SRE 高延迟问题的罪魁祸首 System.gc()
01 案例一:
某日,支付平台的开发人员找到 SRE, 需要 SRE 帮助解决一个棘手的问题。 他们发现一个调用第三方支付接口的应用里面,偶尔出现请求超时的情况 。第三方平台保证他们的服务 99% 在 10 秒 内完成,算上网络传输时间, 15 秒 足够了,尽管支付平台设置的超时时间是 30 秒 ,但还是发生了超时的情况。
从最近一周日志的数据来看,大概每天出现 15~40 次超时问题。发生的时间也没有什么大致规律,有时同时出现 2~3 次,有时过 2 个小时才又出现一次。尽管客户只要重试几乎全部成功,并且这种请求错误出现的次数相对于总请求数比例极低,可这确实影响部分用户的支付体验。
出现的总数量虽相对不高,但影响用户体验的问题必须是大问题。
支付平台的小伙伴先是和这个外部支付公司联系, 根据我们提供的业务 ID, 该公司确认他们那边都是很快完成了支付,不存在超时的现象 。
那么还有一个可能是 中间的网络问题 ,网络先是通过我们的内网,然后是互联网,最后是他们的内网,这中间任何一步都有可能出现网络的抖动,导致我们的业务超时。
可是为什么又每天出现这么多次呢?因为网络问题涉及外网,并没有那么容易查清楚,并且每天分布的时间点并没有什么规律,所以支付平台的小伙伴转而找到 SRE 寻求帮助。
SRE 拿到这个问题之后,也感觉很棘手。这种超时问题,我们一般分为三段:
首先是服务提供者,它的处理时间变长,直接导致超时,这个问题中第三方已经确认他们并没有超时。
其次是中间的网络传输,这个问题中我们又跨越 3 段 网络:我们的内网,互联网和服务提供商的网络。任何一段出问题,都会导致问题超时,并且这里面有很多是我们很难拿到数据去诊断的。
再次是服务客户端,我们的代码里面偶尔也会出现使程序变慢的地方,但这也是我们最不容易去怀疑的地方,因为它是我们自己写的代码。
鉴于每天出现的数量和网络的不确定性,SRE 决定先排除我们这端代码的问题。这个应用有 几十台 服务器分布在 三个 数据中心,每个数据中心的服务器都出现过这种超时问题。平时这个业务都是在 5 秒 左右完成,但发生超时的时候等待 30 秒 都无法完成。
SRE 先是找到一个具体的错误日志,然后观察了那台服务器的各种监控指标,发现那台服务器的 GC 开销在出错的时间点左右有明显增高, 初步怀疑是 GC 导致的变慢 。
继而查看当时的 verbose GC 日志,确认那个时间点确实有 Full GC 发生,并且 Full GC 时间超过 30 秒 。不过发生的时间点上堆内存和永久代内存都有足够空闲, 于是怀疑是 System.gc() 导致的问题 。
又查看其它几个出错的例子, 发现一样的问题 。查看更长时间的 verbose GC 日志,发现这种 Full GC 对于每一台机器都是每隔 24 小时 出现一次。与服务启动成功时间对比,发现第一次发生的时间点正是服务刚启动之后的时间点,之后每天这个时间点再来一次。
开发人员搜索并确认了他们的代码中并没有明确的 System.gc() 调用 ,所以只能怀疑某个依赖库中存在这个调用。虽然确认的过程稍显复杂, 但是在 JVM 启动参数中添加 -XX:+DisableExplicitGC 后终于彻底解决了这个问题 。
02 案例二:
某日,监控平台上突然跳出一个新的报警,一个应用的 CPU 使用率突然达到了 60% 以上。SRE 查看这个应用的历史记录,发现之前它的 CPU 使用率基本在 5% 以下。智能的云监控平台已经检测到这个问题,并且已经尝试通过替换新机器的方式帮它去修复了。
SRE 并没有发现这个应用最近有什么新的 代码部署 ,也没有发现最近有新的 请求 URL 进入。联系开发人员,他们说可能上游最近有变动,发过来的请求内部有不同的参数,导致可能走不同的代码路径。
查看这个应用的监控指标数据,发现这个应用的 GC 开销明显提高, 是 GC 导致 JVM CPU 开销增加 。于是 SRE 查看了它的 verbose GC 日志,具体如图 1 所示:
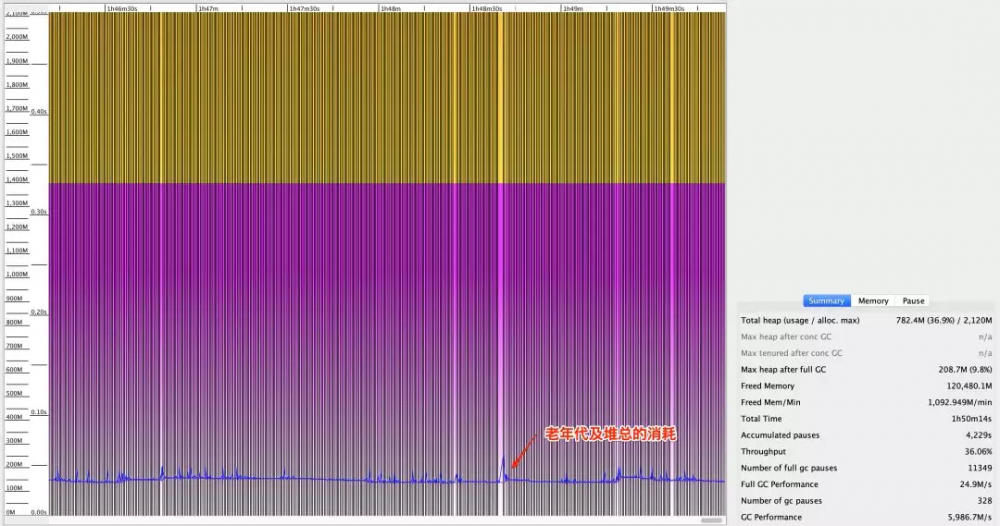
我们看到 堆空间有大量空闲,却频繁地在做 Full GC 。从图 2 的原始日志可以看到,永久代也有大量空闲内存。

于是我们通过 jstat 命令 查看了做 Full GC 的原因:

原来也是 System.gc() 方法导致的。也就是说新的代码路径里面有 System.gc() 的调用。和上面的问题一样,加上 **-XX:+DisableExplicitGC 参数 ** 后就修复了这个问题。
03 如何排查及修复
上面两个案例都是有人在代码中明确调用 System.gc() 导致的问题,并且都通过添加 JVM 启动参数 -XX:+DisableExplicitGC 得以解决。
那么如果真的想要从代码层面修复这个问题,怎么才能找到这段代码呢?
通常,如果这个调用发生在我们可控的 源代码 里,基本通过全文搜索或者借助 IDE 里面的方法调用查询,都能找到。
如果这个 System.gc() 调用在某个 依赖包 里面,如何才能找出来呢,这经常是比较麻烦的一步。 这里介绍两个方法:
- 如果这个应用可以 本地调试 ,只要开启 调试 (debug) 模式 ,然后在 System.gc() 方法上设置 断点 ,那么一旦运行到这一步,调试视图就会立马告诉你。
- 使用 FindBugs 工具 ,它能分析工程里面的源代码和依赖包,通过 DM_GC 这个规则就能查找出调用点。具体见图 4:

04 System.gc() 存在的必要性
System.gc() 方法一旦被调用并被执行,它将是一次 Full GC。Full GC 对于绝大多数 Hotspot JVM 实现里面已有的 GC 算法而言,将是一次相对比较长的 全局停顿(stop-the-world) 。
在一些对时延要求比较高的服务上,这将造成一定程度的不能满足 SLA 。甚至可能在瞬间因为客户端的超时,带来更多不必要的重试请求。正常情况下,JVM 都有自适应算法去判断什么时候需要做一次 GC,并且尽力避免 Full GC, 所以大多数情况下,不需要编程人员调用 System.gc() 方法 。
这并非说这个方法没有用处,在以下场景,这个方法能带来一些有益的效果:
1. 服务启动并初始化完成,在没有提供服务之前调用 System.gc()。这样可以回收掉启动过程中一些未来没必要存在的对象,大幅提高可用堆的数量,并且把一些对象从年轻代直接移到了老年代,不再需要经过多次在 Survival 空间来回移动才最终移到老年代。
2. 在做 heap dump 之前。这样回收掉一些已经没有被引用的对象,减少 heap 中没必要分析的对象。
3. 微观测试 (microbenchmark) 之前。减小由于测试当中可能出现 GC 过程引起的测试结果不正确。
05 总结
System.gc() 作为 Java 提供的一个方法,在如今 JVM 已经很智能的情况下,大多数时候已经不再需要我们明确去调用它。 一旦发生了延迟较长的情况,可以把这个方法的调用作为一个怀疑的对象 。通过一些具体的方法能够找到调用的点并且修复这个问题。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
https://mp.weixin.qq.com/s/Ivtfu4bH5vVd0KiAOonoCA
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

