Java 并发——基石篇(中)
完整长文请见: https://createchance.github.io/post/java- 并发之基石篇 /
Synchronized 实现机制
synchronized 是 Java 并发同步开发的基本技术,是 java 语言层面提供的线程间同步手段。我们编写如下一段代码:
复制代码
publicclassSyncTest{
privatestaticfinal Objectlock=newObject();
publicstaticvoidmain(String[] args){
inta =0;
synchronized (lock) {
a++;
}
System.out.println("Result: "+ a);
}
}
针对其中同步的部分我们会看到如下字节码:
复制代码
monitorenter iinc1by1 aload_2 monitorexit
这其实是 javac 和我们玩的一个小把戏,在编译时将 synchronized 同步块的前后插入 montor 进入和退出的字节码指令,相信这一点大多数 java 程序员都了如指掌。
所以我们想要探索 synchronized 的实现机制,就需要探索 monitorenter 和 monitorexit 指令的执行过程了~
我们知道,在 HotSpot JVM 早期的时候,字节码的执行是通过解释性来执行每一条字节码指令的,但是这种方式效率低下。这里插个内容,你知道为啥这种方式效率低下呢?JVM 也是通过 C/C++ 来编写的,为啥效率就那么慢呢?其实所谓效率低下,在 CPU 层面其实就是一个本来很简单的功能却需要大量的 CPU 机器指令来完成,从而导致效率低下。但是,我们还要问,为啥一个简单的功能会产生很多的机器指令呢?原因是这样,Java 程序编译之后,会产生很多字节码指令,每一个字节码指令在 JVM 底层执行的时候又会变成一堆 C 代码,这一堆 C 代码在编译之后又会变成很多的机器指令,这样一来,我们的 java 代码最终到机器指令一层,所产生的机器指令将是指数级的,因此就导致了 Java 执行效率非常低下,话说这个帽子貌似现在还在~
如果我们仔细思考下,怎么优化这个问题呢?字节码是肯定不能动的,因为 JVM 的一处编写,到处运行的梦想就是靠它完成的。其实,我们会发现,问题的根本就在于 Java 和机器指令之间隔了一层 C/C++,而例如 GCC 之类的编译器又不能做到绝对的智能编译,所产生的机器码效率仍然不是非常高。因此,我们会想,能不能跳过 C/C++ 这个层次能,直接将 java 字节码和本地机器码进行一个对应呢?是的!可以的!HotSpot 工程师们早就想到了,因此早期的解释执行器很快就被废弃了,转而采用模版执行器。什么是模版执行器,顾名思义,模版就是将一个 java 字节码通过「人工手动」的方式编写为固定模式的机器指令,这部分不在需要 GCC 的帮助,这样就可以大大减少最终需要执行的机器指令,所以才能提高效率。 所谓模版,就是定义了字节码到机器码转化的统一方式,就像生活中的模板一样,执行字节码的时候套用模版就能得到对应的「人工」调优的机器码~说到这里,真是要感叹,JVM 的字节码执行调优过程真是「人工」智能的结果啊!
上面我们向大家解释了,现代 HotSpot JVM 中采用模版执行器执行字节的原因以及基本的技术方案。现在我们就要从 OpenJDK 中的模版执行器中探索 monitorenter 和 monitorexit 指令执行的细节过程。
在 OpenJDK 11 的源码中,所有 JVM 的解释器(包括最古老的原始解释器)都在:src/hotspot/share/interpreter 目录下,通过这个目录下的代码文件名称我们就很容易地找到模版解释器的代码位置:templateInterpreter.cpp。通过分析这里的实现,我们知道,其实字节码对应到机器码的模版是在 templateTable.cpp 中定义的,这个文件中的代码量不多,全是字节码对应到本地机器码的实现逻辑,这里我们只是放上 monitor 相关的内容:
复制代码
def(Bytecodes::_monitorenter , ____|disp|clvm|____, atos, vtos, monitorenter ,_); def(Bytecodes::_monitorexit , ____|____|clvm|____, atos, vtos, monitorexit ,_);
这里的每一列的含义,在代码中都有说明,这里我们只要知道 monitorenter 函数和 monitorexit 函数就是对应字节码的机器码模版的位置,首先我们看下 monitorenter 的实现:

因为,实际的机器码是和 CPU 相关的,因此 JVM 提供给了几乎所有主流 CPU 的对应版本。这里我们依然看最主流的 x86 的实现(下面要看汇编了,是不是有点激动,但是不要慌,JVM 针对汇编的调用已经做了非常完备的封装,以至于下面的代码看起来和普通的 C 代码没啥区别):
复制代码
voidTemplateTable::monitorenter() {
...
// store object
__ movptr(Address(rmon, BasicObjectLock::obj_offset_in_bytes()), rax);
// 跳转执行 lock_object 函数
__ lock_object(rmon);
...
}
这里我们仍然只给出重点代码部分,代码比较长,前面有很多指令是初始化执行环境的,最后重点会跳转执行 lock_object 函数,同样这个函数也是有不同 CPU 平台实现的,我们还是看 X86 平台的:
复制代码
// Lock object
//
// Args:
// rdx, c_rarg1: BasicObjectLock to be used for locking
//
// Kills:
// rax, rbx
voidInterpreterMacroAssembler::lock_object(Register lock_reg) {
if(UseHeavyMonitors) {
call_VM(noreg,
CAST_FROM_FN_PTR(address,InterpreterRuntime::monitorenter),
lock_reg);
}else{
// 执行锁优化的逻辑部分,例如:锁粗化,锁消除等等
// 如果一切优化措施都执行了,还是需要进入 monitor,就执行如下,其实和上面那个 if 分支是一样的
// Call the runtime routine for slow case
call_VM(noreg,
CAST_FROM_FN_PTR(address,InterpreterRuntime::monitorenter),
lock_reg);
}
}
这里我们无论如何最终都是执行了 InterpreterRuntime::monitorenter 函数,这个函数不仅仅是模版执行器会调用,解释执行器也会执行这个,所以定义在 InterpreterRuntime 类下:
复制代码
// Synchronization
//
// The interpreter's synchronization code is factored out so that it can
// be shared by method invocation and synchronized blocks.
//%note synchronization_3
//%note monitor_1
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread*thread, BasicObjectLock*elem))
Handle h_obj(thread,elem->obj());
if(UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj,elem->lock(),true, CHECK);
}else{
ObjectSynchronizer::slow_enter(h_obj,elem->lock(), CHECK);
}
IRT_END
上面的代码,在原始的代码基础上有删减,保留了核心关键逻辑。其实这里的逻辑很简单,就是根据 UseBiasedLocking 这个变量分别执行 fast_enter 或者 slow_enter 的逻辑。从 UseBiasedLocking 这个变量的名称就能看出来,这是 JVM 1.6 之后默认使能的偏置锁优化,可以通过 JVM 启动参数 -XX:+/-UseBiasedLocking 来控制开关。什么?你问我什么是偏置锁?ok,别慌,下面我们就要开讲了。
同步锁优化处理
因为我们是在 JDK 11 上分析,因此上面的代码,肯定是执行 fast_enter 啦~至于这个函数为啥叫 fast,后面分析完你就知道了~
下面是 fast_enter 函数的定义:
复制代码
// Fast Monitor Enter/Exit
// This the fast monitor enter. The interpreter and compiler use
// some assembly copies of this code. Make sure update those code
// if the following function is changed. The implementation is
// extremely sensitive to race condition. Be careful.
voidObjectSynchronizer::fast_enter(Handleobj, BasicLock* lock,
bool attempt_rebias, TRAPS) {
if(UseBiasedLocking) {
if(!SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::Conditioncond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias,THREAD);
if(cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
}else{
assert(!attempt_rebias,"can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(),"biases should be revoked by now");
}
slow_enter(obj, lock,THREAD);
}
这里开始还是要判断 UseBiasedLocking,如果是 true 的话,就真的开始执行优化逻辑,否则还是会 fall back 到 slow_enter 的。是不是感觉判断 UseBiasedLocking 有点啰嗦?其实不是的,因为这个函数在很多地方都会调用的,因此判断是必要的!为了方便接下来的代码分析,下面我要放出 OpenJDK 官方 wiki 中针对锁优化的原理图:
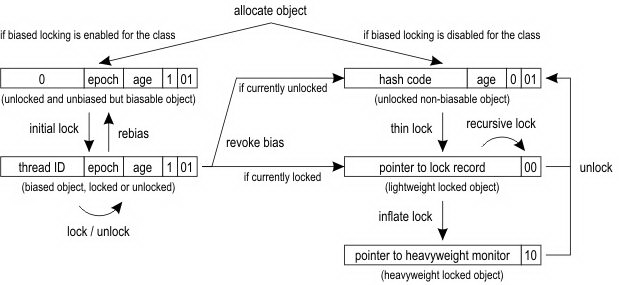
这张图咋一看,很复杂,你可能看不懂。但是,相信我,如果你仔细看完下面的代码分析并且自己结合 JVM 源码尝试理解,你肯定会完全吃透这张图。
预警:接下来的内容会比较烧脑,内容比较复杂,建议你休息一下再来看~
在解释上面那张图之前,需要介绍一下 Java 对象的内存布局,因为上面图中的实现原理就是充分利用 java 对象的头完成的。Java 对象在内存的结构基本上分为:对象头和对象体,其中对象头存储对象特征信息,对象体存放对象数据部分。那么我们除了研究 JVM 源代码获取 java 对象内存布局之外,还有什么办法得知对象的内存布局呢?有的,在 OpenJDK 工程中,有一个子工程叫做: jol ,全名是:java object layout,是的就是 java 对象布局的意思。这是一个工具库,通过这个库可以获取 JVM 中对象布局信息,下面我们展示一个简单的例子(这也是官方给的例子):
复制代码
publicclassJOLTest {
public static void main(String[]args) {
System.out.println(VM.current().details());
System.out.println(ClassLayout.parseClass(A.class).toPrintable());
}
public staticclassA {
boolean f;
}
}
这里通过 JOL 的接口来获取类 A 的对象内存布局,执行之后输出如下内容:
复制代码
# Running64-bit HotSpot VM. # Using compressed oop with3-bit shift. # Using compressed klass with3-bit shift. # WARNING | Compressedreferences base/shifts are guessed by the experiment! # WARNING | Therefore, computed addresses are just guesses,andARE NOT RELIABLE. # WARNING | Make sure to attach Serviceability Agent togetthe reliable addresses. # Objects are8bytes aligned. # Field sizes by type:4,1,1,2,2,4,4,8,8[bytes] # Array element sizes:4,1,1,2,2,4,4,8,8[bytes] JOLTest$A objectinternals: OFFSET SIZE TYPE DESCRIPTION VALUE 012(object header) N/A 121boolean A.f N/A 133(loss due to the next object alignment) Instance size:16bytes Space losses:0bytesinternal +3bytesexternal=3bytes total
这里我们看到输出了很多信息,上面我们类 A 的对象布局如下:12 byte 的对象头 + 1 byte 的对象体 + 3 byte 的填充部分。下面我们分别简要说明下:
对象头:从 JVM 的代码中我们可以看出一个对象的头部定义:
复制代码
volatile markOop _mark;
union_metadata{
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
可以看到分为两部分:第一部分就是 mark 部分,官方称之为 mark word,第二个是 klass 的类型指针,指向这个对象的类对象。这里的 mark word 长度是一个系统字宽,在 64 bit 系统上就是 8 个字节,从上面的日志中我们可以看到虚拟机默认使能了 compressed klass,因此第二部分的 union 其实就是 narrowKlass 类型的,如果我们继续看下 narrowKlass 的定义就知道这是个 32 bit 的 unsigned int 类型,因此将占用 4 个字节,所以对象的头部长度整体为 12 字节。
对象体:因为 A 类只定义了一个字段,是 boolean 类型的,在 JVM 底层占用一个字节的长度
填充部分:上面的对象头和对象体长度的总和为 13 字节,因为 JVM 的内存是以 8 字节长度对齐的,因此这里需要填充 3 个字节的长度是的整体的长度等于 16 字节
上面我们说明了下一个 java 对象的内存布局,上面我们展示的是 JVM 启用了 oop 压缩技术的结果,你可以通过 -XX:-UseCompressedOops 来关闭它,关闭之后的布局如下图(这是标准的内存布局):
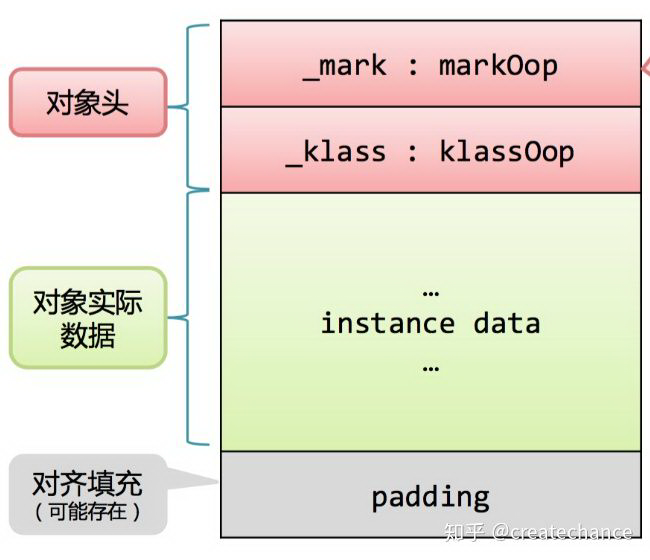
下面回到我们的话题,我们重点需要关注的是对象的头部定义。上面我们看到,对象的头部总共可以分为两个部分:第一个是 mark word ,第二个是这个类的对象指针信息。其中 Mark word 用于存储对象自身运行时的数据,如 hash code、GC 分代年龄等等信息,他是实现偏向锁的关键。
对象头部信息是与对象自身定义的数据无关的额外信息,考虑到虚拟机的空间效率,mark word 被设计成一个非固定数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。在 JVM 中,mark word 内存布局定义在 /src/hotspot/share/oops/markOop.hpp 中,在这个文件的注释中清晰地说明了在 32bit 和 64bit 系统中对象不同状态下的 mark word 布局:
复制代码
//32bits: //-------- //hash:25------------>|age:4biased_lock:1lock:2(normalobject) //JavaThread*:23epoch:2age:4biased_lock:1lock:2(biasedobject) //size:32------------------------------------------>|(CMSfreeblock) //PromotedObject*:29---------->|promo_bits:3----->|(CMSpromotedobject) // //64bits: //-------- //unused:25hash:31-->|unused:1age:4biased_lock:1lock:2(normalobject) //JavaThread*:54epoch:2unused:1age:4biased_lock:1lock:2(biasedobject) //PromotedObject*:61--------------------->|promo_bits:3----->|(CMSpromotedobject) //size:64----------------------------------------------------->|(CMSfreeblock) // //unused:25hash:31-->|cms_free:1age:4biased_lock:1lock:2(COOPs&&normalobject) //JavaThread*:54epoch:2cms_free:1age:4biased_lock:1lock:2(COOPs&&biasedobject) //narrowOop:32unused:24cms_free:1unused:4promo_bits:3----->|(COOPs&&CMSpromotedobject) //unused:21size:35-->|cms_free:1unused:7------------------>|(COOPs&&CMSfreeblock)
在所有状态的前两个状态是我们需要重点关注的:normal object 和 biased object。仔细看这两部分的头定义,最后三个 bit 用来区分偏置锁和普通锁的部分,这里就和前面 OpenJDK wiki 中的图对上了,总结如下:
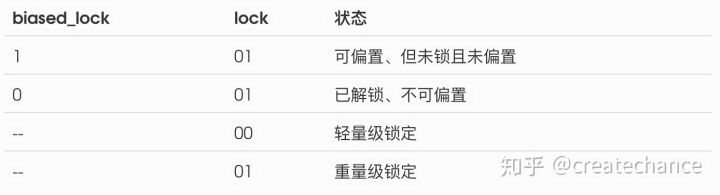
具体的内容参考 OpenJDK wiki 中的图,为了方便描述,这里再贴一次:
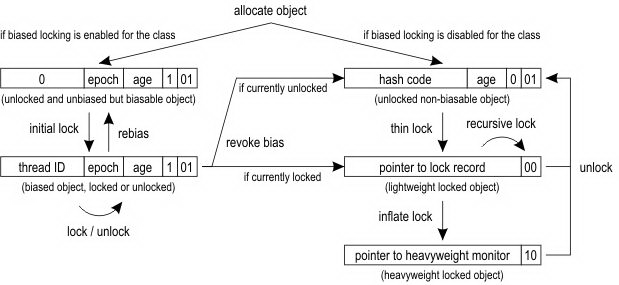
下面我们针对上面的那张图解释一下,首先解释一下什么是偏置锁。所谓偏置,就是偏向某一个线程的意思,也就是说这个锁首先假设自己被偏向的线程持有。在单个线程连续持有锁的时候,偏向锁就起作用了。如果一个线程连续不停滴获取锁,那么获取的过程中如果没有发生竞态,那么可以跳过繁重的同步过程,直接就获得锁执行,这样可以大大提高性能。偏向锁是 JDK 1.6 中引入的一项锁优化手段,它的目的就是消除数据在无争用的情况下的同步操作,进一步提高运行性能。这里还涉及到了轻量级锁,轻量级锁也是 JDK 1.6 引入的一个锁优化机制,所谓轻量级是相对于使用操作系统互斥机制来实现传统锁而言的,在这个角度上,传统的方式就是重量级锁,所谓重量级的原因是同步的方式是一种悲观锁,会导致线程的状态切换,而线程状态的切换是一个相当重量级的操作。在 JVM 6 以上版本中,默认使能偏置优化技术,因此上面的图中,只要分配了新的对象,都会指定左图中的逻辑。首先一个新的对象处于未锁定、未偏置但是可以偏置的状态,也就是上面表格的第一行,这个时候如果有个线程来获取这个对象锁,那么就直接进入已偏置状态,这个状态和未偏置状态的差别就是原来开头的 25 bit 的 hash code 变成了 23 bit 的 thread 指针和 2 bit 的分代信息,那么原始的信息去哪里了呢?其实就存储到获取到锁的线程栈中了,后面我们会在代码中看到这一点。经过这一步的操作,我们就在对象头部存储上了线程指针信息,标记这个对象的锁已经被这个线程持有了,相当于表明:此花已有主。下次当这个线程在此获取这个锁的时候,只要状态没有发生变化,所需要的开销就是一次指针的比较运算,而这个运算是非常轻量的。但是在某个线程持有这个对象锁的时候,如果有另外一个线程来竞争了,锁的偏置状态结束,会触发撤销偏置的逻辑,这个时候可以分为如下两个情况(持有锁的线程成为 线程 A,竞争的成为线程 B):
- 线程 B 到达的时候,线程 A 已经放开对象锁,此时对象锁处于的状态是:偏置对象、未锁定
- 线程 B 到达的时候,线程 A 正持有这个锁,此时对象处于的状态是:偏置对象,已锁定
以上两种情况的操作是不同的,下面分别讲述。
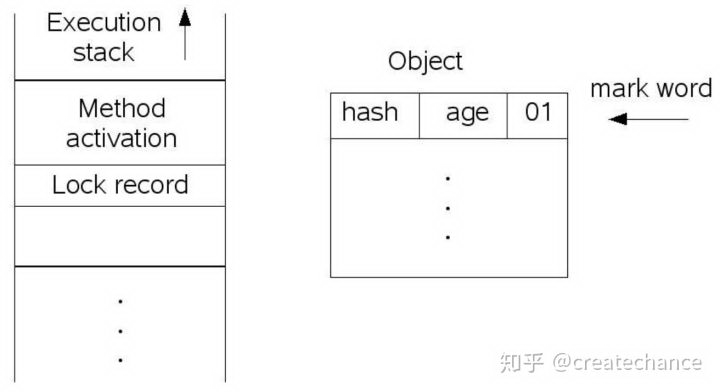
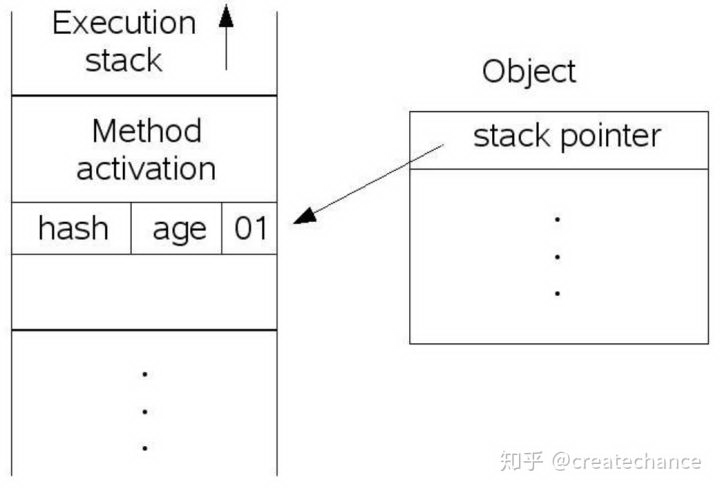
第一种情况,由于对象的状态是偏置对象并且未锁定,因此首先讲对象状态置为不可偏置对象并且未锁定。然后在线程的栈空间新建一个 lock record 的空间,用于存储对象目前的 mark word 的拷贝,然后虚拟机将使用 CAS 操作尝试将对象的 mark word 更新指向 lock record 空间。如果这个更新成功了,那么这个线程就拥有了该对象的锁,并且 mark word 的锁标志位变成 00,表示当前对象锁处于轻量级锁定状态,这个过程如下图所示(上图是锁定前,下图是锁定后):
第二种情况,就是当前对象正在处于锁定状态,这个时候仍然会升级为轻量级锁定对象,但是此时线程 B 获取锁会失败,因此这个对象锁会进行「膨胀」操作,彻底成为一个重量级的锁。
另外,需要说明的是,在一个线程轻量级锁定某个对象的时候,另外一个线程过来竞争也会导致锁的膨胀,进入到重量级的锁。总结起来的话,就是没有竞争就是偏向锁,少量竞争就是轻量级锁,大量竞争就是重量级锁。
需要说明的是,偏置锁和轻量级锁的关系并不是互相取代或者竞争关系,而是属于在不同情况下的不同的锁优化手段。这里就需要提到在概念上的锁分类,通常可以分为:悲观锁和乐观锁。所谓悲观锁,就是认为如果我不做充分的同步的手段(包括执行重量级的操作)就肯定会出现问题;所谓乐观锁,就是会乐观地预估系统当前的状态,认为状态是符合预期的,因此不用重量级的同步也可以完成同步,如果不巧发生了竞态,就退避,然后再按照一定的策略重试。在 java 中,很多传统的同步方式(包括 synchronized,重入锁)都是悲观锁,在 java 9 中在 Thread 类中新加入了一个接口 onSpinWait 就是一种乐观锁,另外在 JUC 中很多的原子工具类都使用到了 CAS(Compare And Swap)操作,这种操作本质上是利用 CPU 提供的特定原子操作指令,基于冲突检测的方式来实现的一种乐观锁定的同步技术。
上面我们详细介绍了 JVM 中的各种锁优化的技术细节,现在我们看下在 JVM 的代码实现上是如何操作的。在看到 fast_enter 函数的时候,看到了代码中有判断 safepoint 的地方,这里大家先不用关心,这个是和 JVM 的 GC 有关的内容,不是我们这里关心的内容。一般而言,都会执行到 revoke_and_rebias 这个函数中,这个函数比较长,主要是在执行 OpenJDK wiki 中图的 revoke 和 rebias 操作,这里就不再深入代码细节分析了。
inflate 成为重锁
从 fas_enter 函数中可以看到,大部分情况下,我们会执行到 slow_enter 函数中:
复制代码
// Interpreter/Compiler Slow Case
// This routine is used to handle interpreter/compiler slow case
// We don't need to use fast path here, because it must have been
// failed in the interpreter/compiler code.
void ObjectSynchronizer::slow_enter(Handleobj, BasicLock*lock, TRAPS){
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(),"should not see bias pattern here");
if(mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
lock->set_displaced_header(mark);
if(mark==obj()->cas_set_mark((markOop)lock, mark)) {
TEVENT(slow_enter:releasestacklock);
return;
}
// Fall through to inflate() ...
}elseif(mark->has_locker()&&
THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(),"must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(),"don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
// The object header will never be displaced to this lock,
// so it does not matter what the value is, except that it
// must be non-zero to avoid looking like a re-entrant lock,
// and must not look locked either.
lock->set_displaced_header(markOopDesc::unused_mark());
ObjectSynchronizer::inflate(THREAD,
obj(),
inflate_cause_monitor_enter)->enter(THREAD);
}
这里的执行逻辑比较简洁,主要执行上面 OpenJDK wiki 中的锁优化逻辑。首先会判断对象锁是否为中立的(neutral):
复制代码
boolis_neutral() const {
// 这里的 biased_lock_mask_in_place 是 7
// unlocked_value 值是 1
return(mask_bits(value(), biased_lock_mask_in_place) == unlocked_value);
}
这里的判断也是比较简单的,就是将 mark word 中的最后 7 个 bit 进行掩码运算,将得到的值和 1 进行比较,如果等于 1 就表示对象是中立的,也就是没有被任何线程锁定,否则就失败。这里需要问一个问题,那就是为什么我们要对 mark word 的最后的 7 个 bit 进行掩码运算?这里我们就需要再次看下在 biase 模式下的对象 mark word 的布局(这里以 32 bit 为例,仍然是上面的 oopDesc 注释描述):
复制代码
hash:25------------>| age:4biased_lock:1lock:2(normal object) JavaThread*:23epoch:2age:4biased_lock:1lock:2(biased object) size:32------------------------------------------>| (CMS free block) PromotedObject*:29---------->| promo_bits:3----->| (CMS promoted object)
可以看到,无论是普通对象或者是可偏置的对象,最后 7 个 bit 的格式是固定的,其他几种模式下,都是不确定的,因此我们需要通过掩码运算将最后 7 个 bit 运算出来。但是为什么要和 1 比较呢?这里我们再次看下上面 OpenJDK wiki 中的锁优化图,会发现在普通对象的时候,也就是 biase revoke 时 unlock 状态下的 header 最后三个 bit 就是 001,也就是十进制的 1!所以这里通过简单高效的二进制运算就获得了对象的锁定状态。
再次回到上面的 slow_enter 函数,如果判断为中立的,也就是没有锁定的话,会执行:
复制代码
if(mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
lock->set_displaced_header(mark);
if(mark==obj()->cas_set_mark((markOop)lock, mark)) {
TEVENT(slow_enter:releasestacklock);
return;
}
// Fall through to inflate() ...
}
首先将当前的 mark word,存储到 lock 指针指向的对象中,这里的 lock 指针指向的就是上面提到的 lock record。然后进行一个非常重要的操作,就是通过原子 cas 操作将这个 lock 指针安装到对象 mark word 中,如果安装成功就表示当前线程获得了这个对象锁,可以直接返回执行同步代码块了,否则就会 fall back 到膨胀锁中,正如注释说的那样。
上面是判断对象是否为中立的逻辑,如果当线程进来的发现当前的对象锁已经被另外一个线程锁定了。这个时候就会执行到 else 逻辑中:
复制代码
if(mark->has_locker() &&
THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(),"must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(),"don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
如果发现当前对象已经锁定,需要判断下是不是当前线程自己锁定了,因为在 synchronized 中可能再一次 synchronized,这种情况下就直接返回即可。
如果上面的两个判断都失败了,也就是对象被锁定,并且锁定线程不是当前线程,这个时候需要执行上面 OpenJDK wiki 中的 inflate 膨胀逻辑。所谓膨胀,就是根据当前锁对象,生成一个 ObjectMonitor 对象,这个对象中保存了 sychronized 阻塞的队列,以及实现了不同的队列调度策略,下面我们重点看下 ObjectMonitor 中的 enter 逻辑(inflate 逻辑不是十分复杂,但是代码量较大,主要是在判断一堆 obj 的状态和检查,这里就不再分析了)。
ObjectMonitor enter
在 enter 函数中,有很多判断和优化执行的逻辑,但是核心和通过 EnterI 函数实际进入队列将当前线程阻塞:
复制代码
void ObjectMonitor::EnterI(TRAPS) {
...
// Try the lock - TATAS
if(TryLock (Self) >0) {
assert(_succ !=Self,"invariant");
assert(_owner ==Self,"invariant");
assert(_Responsible !=Self,"invariant");
return;
}
...
// We try one round of spinning *before* enqueueing Self.
//
// If the _owner is ready but OFFPROC we could use a YieldTo()
// operation to donate the remainder of this thread's quantum
// to the owner. This has subtle but beneficial affinity
// effects.
if(TrySpin (Self) >0) {
assert(_owner ==Self,"invariant");
assert(_succ !=Self,"invariant");
assert(_Responsible !=Self,"invariant");
return;
}
...
ObjectWaiter node(Self);
// Push "Self" onto the front of the _cxq.
// Once on cxq/EntryList, Self stays on-queue until it acquires the lock.
// Note that spinning tends to reduce the rate at which threads
// enqueue and dequeue on EntryList|cxq.
ObjectWaiter * nxt;
for(;;) {
node._next = nxt = _cxq;
if(Atomic::cmpxchg(&node, &_cxq, nxt) == nxt)break;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
if(TryLock (Self) >0) {
assert(_succ !=Self,"invariant");
assert(_owner ==Self,"invariant");
assert(_Responsible !=Self,"invariant");
return;
}
}
...
for(;;) {
if(TryLock(Self) >0)break;
...
if((SyncFlags &2) && _Responsible ==NULL) {
Atomic::replace_if_null(Self, &_Responsible);
}
// park self
if(_Responsible ==Self|| (SyncFlags &1)) {
TEVENT(Inflated enter - park TIMED);
Self->_ParkEvent->park((jlong) recheckInterval);
// Increase the recheckInterval, but clamp the value.
recheckInterval *=8;
if(recheckInterval > MAX_RECHECK_INTERVAL) {
recheckInterval = MAX_RECHECK_INTERVAL;
}
}else{
TEVENT(Inflated enter - park UNTIMED);
Self->_ParkEvent->park();
}
if(TryLock(Self) >0)break;
...
}
...
if(_Responsible ==Self) {
_Responsible =NULL;
}
// 善后处理,比如将当前线程从等待队列 CXQ 中移除
...
}
这个函数比较复杂,代码很长,上面将重点核心逻辑列出来了。上面的逻辑上来先执行了 TryLock:
复制代码
int ObjectMonitor::TryLock(Thread*Self) {
void* own = _owner;
if(own !=NULL)return0;
if(Atomic::replace_if_null(Self, &_owner)) {
// Either guarantee _recursions == 0 or set _recursions = 0.
assert(_recursions ==0,"invariant");
assert(_owner ==Self,"invariant");
return1;
}
// The lock had been free momentarily, but we lost the race to the lock.
// Interference -- the CAS failed.
// We can either return -1 or retry.
// Retry doesn't make as much sense because the lock was just acquired.
return-1;
}
这里的逻辑很简单,主要是尝试通过 cas 操作将 _owner 字段设置为 Self,其中 _owner 表示当前 ObjectMonitor 对象锁持有的线程指针,Self 指向当前执行的线程。如果设置上了,表示当前线程获得了锁,否则没有获得。
再回到上面的 EnterI 函数中,我们看到 TryLock 前后连续执行了两次,而且代码判断逻辑一样,为什么要这样?这其实是为了在入队阻塞线程之前的最后检查,防止线程无谓地进行状态切换。但是为什么执行两次?其实第二次执行的注释已经说明了,这么做有一些微妙的亲和力影响?什么是亲和力?这是很多操作系统中都有的一种 CPU 执行调度逻辑,说的是,如果在过去一段时间内,某个线程尝试获取某种资源一直失败,那么系统在后面会倾向于将该资源分配给这个线程。这里我们前后两次执行,就是告诉系统当前线程「迫切」想要获得这个 cas 资源,如果可以用的话尽量分配给它。当然这种亲和力不是一种得到保证的协议,因此这种操作只能是一种积极的、并且人畜无害的操作。
如果上面进行了两次「微妙」的 try lock 之后仍然失败,那么就只能乖乖入队阻塞了。在入队之前需要创建一个 ObjectWaiter 对象,这个对象将当前线程的对象(注意是 JavaThread 对象)包裹起来,我们看下 ObjectWaiter 的定义:
复制代码
classObjectWaiter:publicStackObj{
public:
enumTStates{TS_UNDEF,TS_READY,TS_RUN,TS_WAIT,TS_ENTER,TS_CXQ};
enumSorted{PREPEND,APPEND,SORTED};
ObjectWaiter * volatile _next;
ObjectWaiter * volatile _prev;
Thread* _thread;
jlong _notifier_tid;
ParkEvent * _event;
volatile int _notified;
volatile TStates TState;
Sorted _Sorted;//List placement disposition
bool _active;//Contention monitoring is enabled
public:
ObjectWaiter(Thread* thread);
void wait_reenter_begin(ObjectMonitor *mon);
void wait_reenter_end(ObjectMonitor *mon);
};
如果你看到 _next 和 _prev 你就会立即明白,这是需要使用双向队列实现等待队列的节奏(但是实际上,下面入队操作并没有形成双向链表,真正形成双向链表时在 exit 的时候,下面分析 exit 的时候会看到这个逻辑)。node 节点创建完毕之后会执行如下入队操作(为了方便大家阅读,我把上面的入队逻辑 copy 过来了):
复制代码
// Push "Self" onto the front of the _cxq.
// Once on cxq/EntryList, Self stays on-queue until it acquires the lock.
// Note that spinning tends to reduce the rate at which threads
// enqueue and dequeue on EntryList|cxq.
ObjectWaiter * nxt;
for(;;) {
node._next= nxt =_cxq;
if(Atomic::cmpxchg(&node, &_cxq, nxt) == nxt) break;
// Interference - the CAS failed because _cxq changed. Just retry.
// As an optional optimization we retry the lock.
if(TryLock (Self) >0) {
assert(_succ!= Self,"invariant");
assert(_owner== Self,"invariant");
assert(_Responsible!= Self,"invariant");
return;
}
}
正如注释中说的那样,我们是要将当前节点放到 CXQ 队列的头部,将节点的 next 指针通过 cas 操作指向 _cxq 指针就完成了入队操作。如果入队成功,则退出当前循环,否则再次尝试 lock,因为可能这个时候会成功。这里使用循环操作 cas 的逻辑,就是处理在高并发的状态下 cas 锁定失败问题,这一点和 JUC 中的 atomic 类的很多 update 操作是一致的。
如果上面的循环退出了,就表示当前线程的 node 节点已经顺利进入 CXQ 队列了,那么接下来需要进入另外一个循环:
复制代码
for(;;) {
if(TryLock(Self) >0)break;
...
if((SyncFlags &2) && _Responsible ==NULL) {
Atomic::replace_if_null(Self, &_Responsible);
}
// park self
if(_Responsible ==Self|| (SyncFlags &1)) {
TEVENT(Inflated enter - park TIMED);
Self->_ParkEvent->park((jlong) recheckInterval);
// Increase the recheckInterval, but clamp the value.
recheckInterval *=8;
if(recheckInterval > MAX_RECHECK_INTERVAL) {
recheckInterval = MAX_RECHECK_INTERVAL;
}
}else{
TEVENT(Inflated enter - park UNTIMED);
Self->_ParkEvent->park();
}
if(TryLock(Self) >0)break;
...
}
这个循环中的逻辑比较简单,一眼就能看明白。主要执行三件事:
- 尝试获取锁
- park 当前线程
- 再次尝试获取锁
重点在于第 2 步,我们知道 synchronzed 如果获取对象锁失败的话,会导致当前线程被阻塞,那么这个阻塞操作就是在这里完成的。这里需要注意的是,这里需要判断一下 _Responsible 指针,如果这个指针为 NULL,表示之前对象锁还没有等待线程,也就是说当前线程是第一个等待线程,这个时候通过 cas 操作将 _Responsible 指向 Self,表示当前线程是这个对象锁的等待线程。接下来,如果发现当前线程就是等待线程或者不是等待线程,那么执行的的逻辑是不一样的。如果是当前线程是等待线程,那么会执行一个简单的「退避算法」,进行一个短时间的阻塞等待。这个算法很简单,第一次等待 1 ms,第二次等待 8 ms,第三次等待 64 ms,以此类推,直到达到等待时长的上线:MAX_RECHECK_INTERVAL,这个 MAX_RECHECK_INTERVAL 的值默认是 1000 ms,也就是说在 synchronize 在一个对象锁上的线程,如果他是第一个等待线程的话,那么他会不停滴休眠、检查锁,休眠的时间由刚才的退避算法指定。如果当前线程不是第一个等待线程,那么只能执行无限期的休眠,一直等待对象锁的 exit 函数执行唤醒才行,这一点在下面分析 exit 函数的时候会说明。
这里有一个问题,就是 park 函数是怎么实现线程的阻塞的?我们看下 park 的实现:

一共有三个实现,从名字可以看出来实现的方式。通常情况下,我们关心在 linux 上的 posix 实现方式:
复制代码
void os::PlatformEvent::park(){
...
intstatus = pthread_mutex_lock(_mutex);
...
status = pthread_cond_wait(_cond,_mutex);
...
status = pthread_mutex_unlock(_mutex);
}
从这里,我们一下子就明白这里的实现方法,其实就是通过 pthread 的 condition wait 函数是下你 pthread 线程的等待。
当线程获得了锁可以进入时,也就是上面的循环退出来的时候,这个时候需要执行一个重要的操作,就是将 _Responsible 置为 NULL:
复制代码
if(_Responsible ==Self) {
_Responsible =NULL;
}
这样以来,当下个线程唤醒的时候,发现 _Responsible 为 NULL 就会尝试上面的 cas 方式将自己标注为第一个等待线程,这样就可以重复上面的操作,完成 monitor 锁的交接。
ObjectMonitor exit
上面我们理清了 ObjectMonitor enter 的逻辑,我们知道了如下几件事情:
- ObjectMonitor 内部通过一个 CXQ 队列保存所有的等待线程
- 在实际进入队列之前,会反复尝试 lock,在某些系统上会存在 CPU 亲和力的优化
- 入队的时候,通过 ObjectWaiter 对象将当前线程包裹起来,并且入到 CXQ 队列的头部
- 入队成功以后,会根据当前线程是否为第一个等待线程做不同的处理
- 如果是第一个等待线程,会根据一个简单的「退避算法」来有条件的 wait
- 如果不是第一个等待线程,那么会执行无限期等待
- 线程的 park 在 posix 系统上是通过 pthread 的 condition wait 实现的
当一个线程获得对象锁成功之后,就可以执行自定义的同步代码块了。执行完成之后会执行到 ObjectMonitor 的 exit 函数中,释放当前对象锁,方便下一个线程来获取这个锁,下面我们逐步分析下 exit 的实现过程。
exit 函数的实现比较长,但是整体上的结构比较清晰:
复制代码
voidObjectMonitor::exit(bool not_suspended, TRAPS) {
for (;;) {
...
ObjectWaiter * w =NULL;
int QMode = Knob_QMode;
if(QMode ==2&& _cxq !=NULL) {
...
}
if(QMode ==3&& _cxq !=NULL) {
...
}
if(QMode ==4&& _cxq !=NULL) {
...
}
...
ExitEpilog(Self, w);
return;
}
}
上面的 exit 函数整体上分为如下几个部分:
- 根据 Knob_QMode 的值和 _cxq 是否为空执行不同策略
- 根据一定策略唤醒等待队列中的下一个线程
下面我们分两部分分析 exit 逻辑。
出队策略 0——默认策略
在 exit 函数中首先是根据 Knob_QMode 值的不同执行不同逻辑,首先我们看下这个值的默认值:
复制代码
// EntryList-cxq policy - queue discipline staticintKnob_QMode =0;
这个值默认是 0,但是这个值本身表示什么含义呢?从这个值的注释中可以看出,这个值是用来指定在退出时的 EntryList 和 CXQ 队列出队策略的,CXQ 我们知道是 enter 的时候因为锁已经被别的线程阻塞而进不来的线程,但是 EntryList 是什么呢?如果你了解 Java Object 的 wait 和 notify,你就会知道这是 notify 唤醒 wait 线程准备执行时,被唤醒线程加入的队列就是 EntryList。不过没关系,下面我们会单独详细分析 Object 的 wait 和 notify 的实现~那么回到我们的问题,Knob_QMode 这个变量主要用来指定在 exit 的时候 EntryList 和 CXQ 队列之间的唤醒关系,也就是说,当 EntryList 和 CXQ 中都有等待的线程时,因为 exit 之后只能有一个线程得到锁,这个时候选择唤醒哪个队列中的线程是一个值得考虑的事情。因此这里就有很多中策略可以执行,这里的默认策略就是 0。下面我们分别分析一下不同策略下的不同行为。
首先我们看下 JVM 默认的策略,也就是策略 0,这也是大家手上 JVM 的行为表现。在实际分析 JVM 的实现之前,我们先看下一段 java 代码:
复制代码
Thread t3 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 3 start!!!!!!");
synchronized (lock) {
try {
System.in.read();
} catch (Exceptione) {
}
System.out.println("Thread 3 end!!!!!!");
}
}
});
Thread t4 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 4 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 4 end!!!!!!");
}
}
});
Thread t5 =newThread(newRunnable() {
@Override
publicvoidrun() {
inta =0;
System.out.println("Thread 5 start!!!!!!");
synchronized (lock) {
a++;
System.out.println("Thread 5 end!!!!!!");
}
}
});
Thread t6 =newThread(newRunnable() {
@Override
publicvoidrun() {
inta =0;
System.out.println("Thread 6 start!!!!!!");
synchronized (lock) {
a++;
System.out.println("Thread 6 end!!!!!!");
}
}
});
t3.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t4.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t5.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t6.start();
上面的代码很简单,t3 线程首先启动,首先抢占 lock 锁,然后在同步块中调用 http://system.in 的 read 方法,这个方法从键盘获取一个输入,在没有得到输入之前会一直等待,注意此时没有放弃 monitor 锁,这一点和 wait 不同,当我按下键盘回车的时候,会唤醒 t3 线程并结束执行释放 lock 锁。t3 启动之后,t4、t5、t6 相继启动。那么当我按下键盘会输出如下内容:
复制代码
Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!!
这个结果详细如果你了解 synchronized 的机制都不会陌生,看起来后来启动的线程优先获得 lock,产生了一种「后来者居上」的效果。但事实上为什么会这样呢?下面我们从 JVM 底层代码中寻找答案。我们前面在分析 enter 函数的时候,说到了,如果当前对象锁被另外一个线程锁锁定了,那么就需要将当前线程包装进 ObjectWaiter 对象中,然后插入到 CXQ 队列的头部(希望你没有晕掉,还记得这些内容~)。上面的代码中,在我按下回车键之前的 CXQ 队列如下:
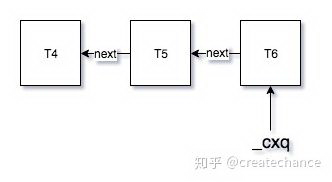
当 t6 线程启动之后,会进入 cxq 队列,此时 cxq 队列会指向 t6 的 wait 节点,现在大家记住这张图,下面我们开始看下 exit 中针对默认状态下,也就是 mode 等于 0 的时候的逻辑:
复制代码
void ObjectMonitor::exit(boolnot_suspended, TRAPS) {
for(;;) {
...
ObjectWaiter * w =NULL;
intQMode = Knob_QMode;
...
w = _cxq;
...
_EntryList = w;
ObjectWaiter * q =NULL;
ObjectWaiter * p;
for(p = w; p !=NULL; p = p->_next) {
guarantee(p->TState == ObjectWaiter::TS_CXQ,"Invariant");
p->TState = ObjectWaiter::TS_ENTER;
p->_prev = q;
q = p;
}
...
w = _EntryList;
if(w !=NULL) {
guarantee(w->TState == ObjectWaiter::TS_ENTER,"invariant");
ExitEpilog(Self, w);
return;
}
}
}
因为我们只关注 mode == 0 的情况,因此 exit 函数的行为就变得非常简单。首先将 cxq 指针赋值给 _EntryList,然后通过一个循环将原本单向链表的 cxq 链表变成双向链表,这么做的目的就是为了方便后面针对 cxq 链表进行查询。还记得前面我们分析 enter 的时候,说到了虽然 ObjectWaiter 时一个双向链表的节点,但是我们在 enter 的时候并没有形成双向链表,当时我们提到了说双向链表的形成会在 exit 时形成,其实说的就是这里。
在上面的链表操作完毕之后,会将 _EntryList 中(注意 _EntryList 其实就是 cxq,因为前面赋值了)队头的节点传递给 ExitEpilog 函数:
复制代码
void ObjectMonitor::ExitEpilog(Thread *Self, ObjectWaiter * Wakee) {
assert(_owner ==Self,"invariant");
// Exit protocol:
// 1. ST _succ = wakee
// 2. membar #loadstore|#storestore;
// 2. ST _owner = NULL
// 3. unpark(wakee)
_succ = Knob_SuccEnabled ? Wakee->_thread :NULL;
ParkEvent * Trigger = Wakee->_event;
// Hygiene -- once we've set _owner = NULL we can't safely dereference Wakee again.
// The thread associated with Wakee may have grabbed the lock and "Wakee" may be
// out-of-scope (non-extant).
Wakee =NULL;
// Drop the lock
OrderAccess::release_store(&_owner, (void*)NULL);
OrderAccess::fence();// ST _owner vs LD in unpark()
if(SafepointMechanism::poll(Self)) {
TEVENT(unpark before SAFEPOINT);
}
DTRACE_MONITOR_PROBE(contended__exit, this, object(),Self);
Trigger->unpark();
// Maintain stats and report events to JVMTI
OM_PERFDATA_OP(Parks, inc());
}
这里的实现非常简单,其实就是通过 park event 将等待的那个线程唤醒,通过执行 unpark 函数(前面入队之后的休眠操作是 park),同样这个方法有很多平台的实现:

我们依然是关心 posix 平台上的实现:
复制代码
void os::PlatformEvent::unpark(){
if(Atomic::xchg(1, &_event) >=0) return;
intstatus = pthread_mutex_lock(_mutex);
intanyWaiters = _nParked;
status = pthread_mutex_unlock(_mutex);
if(anyWaiters !=0) {
status = pthread_cond_signal(_cond);
assert_status(status==0,status,"cond_signal");
}
}
这是依然是通过 pthread 的 condition signal 唤醒线程,前面线程休眠是通过 condition wait 实现的。
我们继续回到 exit 函数,我们现在可以解释上面 JVM 平台默认执行「后来者居上」的逻辑了:根本原因就是在 enter 的时候插入 cxq 队列是将线程节点插入到队头,这样我们后面又从队头获取节点唤醒,因此总是唤醒后面加进来的节点线程。
出队策略 1
现在我们看下,如果我们将 Knob_QMode 的默认值修改为 1,然后重新编译 JVM,再次运行会出现如下结果:
复制代码
Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread4end!!!!!! Thread5end!!!!!! Thread6end!!!!!!
Wow,终于结束了「后来者居上」的模式了!这种模式下看起来先入队先执行,这种行为才是 FIFO 队列嘛~上面默认的形式其实是 LIFO 栈实现~
那么 mode == 1 和 mode == 0 的差别在哪里,差别很小,就在于如下:
复制代码
if(QMode ==1) {
// QMode == 1 : drain cxq to EntryList, reversing order
// We also reverse the order of the list.
ObjectWaiter * s =NULL;
ObjectWaiter * t = w;
ObjectWaiter * u =NULL;
while(t !=NULL) {
guarantee(t->TState == ObjectWaiter::TS_CXQ,"invariant");
t->TState = ObjectWaiter::TS_ENTER;
u = t->_next;
t->_prev = u;
t->_next = s;
s = t;
t = u;
}
_EntryList = s;
assert(s !=NULL,"invariant");
}else{
// QMode == 0 or QMode == 2
_EntryList = w;
ObjectWaiter * q =NULL;
ObjectWaiter * p;
for(p = w; p !=NULL; p = p->_next) {
guarantee(p->TState == ObjectWaiter::TS_CXQ,"Invariant");
p->TState = ObjectWaiter::TS_ENTER;
p->_prev = q;
q = p;
}
}
可以看到上面我们分析默认行为是 else 分支中的,如果 mode == 1 的话,会走上面的分支。正如注释中说的,下面会通过一个循环将 cxq 队列 reverse 一下,然后将新的队头也就是原来的队尾赋值给 _EntryList,接下来的唤醒还是通过 ExitEpilog 函数实现。
出队策略 2
上面我们分析了默认下的 mode == 0 和 mode ==1 的行为,在 JVM 中还支持 2、3、4 另外三种模式,下面我们分别看下。mode == 2 并且 cxq 队列不等于 NULL 的话会进行如下逻辑:
复制代码
if(QMode ==2&& _cxq !=NULL) {
// QMode == 2 : cxq has precedence over EntryList.
// Try to directly wake a successor from the cxq.
// If successful, the successor will need to unlink itself from cxq.
w = _cxq;
assert(w !=NULL,"invariant");
assert(w->TState == ObjectWaiter::TS_CXQ,"Invariant");
ExitEpilog(Self, w);
return;
}
这里将 w 指针指向了 cxq 队头,然后直接执行将队头唤醒的逻辑。这也就是说,如果 mode == 2 的话,cxq 的优先级是比 EntryList 高的。如果 cxq == NULL,那么会执行后面的逻辑,也就是先看 EntryList 中是否为空,如果 EntryList 不为空,就唤醒 EntryList 中的线程,否则将会继续 exit 中的那个大循环,在每一次循环的开头会判断一下 EntryList 和 cxq 队列是否同时为空,如果是的话,就以为这此时没有线程同步在这个锁上,并且也没有 notify 待唤醒的线程,因此就直接退出了 exit 函数。关于 wait 和 notify 的逻辑下面我们会分析,这里大家只要知道,notify 的时候会将 wait 的线程放到 EntryList 队列中。
这里我们可以看到,如果 mode == 2,并且 cxq 不为空的话,那么对于 cxq 队列执行的逻辑其实和 mode == 2 是一样的。唯一区别就是,当 EntryList 中有被 notify 唤醒的线程时,mode == 0 会优先执行 EntryList 中的线程唤醒,而 mode == 2 会优先执行 cxq 中,等到 cxq 中的线程全部唤醒的之后才会唤醒 EntryList 中的线程,只是一个次序的差别。下面我们通过如下代码验证我们的结论:
复制代码
Thread t0 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 0 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 0 end!!!!!!");
}
}
});
Thread t3 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 3 start!!!!!!");
synchronized (lock) {
try {
System.in.read();
} catch (Exceptione) {
}
lock.notify();
System.out.println("Thread 3 end!!!!!!");
}
}
});
Thread t4 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 4 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 4 end!!!!!!");
}
}
});
Thread t5 =newThread(newRunnable() {
@Override
publicvoidrun() {
inta =0;
System.out.println("Thread 5 start!!!!!!");
synchronized (lock) {
a++;
System.out.println("Thread 5 end!!!!!!");
}
}
});
Thread t6 =newThread(newRunnable() {
@Override
publicvoidrun() {
inta =0;
System.out.println("Thread 6 start!!!!!!");
synchronized (lock) {
a++;
System.out.println("Thread 6 end!!!!!!");
}
}
});
t0.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t3.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t4.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t5.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t6.start();
这段代码执行之后,在我按下回车之后并且没有 exit 出 monitor 时的 EntryList 队列和 cxq 队列状态如下:

在 mode == 0 也就是默认状态下,执行结果如下:
复制代码
Thread0start!!!!!! Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread0end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!!
在 mode == 2 的时候,执行结果如下:
复制代码
Thread0start!!!!!! Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!! Thread0end!!!!!!
我们从 t0 的唤醒时机执行完毕的时机就可以验证我们上面的结论了。
出队策略 3 和出队策略 4
策略 3 和策略 4 的逻辑比较相似:
复制代码
if(QMode ==3&& _cxq !=NULL) {
// Aggressively drain cxq into EntryList at the first opportunity.
// This policy ensure that recently-run threads live at the head of EntryList.
// Drain _cxq into EntryList - bulk transfer.
// First, detach _cxq.
// The following loop is tantamount to: w = swap(&cxq, NULL)
w = _cxq;
for(;;) {
assert(w !=NULL,"Invariant");
ObjectWaiter * u = Atomic::cmpxchg((ObjectWaiter*)NULL, &_cxq, w);
if(u == w)break;
w = u;
}
assert(w !=NULL,"invariant");
ObjectWaiter * q =NULL;
ObjectWaiter * p;
for(p = w; p !=NULL; p = p->_next) {
guarantee(p->TState == ObjectWaiter::TS_CXQ,"Invariant");
p->TState = ObjectWaiter::TS_ENTER;
p->_prev = q;
q = p;
}
// Append the RATs to the EntryList
//TODO:organize EntryList as a CDLL so we can locate the tail in constant-time.
ObjectWaiter * Tail;
for(Tail = _EntryList; Tail !=NULL&& Tail->_next !=NULL;
Tail = Tail->_next)
/* empty */;
if(Tail ==NULL) {
_EntryList = w;
}else{
Tail->_next = w;
w->_prev = Tail;
}
// Fall thru into code that tries to wake a successor from EntryList
}
if(QMode ==4&& _cxq !=NULL) {
// Aggressively drain cxq into EntryList at the first opportunity.
// This policy ensure that recently-run threads live at the head of EntryList.
// Drain _cxq into EntryList - bulk transfer.
// First, detach _cxq.
// The following loop is tantamount to: w = swap(&cxq, NULL)
w = _cxq;
for(;;) {
assert(w !=NULL,"Invariant");
ObjectWaiter * u = Atomic::cmpxchg((ObjectWaiter*)NULL, &_cxq, w);
if(u == w)break;
w = u;
}
assert(w !=NULL,"invariant");
ObjectWaiter * q =NULL;
ObjectWaiter * p;
for(p = w; p !=NULL; p = p->_next) {
guarantee(p->TState == ObjectWaiter::TS_CXQ,"Invariant");
p->TState = ObjectWaiter::TS_ENTER;
p->_prev = q;
q = p;
}
// Prepend the RATs to the EntryList
if(_EntryList !=NULL) {
q->_next = _EntryList;
_EntryList->_prev = q;
}
_EntryList = w;
// Fall thru into code that tries to wake a successor from EntryList
}
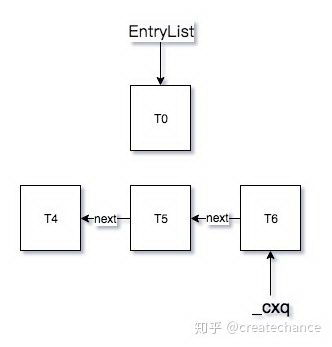
从上面两个策略的注释中可以看出,这两个策略的主要目的是将 EntryList 和 cxq 队列进行一个链接操作。既然是两个队列的链接,就会涉及到谁链接到谁前面的问题。还是拿上面策略 2 的例子来说,如果我的当前 EntryList 和 cxq 队列状态如下:
那么策略 3 的链接之后会成下面这样:

经过策略 4 的链接之后会变成下面这样:

很明显,策略 3 是将 cxq 放在 EntryList 之后,而策略 3 是放在 EntryList 之前。
下面我们还是以策略 2 中代码分别测试,验证我们的结论。
在策略 3 下的运行结果:
复制代码
Thread0start!!!!!! Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread0end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!!
在策略 4 下的运行结果:
复制代码
Thread0start!!!!!! Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!! Thread0end!!!!!!
这个运行结果直接就是印证了上面的分析,线程结束运行的时机就是上面图中的合并之后的链表的顺序。
到这里,我们全部分析完了 exit 的执行逻辑,exit 中的重点就是 EntryList 和 cxq 队列的出队策略。下面我们总结下,出队策略总体上可以分为两组:
- EntryList 优先于 cxq
这种模式对应模式 0 、模式 1 和模式 3,其中模式 0,这两种模式区别就是模式 0 对 cxq 队列会保持「后来者居上」的队列顺序,而模式 1 会 reverse 这个顺序,模式 3 不会变更任何顺序,只是简单地将 cxq 链表放在 EntryList 的后面
- cxq 优先于 EntryList
这种模式对应模式 4,这种模式只是将 EntryList 放在 cxq 的后面,然后按照新的 EntryList 队列开始唤醒线程
本文转载自知乎。
原文链接:
https://zhuanlan.zhihu.com/p/75533444
正文到此结束
- 本文标签: node description 代码 Java 9 volatile http ORM 线程同步 tk java tab swap GitHub 程序员 开发 ask constant 本质 CST 目录 源码 tar IDE App 操作系统 src Service 工程师 并发 linux 测试 数据 智能 参数 详细分析 Atom 高并发 retry 协议 https UI CTO REST 同步 queue id Agent 编译 git 安装 空间 list 总结 trigger 希望 synchronized ssl ip cat 注释 value final ACE IO 字节码 update db 线程 时间 parse 锁 Word NIO JVM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

