zookeeper和dubbo安装与搭建
Zookeeper+Dubbo 安装与搭建
(原创:黑小子 - 余)

本文有借鉴: https://www.cnblogs.com/UncleYong/p/10737119.html
(一) zookeeper 是什么?(动物园)
ZooKeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。 ZooKeeper 通过其简单的架构和 API 解决了这个问题。 ZooKeeper 允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。 ZooKeeper 框架最初是在 “Yahoo!" 上构建的,用于以简单而稳健的方式访问他们的应用程序。 后来, Apache ZooKeeper 成为 Hadoop , HBase 和其他分布式框架使用的有组织服务的标准。
首先我们来了解一下什么是分布式 ,顺便理清几种结构:
分布式应用的优点:
l 可靠性 - 单个或几个系统的故障不会使整个系统出现故障。
l 可扩展性 - 可以在需要时增加性能,通过添加更多机器,在应用程序配置中进行微小的更改,而不会有停机时间。
l 透明性 - 隐藏系统的复杂性,并将其显示为单个实体 / 应用程序。
分布式应用的挑战:
l 竞争条件 - 两个或多个机器尝试执行特定任务,实际上只需在任意给定时间由单个机器完成。例如,共享资源只能在任意给定时间由单个机器修改。
l 死锁 - 两个或多个操作等待彼此无限期完成。
l 不一致 - 数据的部分失败。
1 、 单机结构
我想大家最最最熟悉的就是单机结构,一个系统业务量很小的时候所有的代码都放在一个项目中就好了,然后这个项目部署在一台服务器上就好了。整个项目所有的服务都由这台服务器提供。这就是单机结构。那么,单机结构有啥缺点呢?我想缺点是显而易见的,单机的处理能力毕竟是有限的,当你的业务增长到一定程度的时候,单机的硬件资源将无法满足你的业务需求。此时便出现了集群模式,往下接着看。
2、集群结构
集群模式 其实很简单,虽然在程序界把它吹得牛哄哄的,来看下面,初步理解。其实也就是在单机结构上做的演变。 单机 结构 处理到达瓶颈的时候,你就把单机复制几份,这样就构成了一个 “ 集群 ” 。集群中每台服务器就叫做这个集群的一个 “ 节点 ” ,所有节点构成了一个集群。每个节点都提供相同的服务,那么这样系统的处理能力就相当于提升了好几倍(有几个节点就相当于提升了这么多倍)。但问题是用户的请求究竟由哪个节点来处理呢?最好能够让此时此刻负载较小的节点来处理,这样使得每个节点的压力都比较平均。要实现这个功能,就需要在所有节点之前增加一个 “ 调度者 ” 的角色,用户的所有请求都先交给它,然后它根据当前所有节点的负载情况,决定将这个请求交给哪个节点处理。这个 “ 调度者 ” 有个牛逼了名字 —— 负载均衡服务器。 集群结构的好处 : 就是系统扩展非常容易。如果随着你们系统业务的发展,当前的系统又支撑不住了,那么给这个集群再增加节点就行了。但是,当你的业务发展到一定程度的时候,你会发现一个问题 —— 无论怎么增加节点,貌似整个集群性能的提升效果并不明显了。这时候,你就需要使用微服务结构了。 ( 中间来插一个负载均衡的知识 )
负载均衡 的原理: 一台服务器的处理能力只能达到每秒几万个到几十万个请求,无法在一秒钟内处理上百万个甚至更多的请求。但若能将多台这样的服务器组成一个系统,并通过软件技术将所有请求平均分配给所有服务器处理,那么这个系统完全拥有每秒钟处理几百万甚至更多请求的能力。这就是负载均衡最初的设计思想。
负载均衡 : 负载均衡是由多台服务器一对称的方式组成一个服务器集合,每台服务器都具有等价的地位,都可以单独对外提供服务而无须其他服务器的辅助。通过某种负载分担的技术,将外部发送来的请求均匀分配到堆成结构中的某一台服务器上,而接收到请求的服务器独立的回应客户的的请求。负载均衡能够平均奉陪客户请求到服务器的集群上,来快速获取重要的数据,解决高并发访问服务问题。负载均衡的手段:软 / 硬件负载均衡。 软负载均衡: 通过在一台或者多台服务器响应的操作系统上安装一个或附加软件来实现。 硬件负载均衡: 直接在服务器的外部和外部网络间安装负载均衡硬件设备。
比喻列子: 小饭店原来只有一个厨师,切菜洗菜备料炒菜全干,后来客人多了,厨房一个厨师忙不过来,又请了一个厨师,两个厨师都炒一样的菜,这两个厨师的关系是集群,为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系是分布式,一个配菜师也忙不过来,又请了一个配菜师,这两个配菜师的关系是集群。分布式讲究的是协作,一个事件的发生可以触发多个事件同时进行不同的业务运算。而集群中的成员功能是一样的。
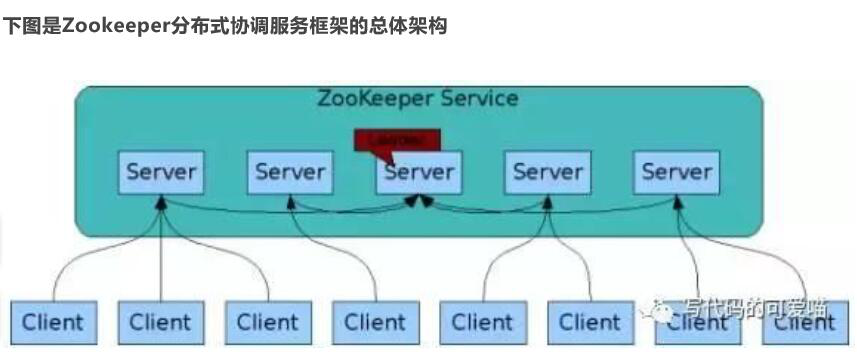
ZooKeeper 的好处 :
以下是使用 ZooKeeper的好处:
l简单的分布式协调过程
l 同步 - 服务器进程之间的相互排斥和协作。此过程有助于 Apache HBase 进行配置管理。
l有序的消息
l 序列化 - 根据特定规则对数据进行编码。确保应用程序运行一致。这种方法可以在 MapReduce 中用来协调队列以执行运行的线程。
l可靠性
l 原子性 - 数据转移完全成功或完全失败,但没有事务是部分的。
(二) zookeeper 用来做什么?
应用场景 1 : 统一命名服务
简单点来说,就是伪分布式系统提供一套完整的命名规则。既能产生唯一的名称又便于让人识别和记住。
应用场景 2 : 配置管理
通过 zookeeper 达到统一的配置文件管理,将配置文件保存在 zookeeper 的某个目录节点中,然后将所有需要修改的应用及其监控配置信息的状态(也就是用上面我们说到的 watcher )。一旦配置文件发生变化,每台机器就会收到 zookeeper 的通知。然后从 zookeeper 获取到最新的配置信息应用到系统中。
应用场景 3 : 集群管理
如果有多台 server 组成的一个服务集群,那么必须要一个 “ 总管 ” 知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中的其他机器必须知道,同样当增加一台或多台 server ,同样也必须让 “ 总管知道 ” ,从而做出调整重新分配服务策略。 Zookeeper 不仅能维护当前集群中机器的服务状态,而且能够选出一个 “ 总管 ” ,让这个总管来管理集群。
应用场景 4 : 数据发布 / 订阅 (其实也就是 dubbo 的注册中心)
数据发布 / 订阅系统,就是将数据发布到 ZooKeeper 的一个或一系列节点上,供订阅者进行数据订阅,从而达到动态获取数据的目的。发布 / 订阅系统一般有两种设计模式,分别是推( Push )和拉( Pull )。 ZooKeeper 中采用的是推拉接口的方式:客户端向服务端注册自己需要关注的节点,一旦该节点数据发生变更,服务端就会向相应的客户端发送 Watcher 事件通知,客户端收到这个消息后,需要主动到服务端获取最新的数据。
应用场景 5 : 负载均衡
在分布式系统中,负载均衡是一种普遍的技术。 ZooKeeper 作为一个集群,负责数据的存储以及一系列分布式协调。所有的请求,会通过 ZooKeeper 通过一些调度策略去协调调度哪一台服务器。
(三) zookeeper 安装与部署?
(一)去官网下载

( 2 )先说 windows 系统安装,注意首先要确认 java 环境是否配置
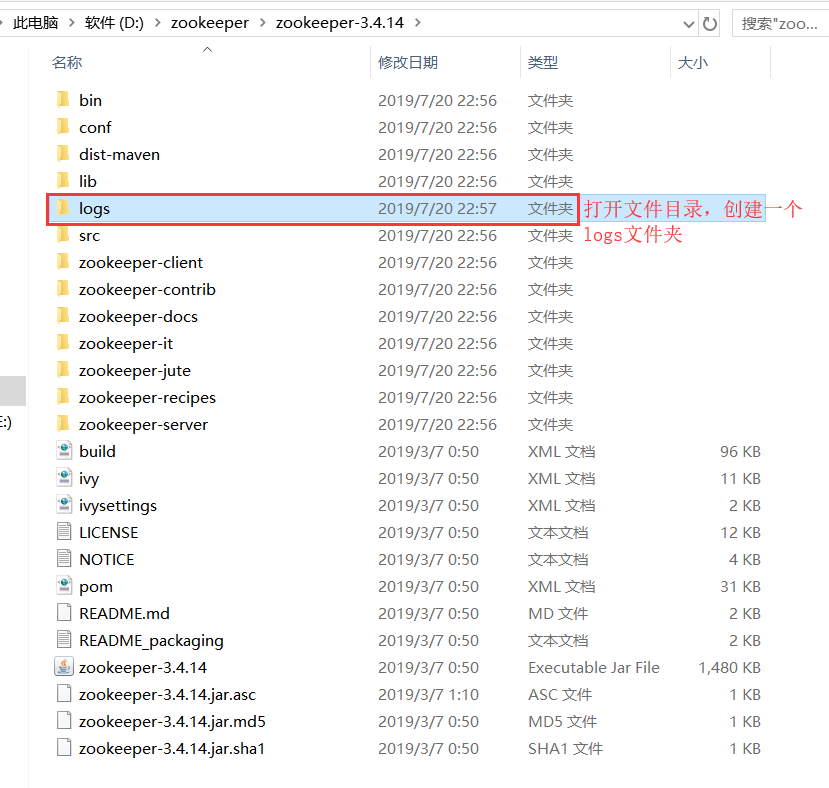
1 、 解压到你的磁盘,打开目录文件并创建一个 logs 文件夹
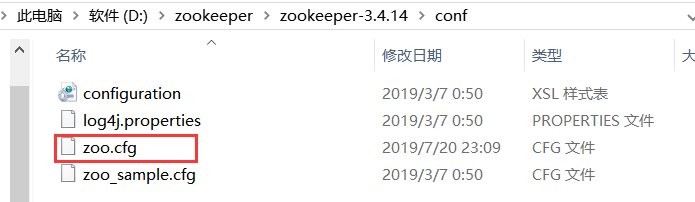
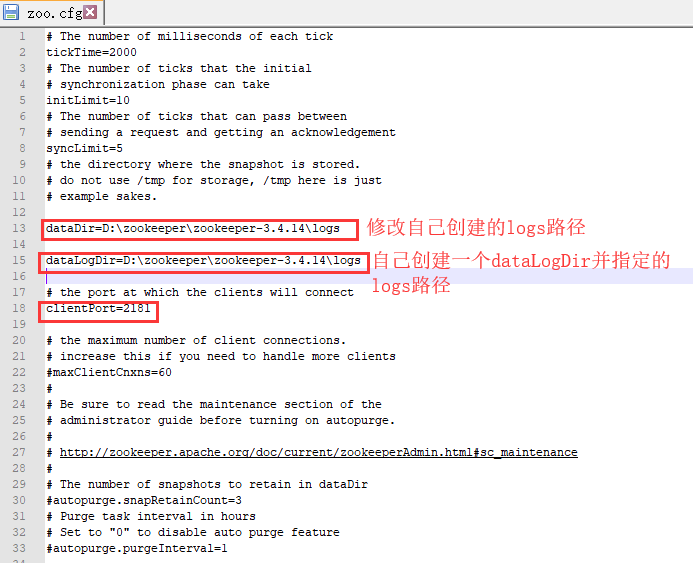
2 、进入 config 目录,将 zoo_sample.cfg 复制一份,并重命名 zoo_sample.cfg 为 zoo.cfg ,并进到 zoo.cfg 里面去修改一些东西,这要是日志目录和端口
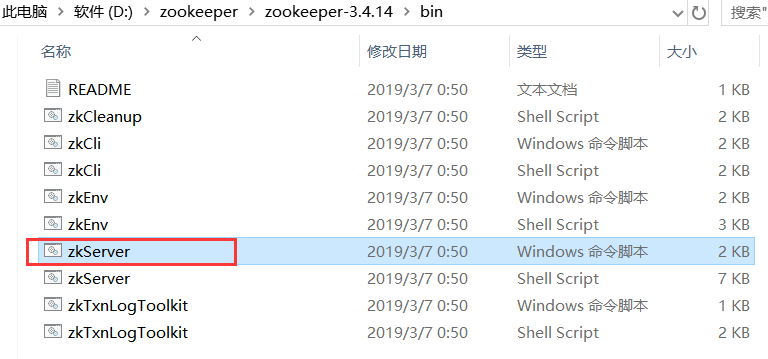
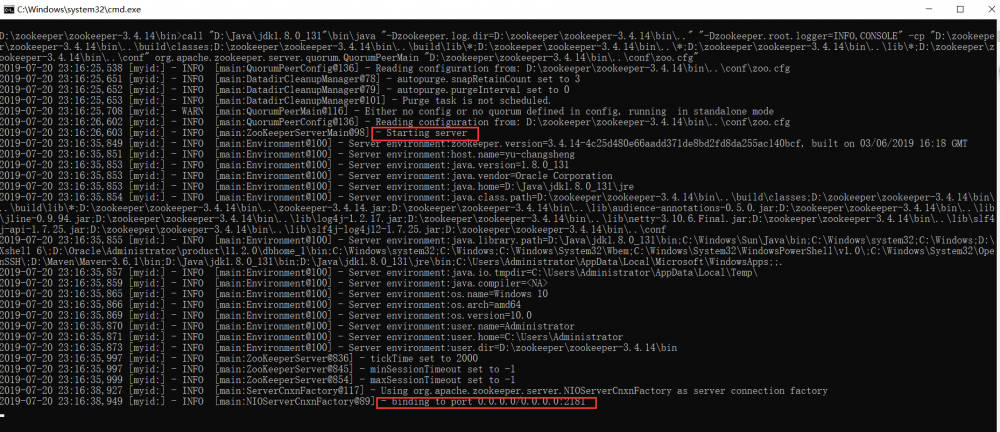
3、 进入 bin 目录,启动服务端
4、 进入 bin 目录,启动客户端
Dubbo
(1)Dubbo是什么?
Dubbo 是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC (远程调用) 实现服务的输出和输入功能,可以和 Spring 框架无缝集成。 Dubbo 是一款高性能、轻量级的开源 Java RPC 框架,它提供了 三大核心能力 : 面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
在这里插播一条关于 RPC 的简介:
RPC(Remote Procedure Call Protocol) :远程过程调用:
两台服务器 A 、 B ,分别部署不同的应用 a,b 。当 A 服务器想要调用 B 服务器上应用 b 提供的函数或方法的时候,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义传达调用的数据。
说白了,就是你在你的机器上写了一个程序,我这边是无法直接调用的,这个时候就出现了一个远程服务调用的概念。
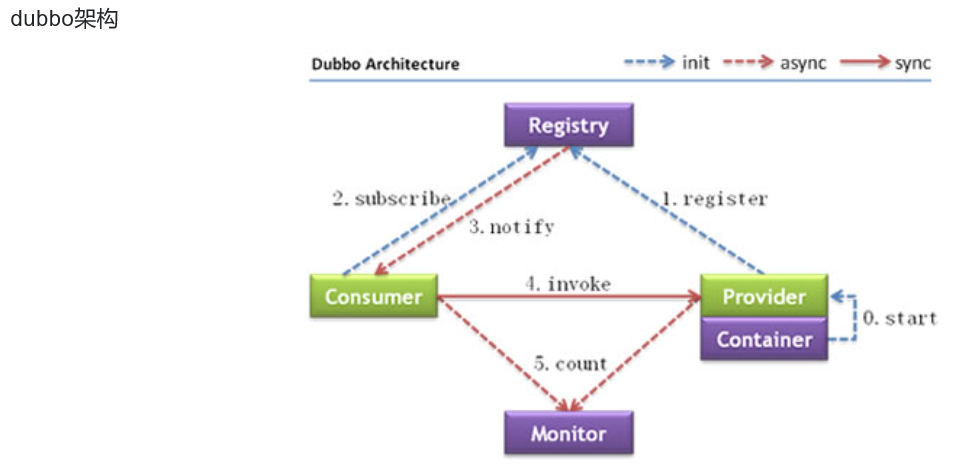
主要核心组件:
Remoting: 网络通信框架,实现了 sync-over-async 和 request-response 消息机制 。
RPC: 一个远程过程调用的抽象,支持负载均衡、容灾和集群功能 。
Registry: 服务目录框架用于服务的注册和服务事件发布和订阅 。
工作原理:
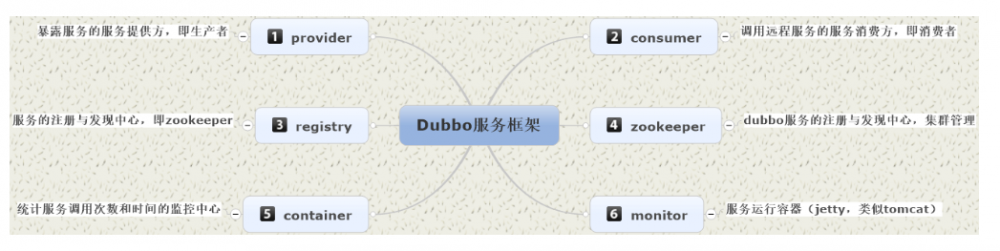
Provider : 暴露服务方称之为 “ 服务提供者 ” 。
Consumer : 调用远程服务方称之为 “ 服务消费者 ” 。
Registry : 服务注册与发现的中心目录服务称之为 “ 服务注册中心 ” 。
Monitor : 统计服务的调用次数和调用时间的日志服务称之为 “ 服务监控中心 ” 。
Conrainer : 服务运行容器。

(1) 连通性:
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
(2) 健壮性:
监控中心宕掉不影响使用,只是丢失部分 采样数据
数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
注册中心对等集群,任意一台宕掉后,将自动切换到另一台
注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
服务提供者无状态,任意一台宕掉后,不影响使用
服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
(3) 伸缩性:
注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
(2)Dubbo部署
1 、源码下载 http://dubbo.apache.org/en-us/blog/download.html
2、下载完成后解压,并通过Eclipse中Maven项目导入形式导进去,然后更新项目
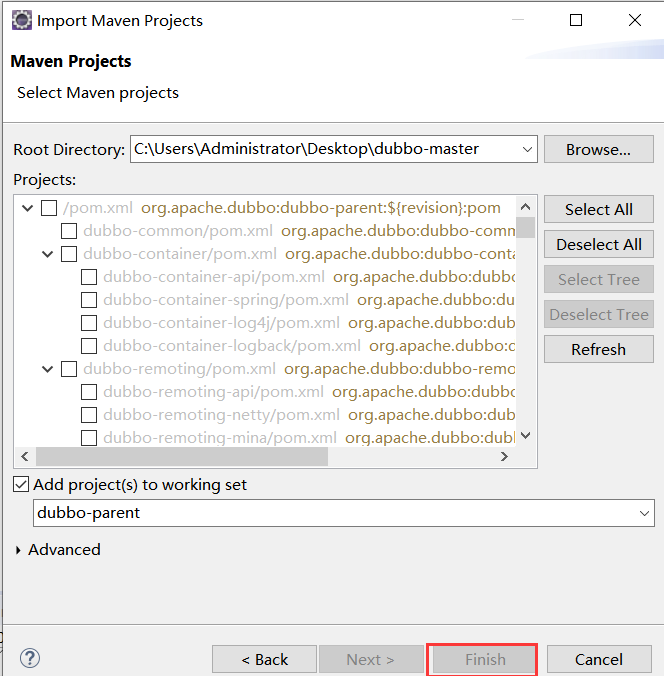
https://www.cnblogs.com/lionsblog/p/7767379.html
总结:文章很长,可能比较乏味,不过我都经过实践的,看到这里,我相信,你多少对分布式、微服务的组件有一点点了解,其实了解它,学习他并不难,只是一个过程,需要最初自己的理解,长久坚持。我最初写博客,也只是想对自己的理解做一个记录,如果本文有不合格的地方,可以指正,三人行,必有我师!
qq : 2931445528
-----------------------------------------------------------END----------------------------------------------------------------
正文到此结束
- 本文标签: eclipse 厨房 并发 集群 同步 数据 工作原理 智能 注册中心 Hadoop 总结 zookeeper http 代码 分布式 spring maven 软件 微服务 压力 consumer UI IO 空间 专注 源码 负载均衡 锁 HBase 主机 API id 目录 组织 Watcher remote 进程 provider 配置 下载 设计模式 专心 服务器 https 开发 apr 统计 管理 服务端 实例 缓存 端口 线程 dubbo 安装 文章 时间 分布式系统 apache ip 操作系统 部署 阿里巴巴 src IDE 长连接 HTML 服务注册 windows 数据库 开源 map 博客 需求 高并发 java
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

