mybatis 源码分析(三)Executor 详解
本文将主要介绍 Executor 的整体结构和各子类的功能,并对比效率;
一、Executor 主体结构
1. 类结构
executor 的类结构如图所示:
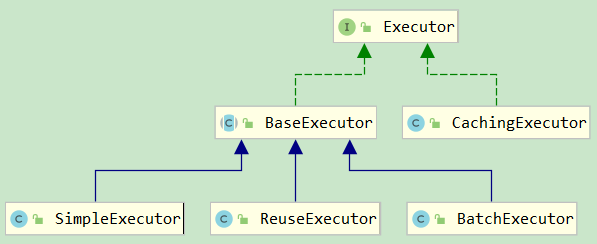
其各自的功能:
- BaseExecutor:基础执行器,封装了子类的公共方法,包括一级缓存、延迟加载、回滚、关闭等功能;
- SimpleExecutor:简单执行器,每执行一条 sql,都会打开一个 Statement,执行完成后关闭;
- ReuseExecutor:重用执行器,相较于 SimpleExecutor 多了 Statement 的缓存功能,其内部维护一个
Map<String, Statement>,每次编译完成的 Statement 都会进行缓存,不会关闭; - BatchExecutor:批量执行器,基于 JDBC 的
addBatch、executeBatch功能,并且在当前 sql 和上一条 sql 完全一样的时候,重用 Statement,在调用doFlushStatements的时候,将数据刷新到数据库; - CachingExecutor:缓存执行器,装饰器模式,在开启二级缓存的时候。会在上面三种执行器的外面包上 CachingExecutor;
2. Executor 的生命周期
初始化:
// DefaultSqlSessionFactory
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
关闭:
public void close() {
try {
executor.close(isCommitOrRollbackRequired(false));
dirty = false;
} finally {
ErrorContext.instance().reset();
}
}
所以 Executor 的生命周期和 SqlSession 是一样的,之所以要明确的指出这一点是因为 Executor 中包含了缓存的处理,并且因为 SqlSession 是线程不安全的,所以在使用 Executor 一级缓存的时候,就很容易发生脏读;后面还会通过具体示例演示;
3. query 方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter); //获取绑定的sql
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); // hash(mappedStementId + offset + limit + sql + queryParams + environment)
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) { throw new ExecutorException("Executor was closed."); }
// 查询的时候一般不清楚缓存,但是可以通过 xml配置或者注解强制清除,queryStack == 0 是为了防止递归调用
if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); }
List<E> list;
try {
queryStack++;
// 首先查看一级缓存
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 没有查到的时候直接到数据库查找
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
// 延迟加载队列
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// 一级缓存本身不能关闭,但是可以设置作用范围 STATEMENT,每次都清除缓存
clearLocalCache();
}
}
return list;
}
4. update 方法
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// update|insert|delete 方法首先会清除一级缓存
clearLocalCache();
return doUpdate(ms, parameter);
}
5. 模版方法
protected abstract int doUpdate(MappedStatement ms, Object parameter)
throws SQLException;
protected abstract List<BatchResult> doFlushStatements(boolean isRollback)
throws SQLException;
//query-->queryFromDatabase-->doQuery
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
这里就是一个典型的模版模式了,子类都会实现自己模版方法;
二、BaseExecutor 子类
1. SimpleExecutor
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
从上面的代码也可以看到 SimpleExecutor 非常的简单,每次打开一个 Statement,使用完成以后关闭;
2. ReuseExecutor
private final Map<String, Statement> statementMap = new HashMap<String, Statement>(); // Statement 缓存
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql(); // 获取绑定的sql
String sql = boundSql.getSql();
if (hasStatementFor(sql)) { // 如果缓存中已经有了,直接得到Statement
stmt = getStatement(sql);
} else { // 如果缓存没有,就编译一个然后加入缓存
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection);
putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
ReuseExecutor 就比 SimpleExecutor 多了一个 Statement 的缓存功能,其他的都是一样的;
3. BatchExecutor
首先需要明确一点 BachExecutor 是基于 JDBC 的 addBatch、executeBatch 功能的执行器,所以 BachExecutor 只能用于更新(insert|delete|update),不能用于查询(select),下面是一个 JDBC 的小 demo:
String url = "jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT";
String sql = "INSERT INTO user(username,password,address) VALUES (?,?,?)";
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.getConnection(url, "root", "root");
PreparedStatement stmt = conn.prepareStatement(sql);
for (int i = 0; i < 4000; i++) {
stmt.setString(1, "test" + i);
stmt.setString(2, "123456");
stmt.setString(3, "test");
stmt.addBatch();
}
stmt.executeBatch();
下面从源码来看一下 mybatis 是如何实现的:
private final List<Statement> statementList = new ArrayList<Statement>(); // 待处理的 Statement
private final List<BatchResult> batchResultList = new ArrayList<BatchResult>(); // 对应的结果集
private String currentSql; // 上一次执行 sql
private MappedStatement currentStatement; // 上次执行的 MappedStatement
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql(); // 本次执行的 sql
final Statement stmt;
// 当本次执行的 sql 和 MappedStatement 与上次的相同时,直接复用上一次的 Statement
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
int last = statementList.size() - 1;
stmt = statementList.get(last);
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
// 不同时,新建 Statement,并加入缓存
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection);
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
handler.parameterize(stmt);
handler.batch(stmt); // 添加批处理任务
return BATCH_UPDATE_RETURN_VALUE; // 注意这里返回的不再是更新的行数,而是一个常量
}
BatchExecutor 的批处理添加过程相当于添加了一个没有返回值的 异步任务 ,那么在什么时候执行异步任务,将数据更新到数据库呢,答案是处理 update 的任何操作,包括 select、commit、close等任何操作,具体执行的方法就是 doFlushStatements ;此外需要注意的是 Batch 方式是不能使用 useGeneratedKeys 返回主键的;
三、效率对比
几种执行器效率对比
| batch | Reuser | simple | foreach | foreach100 | |
|---|---|---|---|---|---|
| 100 | 369 | 148 | 151 | 68 | 70 |
| 1000 | 485 | 735 | 911 | 679 | 148 |
| 10000 | 2745 | 4064 | 4666 | 38607 | 1002 |
| 50000 | 8838 | 17788 | 19907 | 796444 | 3703 |
从上面的结果对比可以看到:
- 整体而言 reuser 比 simple 多了缓存功能,所以无论批处理的大小,其效率都要高一些;
- 此外在批处理量小的时候使用 foreach,效果还是可以的,但是当批量交大时,sql 编译的时间就大大增加了,当 foreach 固定批大小 + reuser 时,每次的 Statement 就可以重用,从表中也可以看到效率也时最高的;
- batch 的有点则时所有的更新语句都能用;
- 所以在配置的时候建议默认使用 reuser,而使用 foreach 和 batch 需要根据具体场景分析,如果更新比较多的时候,可以在批量更新的时候单独指定 ExecutorType.BATCH,如果批量插入很多的时候,可以固定批大小;
正文到此结束
- 本文标签: https 配置 App mybatis autocommit 一级缓存 Statement db map CTO REST Word 二级缓存 JDBC tab sql 时间 list 生命 executor equals 源码 安全 代码 value http cache ArrayList 编译 cat NSA key src StatementHandler session root 线程 IDE XML Connection sqlsession HashMap 递归 update 数据库 数据 Select dataSource SqlSessionFactory id GMT mysql UI HTML final Action IO 缓存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

