TreeMap源码分析(基于jdk1.8)
之前花了很多时间写了HashMap,HashMap算是超级重要的一个知识点了,面试的时候特种问题各种变形都有可能会问到。相对于HashMap,好像TreeMap显得有点不那么重要了,但是常常会伴随着HashMap来提问。因此花了一部分时间对其进行整理了一下。
一、认识TreeMap
1、继承关系
其实从名字就可以看出主要是和树有关,而且这棵树还是赫赫有名的红黑树。因为其处于java集合体系一个一个知识点,我们还是先看一下这个TreeMap处于整个集合体系的一个什么位置?

从类图中我们可以看到,TreeMap继承自AbstractMap。这张图太宏观了,知道其处于一个什么位置,我们按住TreeMap别动,逐渐把视线转变成以TreeMap为中心,看一下他的继承关系。
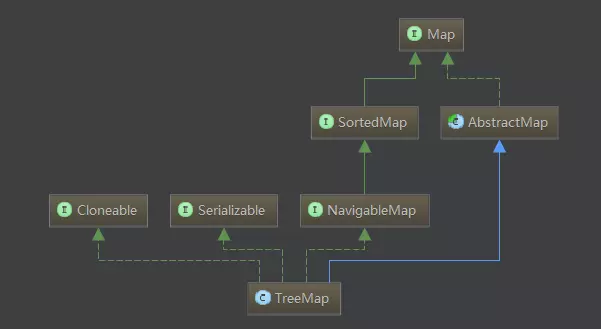
在这里我们就很清晰了,TreeMap继承于AbstractMap,实现了 Cloneable, NavigableMap, Serializable接口。当然这只是让我们去认识一下TreeMap,核心知识还需要往下看。
2、红黑树
我们之前提到,TreeMap的底层是基于红黑树的,那什么是红黑树呢?我们在这里简单的认识一下,了解一下红黑树的特点:红黑树是一颗自平衡的排序二叉树。我们就先从二叉树开始说起。
(1)二叉树
二叉树很容易理解,就是一棵树分俩叉。
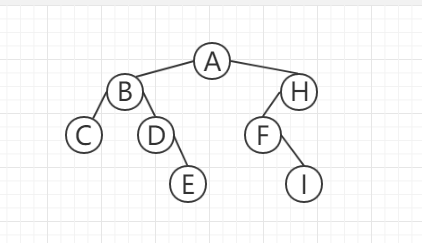
上面这颗就是一颗最普通的二叉树。但是你会发现看起来不那么美观,因为你以H为根节点,发现左右两边高低不平衡,高度相差达到了2。于是出现了平衡二叉树,使得左右两边高低差不多。
(2)平衡二叉树
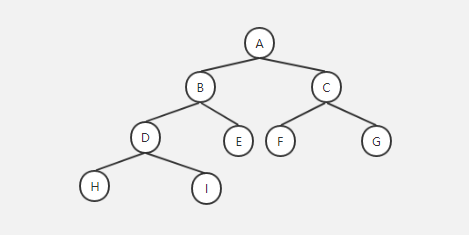
这下子应该能看到,不管是从任何一个字母为根节点,左右两边的深度差不了2,最多是1。这就是平衡二叉树。不过好景不长,有一天,突然要把字母变成数字,还要保持这种特性怎么办呢?于是又出现了平衡二叉排序树。
(3)平衡二叉排序树
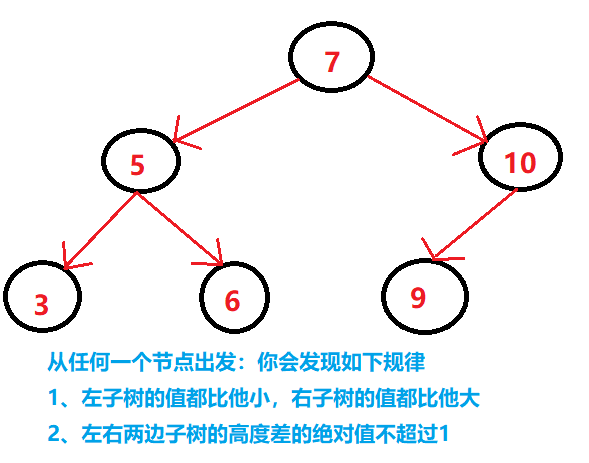
不管是从长相(平衡),还是从规律(排序)感觉这棵树超级完美。但是有一个问题,那就是在增加删除节点的时候,你要时刻去让这棵树保持平衡,需要做太多的工作了,旋转的次数超级多,于是乎出现了红黑树。
(4)红黑树
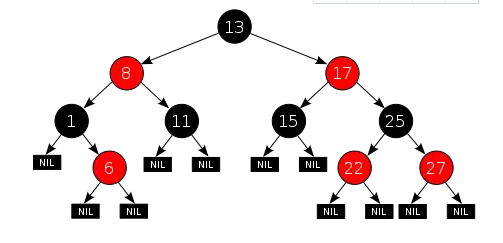
这就是传说中的红黑树,和平衡二叉排序树的区别就是每个节点涂上了颜色,他有下列五条性质:
- 每个节点都只能是红色或者黑色
- 根节点是黑色
- 每个叶节点(NIL节点,空节点)是黑色的。
- 如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
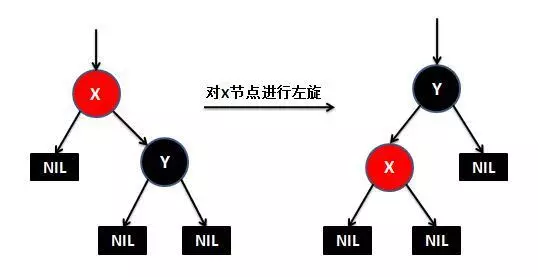
这些性质有什么优点呢?就是插入效率超级高。因为在插入一个元素的时候,最多只需三次旋转,O(1)的复杂度,但是有一点需要说明他的查询效率略微逊色于平衡二叉树,因为他比平衡二叉树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多 多一次比较 。如何去旋转呢?来一张动图表示(从谷歌上找的图,如有侵权问题还请联系我删除)
首先是左旋:
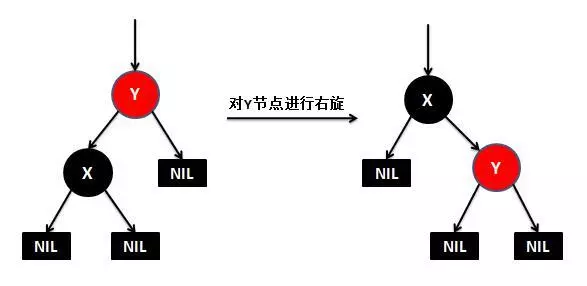
然后是右旋:
当然这里不是专门讲解红黑树的,因此不会特别详细的去说。这里只起到抛砖引玉的作用,想要继续往下看一定要明白红黑树的原理。重要的事说三遍:
想要继续往下看一定要先明白红黑树的原理!
想要继续往下看一定要先明白红黑树的原理!
想要继续往下看一定要先明白红黑树的原理!
说了这么久回归我们的TreeMap正题,TreeMap底层就是使用的这种红黑树。那么他的插入操作肯定效率也是很高的。我们就深入到他的源码中,正式的了解一下:
二、源码分析TreeMap
1、简单使用案例
在源码分析之前,我们先来看TreeMap的一个简单的使用:
public class Test {
public static void main(String[] agrs) {
TreeMap<String, Integer> treeMap = new TreeMap<String, Integer>();
// 新增元素:
treeMap.put("张三", 20);
treeMap.put("李四", 18);
// 遍历元素:
Set<Map.Entry<String, Integer>> entrySet = treeMap.entrySet();
for (Map.Entry<String, Integer> entry : entrySet) {
String key = entry.getKey();
Integer value = entry.getValue();
}
}
}
复制代码
这里只是简单的演示一下基本的增加元素和遍历元素,其他的方法可以自己测试一下,很简单。下面我们就开始分析:
2、基本属性
和HashMap一样,聚焦TreeMap,然后F3进入源码。映入眼帘的就是他的继承关系了。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
复制代码
可以看到继承了AbstractMap,实现了NavigableMap<K,V>、Cloneable、Serializable接口。然后往下看,会有一些属性,我们先解释一下,下面会用到:
//这是一个比较器,方便插入查找元素等操作 private final Comparator<? super K> comparator; //红黑树的根节点:每个节点是一个Entry private transient Entry<K,V> root; //集合元素数量 private transient int size = 0; //集合修改的记录 private transient int modCount = 0; 复制代码
里面一共就这4个属性,每个属性的含义也很简单,其中有一点需要我们注意,每个节点是一个Entry,那么这个Entry长什么样呢?我们不妨看一下:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
//左子树
Entry<K,V> left;
//右子树
Entry<K,V> right;
//父节点
Entry<K,V> parent;
//每个节点的颜色:红黑树属性。
boolean color = BLACK;
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
复制代码
这个类也是很简单,学过数据结构都知道其含义,在这里就不赘述了。
3、构造方法
TreeMap的构造方法一共有四个:
//构造方法1:默认构造方法,比较器为空
public TreeMap() {
comparator = null;
}
//构造方法2:指定一个比较器
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
//构造方法3:指定一个map创建,比较器为空,元素自然排序
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
//构造方法4:指定SortedMap,根据SortedMap的比较器来来维持TreeMap的顺序
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
复制代码
在这里可以看到,对于TreeMap来说,不管是哪一种构造方法,都离不开比较器。这也符合底层红黑树的要求,增删改查都需要知道元素大小,来确定位置。
在第三个构造方法中,指定一个map创建的意思就是在创建TreeMap的时候就往里存一些东西。方法就是putAll。我们可以进入到这个方法看看,是如何把map放到TreeMap中的。
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
return;
}
}
super.putAll(map);
}
复制代码
也就是使用了SortedMap的比较器,迭代排序之后插入,插入操作是父类调用的。
4、插入元素
插入元素是put方法,在一开始的基本使用中也演示了,我们进入到这个方法中看一下:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {//如果root为null 说明是添加第一个元素 直接实例化一个Entry 赋值给root
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;//如果root不为null,说明已存在元素
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) { //如果比较器不为null 则使用比较器
//找到元素的插入位置
do {
parent = t; //parent赋值
cmp = cpr.compare(key, t.key);
//当前key小于节点key 向左子树查找
if (cmp < 0)
t = t.left;
else if (cmp > 0)//当前key大于节点key 向右子树查找
t = t.right;
else //相等的情况下 直接更新节点值
return t.setValue(value);
} while (t != null);
}
else { //如果比较器为null 则使用默认比较器
if (key == null)//如果key为null 则抛出异常
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
//找到元素的插入位置
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);//定义一个新的节点
//根据比较结果决定插入到左子树还是右子树
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);//保持红黑树性质 插入后进行修正
size++;//元素树自增
modCount++;
return null;
}
复制代码
到了map这一部分的源码都很恶心,直接看确实看不下去,我们可以把上面的代码用个流程图来表示一下:
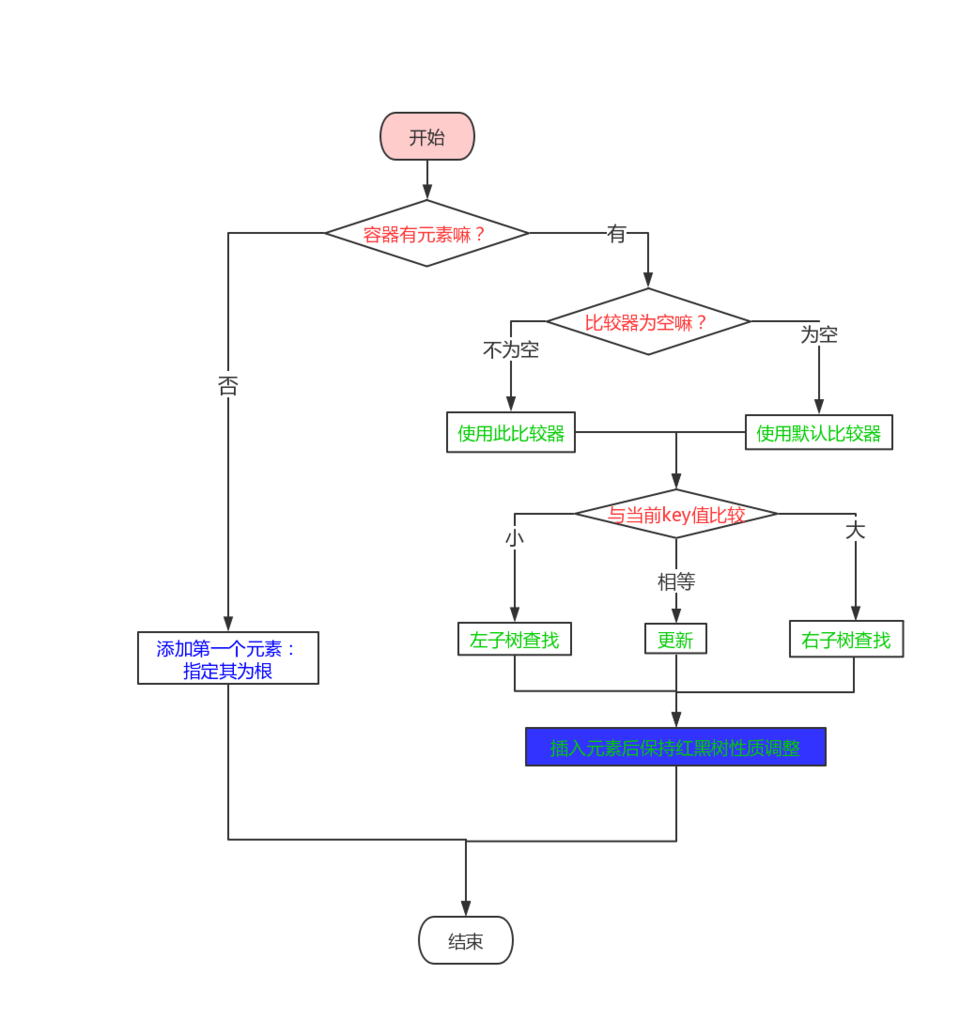
有了这个流程图,你再来重新看一下上面的代码,应该就能看明白了,不过上面有一个知识点,需要我们去注意,那就是插入之后红黑树为了保持其性质如何调整呢?代码定位到fixAfterInsertion方法。跟进去看看:
private void fixAfterInsertion(Entry<K,V> x) {
// 将新插入节点的颜色设置为红色
x. color = RED;
// while循环,保证新插入节点x不是根节点或者新插入节点x的父节点不是红色(这两种情况不需要调整)
while (x != null && x != root && x. parent.color == RED) {
// 如果新插入节点x的父节点是祖父节点的左孩子
if (parentOf(x) == leftOf(parentOf (parentOf(x)))) {
// 取得新插入节点x的叔叔节点
Entry<K,V> y = rightOf(parentOf (parentOf(x)));
// 如果新插入x的父节点是红色
if (colorOf(y) == RED) {
// 将x的父节点设置为黑色
setColor(parentOf (x), BLACK);
// 将x的叔叔节点设置为黑色
setColor(y, BLACK);
// 将x的祖父节点设置为红色
setColor(parentOf (parentOf(x)), RED);
// 将x指向祖父节点,如果x的祖父节点的父节点是红色,按照上面的步奏继续循环
x = parentOf(parentOf (x));
} else {
// 如果新插入x的叔叔节点是黑色或缺少,且x的父节点是祖父节点的右孩子
if (x == rightOf( parentOf(x))) {
// 左旋父节点
x = parentOf(x);
rotateLeft(x);
}
// 如果新插入x的叔叔节点是黑色或缺少,且x的父节点是祖父节点的左孩子
// 将x的父节点设置为黑色
setColor(parentOf (x), BLACK);
// 将x的祖父节点设置为红色
setColor(parentOf (parentOf(x)), RED);
// 右旋x的祖父节点
rotateRight( parentOf(parentOf (x)));
}
} else { // 如果新插入节点x的父节点是祖父节点的右孩子和上面的相似
Entry<K,V> y = leftOf(parentOf (parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf (x), BLACK);
setColor(y, BLACK);
setColor(parentOf (parentOf(x)), RED);
x = parentOf(parentOf (x));
} else {
if (x == leftOf( parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf (x), BLACK);
setColor(parentOf (parentOf(x)), RED);
rotateLeft( parentOf(parentOf (x)));
}
}
}
// 最后将根节点设置为黑色
root.color = BLACK;
}
复制代码
如果看不明白那就百度一下红黑树的原理,相信会有所收获。
5、删除元素
删除元素是remove。我们还是进入到这里面看看:
public V remove(Object key) {
// 根据key查找到对应的节点对象
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
// 记录key对应的value,供返回使用
V oldValue = p. value;
// 删除节点
deleteEntry(p);
return oldValue;
}
复制代码
我们会发现删除的核心代码就是调用了deleteEntry方法。我们不妨再跟进去看看:
private void deleteEntry(Entry<K,V> p) {
modCount++;
//元素个数减一
size--;
// 如果被删除的节点p的左孩子和右孩子都不为空,则查找其替代节
if (p.left != null && p. right != null) {
// 查找p的替代节点
Entry<K,V> s = successor (p);
p. key = s.key ;
p. value = s.value ;
p = s;
}
Entry<K,V> replacement = (p. left != null ? p.left : p. right);
if (replacement != null) {
// 将p的父节点拷贝给替代节点
replacement. parent = p.parent ;
// 如果替代节点p的父节点为空,也就是p为跟节点,则将replacement设置为根节点
if (p.parent == null)
root = replacement;
// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的左孩子
else if (p == p.parent. left)
p. parent.left = replacement;
// 如果替代节点p是其父节点的左孩子,则将replacement设置为其父节点的右孩子
else
p. parent.right = replacement;
// 将替代节点p的left、right、parent的指针都指向空
p. left = p.right = p.parent = null;
// 如果替代节点p的颜色是黑色,则需要调整红黑树以保持其平衡
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
// 如果要替代节点p没有父节点,代表p为根节点,直接删除即可
root = null;
} else {
// 如果p的颜色是黑色,则调整红黑树
if (p.color == BLACK)
fixAfterDeletion(p);
// 下面删除替代节点p
if (p.parent != null) {
// 解除p的父节点对p的引用
if (p == p.parent .left)
p. parent.left = null;
else if (p == p.parent. right)
p. parent.right = null;
// 解除p对p父节点的引用
p. parent = null;
}
}
}
复制代码
删除操作同样是红黑树的删除,只是用代码实现了一遍。红黑树的删除就是被删除路径上的黑色节点减少,于是需要进行一系列旋转和着色。
6、查找元素
这个方法就比较简单了。也就是get方法。
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p. value);
}
复制代码
到了这一步,很简单,真正获取元素的操作是getEntry方法,再跟进去就OK了。
final Entry<K,V> getEntry(Object key) {
/ 如果比较器为空,只是用key作为比较器查询
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 取得root节点
Entry<K,V> p = root;
//核心来了:从root节点开始查找,根据比较器判断是在左子树还是右子树
while (p != null) {
int cmp = k.compareTo(p.key );
if (cmp < 0)
p = p. left;
else if (cmp > 0)
p = p. right;
else
return p;
}
return null;
}
复制代码
这个更简单,核心代码就是左右子树查找。
三、总结
如果看起来比较懵逼,建议还是先了解一下红黑树,把这种数据机构搞清楚了,上面的代码确实都是小儿科。下面我们就对其来个总结:
1、基于红黑树的数据结构实现。
2、不允许插入为Null的key,HashMap可以为空,注意区别
4、若Key重复,则后面插入的直接覆盖原来的Value
5、非线程安全:底层没有 synchronized 这类的关键字。
6、可传入自己的比较器:从构造方法就可以看出。
OK,先到这里,如有问题,还请批评指正。

正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

