纯数据结构Java实现(2/11)(栈与队列)
栈和队列的应用非常多,但其起实现嘛,其实很少人关心。
虽然苹果一直宣传什么最小年龄的编程者,它试图把编程大众化,弱智化,但真正的复杂问题,需要抽丝剥茧的时候,还是要 PRO 人士出场,所以知根知底,实在是必要之举(而非无奈之举)。
大门敞开,越往里走越窄,竞争会越激烈。
栈
基本特性
就一条,FILO。但是用在其他复杂数据结构,比如树,或者用在其他应用场景的时候,比如记录调用过程中的变量及其状态等,超有用。
应用举例
比如 撤销操作:
用户每次的录入都会入栈,被系统记录,然后写入文件;但是用户撤销,则是当前的操作出栈,此时上一次操作位于栈顶,也就相当于本次操作被取消了。
这里始终 操作栈顶 即可。
比如 程序调用栈:
函数一调用就会入栈(因为这个函数可能内部还要调用别的函数),函数调用返回时,出栈。
每次返回时不知道下一步执行谁?不会的,它会参考栈里面记录的调用链。
比如 括号匹配 问题:
遇到左括号(只要是左边括号)就入栈,碰到右边括号就比较,如果匹配,那么就出栈。(不匹配直接返回false)
(抱歉,Python代码写多了,老是忘记加上 ;
分号)
顺序栈实现
定义好接口,然后内部封装一个动态数组,实现接口的方法即可。
大概的接口,通用的方法就五个:
public interface Stack<E> {
//接口中声明相关方法即可
boolean isEmpty();
int getSize();
E pop();
E peek();
void push(E e);
}
然后实现代码如下:
// 真正的实现
import array.AdvanceDynamicArray;
public class ArrayStack<E> implements Stack<E> {
//底层实现是动态数组,所以内部直接引用动态数组就好了
AdvanceDynamicArray<E> array;
public ArrayStack(int capacity) {
array = new AdvanceDynamicArray<>(capacity);
}
public ArrayStack() {
array = new AdvanceDynamicArray<>();
}
@Override
public boolean isEmpty() {
return array.isEmpty();
}
@Override
public int getSize() {
return array.getSize();
}
@Override
public E pop() {
return array.pop();
}
@Override
public E peek() {
return array.getLast();
}
@Override
public void push(E e) {
array.append(e);
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("Stack [");
for (int i = 0; i < array.getSize(); i++) {
res.append(array.get(i));
if (i != array.getSize() - 1) {
res.append(", ");
}
}
res.append("],top right");
return res.toString();
}
}
没事儿简单测试一下看看:
//测试一下栈
private static void test_stack_1() {
ArrayStack<Integer> stack = new ArrayStack<>(); //默认内部动态数组容量 10
//推入 5 个元素
for(int i=0; i< 5; i++){
stack.push(i);
System.out.println(stack); //每次入栈,打印一次
}
System.out.println("---------");
stack.pop();
System.out.println(stack);
}
// 打印输入结果如下:
Stack [0],top right
Stack [0, 1],top right
Stack [0, 1, 2],top right
Stack [0, 1, 2, 3],top right
Stack [0, 1, 2, 3, 4],top right
---------
Stack [0, 1, 2, 3],top right
复杂度分析
基本都在末尾操作,所以基本都是 O(1)。
(push 和 pop 由于涉及到扩容和缩容,所以上面的 O(1) 其实是均摊的)
普通队列
同样是一个操作受限的容器
基本特性
感觉就一条 FILO 。
应用举例
我接触的用到的队列,要么是支持并发操作的并发队列,由于加锁,所以并发性并不是很好。
另外一种就是异步任务队列,即把工作加入队列,由外部 IO 接口读取(可能是多个线程,也可能是多路复用的读)
哦,个人在广度优先遍历时用过。(需要统计相关目录及其子目录的各种各样语言的代码量,此时把子目录加入到队列尾部,然后不断出队检查当前目录的文件)
顺序队列实现
-
定义好接口,底层实现用
动态数组完成接口中的方法 -
入队
enqueue,出队dequeue为核心 (不必担心满和空,因为一个在数组尾部操作,一个在数组头部操作,空间够不够底层数组负责)
接口及其实现 如下:
//接口
public interface Queue<E> {
boolean isEmpty();
int getSize();
E dequeue();
E getFront();
void enqueue(E e);
}
public class ArrayQueue<E> implements Queue<E> {
private AdvanceDynamicArray<E> array;
public ArrayQueue(int capacity) {
array = new AdvanceDynamicArray<>(capacity);
}
public ArrayQueue() {
array = new AdvanceDynamicArray<>();
}
@Override
public boolean isEmpty() {
return array.isEmpty();
}
@Override
public int getSize() {
return array.getSize();
}
@Override
public E dequeue() {
return array.popLeft();
}
@Override
public E getFront() {
return array.getFirst();
}
@Override
public void enqueue(E e) {
array.append(e);
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("Queue: [");
for(int i = 0; i< array.getSize(); i++) {
res.append(array.get(i));
if(i != array.getSize() - 1) {
res.append(", ");
}
}
res.append("],tail");
return res.toString();
}
//测试看看
public static void main(String[] args) {
ArrayQueue<Integer> queue = new ArrayQueue<>();
//放入元素
for(int i = 0; i< 10; i++) {
queue.enqueue(i);
System.out.println(queue); //放入一个元素,查看一次队列
}
//出栈试试
System.out.println("--------");
queue.dequeue();
System.out.println(queue);
}
}
输出结果:
Queue: [0],tail Queue: [0, 1],tail Queue: [0, 1, 2],tail Queue: [0, 1, 2, 3],tail Queue: [0, 1, 2, 3, 4],tail Queue: [0, 1, 2, 3, 4, 5],tail Queue: [0, 1, 2, 3, 4, 5, 6],tail Queue: [0, 1, 2, 3, 4, 5, 6, 7],tail Queue: [0, 1, 2, 3, 4, 5, 6, 7, 8],tail Queue: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],tail -------- Queue: [1, 2, 3, 4, 5, 6, 7, 8, 9],tail
复杂度分析
其实就是出队的时候,从头部出,涉及到移动(覆盖元素),所以为 O(n)
其他操作都只在尾部进行,所以都是 O(1),其中尾部 enqueue 是均摊。总体来说,这个出队的消耗时间太大了。如果要 底层实现不变 ,可以实现其他队列, 减少移动次数 。
循环队列
循环队列是如何减少移动操作?
出队一定要移动元素么?如果只移动记录队首的标记,这样会不好好一点?
- 尝试移动标记队首、队尾的标志(索引)
循环队列有一个非常重要的点, 区分队列满、队列空的条件 :
(tail+1)%capacity == front tail == front
人为的浪费一个空间,不存元素,和队列空条件区分开。(否则队列满和空都能用 tail == front
来判断,无法区分)
基本原理
其实也就是相对于普通队列而言,支持其优化的理由在哪里。
首先老规矩, front
肯定指向的是第一个元素, tail
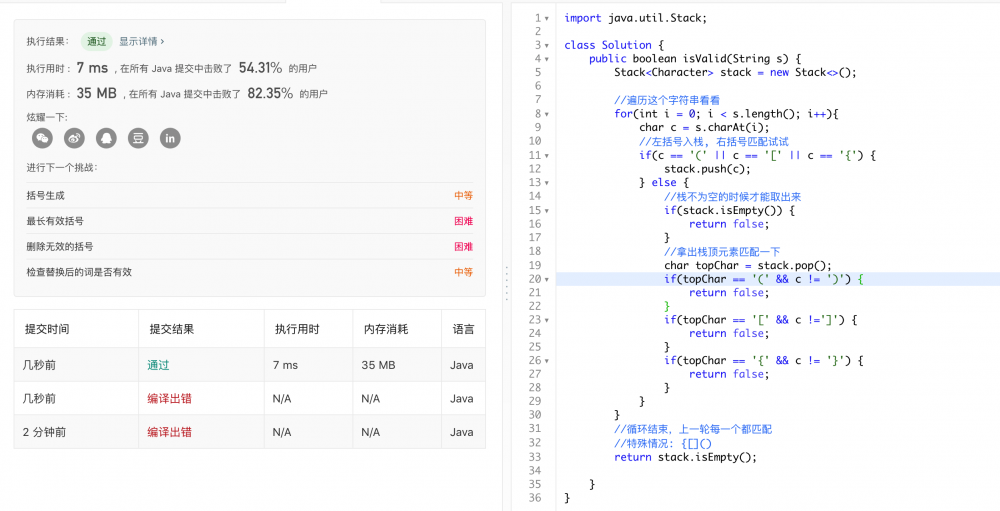
肯定执行的是最后一个元素的后一个位置,大致如下图:
也即是说,还是基于顺序存储的结构,新增两个变量记录队首和队尾的索引。
然后看一下 tail 和 front 都是怎么变? 一句话总结:
- 添加元素 tail++ ((tail+1)%capacity)
- 删除元素 front++ ((front+1)%capacity)
在队列中移动索引,front 或者 tail, 都要取模,以免越界。
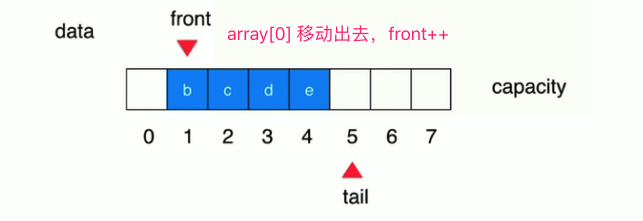
细说, 初始状态 ,没有元素,两者都指向索引为 0 的位置,然后添加元素 tail++,不断添加不断++;当且仅在队首出元素的时候,front++。
此时出队就不需要移动元素覆盖前面的了,直接移动索引 front 即可。然后就出现这样的状况:
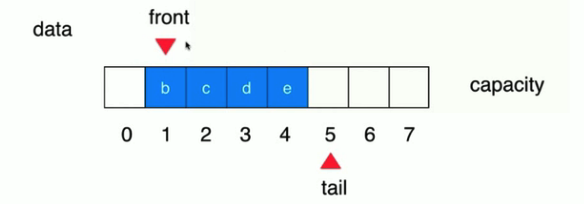
发现前面有可用的空间,然后也还会出现这样的状态:
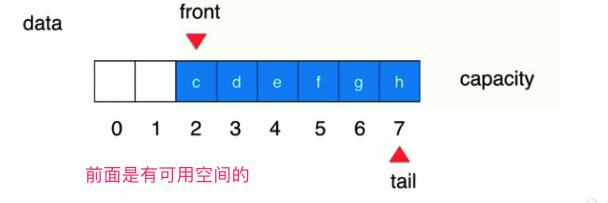
然后再往里面扔一个元素试试,结果就 循环了 :
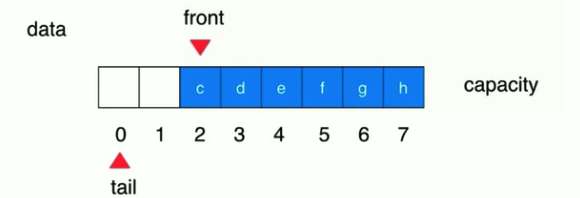
那再放一个呢?队列满了。
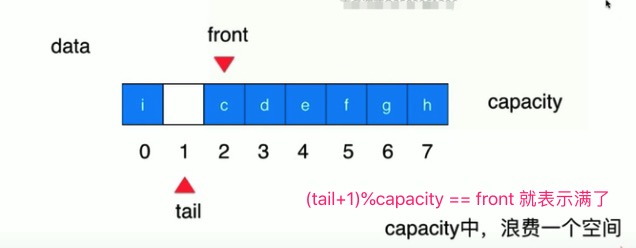
(因为前面说过认为的空出一个空间,让队列满和队列空区分开来)
这里的扩容怎么设计?需要修改底层动态数组么?
原始的动态数组方式,即使它扩容,也无法改变 front 和 tail 关系,所以不适用。
(且扩容拷贝的时候,也要考虑偏移,即取模问题)
具体实现
先把基于 Queue 接口把框架写出来,然后填补 enqueue 和 dequeue 方法。
public class LoopQueue<E> implements Queue<E> {
//内部自己维护一个数组
private E[] data;
private int front, tail; //front 指向头,tail 指向队尾的下一个元素
private int size; //其实可以用通过 front, tail 实现,但复杂,容易出错
public LoopQueue(int capacity){
data = (E[]) new Object[capacity+1]; //因为要故意浪费一个空间
front = tail = 0;
size = 0;
}
public LoopQueue(){
data = (E[]) new Object[10+1]; //因为要故意浪费一个空间,默认存储10个元素
front = tail = 0;
size = 0;
}
//外部能感知的实际能存储的 capacity
public int getCapacity() {
return data.length -1; //注意是 data.length 少一个
}
//快捷方法,判断队列满 -- 用户不用关心,client始终可以放入 (因为会动态扩容)
private boolean isFull() {
//return (tail+1)%getCapacity() == front;
return (tail+1)%data.length == front; //判断队列满,用实际的 data.length 判断
}
@Override
public boolean isEmpty() {
//return size == 0;
return front == tail; //特别注意队列为空的条件
}
@Override
public int getSize() {
return size; //专门有一个变量维护
}
@Override
public E getFront() {
//但凡要取元素,都要看看是否为空
if(isEmpty()){
throw new IllegalArgumentException("队列为空,不能出队");
}
return data[front];
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append(String.format("Queue: size=%d, capacity=%d/n", size, getCapacity()));
res.append("front [");
/*
for (int i = 0; i < size; i++) {
res.append(data[i]);
if (i != size - 1) {
res.append(", ");
}
} */
//相对于 front 偏移的方式也是可以的 data[(i+front)%data.length]
for (int i = front; i != tail; i = (i+1)%data.length) {
res.append(data[i]);
if ((i+1)%data.length != tail) { //不是最后一个元素之前的一个元素
res.append(", ");
}
}
res.append("] tail");
return res.toString();
}
// ---------------------- TODO
@Override
public E dequeue() {
//TODO
return null;
}
@Override
public void enqueue(E e) {
//TODO
}
}
上面的遍历方式也可以用取模偏移来写。
然后实现遗留下来的两个 TODO:
入队
,先看队列是否为满。
- 如果满,则重新分配空间,此时新空间自然应该从 0 开始放元素:
@Override
public void enqueue(E e) {
//添加之前,先要看看队列是否是满的
if (isFull()) {
//抛出异常 or 动态扩容(包括移动元素)
resize(2 * getCapacity()); //当前实际占用空间*2
}
//入队列
//data[tail++] = e; // tail++ 可能超过了 data.length
data[tail] = e;
tail = (tail + 1) % data.length;
size++;
}
private void resize(int newCapacity) {
//改变容量,然后移动元素,重置索引
E[] newData = (E[]) new Object[newCapacity + 1];
//复制: 把旧的元素,放入新的数组
//新数组的索引是从 0 -> size 的
for (int i = 0; i < size; i++) {
//newData[i] = data[?];
newData[i] = data[(front + i) % data.length]; //索引移动,用的是data.length 判断
}
//重置索引
front = 0;
tail = size; //实际个数是不变的
data = newData; //data.length 变化了,所以 getCapacity() 自然也变了
}
出队
操作,先看队列是否 为空
:
- 如果为空,不返回或者抛出异常
@Override
public E dequeue() {
//先看看是否为空
if(isEmpty()){
throw new IllegalArgumentException("队列为空,不能出队");
}
E ret = data[front];
//最好还是把 data[front] 处理一下
data[front] = null;
front = (front+1)%data.length;
size--;
// 是否需要缩减容量
return ret;
}
其实还没有完,如果一直出列,size 比 data.length 小太多,则有必要缩减容量。
即在出队 dequeue 的代码中有必要添加 是否需要缩减容量 这一段:
@Override
public E dequeue() {
//先看看是否为空
if(isEmpty()){
throw new IllegalArgumentException("队列为空,不能出队");
}
E ret = data[front];
//最好还是把 data[front] 处理一下
data[front] = null;
front = (front+1)%data.length;
size--;
//缩减容量(lazy 缩减),当实际存储为 1/4 capacity时,capacity缩减为一半
if(size == getCapacity()/4 && getCapacity()/2 != 0) {
resize(getCapacity()/2); //缩减后的容量不能为0
}
return ret;
}
测试看看:
public static void main(String[] args) {
LoopQueue<Integer> queue = new LoopQueue<>(); //默认实际存储 10 个元素
//存储 11 个元素看看
for(int i=0; i<11; i++){
queue.enqueue(i);
System.out.println(queue); // 在 10 个元素满的时候回扩容
}
//出队试试
System.out.println("------");
queue.dequeue();
System.out.println(queue);
//出队到只剩 5 个元素,即 20/4 时,缩减容量
queue.dequeue();
queue.dequeue();
queue.dequeue();
queue.dequeue();
queue.dequeue();
// 6, 7, 8, 9 10
System.out.println(queue); //此时容量变为 10 了
}
运行结果:
Queue: size=1, capacity=10 front [0] tail Queue: size=2, capacity=10 front [0, 1] tail Queue: size=3, capacity=10 front [0, 1, 2] tail Queue: size=4, capacity=10 front [0, 1, 2, 3] tail Queue: size=5, capacity=10 front [0, 1, 2, 3, 4] tail Queue: size=6, capacity=10 front [0, 1, 2, 3, 4, 5] tail Queue: size=7, capacity=10 front [0, 1, 2, 3, 4, 5, 6] tail Queue: size=8, capacity=10 front [0, 1, 2, 3, 4, 5, 6, 7] tail Queue: size=9, capacity=10 front [0, 1, 2, 3, 4, 5, 6, 7, 8] tail Queue: size=10, capacity=10 front [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] tail Queue: size=11, capacity=20 front [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] tail ------ Queue: size=10, capacity=20 front [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] tail Queue: size=5, capacity=10 front [6, 7, 8, 9, 10] tail
实现总结
-
开辟内部数组时,data.length 始终要比指定的
capacity多一个-
即便是 resize,也是
new Object[newCapacity + 1]
-
即便是 resize,也是
-
队列空
front == tail,队列满(tail+1)%capacity == tail - 满、空的判断都要放在前面(enqueue, dequeue)
- 索引的移动都要取模,包括 tail 和 front
此时,出队的复杂度也变为 O(1) 了(因为根本没有移动元素)。
复杂度分析
还分析啥?因为普通队列 dequeue 时要移动元素,O(n),所以这里才会拉扯一个循环队列。
所以除了 dequeue 是均摊的 O(1) 以及 enqueue 均摊O(1),其他操作都是 O(1)。
(链式存储的部分,后续再补充进来)
如果有不正确的地方,欢迎批评指正。
以防万一,我这里还是把相关代码上传到 gayhub 上了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

