后端开发实践系列——事件驱动架构(EDA)编码实践
在本系列的前两篇文章中,笔者分别讲到了后端项目的代码模板和DDD编码实践,在本文中,我将继续以编码实践的方式分享如何落地事件驱动架构。
单纯地讲事件驱动架构(Event Driven Architecture, EDA),那是几十年前就出现了的话题;单纯地讲领域事件,那也是这些年被大量提及并讨论得快熟透了的软件用语。然而,就笔者的观察看,事件驱动架构远没有想象中那样普遍地被开发团队所接受。即便搞微服务的人都知道除了同步的HTTP还有异步的消息机制,即便搞DDD的人都知道领域事件是其中的一等公民,事件驱动架构所带来的优点并没有相应地转化为软件从业者的青睐。
我尝试着去思考其中的原因,总结出了两点:第一是事件驱动可能是客观世界的运作方式,但不是人的自然思考问题的方式;第二是事件驱动架构在给软件带来好处的同时,又会增加额外的复杂性,比如调试的困难性,又比如并不直观的最终一致性。
当然,事实上有不少软件项目都使用了消息队列,但是这里需要明确的是,对消息队列的使用并不意味着你的项目就一定是事件驱动架构,很多项目只是由于技术方面的驱动,小范围地采用了某些消息队列(比如RabbitMQ和Kafka等)的产品而已。偌大一个系统,如果你的消息队列只是用作邮件发送的通知,那么这样系统自然谈不上采用了事件驱动架构。
放到当下,微服务兴起,DDD重现,在采用事件驱动架构时, 我们需要考虑业务的建模、领域事件的设计、DDD的约束、限界上下文的边界以及更多技术方面的因素,这一个系统工程应该如何从头到尾的落地,是需要经过思考和推敲的。还是那句话,有讲究的编程并不是一件易事。
诚然,用好事件驱动架构存在实践上的难处,然而它的 优点 也委实诱人,本文希望形成一定的“条理”和“套路”,让事件驱动架构能够更简单的落地。
本文主要分为两大部分,第一部分独立于具体的消息队列实现来讲解通用的对领域事件的建模,第二部分以一个真实的微服务系统为例,采用RabbitMQ作为消息队列,并以此分享完整的事件驱动架构落地实践。
本文以DDD为基础进行编码,其中会涉及到DDD中的不少概念,比如聚合根、资源库和应用服务等,对DDD不熟悉的读者可以参考笔者的DDD编码实践文章。
本文的示例代码请参考github上的 e-commerce-sample 项目。
第一部分:领域事件的建模
领域事件是DDD中的一个概念,表示的是在一个领域中所发生的一次对业务有价值的事情,落到技术层面就是在一个业务实体对象(通常来说是聚合根)的状态发生了变化之后需要发出一个领域事件。虽然事件驱动架构中的“事件”不一定指“领域事件”,但本文由于密切结合DDD,因此当提到事件时,我们特指“领域事件”。
创建领域事件
关于领域事件的基础知识,请参考笔者的 在微服务中使用领域事件 文章,本文直接进入编码实践环节。
在建模领域事件时,首先需要记录事件的一些通用信息,比如唯一标识ID和创建时间等,为此创建事件基类 DomainEvent :
public abstract class DomainEvent {
private final String _id;
private final DomainEventType _type;
private final Instant _createdAt;
}
在DDD场景下,领域事件一般随着聚合根状态的更新而产生,另外,在事件的消费方,有时我们希望监听发生在某个聚合根下的所有事件,为此笔者建议为每一个聚合根对象创建相应的事件基类,其中包含聚合根的ID,比如对于订单(Order)类,创建 OrderEvent :
public abstract class OrderEvent extends DomainEvent {
private final String orderId;
}
然后对于实际的Order事件,统一继承自 OrderEvent ,比如对于创建订单的 OrderCreatedEvent 事件:
public class OrderCreatedEvent extends OrderEvent {
private final BigDecimal price;
private final Address address;
private final List<OrderItem> items;
private final Instant createdAt;
}
领域事件的继承链如下:
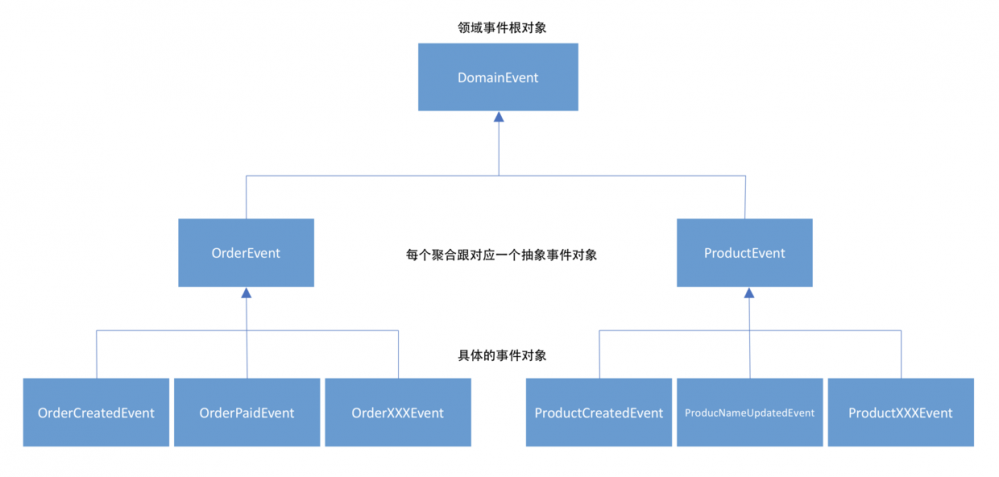
在创建领域事件时,需要注意2点:
ProductNameUpdatedEvent
public class ProductNameUpdatedEvent extends ProductEvent {
private String oldName; //更新前的名称
private String newName; // 更新后的名称
}
发布领域事件
发布领域事件有多种方式,比如可以在应用服务(ApplicationService)中发布,也可以在资源库(Repository)中发布,还可以引入事件表的方式,这3种发布方式的详细比较可以参考笔者的 在微服务中使用领域事件 文章。笔者建议采用事件表方式,这里展开讨论一下。
通常的业务处理过程都会更新数据库然后发布领域事件,这里一个比较重要的点是:我们需要保证数据库更新和事件发布之间的原子性,也即要么二者都成功,要么都失败。在传统的实践方式中, 全局事务(Global Transaction/XA Transaction) 通常用于解决此类问题。然而,全局事务本身的效率是很低的,另外,一些技术框架并不提供对全局事务的支持。当前,一种比较受推崇的方式是引入事件表,其流程大致如下:
- 在更新业务表的同时,将领域事件一并保存到数据库的事件表中,此时业务表和事件表在同一个本地事务中,即保证了原子性,又保证了效率。
-
在后台开启一个任务,将事件表中的事件发布到消息队列中,发送成功之后删除掉事件。
但是,这里又有一个问题:在第2步中,我们如何保证发布事件和删除事件之间的原子性呢?答案是:我们不用保证它们的原子性,我们需要保证的是“至少一次投递”,并且保证消费方幂等。此时的大致场景如下:
- 代码中先发布事件,成功后再从事件表中删除事件;
- 发布消息成功,事件删除也成功,皆大欢喜;
- 如果消息发布不成功,那么代码中不会执行事件删除逻辑,就像事情没有发生一样,一致性得到保证;
- 如果消息发布成功,但是事件删除失败,那么在第二次任务执行时,会重新发布消息,导致消息的重复发送。然而,由于我们要求了消费方的幂等性,也即消费方多次消费同一条消息是ok的,整个过程的一致性也得到了保证。
发布领域事件的整个流程如下:
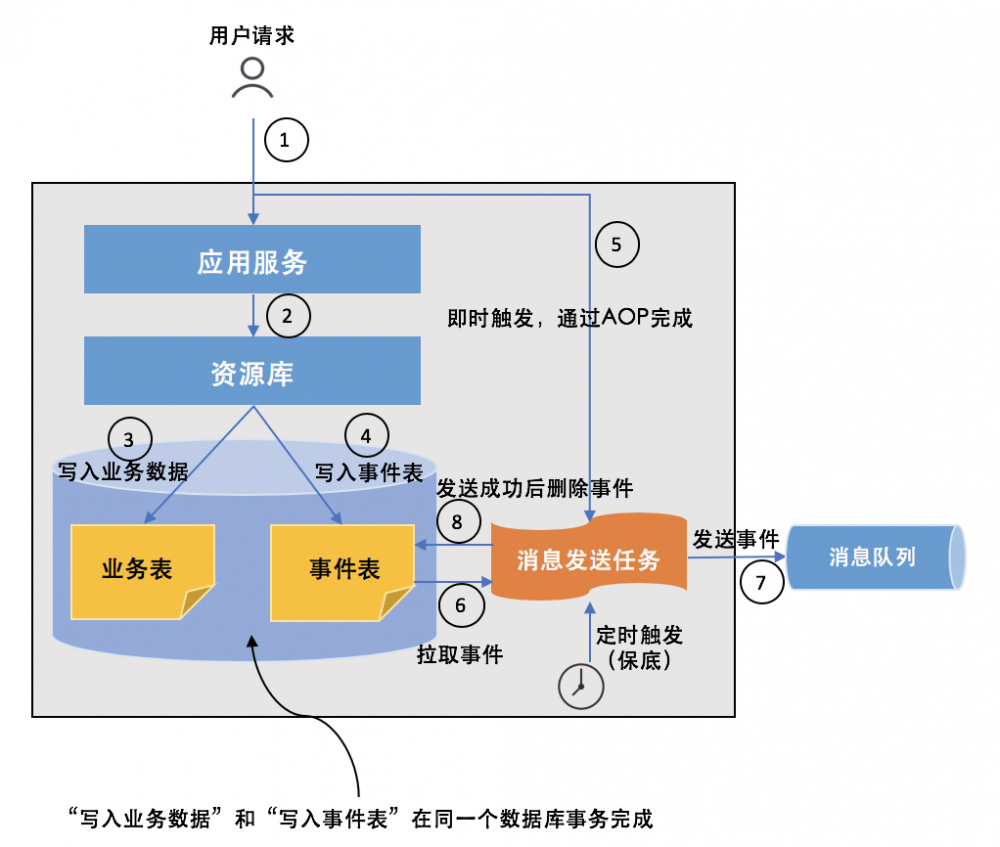
- 接受用户请求;
- 处理用户请求;
- 写入业务表;
- 写入事件表,事件表和业务表的更新在同一个本地数据库事务中;
- 事务完成后,即时触发事件的发送(比如可以通过Spring AOP的方式完成,也可以定时扫描事件表,还可以借助诸如MySQL的binlog之类的机制);
- 后台任务读取事件表;
- 后台任务发送事件到消息队列;
- 发送成功后删除事件。
更多有关事件表的介绍,请参考 Chris Richardson 的 “Transaction Outbox模式” 和 Udi Dahan 的 “在不使用分布式事务条件下如何处理消息可靠性” 的视频。
在事件表场景下,一种常见的做法是将领域事件保存到聚合根中,然后在Repository保存聚合根的时候,将事件保存到事件表中。这种方式对于所有的Repository/聚合根都采用的方式处理,因此可以创建对应的抽象基类。
创建所有聚合根的基类 DomainEventAwareAggregate 如下:
public abstract class DomainEventAwareAggregate {
@JsonIgnore
private final List<DomainEvent> events = newArrayList();
protected void raiseEvent(DomainEvent event) {
this.events.add(event);
}
void clearEvents() {
this.events.clear();
}
List<DomainEvent> getEvents() {
return Collections.unmodifiableList(events);
}
}
这里的 raiseEvent() 方法用于在具体的聚合根对象中产生领域事件,然后在Repository中获取到事件,与聚合根对象一起完成持久化,创建 DomainEventAwareRepository 基类如下:
public abstract class DomainEventAwareRepository<AR extends DomainEventAwareAggregate> {
@Autowired
private DomainEventDao eventDao;
public void save(AR aggregate) {
eventDao.insert(aggregate.getEvents());
aggregate.clearEvents();
doSave(aggregate);
}
protected abstract void doSave(AR aggregate);
}
具体的聚合根在实现业务逻辑之后调用 raiseEvent() 方法生成事件,以“更改Order收货地址”业务过程为例:
public class Order extends DomainEventAwareAggregate {
//......
public void changeAddressDetail(String detail) {
if (this.status == PAID) {
throw new OrderCannotBeModifiedException(this.id);
}
this.address = this.address.changeDetailTo(detail);
raiseEvent(new OrderAddressChangedEvent(getId().toString(), detail, address.getDetail()));
}
//......
}
在保存Order的时候,只需要处理Order自身的持久化即可,事件的持久化已经在 DomainEventAwareRepository 基类中完成:
@Component
public class OrderRepository extends DomainEventAwareRepository<Order> {
//......
@Override
protected void doSave(Order order) {
String sql = "INSERT INTO ORDERS (ID, JSON_CONTENT) VALUES (:id, :json) " +
"ON DUPLICATE KEY UPDATE JSON_CONTENT=:json;";
Map<String, String> paramMap = of("id", order.getId().toString(), "json", objectMapper.writeValueAsString(order));
jdbcTemplate.update(sql, paramMap);
}
//......
}
当业务操作的事务完成之后,需要通知消息发送设施即时发布事件到消息队列。发布过程最好做成异步的后台操作,这样不会影响业务处理的正常返回,也不会影响业务处理的效率。在Spring Boot项目中,可以考虑采用AOP的方式,在HTTP的POST/PUT/PATCH/DELETE方法完成之后统一发布事件:
@Aspect
@Component
public class DomainEventPublishAspect {
//......
@After("@annotation(org.springframework.web.bind.annotation.PostMapping) || " +
"@annotation(org.springframework.web.bind.annotation.PutMapping) || " +
"@annotation(org.springframework.web.bind.annotation.PatchMapping) || " +
"@annotation(org.springframework.web.bind.annotation.DeleteMapping) ||")
public void publishEvents(JoinPoint joinPoint) {
logger.info("Trigger domain event publish process.");
taskExecutor.execute(() -> publisher.publish());
}
//......
}
以上,我们使用了TaskExecutor在后台开启新的线程完成事件发布,实际的发布由 RabbitDomainEventPublisher 完成:
@Component
public class DomainEventPublisher {
// ......
public void publish() {
Instant now = Instant.now();
LockConfiguration configuration = new LockConfiguration("domain-event-publisher", now.plusSeconds(10), now.plusSeconds(1));
distributedLockExecutor.execute(this::doPublish, configuration);
}
//......
}
这里,我们使用了分发布锁来处理并发发送的情况, doPublish() 方法将调用实际的消息队列(比如RabbitMQ/Kafka等)API完成消息发送。更多的代码细节,请参考本文的 示例代码 。
消费领域事件
在事件消费时,除了完成基本的消费逻辑外,我们需要重点关注以下两点:
- 消费方的幂等性
- 消费方有可能进一步产生事件
对于“消费方的幂等性”,在上文中我们讲到事件的发送机制保证的是“至少一次投递”,为了能够正确地处理重复消息,要求消费方是幂等的,即多次消费事件与单次消费该事件的效果相同。为此,在消费方创建一个事件记录表,用于记录已经消费过的事件,在处理事件时,首先检查该事件是否已经被消费过,如果是则不做任何消费处理。
对于第2点,我们依然沿用前文讲到的事件表的方式。事实上,无论是处理HTTP请求,还是作为消息的消费方,对于聚合根来讲都是无感知的,领域事件由聚合根产生进而由Repository持久化,这些过程都与具体的业务操作源头无关。
综上,在消费领域事件的过程中,程序需要更新业务表、事件记录表以及事件发送表,这3个操作过程属于同一个本地事务,此时整个事件的发布和消费过程如下:
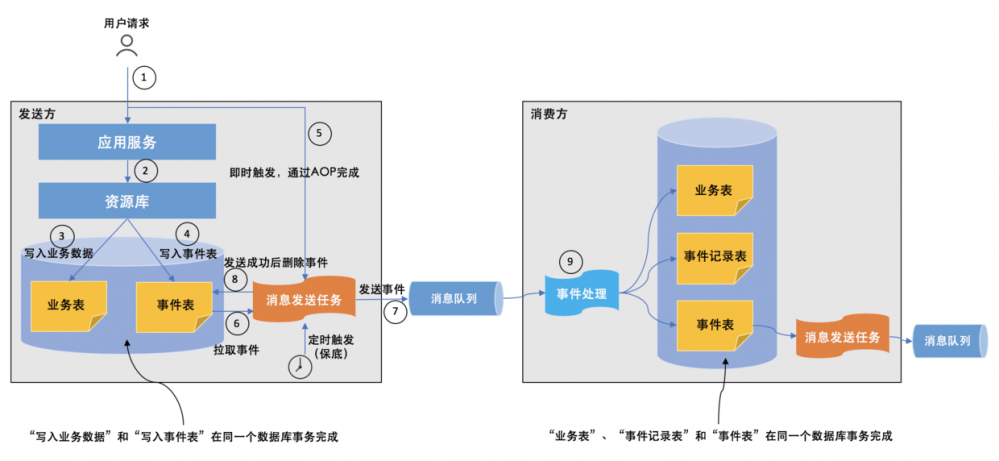
在编码实践时,可以考虑与事件发布过程相同的AOP方式完成对事件的记录,以Spring和RabbitMQ为例,可以将 @RabbitListener 通过AOP代理起来:
@Aspect
@Component
public class DomainEventRecordingConsumerAspect {
//......
@Around("@annotation(org.springframework.amqp.rabbit.annotation.RabbitHandler) || " +
"@annotation(org.springframework.amqp.rabbit.annotation.RabbitListener)")
public Object recordEvents(ProceedingJoinPoint joinPoint) throws Throwable {
return domainEventRecordingConsumer.recordAndConsume(joinPoint);
}
//......
}
然后在代理过程中通过 DomainEventRecordingConsumer 完成事件的记录:
@Component
public class DomainEventRecordingConsumer {
//......
@Transactional
public Object recordAndConsume(ProceedingJoinPoint joinPoint) throws Throwable {
Object[] args = joinPoint.getArgs();
Optional<Object> optionalEvent = Arrays.stream(args)
.filter(o -> o instanceof DomainEvent)
.findFirst();
if (optionalEvent.isPresent()) {
DomainEvent event = (DomainEvent) optionalEvent.get();
try {
dao.recordEvent(event);
} catch (DuplicateKeyException dke) {
logger.warn("Duplicated {} skipped.", event);
return null;
}
return joinPoint.proceed();
}
return joinPoint.proceed();
}
//......
}
这里的 DomainEventRecordingConsumer 通过直接向事件记录表中插入事件的方式来判断消息是否重复,如果发生重复主键异常 DuplicateKeyException ,即表示该事件已经在记录表中存在了,因此直接 return null; 而不再执行业务过程。
需要特别注意的一点是,这里的封装方法 recordAndConsume() 需要打上 @Transactional 注解,这样才能保证对事件的记录和业务处理在同一个事务中完成。
此外,由于消费完毕后也需要即时发送事件,因此需要在发布事件的AOP配置 DomainEventPublishAspect 中加入 @RabbitListener :
@Aspect
@Component
public class DomainEventPublishAspect {
//......
@After("@annotation(org.springframework.web.bind.annotation.PostMapping) || " +
"@annotation(org.springframework.web.bind.annotation.PutMapping) || " +
"@annotation(org.springframework.web.bind.annotation.PatchMapping) || " +
"@annotation(org.springframework.web.bind.annotation.DeleteMapping) ||" +
"@annotation(org.springframework.amqp.rabbit.annotation.RabbitListener) ||")
public void publishEvents(JoinPoint joinPoint) {
logger.info("Trigger domain event publish process.");
taskExecutor.execute(() -> publisher.publish());
}
//......
}
事件驱动架构的2种风格
事件驱动架构存在多种风格,本文就其中的2种主要风格展开讨论,它们是:
- 事件通知
- 事件携带状态转移(Event-Carried State Transfer)
在“事件通知”风格中,事件只是作为一种信号传递到消费方,消费方需要的数据需要额外API请求从源事件系统获取,如图:
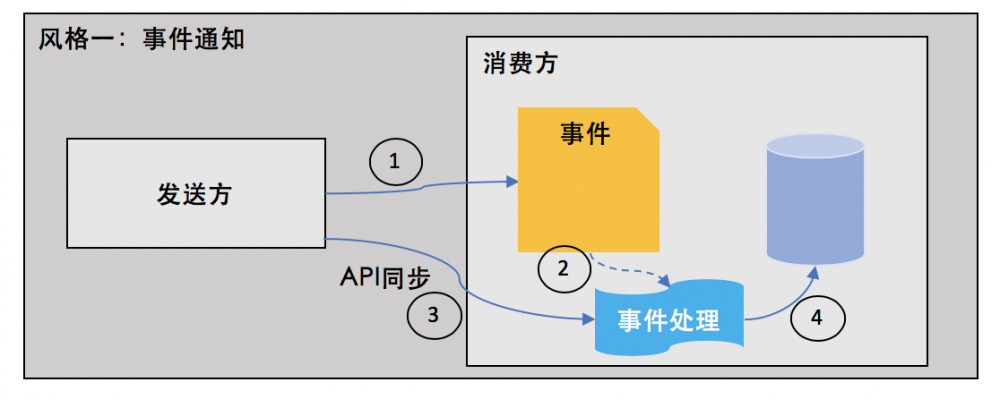
在上图的事件通知风格中,对事件的处理流程如下:
1. 发布方发布事件
2. 消费方接收事件并处理
3. 消费方调用发布方的API以获取事件相关数据
4. 消费方更新自身状态
这种风格的好处是,事件可以设计得非常简单,通常只需要携带聚合根的ID即可,由此进一步降低了事件驱动系统中的耦合度。然而,消费方需要的数据依然需要额外的API调用从发布方获取,这又从另一个角度增加了系统之间的耦合性。此外,如果源系统宕机,消费方也无法完成后续操作,因此可用性会受到影响。
在“事件携带状态转移”中,消费方所需要的数据直接从事件中获取,因此不需要额外的API请求:
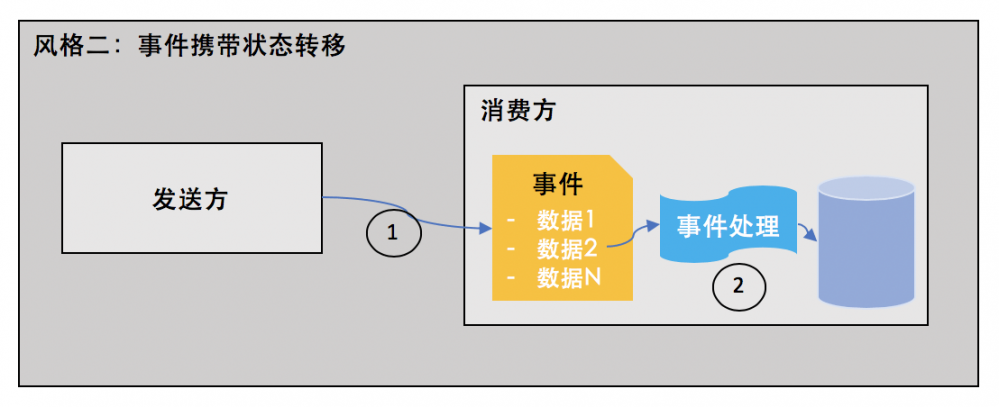
这种风格的好处在于,即便发布方系统不可用,消费方依然可以完成对事件的处理。
笔者的建议是,对于发布方来说,作为一种数据提供者的“自我修养”,事件应该包含足够多的上下文数据,而对于消费方来讲,可以根据自身的实际情况确定具体采用哪种风格。在同一个系统中,同时采用2种风格是可以接受的。比如,对于基于事件的CQRS而言,可以采用“事件通知”,此时的事件只是一个“触发器”,一个聚合下的所有事件所触发的结果是一样的,即都是告知消费方需要从源系统中同步数据,因此此时的消费方可以对聚合下的所有事件一并处理,而不用为每一种事件单独开发处理逻辑。
事实上,事件驱动还存在第3种风格,即事件溯源,本文不对此展开讨论。更多有关事件驱动架构不同风格的介绍,请参考 Martin Fowler的“事件风格”文章 。
第二部分:基于RabbitMQ的示例项目
在本部分中,我将以一个简单的电商平台微服务系统为例,采用RabbitMQ作为消息机制讲解事件驱动架构落地的全过程。
该电商系统包含3个微服务,分别是:
– 订单(Order)服务:用于用户下单
– 产品(Product)服务:用于管理/展示产品信息
– 库存(Inventory)服务:用于管理产品对应的库存
整个系统 包含以下代码库:
| 代码库 | 用途 | 地址 |
|---|---|---|
| order-backend | Order服务 | https://github.com/e-commerce-sample/order-backend |
| product-backend | Product服务 | https://github.com/e-commerce-sample/product-backend |
| inventory-backend | Inventory服务 | https://github.com/e-commerce-sample/inventory-backend |
| common | 共享依赖包 | https://github.com/e-commerce-sample/common |
| devops | 基础设施 | https://github.com/e-commerce-sample/devops |
其中, common 代码库包含了所有服务所共享的代码和配置,包括所有服务中的所有事件(请注意,这种做法只是笔者为了编码上的便利,并不是一种好的实践,一种更好的实践是各个服务各自管理自身产生的事件),以及RabbitMQ的通用配置(即每个服务都采用相同的方式配置RabbitMQ设施),同时也包含了异常处理和分布式锁等配置。 devops 库中包含了RabbitMQ的Docker镜像,用于在本地测试。
整个系统中涉及到的领域事件如下:
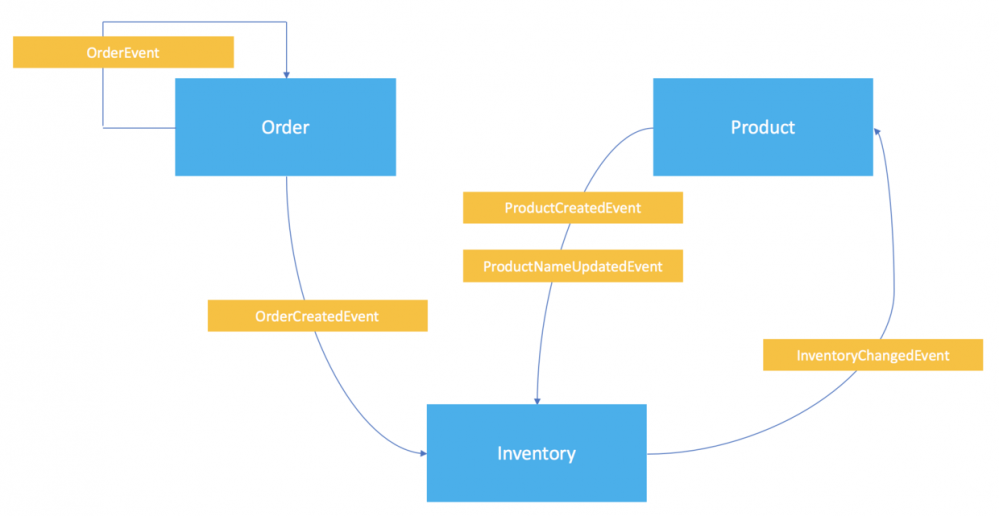
其中:
- Order服务自己消费了自己产生的所有
OrderEvent用于CQRS同步读写模型; - Inventory服务消费了Order服务的
OrderCreatedEvent事件,用于在下单之后即时扣减库存; - Inventory服务消费了Product服务的
ProductCreatedEvent和ProductNameChangedEvent事件,用于同步产品信息; - Product服务消费了Inventory服务的
InventoryChangedEvent用于更新产品库存。
####配置RabbitMQ
阅读本小节需要熟悉RabbitMQ中的基本概念,建议不熟悉RabbitMQ的读者事先参考 RabbitMQ入门文章 。
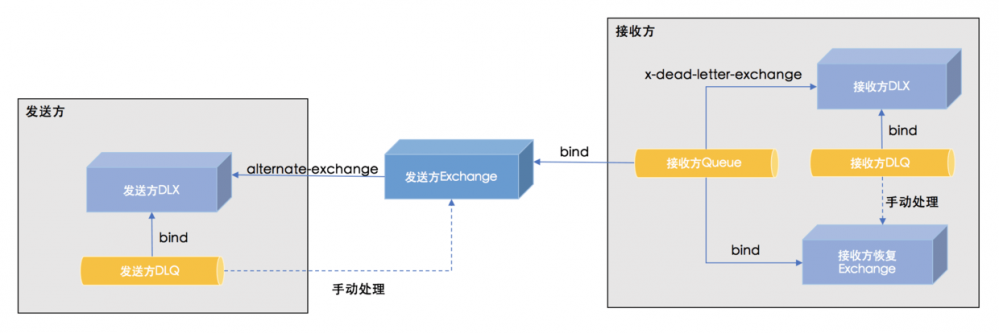
这里介绍2种RabbitMQ的配置方式,一种简单的,一种稍微复杂的。两种配置过程中会反复使用到以下概念,读者可以先行熟悉:
| 概念 | 类型 | 解释 | 命名 | 示例 |
|---|---|---|---|---|
| 发送方Exchange | Exchange | 用于接收某个微服务中所有消息的Exchange,一个服务只有一个 发送方Exchange |
xxx-publish-x | order-publish-x |
| 发送方DLX | Exchange | 用于接收发送方无法路由的消息 | xxx-publish-dlx | order-publish-dlx |
| 发送方DLQ | Queue | 用于存放 发送方DLX 的消息 |
xxx-publish-dlq | order-publish-dlq |
| 接收方Queue | Queue | 用于接收 发送方Exchange 的消息,一个服务只有一个 接收方Queue 用于接收所有外部消息 |
xxx-receive-q | product-receive-q |
| 接收方DLX | Exchange | 死信Exchange,用于接收消费失败的消息 | xxx-receive-dlx | product-receive-dlx |
| 接收方DLQ | Queue | 死信队列,用于存放 接收方DLX 的消息 |
xxx-receive-dlq | product-receive-dlq |
| 接收方恢复Exchange | Exchange | 用于接收从 接收方DLQ 中手动恢复的消息, 接收方Queue 应该绑定到 接收方恢复Exchange |
xxx-receive-recover-x | product-receive-recover-x |
在简单配置方式下,消息流向图如下:
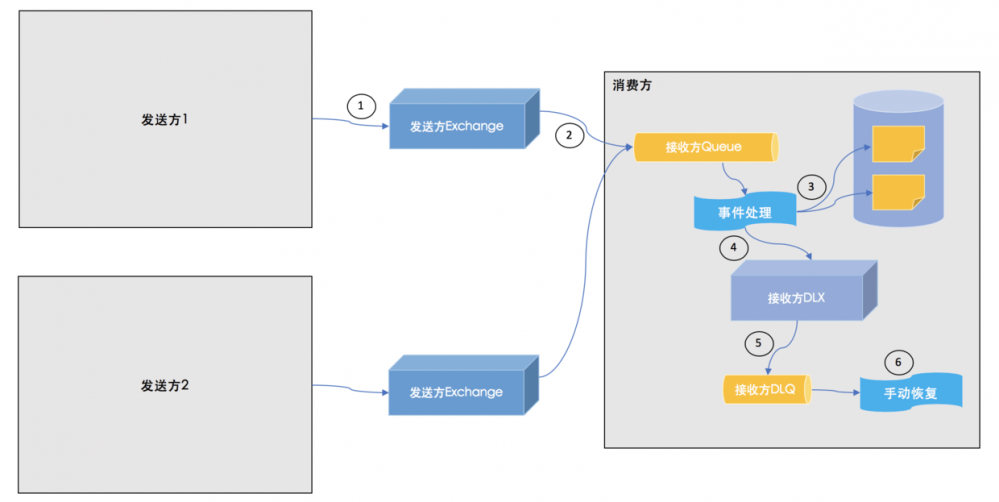
发送方Exchange 接收方Queue 接收方DLX 接收方DLQ
对于发送方而言,事件驱动架构提倡的是“发送后不管”机制,即发送方只需要保证事件成功发送即可,而不用关心是谁消费了该事件。因此在配置发送方的RabbitMQ时,可以简单到只配置一个 发送方Exchange 即可,该Exchange用于接收某个微服务中所有类型的事件。在消费方,首先配置一个 接收方Queue 用于接收来自所有 发送方Exchange 的所有类型的事件,除此之外对于消费失败的事件,需要发送到 接收方DLX ,进而发送到 接收方DLQ 中,对于 接收方DLQ 的事件,采用手动处理的形式恢复消费。
在简单方式下的RabbitMQ配置如下:
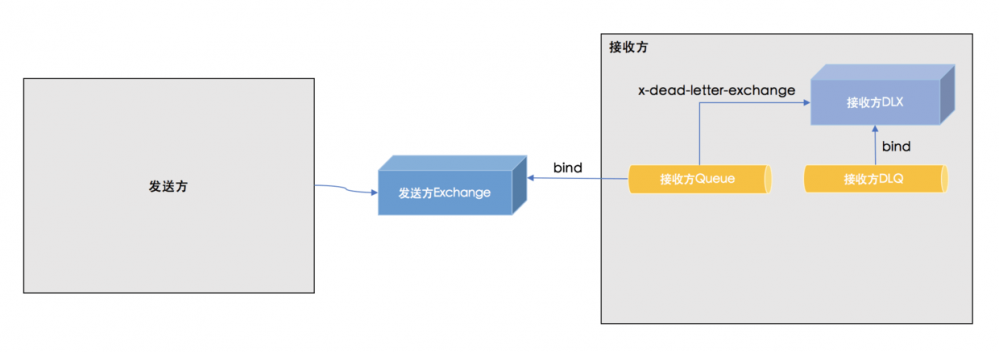
在第2种配置方式稍微复杂一点,其建立在第1种基础之上,增加了发送方的死信机制以及消费方用于恢复消费的Exchange,此时的消息流向如下:
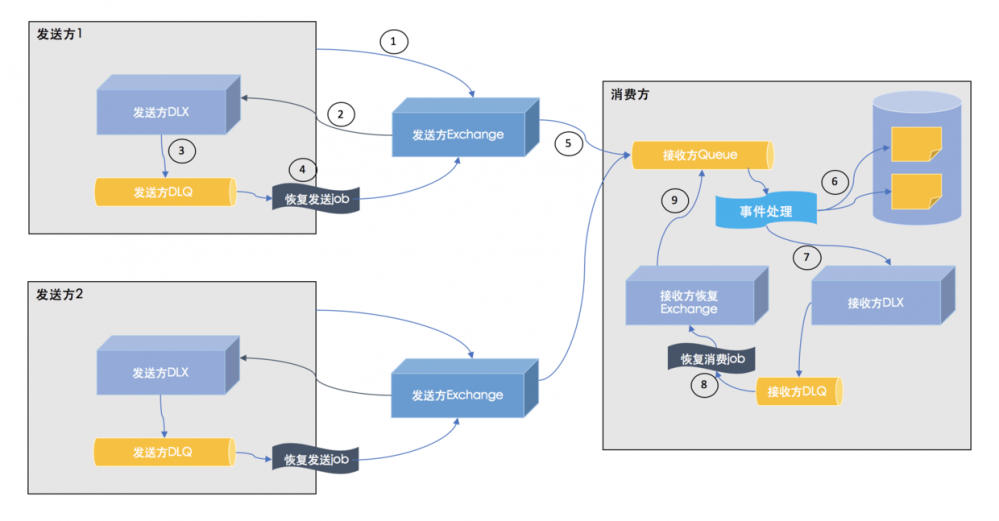
- 发送方发布事件
- 事件发布失败时被放入死信Exchange
发送方DLX - 消息到达死信队列
发送方DLQ - 对于
发送方DLQ中的消息进行人工处理,重新发送 - 如果事件发布正常,则会到达
接收方Queue - 正常处理事件,更新本地数据库
- 事件处理失败时,发到
接收方DLX,进而路由到接收方DLQ - 手工处理死信消息,将其发到
接收方恢复Exchange,进而重新发到接收方Queue
此时的RabbitMQ配置如下:
在以上2种方式中,我们都启用了RabbitMQ的“发送方确认”和“消费方确认”,另外,发送方确认也可以通过RabbitMQ的事务(不是分布式事务)替代,不过效率更低。更多关于RabbitMQ的知识,可以参考笔者的 Spring AMQP学习笔记 和 RabbitMQ最佳实践 。
系统演示
- 启动RabbitMQ,切换到
ecommerce-sample/devops/local/rabbitmq目录,运行:
./start-rabbitmq.sh
- 启动Order服务:切换到
ecommerce-sample/order-backend项目,运行:
./run.sh //监听8080端口,调试5005端口
- 启动Product服务:切换到
ecommerce-sample/product-backend项目,运行:
./run.sh //监听8082端口,调试5006端口
- 启动Inventory服务:切换到
ecommerce-sample/inventory-backend项目,运行:
./run.sh //监听8083端口,调试5007端口
- 创建Product:
curl -X POST /
http://localhost:8082/products /
-H 'Content-Type: application/json' /
-H 'cache-control: no-cache' /
-d '{
"name":"好吃的苹果",
"description":"原生态的苹果",
"price": 10.0
}'
此时返回Product ID:
{"id":"3c11b3f6217f478fbdb486998b9b2fee"}
- 查看Product:
curl -X GET / http://localhost:8082/products/3c11b3f6217f478fbdb486998b9b2fee / -H 'cache-control: no-cache'
返回如下:
{
"id": {
"id": "3c11b3f6217f478fbdb486998b9b2fee"
},
"name": "好吃的苹果",
"price": 10,
"createdAt": 1564361781956,
"inventory": 0,
"description": "原生态的苹果"
}
可以看到,新创建的Product的库存( inventory )默认为0。
– 创建Product时,会创建ProductCreatedEvent,Inventory服务接收到该事件后会自动创建对应的Inventory,日志如下:
2019-07-29 08:56:22.276 -- INFO [taskExecutor-1] c.e.i.i.InventoryEventHandler : Created inventory[5e3298520019442b8a6d97724ab57d53] for product[3c11b3f6217f478fbdb486998b9b2fee].
- 增加Inventory为10:
curl -X POST /
http://localhost:8083/inventories/5e3298520019442b8a6d97724ab57d53/increase /
-H 'Content-Type: application/json' /
-H 'cache-control: no-cache' /
-d '{
"increaseNumber":10
}'
- 增加Inventory之后,会发送InventoryChangedEvent,Product服务接收到该事件后会自动同步自己的库存,再次查看Product:
curl -X GET / http://localhost:8082/products/3c11b3f6217f478fbdb486998b9b2fee / -H 'cache-control: no-cache'
返回如下:
{
"id": {
"id": "3c11b3f6217f478fbdb486998b9b2fee"
},
"name": "好吃的苹果",
"price": 10,
"createdAt": 1564361781956,
"inventory": 10,
"description": "原生态的苹果"
}
可以看到,Product的库存已经更新为10。
- 至此,Product和Inventory都准备好了,让我们下单吧:
curl -X POST /
http://localhost:8080/orders /
-H 'Content-Type: application/json' /
-H 'cache-control: no-cache' /
-d '{
"items": [
{
"productId": "3c11b3f6217f478fbdb486998b9b2fee",
"count": 2,
"itemPrice": 10
}
],
"address": {
"province": "四川",
"city": "成都",
"detail": "天府软件园1号"
}
}'
返回Order ID:
{
"id": "d764407855d74ff0b5bb75250483229f"
}
- 创建订单之后,会发送OrderCreatedEvent,Inventory服务接收到该事件会自动扣减相应库存:
2019-07-29 09:11:31.202 -- INFO [taskExecutor-1] c.e.i.i.InventoryEventHandler : Inventory[5e3298520019442b8a6d97724ab57d53] decreased to 8 due to order[d764407855d74ff0b5bb75250483229f] creation.
同时,Inventory将发送InventoryChangedEvent,Product服务接收到该事件会自动更新Product的库存,再次查看Product:
curl -X GET / http://localhost:8082/products/3c11b3f6217f478fbdb486998b9b2fee / -H 'cache-control: no-cache'
返回如下:
{
"id": {
"id": "3c11b3f6217f478fbdb486998b9b2fee"
},
"name": "好吃的苹果",
"price": 10,
"createdAt": 1564361781956,
"inventory": 8,
"description": "原生态的苹果"
}
可以看到,Product的库存从10减少到了8,因为先前下单时我们选了2个Product。
##总结
本文首先独立于消息队列的技术实现,讲到了事件驱动架构在落地过程中的诸多方面以及问题,包括领域事件的建模、通过聚合根暂存事件然后由Repository完成存储,再由后台任务读取事件表完成事件的实际发布。在消费方,通过幂等性解决在“至少一次投递”的情况下所带来的重复消费问题。另外,还讲到了事件驱动架构的2种常见风格,即事件通知和事件携带状态转移,以及他们之间的优劣势。在第二部分,以RabbitMQ为例,分享了如何在一个微服务化的系统中落地事件驱动架构。
正文到此结束
- 本文标签: 产品 IDE App value Architect cache 希望 分布式锁 2019 update https 线程 数据 CEO key 苹果 删除 mapper 十年 一致性 并发 spring git 数据库 调试 时间 Collections 总结 http Service mmap 模型 stream 目录 ip description UI 代码 分布式事务 final ask Action MQ rabbitmq 微服务 mysql db find 配置 GitHub 消息队列 锁 src queue AOP 分布式 幂等 端口 tar map API Docker 开发 dist trigger Collection Spring Boot JDBC tab sql 管理 json 软件 同步 自我修养 IO 幂等性 ArrayList 测试 cat NSA DOM list consumer 文章 executor id amqp web js
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

