美团点评技术专家孙佳林:万亿级实时全链路监控系统架构演进!

本文来源 高效运维(ID: greatops)
讲师简介
孙佳林
-
美团点评基础架构部

本文将围绕上述三个方面,来介绍美团点评万亿数据量下的实时监控平台CAT。
1. CAT介绍
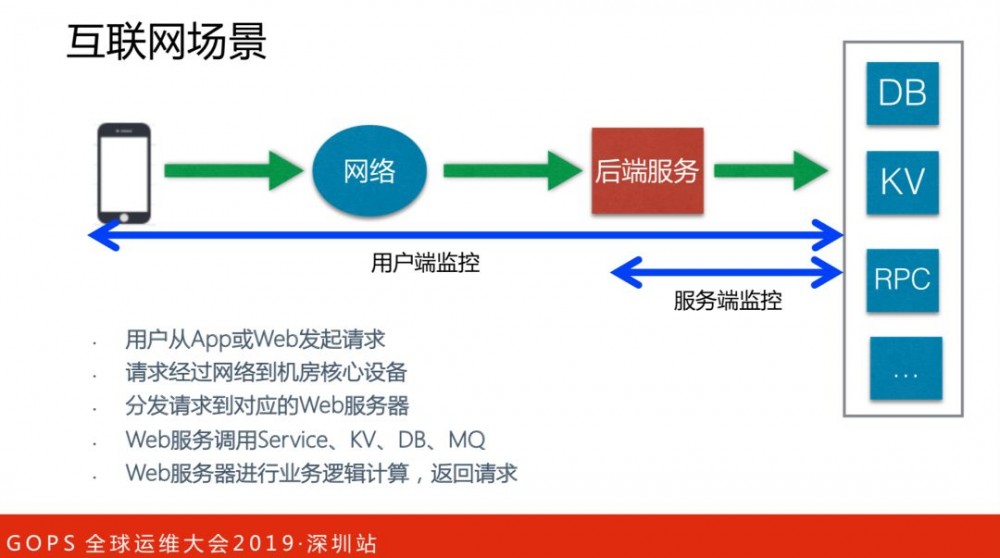
这里细分为两个端监控:用户端监控和服务端监控。
用户端监控是从用户角度监控服务请求是否正常,覆盖了美团点评几乎所有APP包括浏览器端项目,提供了近实时用户端多维数据分析,立体式监控功能。
服务端监控是从服务本身角度监控是否健康,在基础架构中间件框架(MVC框架,RPC框架,数据库框架,缓存框架等,消息队列,配置系统等)深度集成,为美团点评各业务线提供系统丰富的性能指标、健康状况、实时告警等。

面临的问题有:
-
用户端监控。需要了解用户最真实的使用情况,比如打开美团外卖体验如何,主要表现有打开速度、加载流畅度等。
-
服务端监控。异常发现和根因定位,性能瓶颈在哪里?线上运行的系统指标是否正常?很多情况下,系统指标正常,并不代表应用是健康的。
-
运维运营。清楚了解服务的QPS及响应时间等核心指标,并根据这些指标来做相应的降级、扩容、缩容等操作。


用户端监控主要阐述三个方面:
-
用户端大盘
-
用户访问监控
-
用户资源监控

这是用户端大盘,对于分析整体的SLA数据是非常有帮助的,通过它我们能知道全国用户使用情况。曾经有些偏远地区网络稍微差一点,一段时间的成功率非常低,通过大盘可以很快定位和发现。
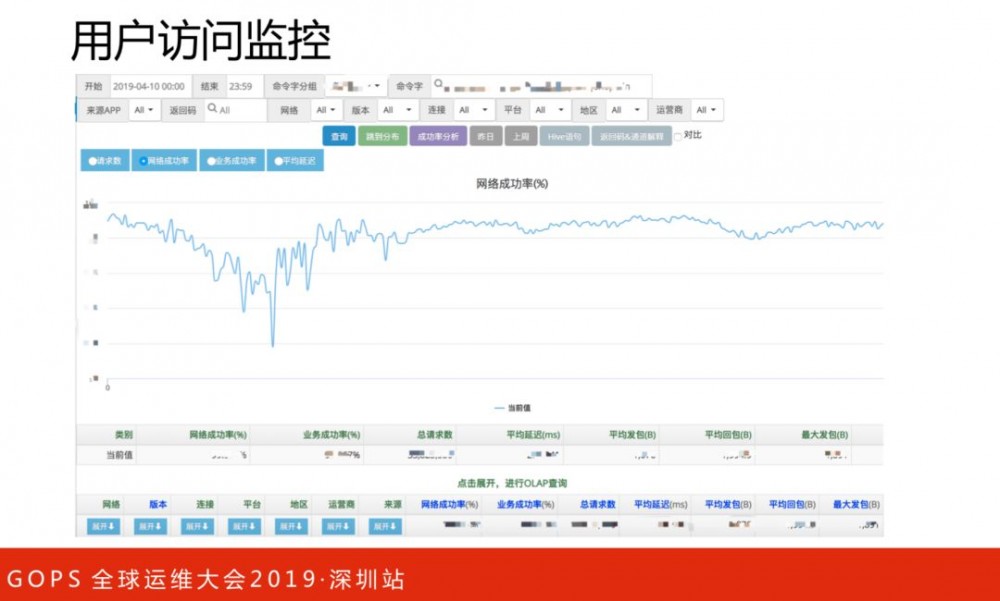
仅仅有整体数据是不足的,如果某一个时间里出现了显红的地区,我们需要知道是哪个接口出问题导致,可以通过用户访问监控来分析。用户访问监控有很多维度,比如返回码、请求来源APP、网络类型、平台类型、APP版本等等。
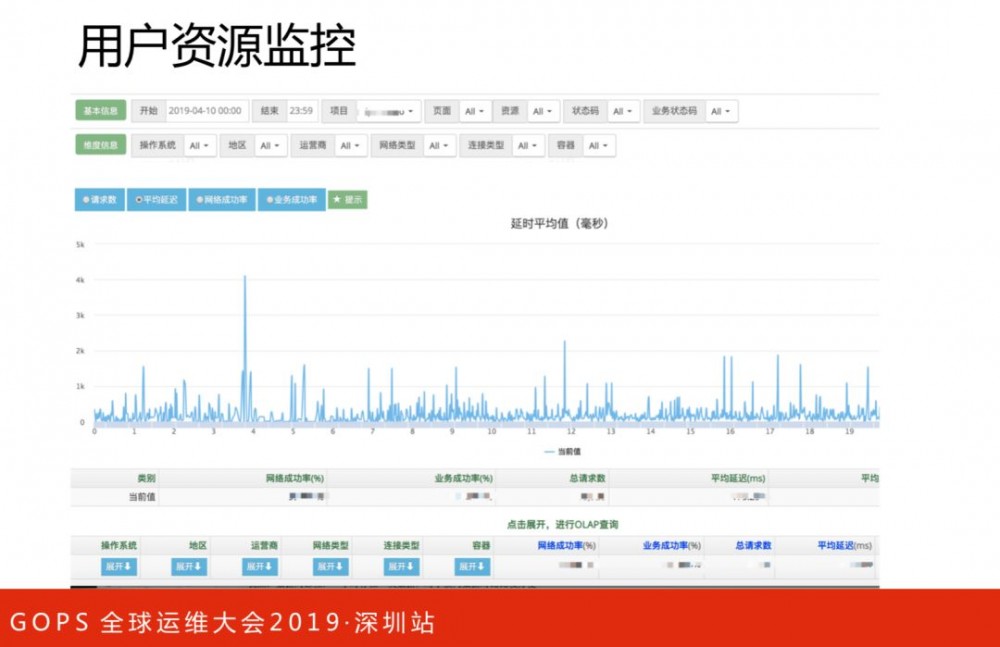
用户资源监控与上面的用户访问监控类似的,这里不再详细展开。
-
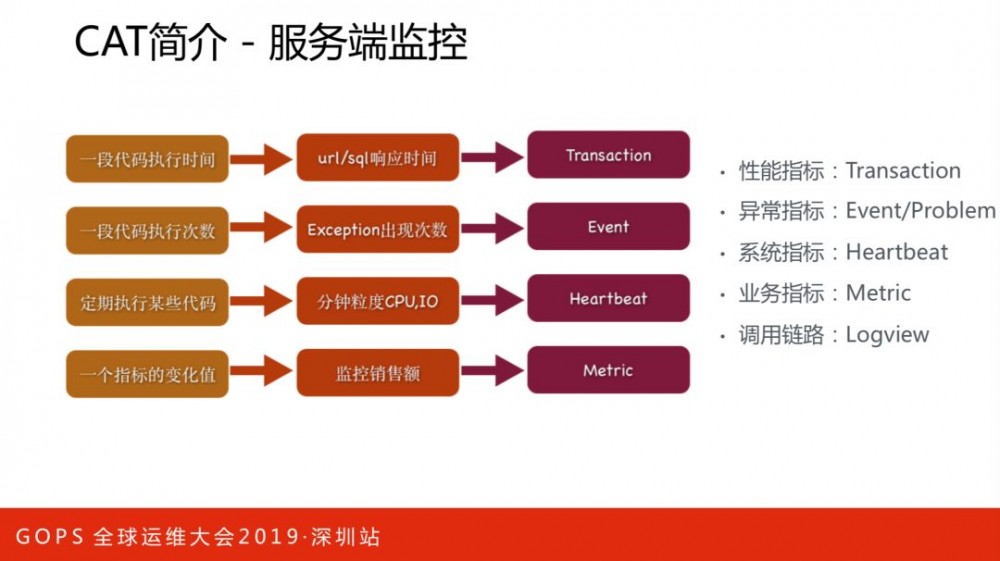
服务端监控指标有:性能指标、异常指标、系统指标、业务指标和调用链路。想象一个场景,用户打开APP加载比较慢,假设是后端服务返回影响了用户体验,那么要定位这个问题,往往要多个环节去排查。
-
如果是请求到达服务端后的响应较慢,可能伴随着请求超时异常,我们可以分别排查性能指标、异常指标的报表数据和趋势图,这些指标都是可以到机器维度的。对于出现异常的请求,会有一条调用链路与之关联,点开调用链路,可以看到详细的调用情况,以及每一步的耗时,对于我们分析哪一环节出现问题,起到关键作用。
-
业务指标是统计到集群粒度,关心整个服务宏观的业务表现。
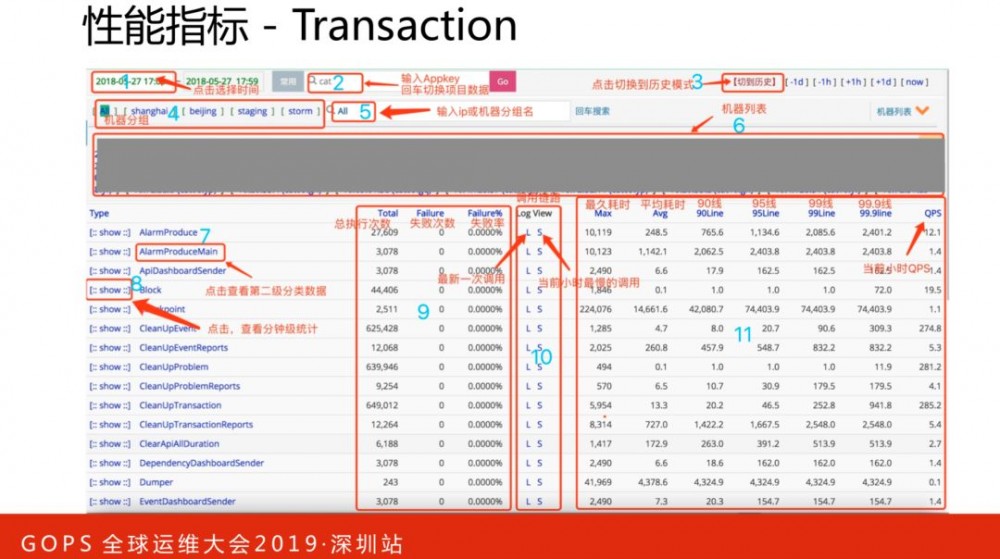
Transaction监控一段代码运行情况:运行次数、QPS、错误次数、失败率、响应时间统计(平均响应时间、Tp分位值)等等。监控维度为时间、项目、机器、第一级指标名Type、第二级指标名Name。
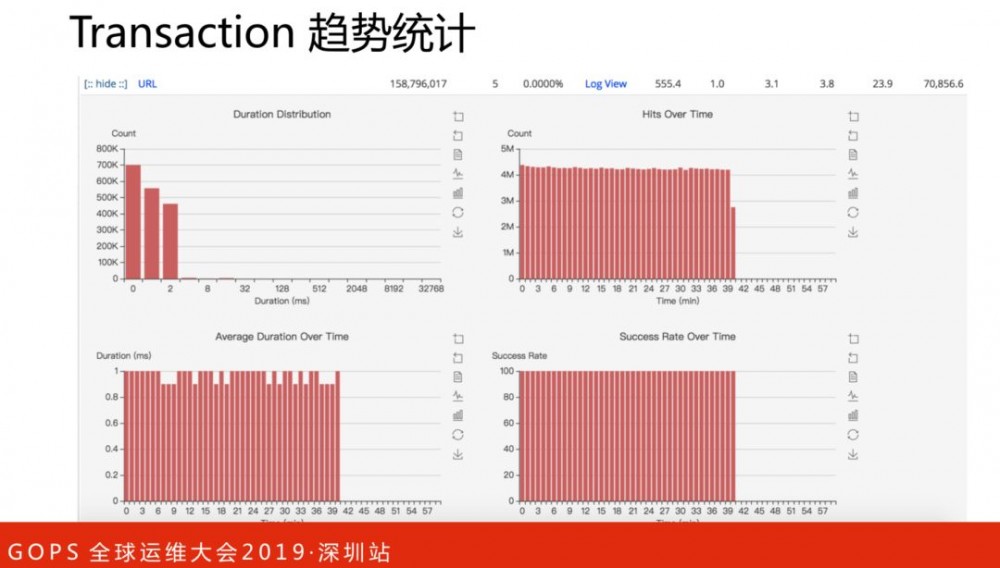
点开show可以查看各个指标的分钟级趋势数据,包括响应分布、每分钟访问量、每分钟平均响应时间、每分钟成功率等。

异常大盘可以让我们快速发现目前哪些服务出现大量异常,并能按照每个部门的范围查找出现问题最多的服务。
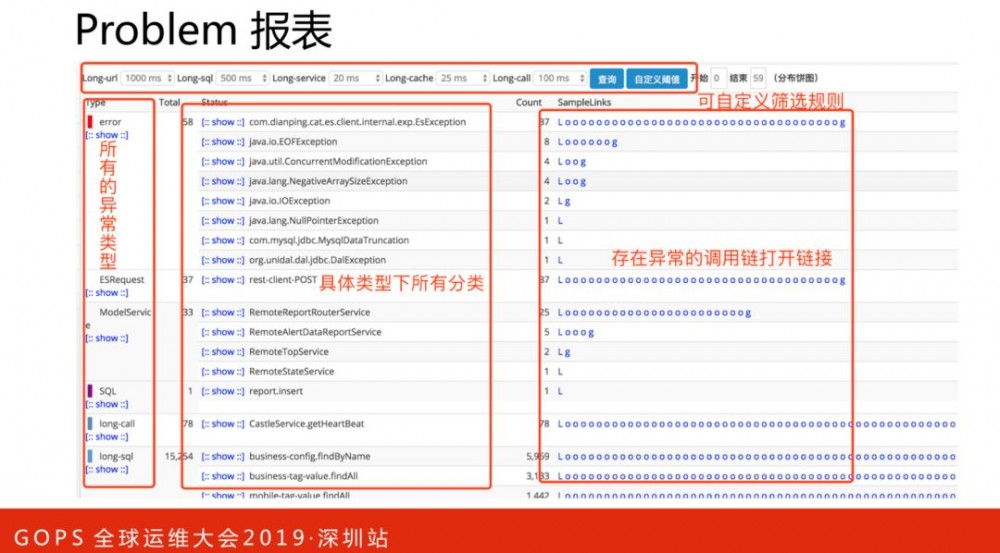
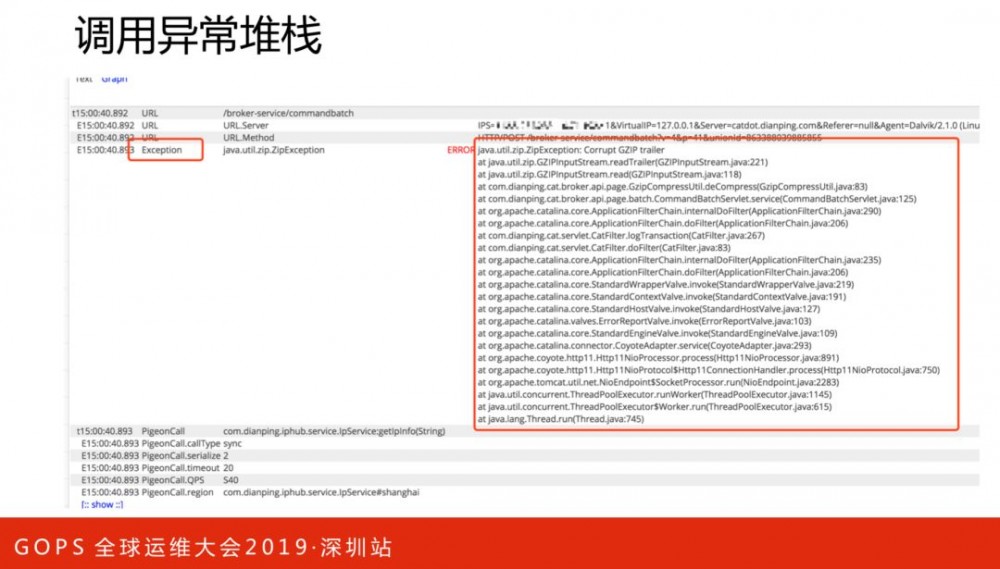
Problem记录整个项目在运行过程中出现的问题,包括一些异常、错误、访问较长的行为。Problem报表是由logview存在的特征整合而成,方便用户定位问题。常见做法,是把异常写到机器日志文件,出现问题后,需要登陆机器进行日志排查。而Problem报表可以列出异常名称和堆栈明细,效率提高了很多。如下图,是一个请求异常的调用链路明细。
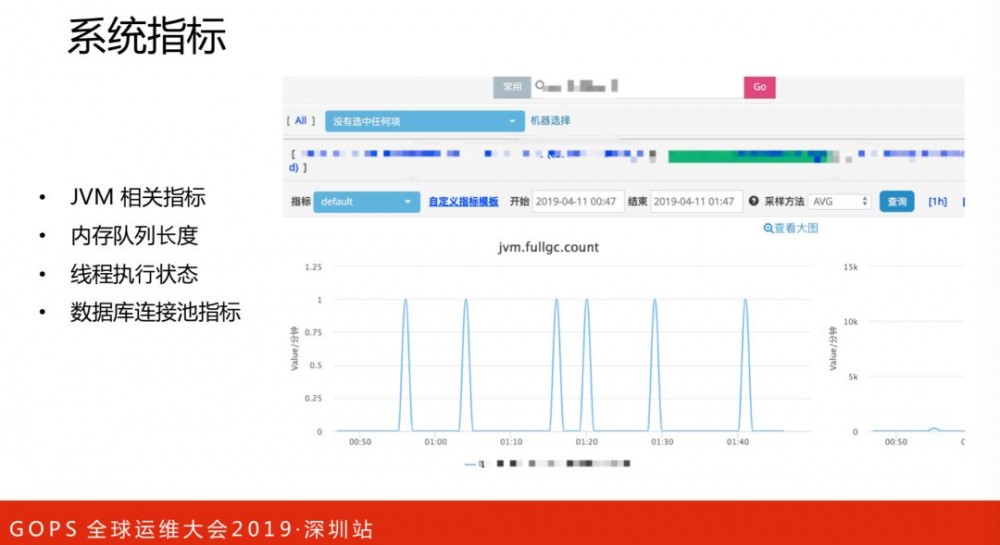
系统指标:客户端定期每分钟向服务端汇报当前运行时候的一些状态。
-
JVM相关指标
-
内存队列长度
-
线程执行状态
-
数据库连接池指标
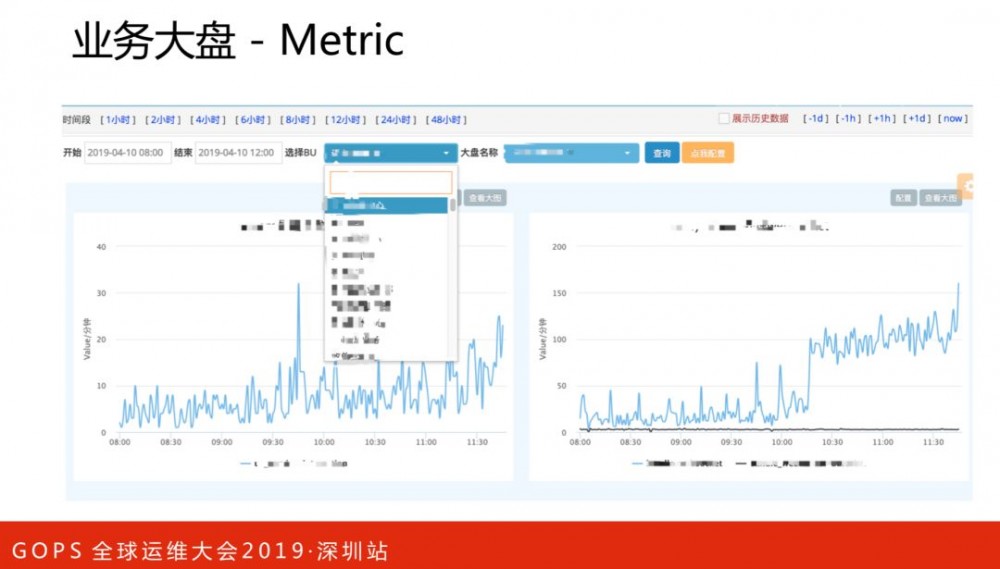
业务指标支持多维度的标签,比如订单指标,可以额外加上来源、渠道等标签,这样当出现问题时候,可以根据来源、渠道等多种选择条件来看业务指标,分析问题出现在哪个渠道。

CAT已经在基础架构中间件框架深度集成,业务接入基础架构部提供的组件后,大部分的中间件的打点就默认存在了。此外CAT还提供了丰富的API,供业务结合自己的业务场景,进行自定义的埋点,这些埋点在分析微观性能问题时,往往非常关键。
2. 架构演进
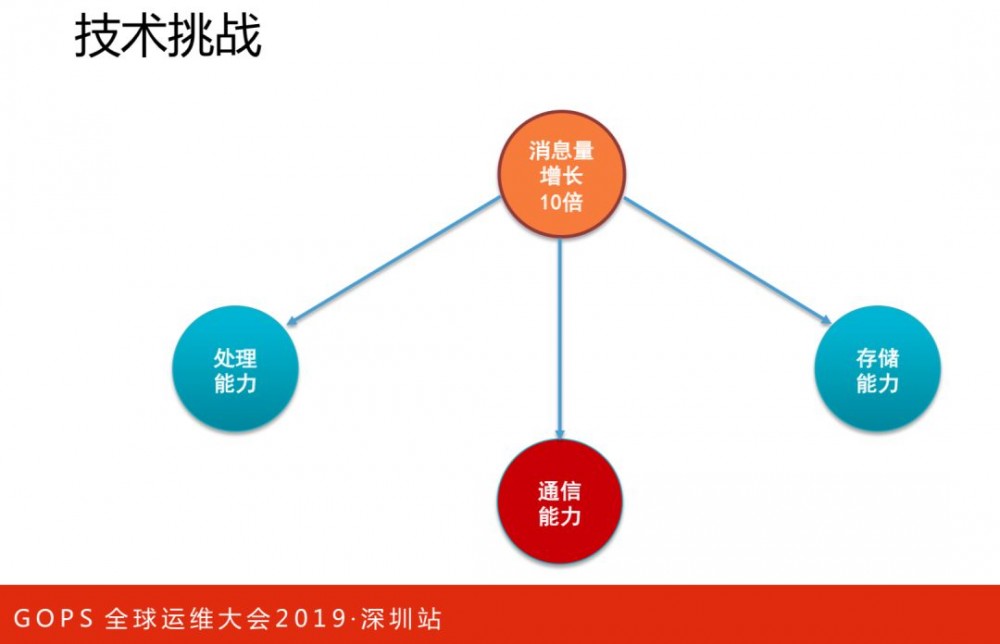
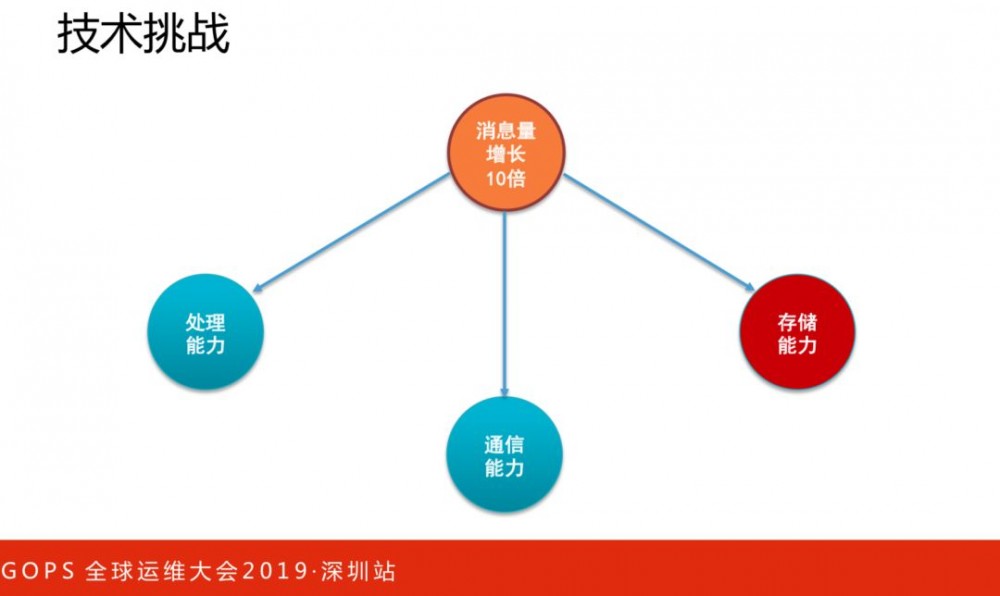
随着业务规模的增长,CAT监控流量也呈现了指数级的增加。过去几年,我们不断进行技术和架构演进,接下来与大家一起回顾下我们的演进过程。
处理能力
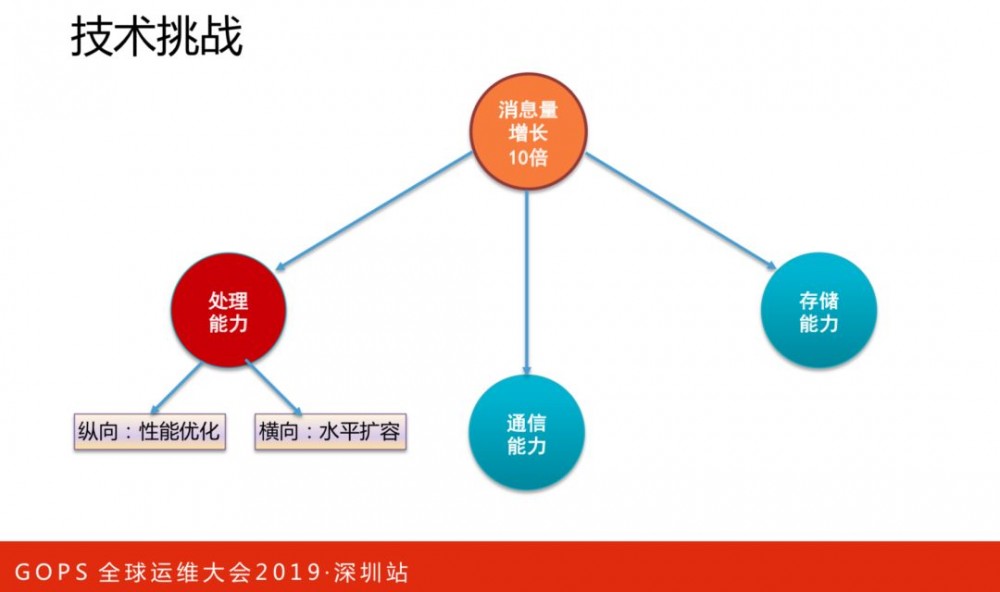
处理能力:
-
纵向,性能优化,消息采样聚合
-
横向,水平扩容
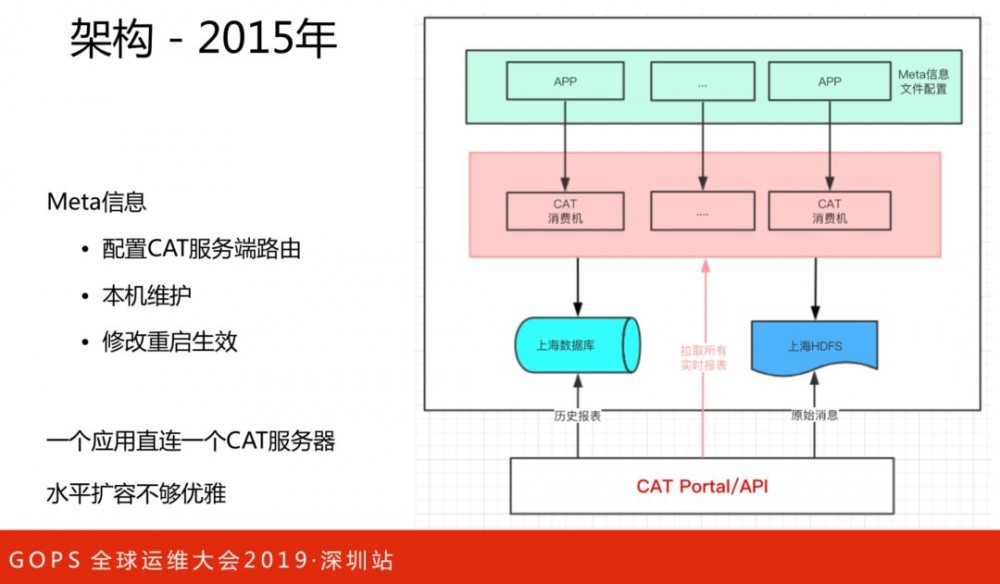
这是2015年的架构,存在问题:
-
需要配置CAT服务端路由信息
-
本机维护,维护成本较高
-
修改重启才能生效
一个应用直接连接一个CAT服务器,水平扩容不够优雅。
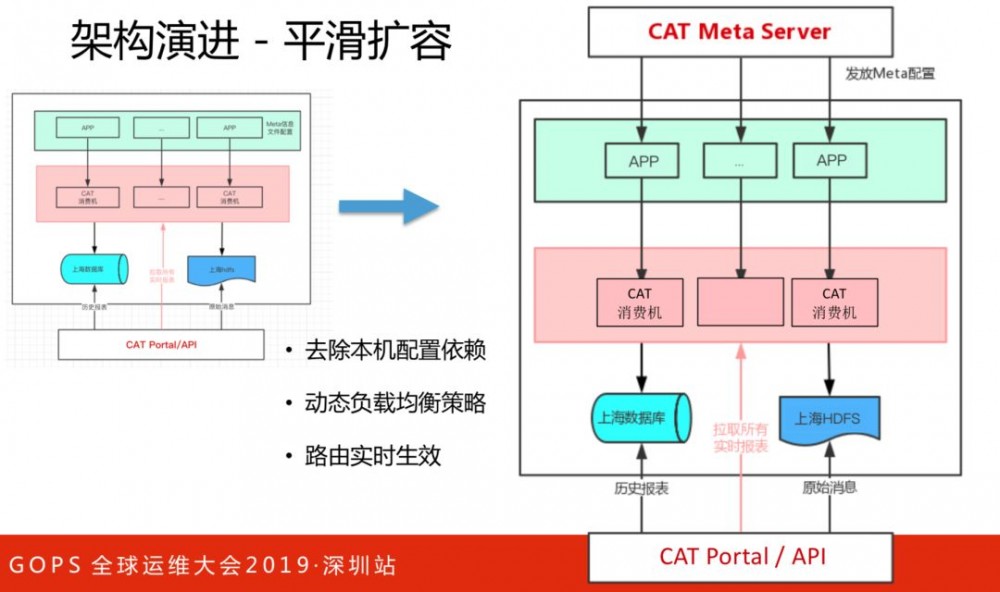
架构的改进,去除本机配置依赖,动态负载均衡策略和路由实时生效,便于水平扩容,解决横向的问题。
通信能力
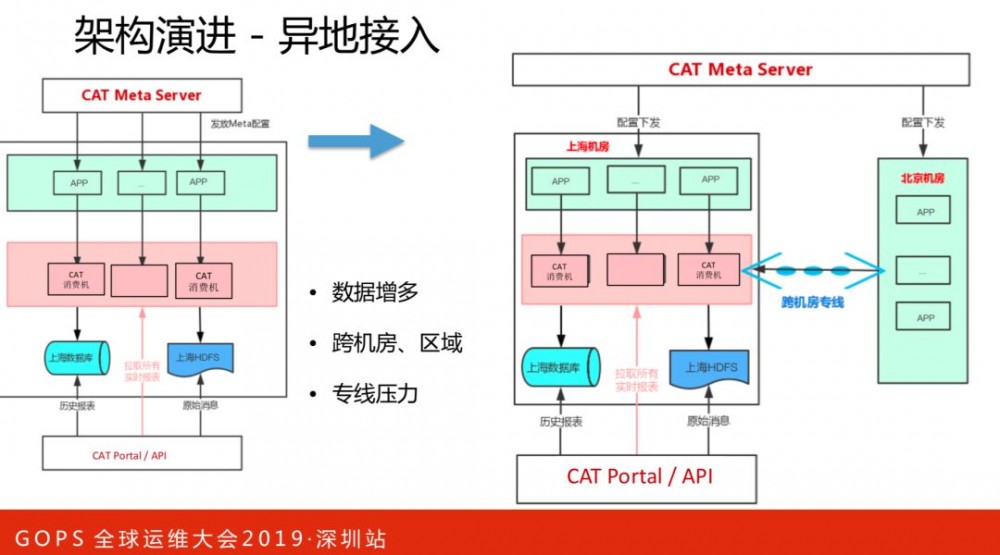
北京侧机房业务流量接入CAT,而CAT部署在上海侧机房,所有的监控数据输入都集中在上海侧机房,北上跨机房专线是宝贵资源,专线压力比较大,对于成本和风险控制都是不利的。
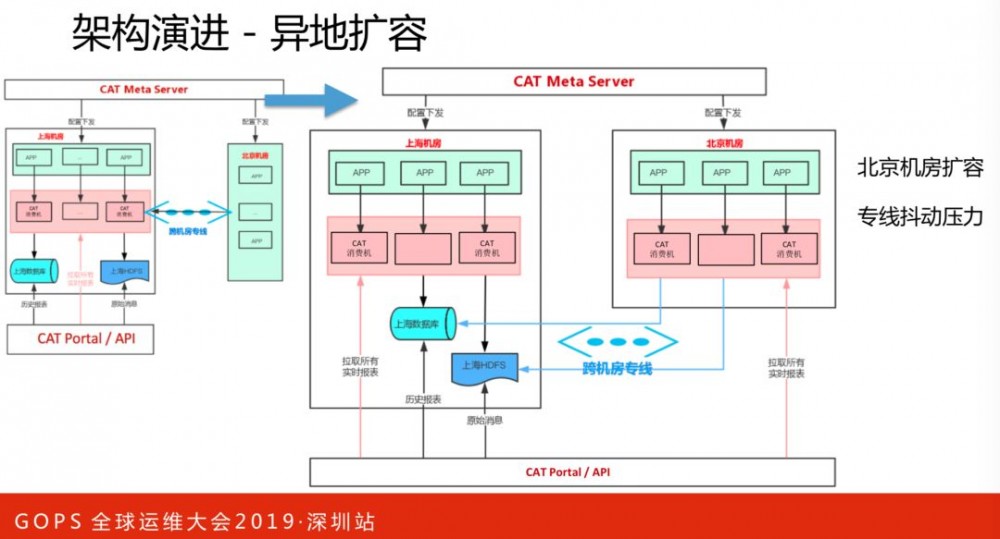
接下来在北京侧机房扩容CAT服务器,监控数据的上报不再跨机房,数据输出落地还是会跨机房。落地有两部分数据:一部分是监控统计数据,一小时一次集中写到数据库;
另一部分是原始消息数据(比如调用链数据、堆栈日志),处理逻辑是异步写本地磁盘,每小时一次集中异步写到HDFS。两部分数据落地,都会导致每小时有一次集中的流量跨机房写入,造成带宽固定周期的流量抖动。
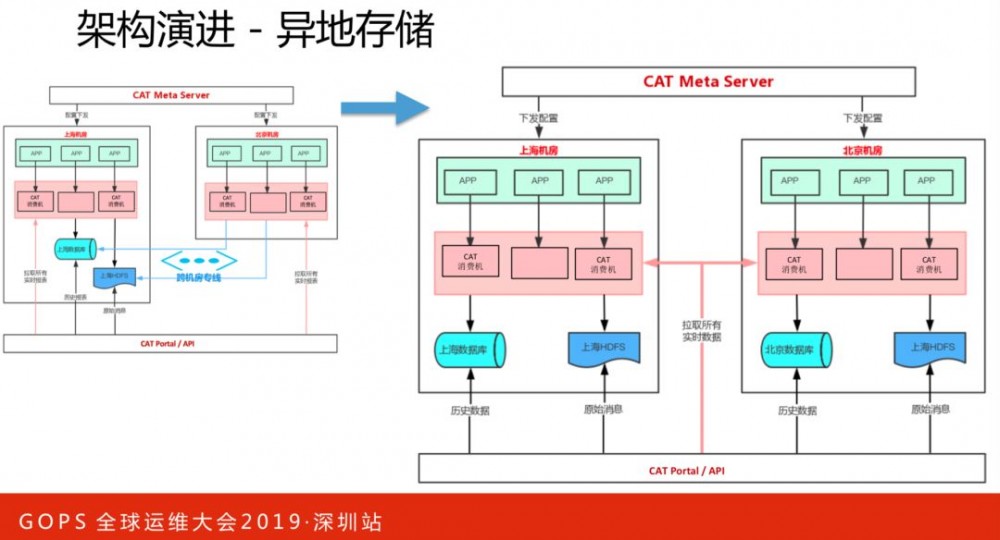
接下来异地部署数据库和HDFS,将异地的存储落地控制在机房内部,解决跨机房流量抖动问题,同时避免数据查询跨机房、跨地域,也利于降低数据查看平均延时。
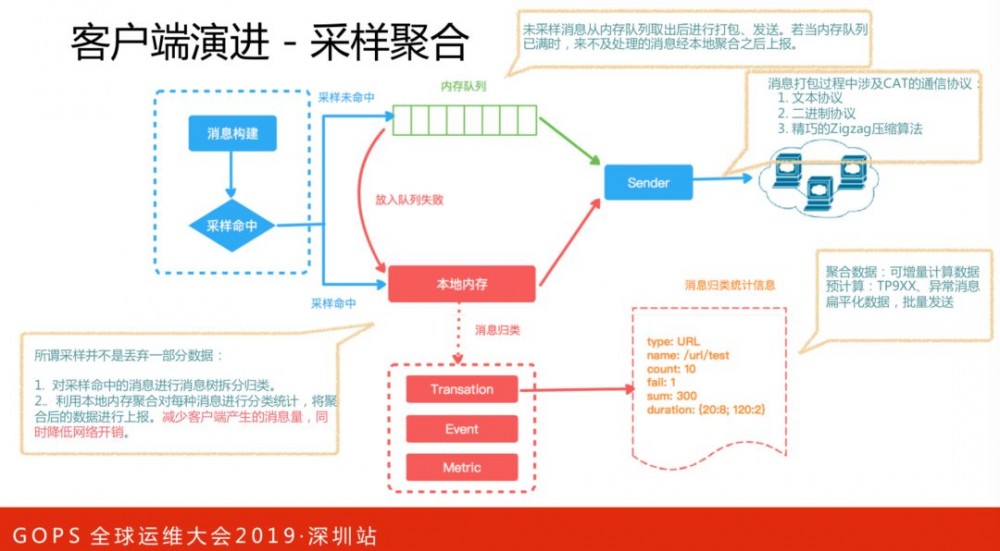
面对海量监控数据,准确地统计全量数据是有挑战的。譬如一百个请求,打开了一百次同样的页面,在减少数据采集的同时,如何保证统计到的数据(响应时间、请求数、TP线等)是准确的?
我们通过同类数据批量上报、采样聚合、支持增量计算、自定义序列化格式等方式,将数据量得到有效降低,同时保证基本的调用链路不丢失、监控数据准确。
存储能力
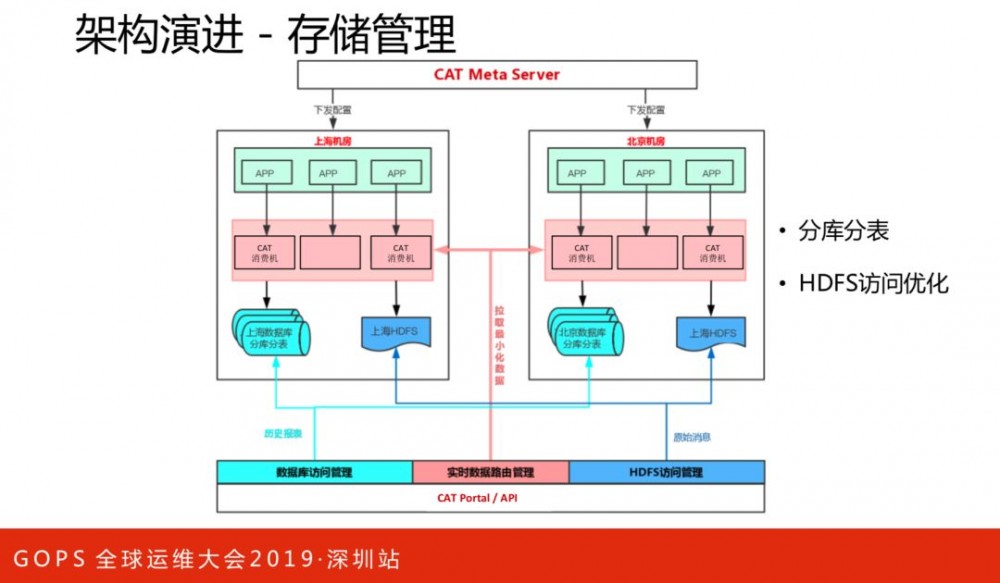
所有的监控消息,CAT消费引擎会实时分析得出监控报表数据,需要足够容量的存储能力作支撑,存储上我们做了分库分表来确保容量和查询效率。
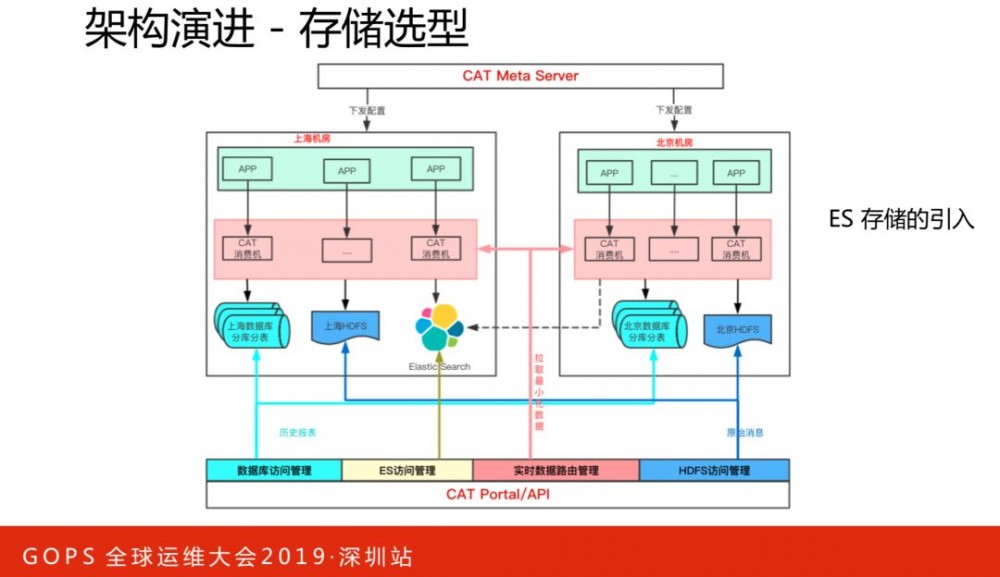
CAT中监控数据,均是基于一小时报表形式存储在数据库中。随着业务需求的丰富化,这种存储对于跨多个小时的查询是不太合适的。我们在保留报表模型的基础上,引入了ES存储,将需要大量跨小时查询的指标,演进到ES存储模型,将一部分数据计算和存储能力下放到MQ的消费端。
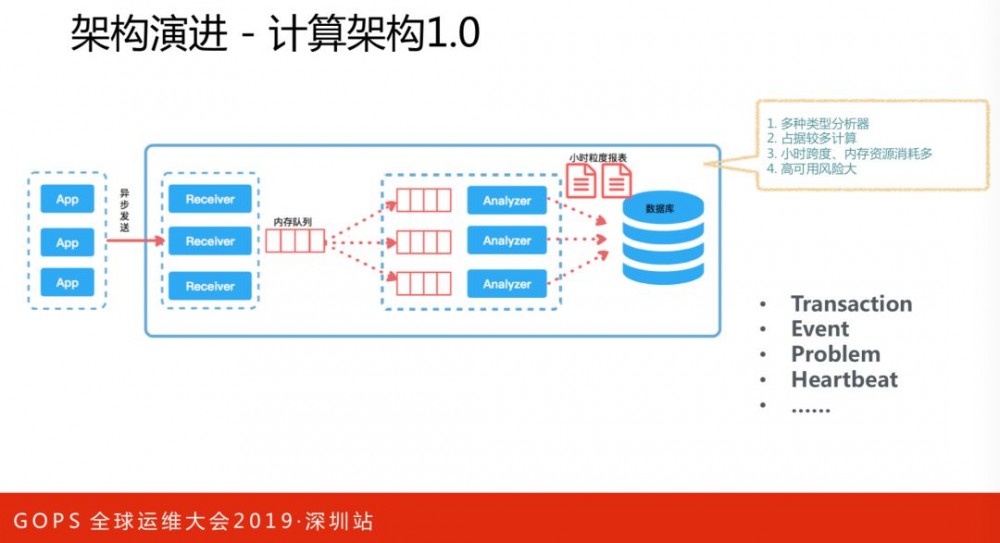
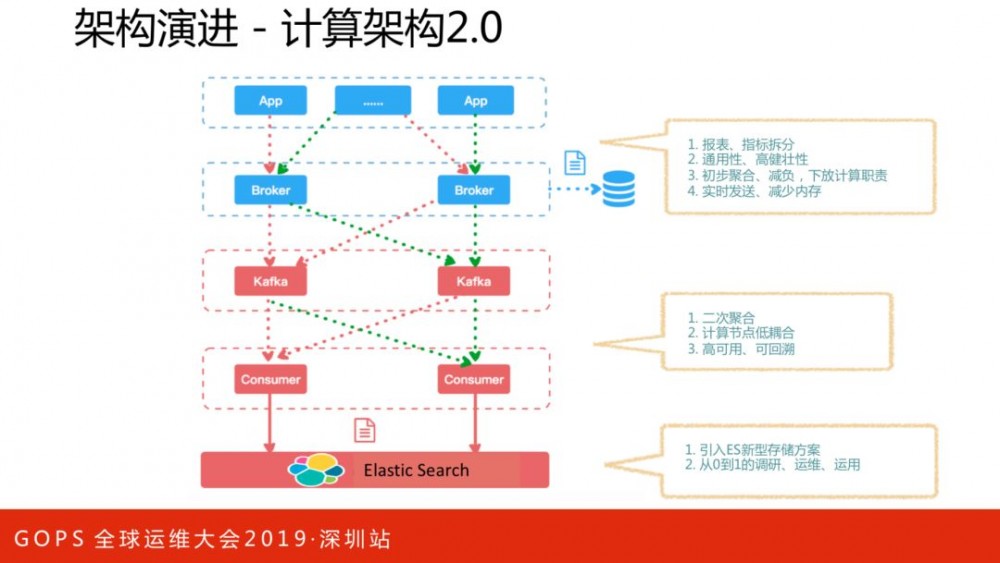
计算架构1.0,将所有数据放在内存里面,一小时落地一次。这么设计优势是访问当前小时的数据非常快,相当于访问一个缓存服务;劣势包括:内存消耗占用多、计算压力较大、高可用性差。在计算架构2.0里,将报表和指标进行区分,指标数据序列化为通用模型写入Kafka,消费者对指标数据进行二次聚合、批量处理、削峰存入ES中。
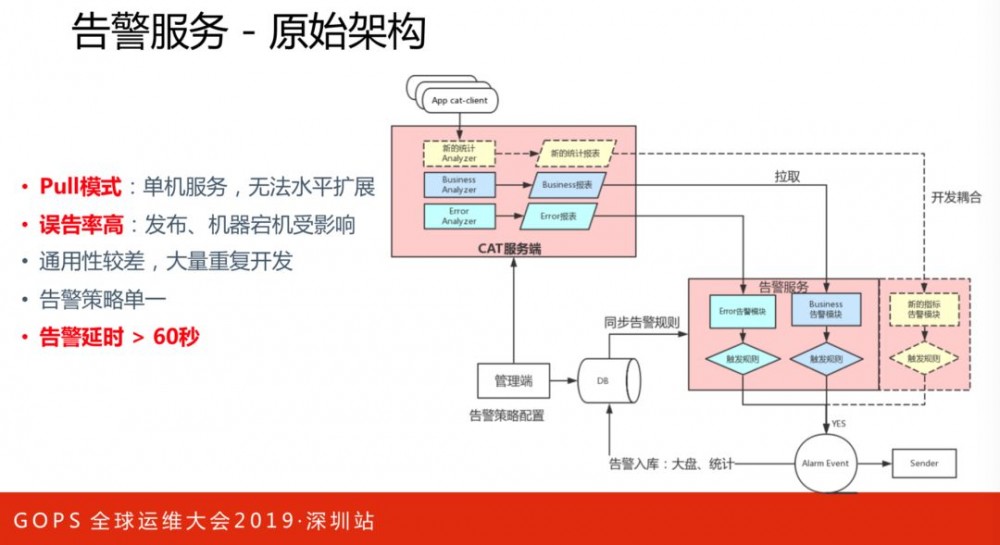
上图是告警服务的原始架构。存在的问题如下:
-
Pull模式,单机服务,无法水平扩展。
-
误告率高,发布、机器宕机受影响。
-
通用性较差,大量重复开发。
-
告警策略单一。
-
告警不及时。
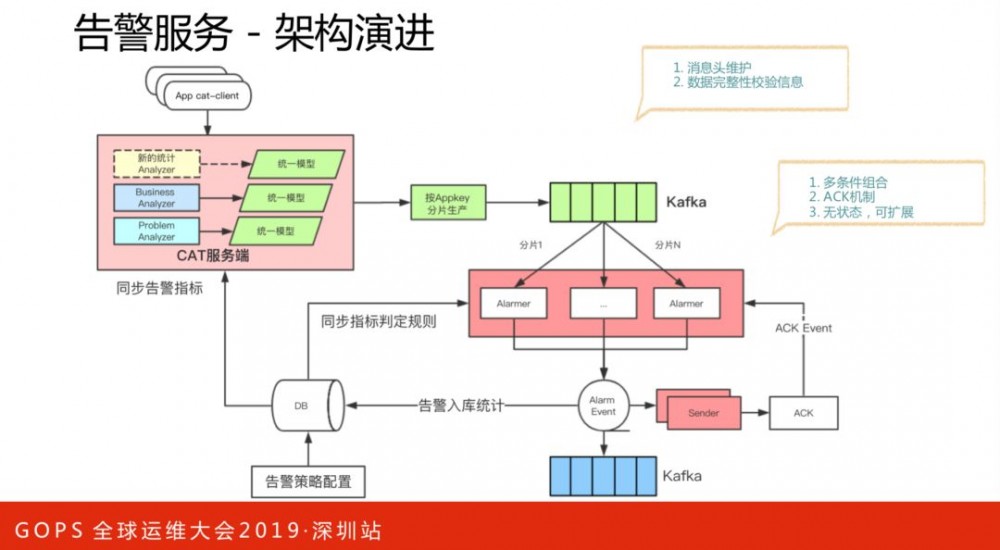
告警服务架构的演进,能保证高可用性和可扩展性。这里引入了Kafka,所有数据全部统一模型到消息队列,并加入元数据信息标识消息的完整度。原本的告警策略单一,引入新的架构之后,可以更加灵活,如多条件组合、告警信息消费,下游服务消费告警后进行弹性扩容、降级熔断等。
3. 开源社区
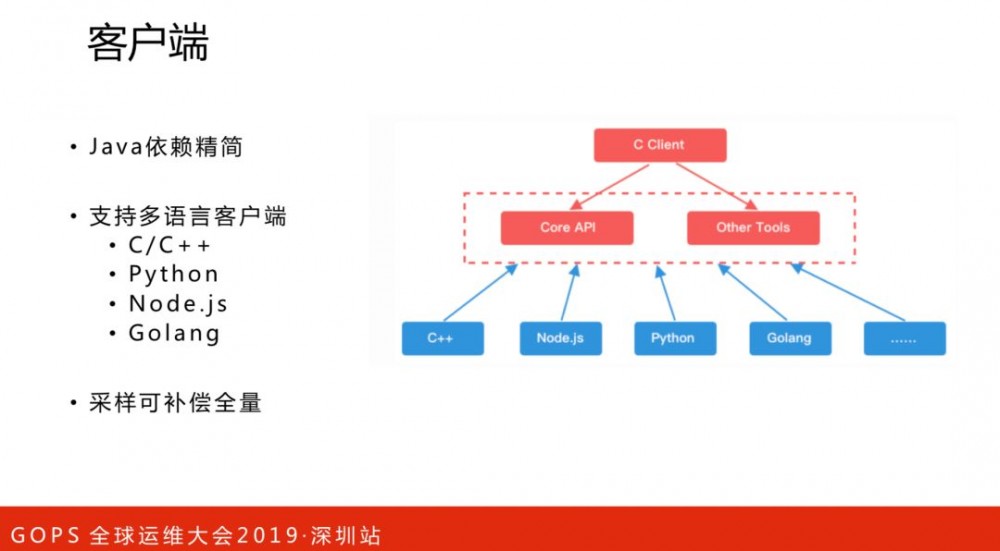
在2018年10月份的发布了CAT2.0版本,有一些显著的更新:
-
Java依赖精简,客户端对于陈旧框架的依赖进行了去除,更加精简。
-
支持多语言客户端。如c/c++、python、Golang等。
-
采样可补偿全量。
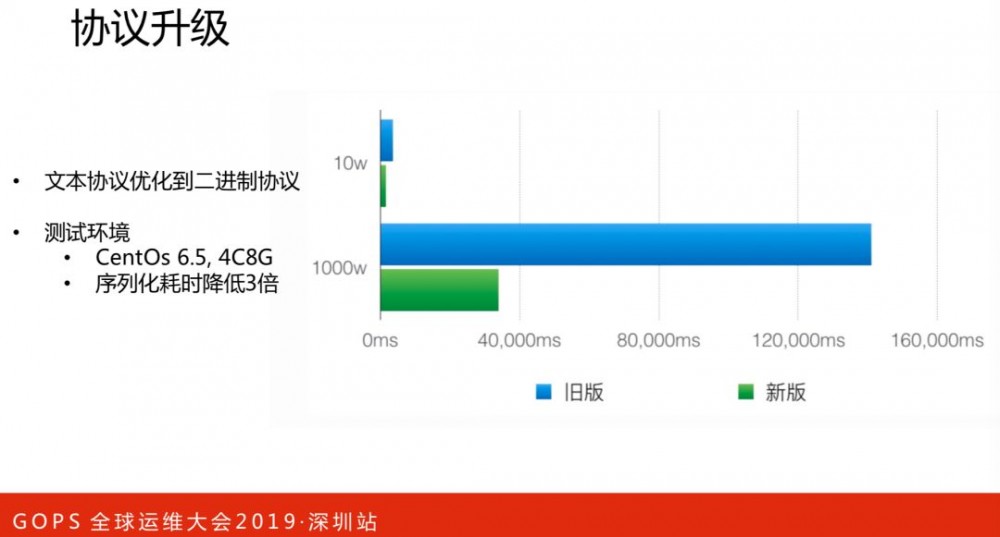

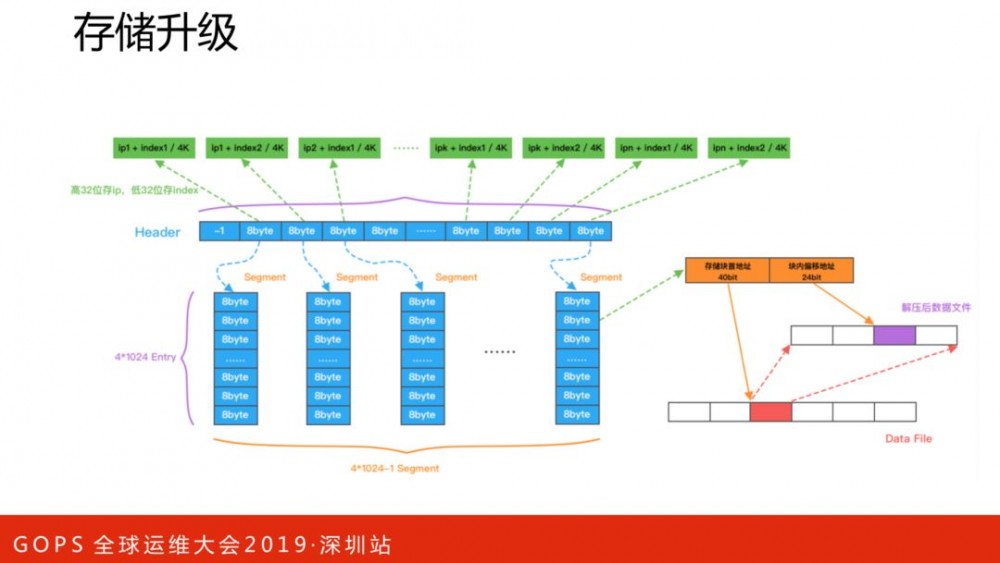
CAT新版存储做了很多的优化,感兴趣的可以阅读源码,这里不展开讲解。
 本文来源 高效运维(ID: greatops)
本文来源 高效运维(ID: greatops)
高效运维公众号由萧田国及朋友们维护,经常发布各种广为传播的优秀原创技术文章,关注运维转型,陪伴您的运维职业生涯,一起愉快滴发展。

-End-
阿里中台系列文章:
1. 阿里技术总监,讲透技术中台,16页PPT
2. 阿里架构总监,讲透中台架构,13页PPT
5. 京东架构师王新栋:大型开放平台的技术架构
想下载“阿里中台架构”的PPT?
第一步,关注“技术领导力”公众号
第二步,在对话框输入:中台

想跟文章作者、100位互联网大咖交流学习?
添加助理小姐姐Emma
注明“加群”,稍后她会拉你进社区群

往期精彩推文:
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

