volatile的作用及正确的使用模式
volatile
先从基础的知识说起吧,这样也有个来龙去脉。
我们都知道,程序运行后,程序的数据都会被从磁盘加载到内存里面(主存)

而当局部的指令被执行的时候,内存中的数据会被加载到更加靠近CPU的各级缓存,以及寄存器中。
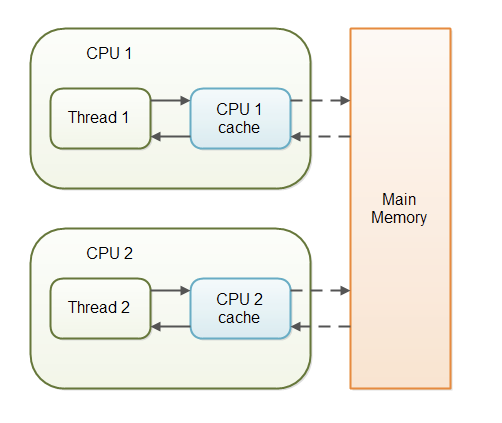
当一个多线程程序执行在一个多核心的机器上时,就会出现真正的并行情况,每个线程都独立的运行在一个CPU上,每个CPU都有属于自己独立的周边缓存。
那么此时,一个变量被两个线程操作,从内存复制到CPU缓存时,就可能出现两份了,这个时候就会出现问题,比如说简单的自增操作,就会变成,你加你的,我加我的,这样运行的效果就会偏离预期。线程1在CPU1上只看得见自己的缓存变量,线程2在CPU2上,也只看得见自己的缓存变量,它们都认为这是正确的、唯一的变量。这样也就导致程序运行结果偏离了预期。
volatile关键字就是用来处理这种可见性的问题。
当一个变量被标记为volatile的时候,这个变量将被放在主存里面,而不是CPU的缓存里面。当这个变量被读取的时候,是从主存读取,当这个变量被写入的时候,是写入到主存。
总所周知,内存肯定是比CPU缓存的读写速度要慢的。
那,是不是就意味着读写volatile的变量,效率会比非volatile的变量低呢。
为了验证这个问题,我写了一个简单的程序,分别有3个变量,分别是成员变量,volatile修饰的成员变量,和static静态变量。
对它们进行1000000000次自增,然后记录下完成时间。
以上的操作执行10次,取平均值。
最终得到了以下的结果:
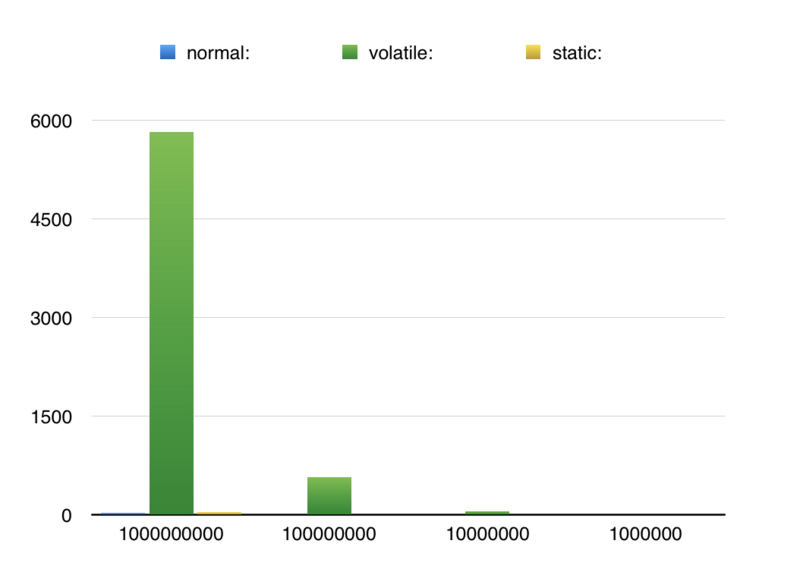
avg-------------- normal: 32.4 volatile: 5828.3 static: 43.8
看来读写volatile变量,确实要比普通的变量要慢,但也是数量级非常大的时候,才会非常明显。
下面是我做的实验,右边比左边逐渐少一个量级,相对于数量级增长,volatile关键字修饰的变量读写耗时有了等比的线性增长。
而普通的成员变量和静态变量就没有这样的现象了,可见CPU缓存对性能的巨大提升。
那么,使用volatile关键字可以让变量总是读写于主存,是不是就可以用它来避免多线程读写同一个变量导致的竞争问题呢?
答案是不能。
因为,volatile关键字只是保证变量的可见性,而没有保证操作的原子性,因此,只使用这个关键字无法保证操作的原子性。
为了验证一下这个问题,我也写了一个小程序来测试。
有两个变量a1,a2,a1是普通的成员变量,a2是volatile的成员变量。使用两个线程对它们进行自增n次,观察最后的结果是否为2n。
public int a1 = 0;
public volatile int a2 = 0;
/**
* 测试volatile是否具备原子性
* */
public static void test2() {
TestVolatile tv = new TestVolatile();
int count = 8000;
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < count; i++) {
tv.a1++;
}
for (int i = 0; i < count; i++) {
tv.a2++;
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < count; i++) {
tv.a1++;
}
for (int i = 0; i < count; i++) {
tv.a2++;
}
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (Throwable e) {
}
System.out.println(tv.a1);
System.out.println(tv.a2);
}
最后的结果是,a1和a2的表现差不多,有时候其中一个会刚好达到2n,但大多数情况,都是两个变量都无法成功的自增到2n(16000)
这也就验证了volatile关键字原子性操作的问题。
那么在实践中,如果出现需要同步的问题,依然还是要使用synchronized来解决,那么volatile应该在什么场景下使用呢?
volatile的应用场景
这个问题,我也是查了非常多的资料,花了几天的时间才搞清楚一点点。
正确的使用场景,基本符合一个原则: 一写多读:有一个数据,只由一个线程更新,其他线程都来读取。
比如,有一个系统回调,告诉我们最新的设备的经纬度,而其他的线程需要去用这个经纬度做一些计算,那么这个经纬度就一直被第一个线程写,其他线程就只负责读取。此时,经纬度就很适合用volatile修饰,这样可以保证其他线程永远读取到的是最新的数值。
再比如,我们有一个WebSocket的封装类,里面包装了长连接的建立和发送数据的方法。那么可能会有好几个线程要使用这个封装类发送自己的请求。要求是当长连接断开了,要调用建立长连接的方法,为了维护长连接的状态标记,就需要这么一个状态flag,类似于 boolean isConnected 这种变量。此时,也很符合一写多读的场景,那么这个变量就可以用volatile进行修饰。
class WebSocketClient {
volatile boolean isConnected = false;
public void connect() {
// ... do connect
if (success) {
isConnected = true;
}
}
public void disconnect() {
isConnected = false;
}
}
总结
volatile的作用是很微妙的,它并不能替代synchronized,因此它无法提供同步的能力,它只能提供改变 可见性 的能力。
由于总是读写与主存,它的读写性能要低于普通的变量。
正确使用的模式总结下来就是一个线程写,多个线程读。
但也不要过于迷信它的功效,大部分情况下,都完全不需要使用这个关键字的。
参考资料
下面是我查阅的资料,供大家在补充阅读以下哦
- on-properly-using-volatile-and-synchronized
- volatile-vs-synchronized
- volatile
- IBM: Managing volatility
如果你喜欢这篇文章,欢迎点赞评论打赏
更多干货内容,欢迎关注我的公众号:好奇码农君

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

