溢出!在JDK1.8 没有方法区的概念,前面文章中也有提到,这里为了讲解使用图解还是JDK1.7!
第二:实例化new两个漂亮女孩!
public static void main(String[] args) {
PrettyGirl pg1 = new PrettyGirl();
pg1.name = "Alice";
pg1.age = 18;
pg1.address = "changsha";
PrettyGirl pg2 = new PrettyGirl();
pg2.name = "Alexia";
pg2.age = 28;
System.out.println(pg1 + " ---" + pg1.address);
System.out.println(pg2 + "----" + pg2.address);
}
----打印结果:--------
PrettyGirl{name='Alice', age=18, marry=false} ---changsha
PrettyGirl{name='Alexia', age=28, marry=false}----changsha
复制代码

在栈内存为 pg1 变量申请一个空间,在堆内存为PrettyGirl对象申请空间,初始化完毕后将其地址值返回给pg1 ,通过pg1 .name和pg1 .age修改其值,静态的变量address是类公有的!
堆存放对象持有的数据,同时保持对原类的引用。可以简单的理解为对象属性的值保存在堆中,对象调用的方法保存在方法区。
从上图也可以看到有一个区域是栈,在程序运行的时候,每当遇到方法 调用时候,Java虚拟机就会在栈中划分一块内存称为栈帧(线程私有,堆和方法区线程共享的)。就如上面的程序,在调用main方法的时候,会创建一下栈,栈帧中的内存供局部变量(包括基本类型和引用类型)使用,基本类型和引用类型后文会详情介绍。当方法调用结束后,虚拟机会回收次栈帧占用的内存。
tips: 回顾
1、堆内存溢出会发生 OutOfMemoryError 错误,提示信息“Java heap Space”。
2、在栈中会有两个异常:
- 如果线程请求的栈的深度大于虚拟机所允许的最大深度,将抛出StackOverflowError 异常(递归可能会导致此异常)!
- 如果虚拟机在扩展栈时候无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
3、如果有方法区 也会出现OutOfMemoryError 错误,提示信息 “PermGen space”。(JDK8 后无此错误提示)
每个区域都有一些参数可以设置,参数学习续持续更新!
二、对象的内存布局
感慨,创建一个对象还是挺不容易的!
在HotSpot虚拟机中,对象在内存中的布局可以分为3块区域:对象头(Header)、实例数据(Instance data)和对象填充(Padding)。
那下面就对这三块区域进行简单介绍:
1、对象头-还是一个看脸的时代!
对象头包括两部分信息。 第一部分用于存储对象自身的运行时数据 ,如
- 哈希码(HashCode),一个对象的hashcode是唯一的,如判断一个对象是不是单例的!
- GC分代年龄(标明是新生代还是老年代..)
- 锁状态标志、线程持有的锁、偏向线程ID(多线程,同步的时候用到)
- 其他等等....
注: 上面的几个点,要结合和关联其他相关知识,理解会更加深入一点。
如 哈希码hashCode,对下面两个问题如果你又自己的一些思考, 欢迎留言探讨!
1、重写了equals 必须要重写hashcode,思考一下,为什么?如果不重写在使用HashMap的时候会有出现什么问题?
2、HashMap中相同key存入数据不替换,而是进行叠加存储,怎么实现?
问题2提示:只要重写了key的hashCode()和Map的put()方法,其实就可以实现对于相同key下叠加存储不同的value了。
第二部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过指针来确定这个对象是那个类的实例。(就如我们上图的箭头,可以简单理解为指针!)
说明:
(1)、并不是所有的虚拟机实现都是必须在对象数据上保留类型指针,也就是查找对象的元数据并一定经过对象本身!
(2)、如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的的数据,因为虚拟机可以通过普通Java对象的元数据确定Java对象的大小,但是从数组的元数据却无法确定数组的大小。
2、实例数据-了解了外在美,还要注重内在美!
实例数据部分是对象真正存储的有效信息,也就是程序代码中定义的各种类型的字段内容。
不论是从父类继承下来的,还是在子类中定义的,都需要记录起来。记录的存储顺序会受到虚拟机分配策略参数和字段在Java源码中的定义的顺序相关。
3、对齐填充-对齐填充成为标准网红!
对象的填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用!由于HotSpot VM的自动内存管理系统要求兑现的起始地址必须是8字节的整数倍,也就是说对象的大小必须是8字节的整数倍。而对象头部分正好是8字节的整数倍,因此当对象实例数据部分没有对齐时候,就需要填充来补全。
(类比记忆对齐填充,由于审美的标准,有一些人天生就是俊俏的脸蛋和好的身材,不需要进行其他的填充,有一些人可能有好看的脸蛋,但是某些地方和标准还差点意思,就需要填充来达到标准)
tips:字节
字节(byte)计算机里用来存储空间的基本计量单位。8个二进制位(bit)构成了一个字节(byte)即1byte=8bit。
三、如何“约”(定位)一个对象
认识了一个对象后,不能总是聊微信,也要约一下吃个饭啥的! 那在Java中建立了一个对象,那肯定是要使用对象的。 Java程序是如果找到具体的对象的呢?
在Java程序中需要通过栈上的reference数据来操作堆上的具体对象(如开篇的图示,栈上面的引入指向堆中具体对象)。但是由于Reference类型在Java虚拟机规范中只规定了一个指向对象的引用,并没有定义这个引用应该通过何种方式去定位、访问堆中的对象的具体位置,所以对象访问方式也是取决于虚拟机实现而定的。
目前主流的访问方式有使用 句柄 和 直接指针 两种。
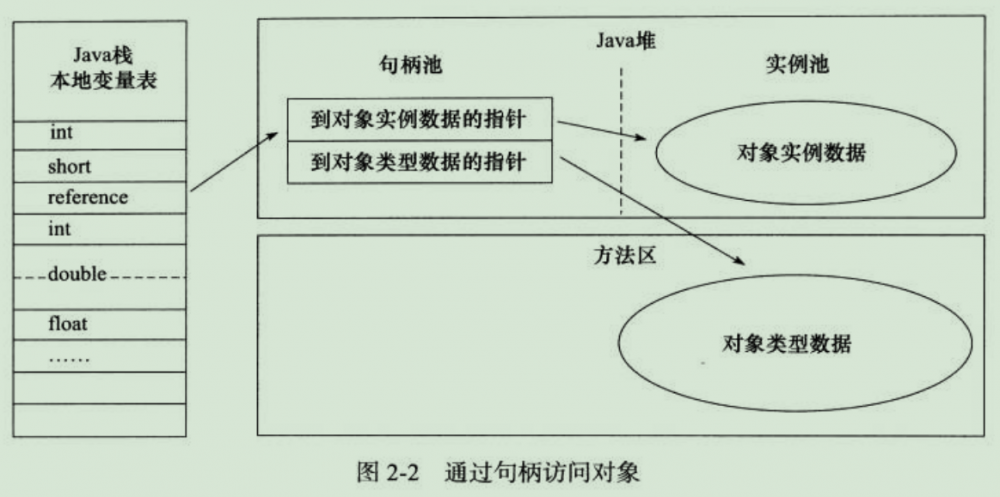
第一:句柄
使用句柄访问,在Java对中将会划分出一块内存来作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象的实例数据与类型数据各自 的具体地址信息,如图,
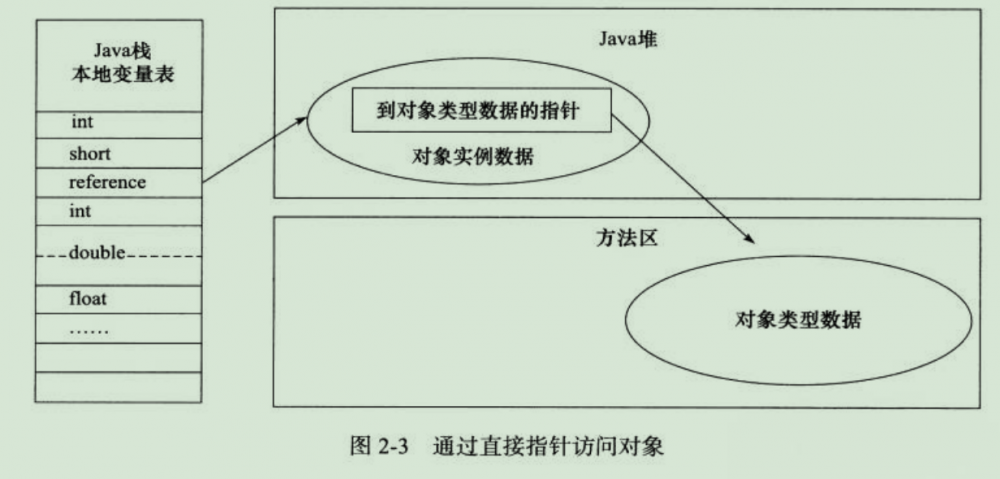
第二:直接指针
使用直接指针,在Java堆对象的布局中就必须考虑如果放置访问类型数组的相关信息,而reference中存储的直接就是对象的地址,如图:
两种方式都各自优势,简单总结:
句柄:最大的好处就是reference中存储的是稳定的句柄地址,在对象被移动(垃圾收集移动对象是非常普通的行为)时只会改变句柄中的实例数据指针,而Reference本身不需要修改。
直接指针:最大的好处就是速度更快,它节省一次指针定位的开销,在Java中对象的访问是非常频繁的,因此能减少这类开销对提高性能还是非常客观的。
虚拟机Hotspot使用的就是直接指针这种方式。但是其他的语言和框架中使用句柄的情况也很常见!
四、本文总结
本文主要整理了Java中一个对象的创建,对象的内存布局以及如何定位一个对象! 也让我们知道对象不是你想new就可以new的,new出的对象想要“约”也是有不同方式的。
因为我也是在整理和学习中,如果文中内容有不对的地方,欢迎留言指出,谢谢!
五、参考资料
《深入理解Java虚拟机》
备注: 由于本人能力有限,文中若有错误之处,欢迎指正。
谢谢你的阅读,如果您觉得这篇博文对你有帮助,请点赞或者喜欢,让更多的人看到!祝你每天开心愉快!

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

