蚂蚁金服在云原生架构下的可观察性的探索和实践 | Meetup#3 回顾
作者:苟利(陈自欣),蚂蚁金服中间件产品专家, 负责蚂蚁金服分布式链路跟踪系统的产品化工作,在日志分析、监控领域有多年工作经验。
本文根据 8 月 11 日 SOFA Meetup#3 广州站 《蚂蚁金服在云原生架构下的可观察性的探索和实践》主题分享整理。现场回顾视频以及 PPT 查看地址见文末链接。
前言
随着应用架构往云原生的方向发展,传统监控技术已经不能满足云原生时代运维的需求,因此,可观察性的理念被引入了 IT 领域。
下面我将会就可观察性在云原生的起源,可观察性发展动力, 可观察性与监控的关系,可观察性的三大支柱,社区发展方向及产品现状,以及蚂蚁金服对相关问题的理解及实践进行探讨。
才疏学浅,欢迎拍砖。
为什么云原生时代需要可观察性
可观察性的由来
在云原生语境下的可观察性这个词,最早出现于2017年7月, Cindy Sridharan 在 Medium 写的一篇博客, “ Monitoring and Observability “,谈到了可观察性与云原生监控的关系。
而在2017年10月, 来自 Pivotal 公司的 Matt Stine,在接受 InfoQ 采访的时候,对云原生的定义进行了调整, 将Cloud Native Architectures 定义为具有以下六个特质:
- 模块化 (Modularity) (通过微服务)
- 可观察性 (Observability)
- 可部署性 (Deployability)
- 可测试性 (Testability)
- 可处理性 (Disposability)
- 可替换性 (Replaceability)
可见,在2017年下半年, 可观察性成为了一个 buzzword(时髦词) ,正式出现在了云计算领域。
可观察性的定义
虽然“可观察性”这个词在 IT 行业是一个新的术语,但它其实是在上世纪60年代,由 匈牙利裔工程师鲁道夫·卡尔曼提出的概念 。
术语“可观察性”,源于控制论,是指系统可以由其外部输出推断其内部状态的程度。
这个外部输出, 在云原生的语境下,即 Telemetry ,遥测,通常由服务(services)产生,划分为三个维度或者说支柱, Tracing(跟踪),Metrics(指标) , Logging(日志)。
为什么云原生需要可观察性
近年可以看到,云计算对基础架构改变甚为巨大,无论是互联网行业,还是传统行业,云化在提升资源利用率,提高业务敏捷性的价值已经成为了公式。而在应用层面,由于业务特性的原因,互联网公司大部分已经完成云化,应用架构也不同程度上,完成了从单体应用向微服务应用演进。 在转型后,整体系统复杂性大大增加,倒逼相应的工具及方法论进行升级改造, 去 hold 住这么复杂的局面。

上图为 Uber 展示的总体调用链图。考虑到业务多样性及复杂度,在蚂蚁金服内部,相关调用关系只会更为复杂,用人类的智力,已经没有办法去理解如此复杂的调用关系。而上图只是展示了可观察性的链路调用, 如果再加上指标及日志, 不对工具及方法论进行革新, 是难以实现对复杂微服务架构的管控的。
微服务只是云原生的模块化特性的体现, 再考虑到近年被广泛应用容器,Kubernetes , 以及大家关注度极高的 Service Mesh , Istio, 每一个新的技术的出现,在带来了更优雅的架构、更灵活的调度、更完善的治理的同时,也带来更多新的复杂性。
因此,可观察性对于云原生的应用架构,是必不可少的特性。
可观察性和传统监控的区别
说半天,不少同学就会说,这个可观察性与我们谈的最多的监控有什么区别。 虽然有不少的人认为, 这词就是个buzzword,就是赶时髦的,没有太大的意义, 但是我结合网上的讨论, 个人认为可观察性与监控, 含义上虽然接近,但是也有一些理念上的差别,使得讨论可观察性这个词,是有具有现实意义,并能真正产生相应的价值。
- 监控更多关注的是基础设施,更多与运维工程师相关,更强调是从外部通过各种技术手段去看内部,打开黑盒系统。
- 可观察性更多的是描述应用,在我们谈论具体某应用,或者是某些应用是否具备客观性的时候,通常与开发人员相关,因为在常见的可观察性的实践之中,开发人员需要在应用的开发过程中嵌入例如 statd 或者是 opentracing,或者是 opencensus 等所提供的库,对相关的 telemetry 进行输出,或者是俗话说的埋点。通过埋点,将服务内部的状态白盒化,使得其在运维阶段具备可观察性。某种程度上可以说,可观察性遵循了 DevOps 及 SRE 的理念,即研发运维一体化,从开发侧就考虑系统的可运维性。
这里值得补充说明的是,目前市面上,有商用或者开源APM 方案,通过入侵 JVM 或者其他技术手段,对应用进行自动埋点的,输出 trace 及 metrics 信息。 这同样也是一种可观察性的实现方式,这样做的最大的好处是,不需要对现有的应用进行改造,但是相应的 agent 对应用进行实时的监控, 必然会或多或少的增加资源的占用,例如每实例额外 30+MB 内存,5~10% 的 CPU 占用,在大规模的运行环境之中, 会有不少的成本增加。
可观察性的三大支柱及社区进展
可观察性的三大支柱

可观察性的三大支柱及其之间的关系, Peter Bourgon 在2017年2月撰写了一篇简明扼要的文章, 叫 “ Metrics, tracing, and logging ” , 有兴趣的可以去看一下, 以下仅为简单的提及。
指标数据(Metrics Data)
描述具体某个对象某个时间点的值。在 Prometheus 中, 指标有四种类型,分别 Counter(计数器)、Gauge(瞬时值)、Histogram(直方图)和 Summary (概要), 通过这四种类型,可以实现指标的高效传输和存储。
日志数据 ( Logging Data)
描述某个对象的是离散的事情,例如有个应用出错,抛出了 NullPointerExcepction,或者是完成了一笔转账,个人认为 Logging Data 大约等同于 Event Data,所以告警信息在我认为,也是一种 Logging Data。 但是也有技术团队认为,告警应该算是可观察性的其中一个支柱。
跟踪数据(Tracing Data)
Tracing Data 这词貌似现在还没有一个权威的翻译范式,有人翻译成跟踪数据,有人翻译成调用数据,我尽量用Tracing 这个词。 Tracing 的特点就是在单次请求的范围内处理信息,任何的数据、元数据信息都被绑定到系统中的单个事务上。 一个Trace 有一个唯一的Trace ID ,并由多个Span 组成。
社区方案进展
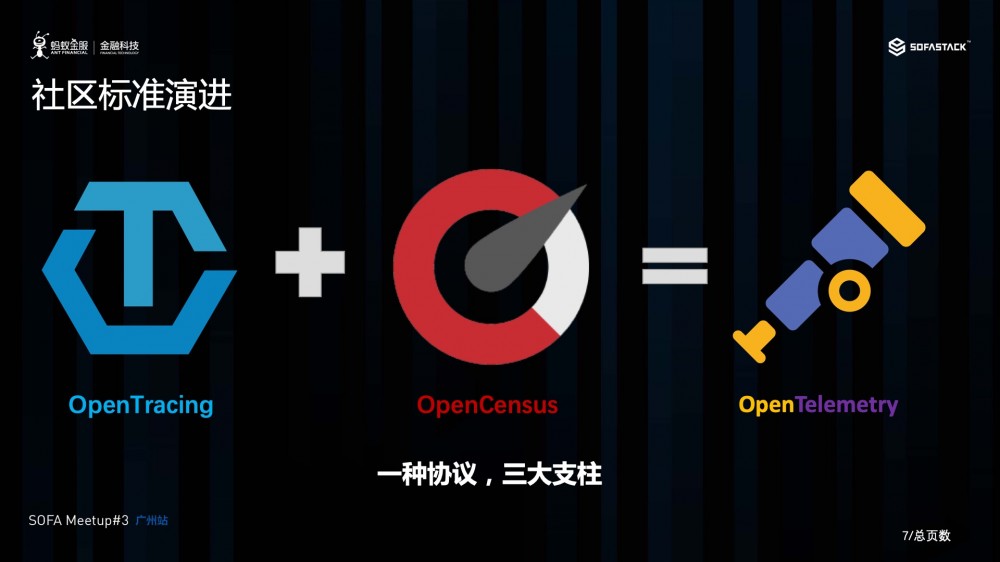
由于可观察性在云原生中,是一个非常重要的特性, 因此,在开源世界中,先后出现了两个定位都比较类似的项目,分别是源自 Google 的 OpenCensus (定位上报 Tracing + metris) 和由 CNCF 孵化的 OpenTracing(定位上报 Tracing)。 两者都定位于提供厂商中立的技术规范,及实现该规范各种编程语言遥测库,使得用户在使用了相关的库以后,可以将相关的遥测数据, 发往不同厂商的后端, 如 Zipkin , SignalFX,Datdog 等,从而促进云原生的可观察的良性发展。
由于两个项目的定位高度雷同, 因此在2019年3月,两个项目社区的主要领导者,决定将两个项目进行融合,产生一个同时向下兼容 OpenCensus 及 OpenTracing 的项目,叫 Open Telemetry,将多个标准,降低为一个。
OpenTelemetry 旨在将可观察性的三大支柱,组合成一组系统组件和特定于语言的遥测库。 项目在最初并不会支持日志,但最终会将其合并。 这个事情比较好理解,因为日志数据量太大, 也缺乏相应的初始规范, 社区选择在时机成熟时再进行引入是一个很合理的策略。
简单来说,以后你在应用开发里头, 只要使用了 Open Telemetry的类库进行埋点, 则应用就可以通过一个协议, 统一上传指标, 跟踪,日志,到不同厂商的后端, 进行后继的分析。
社区产品现状及局限
与协议层,日趋一统情况不一样,在产品层面,由于产品的侧重点不同, 呈现出了百花齐放的局面。

但是,从某种角度来看,目前社区的产品方案有以下的局限:
1、缺乏大一统的产品,同时对三个支柱进行支撑,并进行有机的关联
这个无需多言,只要使用过上述的产品,就会发现没有办法找到一个完整开源产品,能够对以上三种遥测进行同时处理。就更没有办法进行统一的关联了。
2、缺乏大一统的产品模型,统一展示微服务 + Mesh + Serverless
在不远的将来, 传统微服务, Mesh , Serverless 应用, 混合交互,构成业务系统, 将会是一个普遍的情况,但是目前开源的产品,并不具备对以上三种计算模型进行统一的,可识别的管理。
蚂蚁金服对云原生的可观察性的理解及实践
蚂蚁金服在多年的分布式系统的运维过程中,对可观察性有着自己深入的理解, 结合用户的特点,将其进行产品化及解决方案,并提供给金融用户。

链路跟踪是可观察性的核心,用于故障定位
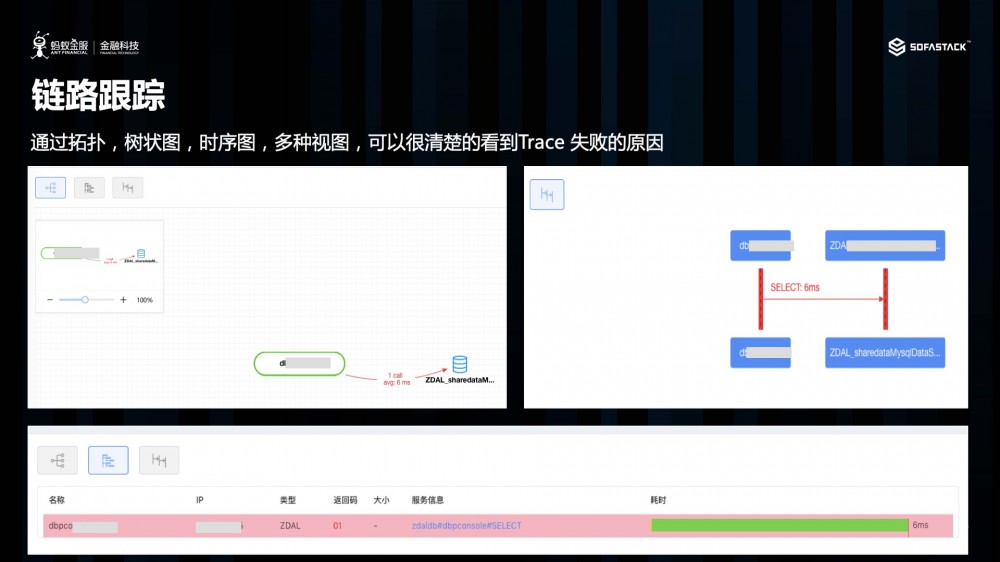
在微服务及分布式架构中, 链路跟踪是用户的核心使用诉求,这里大家都应该比较熟悉了,我也不多做展开。
Tracing + metirce + Log 有机关联是实现可观察性的关键
链路与日志关联

链路与 日志关联 是一个很重要的场景。 在很多时候,某一个调用失败, 失败的原因,并不能体现在 Trace 之上, 也许是发生在业务侧,例如余额不对, 导致整个调用的失败。 因此,很多时候,我们需要将链路和日志关联,帮助我们更好的判断到底是什么原因,导致链路调用失败,或者是进行进行其他分析。
为此,我们提供了一个 SDK ,用户可以根据我们官网上的配置, 对 log4j 及其他 logger进行配置后, 将 TraceId 及 RPCId 从 Tracer 中进行获取, 那么在打印的日志的时候,TraceId , RPCId 也会如图上所, 在日志中打印出来。 最后, 然后通过 Trace view , 我就能在查看链路的同时,查看关联的日志。
具体的配置方式或者原理,感兴趣的同学, 可以查看 蚂蚁金服金融科技官网 。
拓扑与指标关联

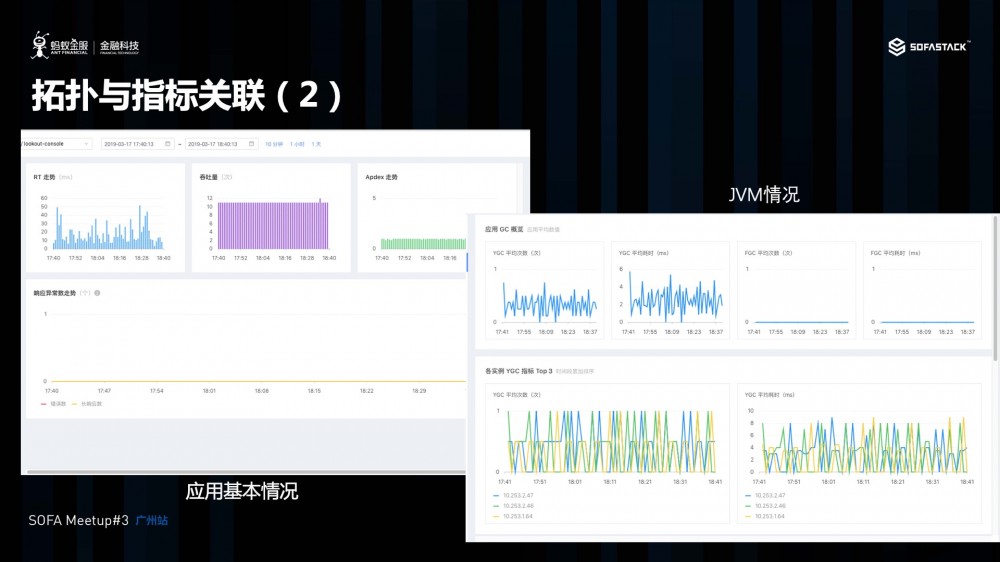
除了链路与日志关联, 我们 SOFA 还提供了应用指标的上传功能, 在应用上传 Trace 的同时, 我们将指标与调用拓扑进行了关联, 用户可以点击应用拓扑中的应用,下转查看响应的拓扑指标。
按照固定采样率进行采样不能满足实践使用需求

有 Tracing 相关产品使用经验的同学都知道,在业务量大的时候, 相关的 Tracing 产生的数据量会较多, 导致存储成本以及处理成本的大幅度增加。在实际的生产中, 我们往往会对 Tracing 进行采样,通常会采用 1 ⁄ 100 甚至是1/1000 的方式进行采样。
具体的采样方式,通常采用 Head-based 采样,即,对 TraceId 进行以 100 或者 1000 来采模,采模后如果是 1 ,则 agent 对该 TraceId 进行进行采集。是否对链路进行采集的决定,发生在链路的第一跳,即 TraceId 产生时,所以叫 Head-based 采样。
这种采样方法好处是实现非常简单,但问题是 100 个链路数据中,可能有 3-5 个是运维人员关心的,通常是调用出错的链路,又或者是调用缓慢的链路,通过这种简单粗暴的采样,能采集到相应链路的机会就会很少。大部分情况下, 用户只能期望异常多次发生,并在某次被采样命中,然后进行分析。
目前,开源软件中,采用的都是这种方案。
我们在蚂蚁金服内部,使用的是 Tail-based 的采样方案,简单来说,我们会把所有的 Span 数据,都会放到内存里, 但这个时候,并不能决定具体那一条链路是采集还是不采集,但是当整条链路闭合后,我们就会对整条的 Trace 根据规则进行判断, 如果有调用失败,或者整个调用中有部分 Span 是处于缓慢状态的,系统会将会标记此链路为异常链路,即命中采样,永久保存。这样就能保证运维人员能够无视采样率,具备对异常链路进行查看能力。由于对某一条链路数据是否采集的决定,其实是处于链路的尾部(非严格意义)才作出的,所以叫 Tail-based 采样。
当然以上 Tail-based 的采样的描述是极其简单及理想化的, 在海量数据量的情况下,以上的方法基本上没有办法使用,很容易就把内存给撑爆了。在实际设计中,我们还考虑了很多的因素, 进行了更多的细节处理, 使得 Tail-based 采样的资源消耗也在一个可以接受的范围内。
目前这个功能在内部已经落地,对外还在产品化之中。
(想要了解上述更多技术细节,可以查看参考资料 [1] & [2] )
统一化 微服务 + Mesh + Serverless
未来,可以预期混合使用经典微服务、服务网格的企业必然越来越多。因此,如何设计一个通用的模型, 对以上三部分进行统一管控, 这也是蚂蚁金服目前正在实践探索的地方,期望外来有机会向大家分享。
未来展望
综上所述,随着云原生的发展, 我们相信拥有完整的可观察性三大支柱处理能力,并能在产品层面上对三大支柱进行灵活关联、下转、查看的监控产品,适用于混合的云原生场景的监控的产品,都将会越来越多,帮助企业内部落地云原生架构。
视频回顾
本次分享的视频回顾以及PPT 查看地址: https://tech.antfin.com/community/activities/779/review
参考资料
[1] https://news.ycombinator.com/item?id=15326272
[2] https://github.com/jaegertracing/jaeger/issues/425
正文到此结束
- 本文标签: 互联网 管理 软件 博客 应用架构 Agent 测试 匈牙利 领导 敏捷 http IO JVM 翻译 科技 数据 实例 src Service 工程师 协议 开源软件 Kubernetes 企业 Logging 模型 zip UI 时间 Uber 文章 分布式系统 云 https 金融 需求 Architect zipkin 2019 git 配置 GitHub 开源 ACE 分布式 部署 ip 产品 Google 开发 Word id 微服务 tab
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

