数据量太大?用数据库水平切分搞定!

本文将介绍数据库架构设计中的一些基本概念,常见问题以及对应解决方案,为了便于读者理解,将以 “用户中心” 为例,讲解数据库架构设计的常见玩法。

用户中心
用户中心是一个非常常见的业务,主要提供用户注册、登录、信息查询与修改的服务,其核心元数据为:
User(uid, uname, passwd, sex, age, nickname, …)
其中:
-
uid为用户ID,主键。
-
uname, passwd, sex, age, nickname, …等为用户的属性。
数据库设计上,一般来说在业务初期,单库单表就能够搞定这个需求。
为了方便大家理解,后文图片说明如下:
-
“灰色”方框,表示service,服务。
-
“紫色”圆框,标识master,主库。
-
“粉色”圆框,表示slave,从库。

单库架构

最常见的架构设计如上:
-
user-service: 用户中心服务,对调用者提供友好的RPC接口。
-
user-db: 一个库进行数据存储。

分组架构
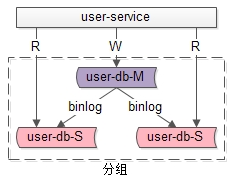
1. 分组架构究竟解决什么问题?
答:大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
-
线性提升数据库读性能。
-
通过消除读写锁冲突提升数据库写性能。
-
通过冗余从库实现数据的“读高可用”。
此时可以使用分组架构,需要注意的是, 分组架构中,数据库的主库依然是写单点 。

分片架构
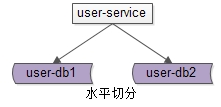
1. 分片架构究竟解决什么问题?
答:大部分互联网业务数据量很大,单库容量容易成为瓶颈,此时通过分片可以:
-
线性提升数据库写性能,需要注意的是,分组架构是不能线性提升数据库写性能的。
-
降低单库数据容量。
一句话总结,分片解决的是“数据库数据量大”问题,所实施的架构设计。

分组+分片架构
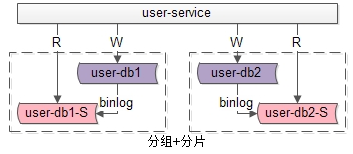
如果业务读写并发量很高,数据量也很大,通常需要实施分组+分片的数据库架构:
-
通过分片来降低单库的数据量,线性提升数据库的写性能。
-
通过分组来线性提升数据库的读性能,保证读库的高可用。

垂直切分
除了水平切分,垂直切分也是一类常见的数据库架构设计,垂直切分一般和业务结合比较紧密。
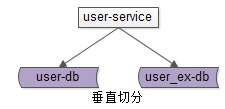
还是以用户中心为例,可以这么进行垂直切分:
User(uid, uname, passwd, sex, age, …)
User_EX(uid, intro, sign, …)
-
垂直切分开的表,主键都是uid。
-
登录名,密码,性别,年龄等属性放在一个垂直表(库)里。
-
自我介绍,个人签名等属性放在另一个垂直表(库)里。
1. 如何进行垂直切分?
答:根据业务对数据进行垂直切分时,一般要考虑属性的“长度”和“访问频度”两个因素:
-
长度较短,访问频度较高的放在一起。
-
长度较长,访问频度较低的放在一起。
这是因为,数据库会以行(row)为单位,将数load到内存(buffer)里,在内存容量有限的情况下,长度短且访问频度高的属性,内存能够load更多的数据,命中率会更高,磁盘IO会减少,数据库的性能会提升。

业务场景决定数据库架构
-
业务初期用单库。
-
读压力大,读高可用,用分组。
-
数据量大,写线性扩容,用分片。
-
属性短,访问频度高的属性,垂直拆分到一起。
本文以“用户中心”为例,对常见数据库架构设计进行了简要梳理与总结,但实际数据库架构设计远比此复杂, 特别是水平切分的架构设计,不同业务场景的切分方式不尽相同 。
感兴趣的可以订阅我的专栏,后续将要详细介绍,覆盖90%互联网业务特性的四类业务:
从《从“单KEY”类业务》中了解到:
-
水平切分方式
-
水平切分后碰到的问题
-
用户侧与运营侧架构设计思路
-
用户前台侧,“建立非uid属性到uid的映射关系”最佳实践
-
运营后台侧,“前台与后台分离”最佳实践
从《“1对多”类业务》这篇文章,能够了解到:
-
“1对多”类业务,在架构上,采用元数据与索引数据分离的架构设计方法;
-
对于元数据的存储,在数据量较大的情况下,有三种常见的切分方法。
从《“多对多”类业务》这篇文章,能够了解到:
-
好友业务是一个典型的多对多关系,又分为强好友与弱好友;
-
数据冗余是一个常见的多对多业务数据水平切分实践;
-
冗余数据的常见三种方案;
-
实现一致性要实践的常见三种方案。
从《“多KEY”类业务》这篇文章,能够了解到:
-
前台、后台系统web/service/db分离解耦,避免后台低效查询引发前台查询抖动。
-
采用前台与后台数据冗余的设计方式,分别满足两侧的需求。
-
采用“外置索引”(例如ES搜索系统)或者“大数据处理”(例如HIVE)来满足后台变态的查询需求。
扫码了解《搞定数据库水平切分》专栏详情
▼

这个专栏系统的展开描述了 “水平切分” 这一个话题,在数据库架构设计过程中,除了水平切分,至少还会遇到这样一些问题:
-
可用性: 不管是主库实例,还是从库实例,如果数据库实例挂了,如何不影响数据的读和写。
-
读性能: 互联网业务大多是读多写少的业务,如果提升数据库的读性能是架构设计中必须考虑的问题。
-
一致性: 数据一旦冗余,就可能出现一致性问题,如何解决主库与从库之间的不一致,如何解决数据库与缓存之间的不一致,也是需要重点设计的。
-
扩展性: 如何在不停服务的情况下扩充数据表的属性,实施数据迁移,实施存储引擎的切换,架构设计上都是十分有讲究的。
-
分布式SQL语句: 单库情况下,所有SQL语句的执行都没问题问题,一旦实施了水平切分,如何实现SQL的集函数,分页,非patition key上的查询都成了大问题。
上面这些问题,都不是简单三言两语能够说清楚的,大家对哪个话题感兴趣,欢迎订阅这个专栏。
本专栏作者——58沈剑: “架构师之路”公众号作者,58到家高级总监,技术委员会主席。前百度高工,58同城高级架构师,技委主席。
点击 阅读原文 ,订阅沈剑大佬的专栏。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

