超干货!Cassandra Java堆外内存排查经历全记录
背景
最近准备上线cassandra这个产品,同事在做一些小规格ECS(8G)的压测。压测时候比较容易触发OOM Killer,把cassandra进程干掉。问题是8G这个规格我配置的heap(Xmx)并不高(约6.5g)已经留出了足够的空间给系统。只有可能是Java堆外内存使用超出预期,导致RES增加,才可能触发OOM。
调查过程
0.初步怀疑是哪里有DirectBuffer泄漏,或者JNI库的问题。
1.按惯例通过google perftools追踪堆外内存开销,但是并未发现明显的异常。
2.然后用Java NMT 看了一下,也没有发现什么异常。
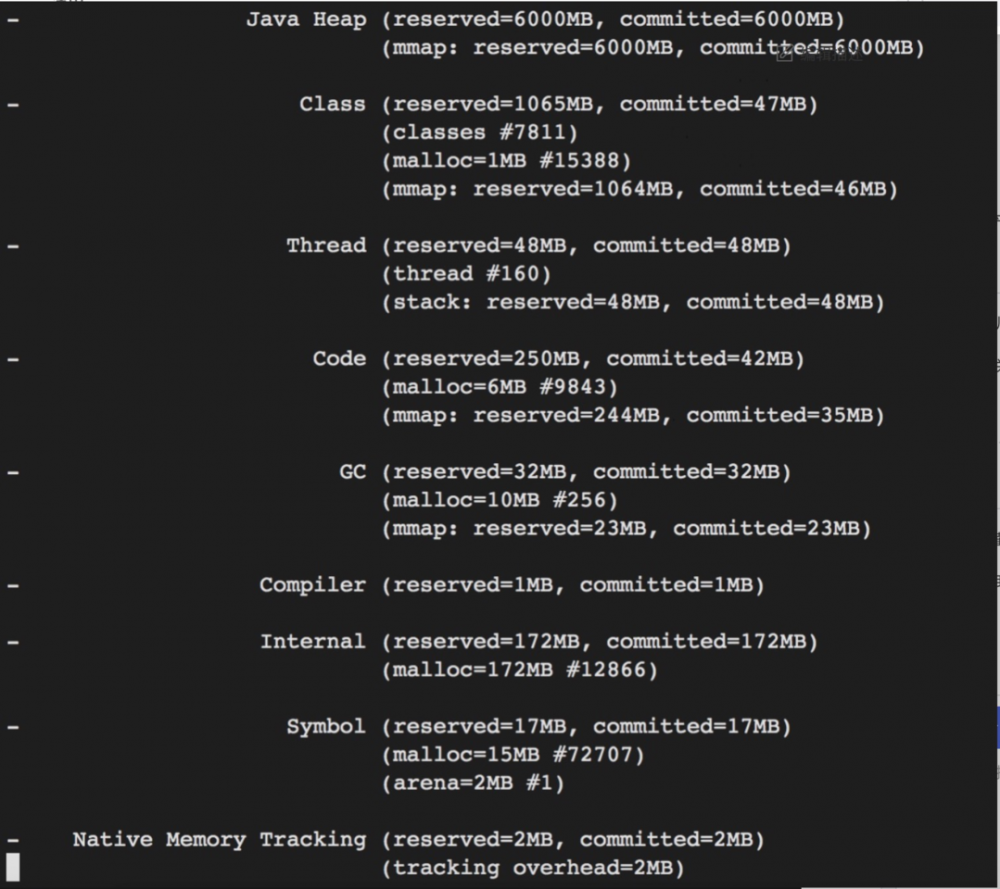
3.查到这里思路似乎断了,因为跟DirectBuffer似乎没啥关系。这时候我注意到进程虚拟内存非常高,已经超过ECS内存了。怀疑这里有些问题。

4.进一步通过/proc/pid/smaps 查看进程内存地址空间分布,发现有大量mmap的文件。这些文件是cassandra的数据文件。
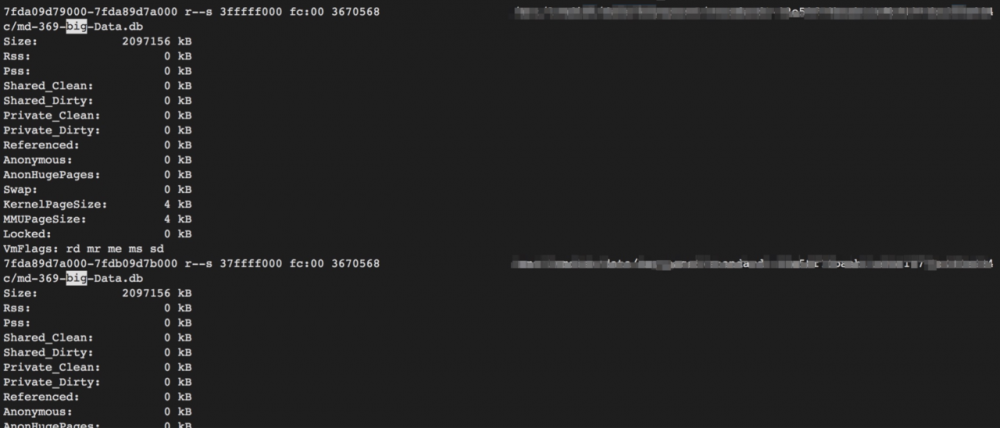
此时这些mmap file 虚拟内存是2G,但是物理内存是0(因为我之前重启过,调低过内存防止进程挂掉影响问题排查)。
显然mmap的内存开销是不受JVM heap控制的,也就是堆外内存。如果mmap的文件数据被从磁盘load进物理内存(RES增加),Java NMT和google perftool是无法感知的,这是kernel的调度过程。
5.考虑到是在压测时候出现问题的,所以我只要读一下这些文件,观察下RES是否会增加,增加多少,为啥增加,就能推断问题是不是在这里。通过下面的命令简单读一下之前导入的数据。
cassandra-stress read duration=10m cl=ONE -rate threads=20 -mode native cql3 user=cassandra password=123 -schema keysp ace=keyspace5 -node core-3复制代码
6.可以观察到压测期间( sar -B ),major page fault是明显上升的,因为数据被实际从磁盘被load进内存。

同时观察到mmap file物理内存增加到20MB:
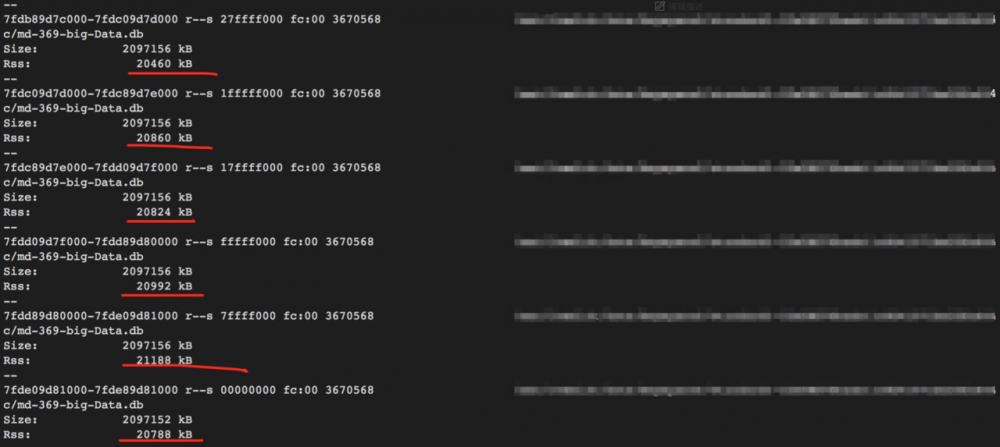
最终进程RES涨到7.1g左右,增加了大约600M:

如果加大压力(50线程),还会涨,每个mmap file物理内存会从20MB,涨到40MB
7. Root cause 是cassandra识别系统是64还是32来确定要不要用mmap,ECS都是64,但是实际上小规格ECS内存并不多。

结论
1.问题诱因是mmap到内存开销没有考虑进去,具体调整方法有很多。可以针对小规格ECS降低heap配置或者关闭mmap特性( disk_access_mode=standard )
2.排查Java堆外内存还是比较麻烦的,推荐先用NMT查查,用起来比较简单,配置JVM参数即可,可以看到内存申请情况。
本文作者:郭泽晖
原文链接
本文为云栖社区原创内容,未经允许不得转载。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

