JSCOUT前端监控平台架构分析
平台背景
前端监控平台(http://jscout.58corp.com)是一个集前端JS异常信息收集、分析、展示于一体的监控平台,用来弥补在项目上线之后对于JS异常发现的空缺,同时也可以提供更多的数据信息便于前端FE人员进行错误定位和分析调试。前端监控平台共分为三个主体部分:接入业务线的JS SDK、数据分析器、WEB展示平台。
1、JS SDK:通过简单的配置接入到需要监控的页面,并提供自定义配置满足业务线定制的需求;
2、数据分析器:通过定时任务,不断对收集的异常信息数据进行不同维度的扫描分析,并将对应的统计信息持久化;
3、WEB展示平台:相关用户登录平台即可观察目前被监控页面的JS异常信息及固定时间段的数据趋势,多角度的展示分析后的数据信息,同时也可通过查询功能快速定位特定条目的异常信息。
架构设计
针对前端监控平台的架构设计,我们从业界找了许多的架构设计作为参考,并结合平台的实际需求设计出前端监控平台的架构。
首先我们参考了比较常见的日志收集系统的架构,业界(如美团、京东等)日志收集系统架构图大致如下:
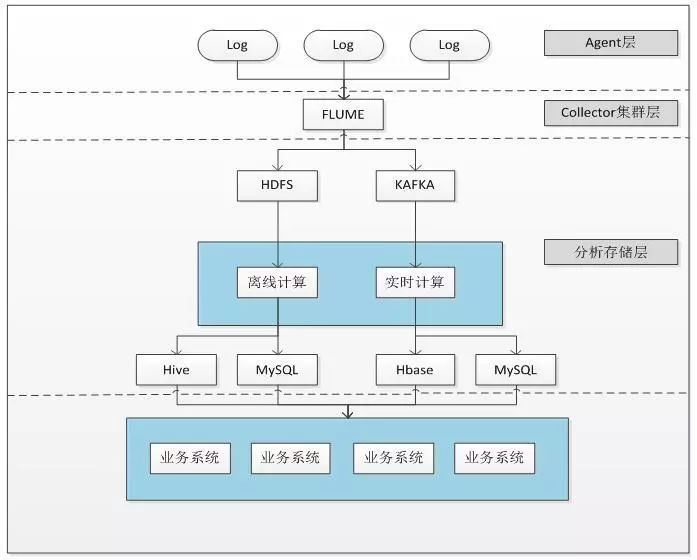
1、Agent层收集到各个系统的日志信息,通过Flume或者类似工具进行日志收集;
2、收集到的日志信息被分发到HDFS或者类似存储介质中进行对应的离线处理操作,同时也会分发到Kafka或者类似流处理工具中进行缓冲,用于进行对应的实时处理操作;
3、不论是离线还是实时都会根据特定的逻辑进行数据分析;
4、离线处理的结果会存储到Hive、MySQL等对应的存储介质中,实时处理的结果会存储到Hbase、MySQL等对应的存储介质中;
5、存储的数据为上层的业务系统提供数据支撑。
该套方案在每一层都可以进行横向扩容以支撑整个系统的高负载和实时性的要求。
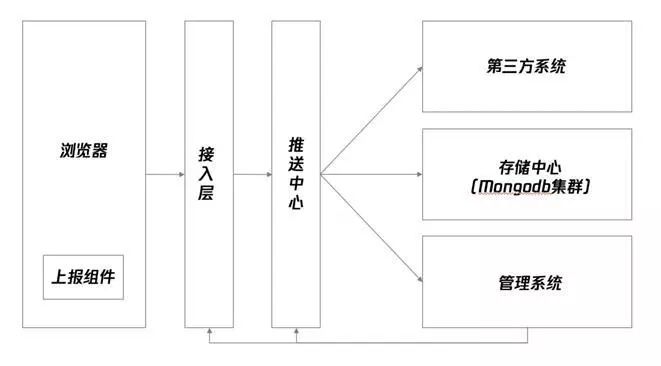
其次,我们也调研了业界前端监控平台的架构设计,这里主要参考了BetterJS平台的架构设计。通过提供独立的日志服务器接收客户端日志,接收过程中,要对客户端日志内容的合法性、安全性等进行甄别,防止被人攻击。而且由于日志提交一般都比较频繁,多客户端同时并发的情况也常见。通过消息队列将日志信息逐一处理后写入到数据库进行保存是比较常用的方案。BetterJS平台的架构设计中,“接入层”和“推送中心”就是这里提到的接入层和消息队列。BetterJS将整个前端监控的各个模块进行拆分,推送中心承担了将日志推送到存储中心进行存储和推送给其他系统(例如告警系统)的角色,但我们可以把接收日志阶段的队列独立出来看,在接入层和存储层之间做一个过渡。
参考了上述平台的架构设计,可以推导出前端监控平台大致的架构设计思路,主体的架构图如下:
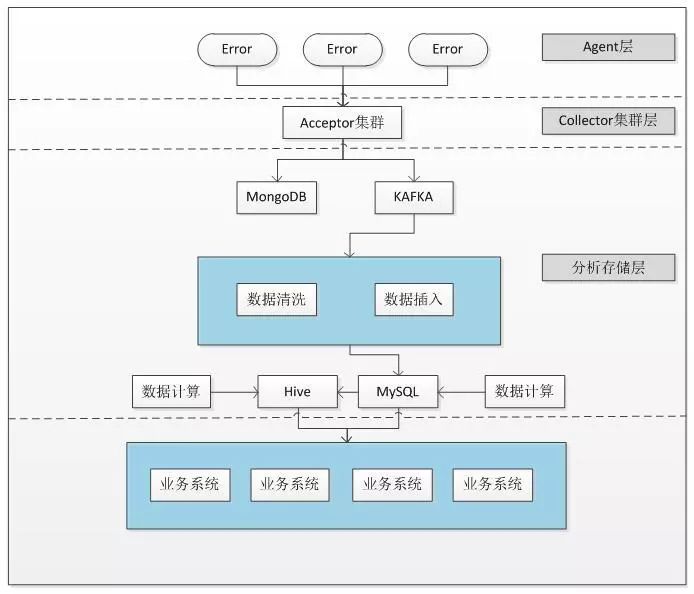
1、前端异常日志通过SDK上报给接收服务器Acceptor,可以通过nginx负载均衡进行集群化;
2、收集到的异常日志流向两个方向,MongoDB中存储原始数据用于故障之后的数据恢复,Kafka中则缓冲大量高并发的数据(Kafka是一个支持分布式消息存储和消费的系统),然后用类似小水管的方式转入分析平台,减轻分析平台的性能压力,Kafka消息队列可以有效地缓冲系统的流量压力,避免系统在大数据的压力下崩溃。同时Kafka可以强有力地推动解决高吞吐量、高性能、高实时性要求的系统的开发和设计。Kafka在设计之初就被赋予了快速持久化,高吞吐率,同时支持离线数据处理和实时数据处理,完全的支持分布式系统并支持在线水平扩展,因此在此处加入了Kafka的环节;
3、分析平台中,会先将Kafaka中的数据进行以记录为粒度的数据清洗(判断是否命中规则以便反写数据)和数据插入(插入MySQL)操作;
4、于此同时在MySQL中会有如分组计算统计相关的数据计算操作,来优化业务系统查询数据时的性能;
5、对于时间跨度较大的统计,采用离线Hive任务进行计算;
6、上层的业务系统通过查询数据库中的数据来进行对应的操作。
需要注意的事项
1、Collector层(接收层),可以横向扩容,以提高高并发的要求,如接收性能数据或者一些异常录制数据的场景;
2、增加消息队列(如Kafka等),以应对非法攻击和高并发的要求,本着类似小水管的原则,将高并发的数据慢慢的流向对应的业务数据库中,同时也能够进行扩容消费者来提升整体的性能(允许异常日志的无序和少量丢失);
3、在存储系统中,目前看来单库单表的是难以应对的。目前业界已经有比较完备的日志存储方案,主要有:MySQL分表、Hbase系,Dremel系,Lucene系等。总体而言,日志存储系统主要面对的问题是数据量大,数据结构不规律,写入并发高,查询需求大等。我们的平台中选择使用MySQL分表来完成对应的存储操作。
为了应对未来大量数据的存储以及对于实时计算的高要求,我们同公司大数据部门进行深入的沟通和合作,在进行了对现有数据在MySQL和HBase上性能数据对比之后,我们得出了MySQL分表 + 离线Hive模式底层数据存储架构。
结合前端监控平台的实际业务需求,MySQL和HBase在性能方面数据对比如下:
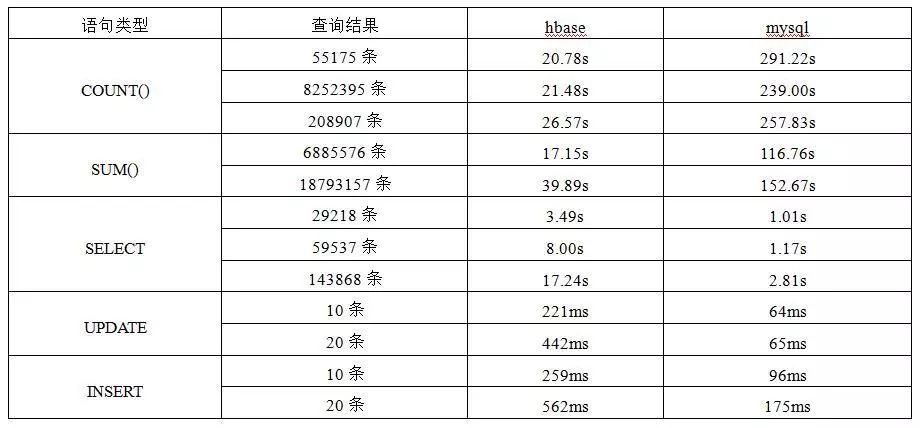
1、在执行函数操作(如COUNT、SUM)时,HBase的时间效率更高;
2、在执行查询、插入和修改操作时,MySQL的时间效率更高;
3、在实际的数据操作中,执行查询、插入和修改操作的频率占比高于使用函数的;
4、在数据量级上,考虑内存大小是主要的性能瓶颈,所以应该尽量控制单次查询获取的数据量;
5、针对跨时间段大量数据的分组统计操作可以通过离线Hive任务进行计算获得。
综上所述,我们选择MySQL分表 + 离线Hive模式为底层架构。
在具体的MySQL分表维护方面我们也进行了基本的约定,在数据完整性的基础上保证其效率。
基本约定
1、在对MySQL的扩展方面,我们根据项目ID进行分表,这样子既保证 了 业务独立也可避免单表过大影响查询效率;
2、对于接入数据类型,不同业务的不同类型也会独立单表,比如二手房业务,会有异常数据表和性能数据表;
3、对于业务线需要拆分项目的情况,原则上是不拆分旧表数据的,如有特殊情况需特殊处理;
4、针对个别业务线单表过大的情况,采用基础日期分割的方法,提升查询效率;
5、表数据的留存方面,按照至少留存一年有效数据的原则,可以通过两个阶段删除上一年的数据,第一阶段为6月1日删除上一年前半年的数据,第二阶段为下一年1月1日删除上半年后半年的数据;
6、统计数据在短时间内不会清除(>=3年);
7、离线Hive任务会执行以季度、半年和年为单位的数据统计相关的操作。
本文主要阐述了前端监控平台的架构设计,本身平台的架构设计也是根据实际出现的业务需求以及性能瓶颈去做的优化,同时在平台的后续使用过程中也会根据实际情况进行改进,正所谓从实践中来到实践中去。在前端监控的道路上,我们希望可以和感兴趣的小伙伴一起合作交流,不断进步。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

