增量同步-spring batch(6)动态参数绑定与增量同步
上一篇《 便捷的数据读写-spring batch(5)结合beetlSql进行数据读写
》中使用 Spring Batch
及 BeetlSql
,对数据库读写组件进行数据库同步,实际上是全量同步。全量同步的问题在于每次需要读取整个表数据,如果表数据量大,则资源耗费大,而且不便于对已有数据的更新。因此,在数据同步过程中,更多的使用增量同步,即通过某些条件,区分新数据进行插入,对有变化的数据进行更新,对不存在的数据进行删除等(当然,一般都不会对数据进行物理删除,只做逻辑删除,因此也就变成了数据更新操作)。
增量更新更多情况需要依据上一次更新后的状态(如时间、自增ID,数据位置等),下一次更新以上一次更新的状态为基础,因此,需要把每一次更新后的状态以变量参数的方式保存下来,下一次更新则以此状态数据为动态参数来使用。 Spring Batch
支持任务运行时的动态参数,结合此特性,可以实现数据的增量同步。
2.开发环境
- JDK: jdk1.8
- Spring Boot: 2.1.4.RELEASE
- Spring Batch:4.1.2.RELEASE
- 开发IDE: IDEA
- 构建工具Maven: 3.3.9
- 日志组件logback:1.2.3
- lombok:1.18.6
3.增量同步简述
增量同步,是相对与全量同步,即每次同步,只需要同步源数据库变化的部分,这样提高了数据同步的效率。是当前数据同步的普遍方式。抽取变化的数据,又名 CDC
,即 Change Data Capture
变化数据捕获。在 《Pentaho Kettle解决方案:使用PDI构建开源ETL解决方案 》
一书中,对 CDC
作了比较详细说明。此处简要做一下说明,当前实现增量同步的方式有4种,分别是基于源数据的 CDC
,基于触发器的 CDC
,基于快照的 CDC
,基于日志的 CDC
。
3.1 基于源数据的 CDC
基于源数据的 CDC
要求源数据里有相关的属性列,利用这些属性列,可以判断出哪里是增量数据,最常见的属性列有:
-
时间戳 基于时间来标识数据,至少需要一个时间,最好两个,一个标识创建,一个标识更新时间,所以一般我们设计数据库时都会添加
sys_create_time和sys_update_time作为默认字段,并且设计为默认当前时间和更新处理。 -
自增序列 使用数据库表的自增序列字段(一般是主键),来标识新插入的数据。不过现实中用得比较少。
此方法需要有一个临时表来保存上一次更新时间或,在实践中,一般是在独立的模式下创建此表,保存数据。下一次更新则比较上一次时间或序列。这是用得比较普遍的方式,本文中的增量同步也是使用此方法。
3.2 基于触发器的 CDC
在数据库中编写触发器,当前数据库执行 INSERT
, UPDATE
, DELETE
等语句时,可以激活数据库中的触发器,然后触发器可以把这些变更的数据保存到中间临时表,然后再从临时表中获取这些数据,同步到目标数据库中。当然,这种方法是入侵性最强的,一般数据库都不允许向数据库里添加触发器(影响性能)。
3.3 基于快照的 CDC
此方法就是一次抽取当前全部数据放到缓冲区,作为快照,下一次同步时从源数据读取数据,然后和快照做比较,找出变化的数据。简单来说是就做全表读取与比较,找出变化的数据。做全表扫描,问题就在于性能,所以一般不会使用这种方式。
3.4 基于日志的 CDC
最高级和最没有入侵性的方法就是基于日志的方式,数据库会把插入、更新、删除的操作记到日志中,如 Mysql
会有 binlog
,增量同步可以读取日志文件,把二进制文件转为可理解的方式,然后再把里面的操作按照顺序重做一遍。但是这种方式只能对同种数据库有效,对于异构的数据库就无法实现了。而且实现起来有一定的难度。
3.5 本示例增量同步方法说明
在本示例中,依然是基于 test_user
表进行增量同步,表有字段 sys_create_time
和 sys_update_time
来标识数据创建和更新时间(当前,若现实情况中只有一个时间,也可以只基于此时间,只是这样就比较难标识此数据是更新还是插入了)。增量同步流程如下:
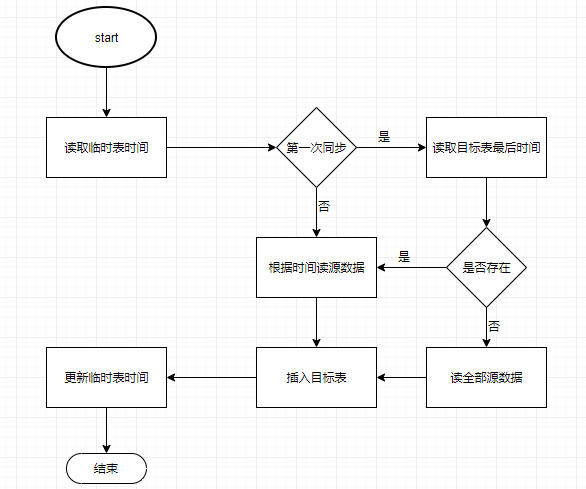
说明:
- 每次同步,会先读取临时表,获取上一次同步后数据的时间。
- 若是第一次同步,则全部同步,若不是,则根据时间作为查询语句的参数。
- 根据时间读取数据后,把数据插入目标表
- 更新临时表的数据时间,以便下一次同步。
4.Spring Batch动态参数绑定
根据上面的增量同步流程,关键点在于把数据时间保存到临时表,在数据读取时可以作为比较的条件。而这时间参数是动态的,在任务执行时才传递进去,在 Spring Batch
中,支持动态参数绑定,只需要使用 @StepScope
注解即可,结合 BeetlSql
,很快就可以实现增量同步。本示例是基于上一篇文章的示例来进一步开发的,可以 下载源码
查看完整示例。
4.1 沿用原来数据库配置和多数据源
mytest my_test1 my_spring_batch test_user
4.2 创建临时表
使用示例中的 sql/initCdcTempTable.sql
,在 my_spring_batch
库中,创建临时表 cdc_temp
,并插入记录为 1
的记录,标识是同步 test_user
表。此处,我们只需要关注 last_update_time
和 current_update_time
,前者表示上一次同步完后的数据最后时间,后者表示上一次同步后的系统时间。
4.3 添加/修改dao
4.3.1 添加临时表dao及service类
-
添加类
CdcTempRepository
根据配置,由于 cdc_temp
是在 my_spring_batch
,而它的读写是在 dao.local
包中,因此需要添加 dao.local
包,然后添加类 CdcTempRepository
,如下所示:
@Repository
public interface CdcTempRepository extends BaseMapper<CdcTemp> {
}
复制代码
-
添加类
CdcTempService,用于cdc_temp表的读取及数据更新 主要包括两个函数,一个是根据ID获取当前的cdc_temp记录,以便获取数据上一次同步的数据最后时间。一个是在同步完成后,更新cdc_temp的数据。如下:
/**
* 根据id获取cdc_temp的记录
* @param id 记录ID
* @return {@link CdcTemp}
*/
public CdcTemp getCurrentCdcTemp(int id){
return cdcTempRepository.getSQLManager().single(CdcTemp.class, id);
}
/**
* 根据参数更新cdcTemp表的数据
* @param cdcTempId cdcTempId
* @param status job状态
* @param lastUpdateTime 最后更新时间
*/
public void updateCdcTempAfterJob(int cdcTempId,BatchStatus status,Date lastUpdateTime){
//获取
CdcTemp cdcTemp = cdcTempRepository.getSQLManager().single(CdcTemp.class, cdcTempId);
cdcTemp.setCurrentUpdateTime(DateUtil.date());
//正常完成则更新数据时间
if( status == BatchStatus.COMPLETED){
cdcTemp.setLastUpdateTime(lastUpdateTime);
}else{
log.info(LogConstants.LOG_TAG+"同步状态异常:"+ status.toString());
}
//设置同步状态
cdcTemp.setStatus(status.name());
cdcTempRepository.updateById(cdcTemp);
}
复制代码
4.3.2 修改源数据dao
在源数据dao类 OriginUserRepository
添加函数 getOriginIncreUser
,此函数对应 user.md
中的 sql
语句。
4.3.3 修改目标数据dao
在目标数据dao类 TargetUserRepository
中添加函数 selectMaxUpdateTime
,用于查询同步后数据的最后时间。由于此方法的sql简单,可以直接使用 @Sql
注解,如下所示:
@Sql(value="select max(sys_update_time) from test_user") Date selectMaxUpdateTime(); 复制代码
4.4 修改 user.md
中的 sql
语句。
4.4.1 添加增量读数据sql
在 user.md
中添加增量读数据的sql语句,如下:
getOriginIncreUser
===
* 查询user数据
select * from test_user
WHERE 1=1
@if(!isEmpty(lastUpdateTime)){
AND (sys_create_time >= #lastUpdateTime# OR sys_update_time >= #lastUpdateTime#)
@}
复制代码
说明:
-
@开头是beetl的语法,可以对变量读取和逻辑判断,此处的意思是如果变量lastUpdateTime不为空,则按此条件进行读取。 -
lastUpdateTime变量由调用时传入(Map) -
具体
beetl使用语法,可参见官方文档
4.4.2 编写增量插入sql语句
对于 Mysql
数据库,有 insert into ... on duplicate key update ...
的用法,即可以根据唯一键(主键或唯一索引),若数据已存在,则更新,不存在,则插入。在 user.md
文件中,添加以下语句:
insertIncreUser
===
* 插入数据
insert into test_user(id,name,phone,title,email,gender,date_of_birth,sys_create_time,sys_create_user,sys_update_time,sys_update_user)
values (#id#,#name#,#phone#,#title#,#email#,#gender#,#dateOfBirth#
,#sysCreateTime#,#sysCreateUser#,#sysUpdateTime#,#sysUpdateUser#)
ON DUPLICATE KEY UPDATE
id = VALUES(id),
name = VALUES(name),
phone = VALUES(phone),
title = VALUES(title),
email = VALUES(email),
gender = VALUES(gender),
date_of_birth = VALUES(date_of_birth),
sys_create_time = VALUES(sys_create_time),
sys_create_user = VALUES(sys_create_user),
sys_update_time = VALUES(sys_update_time),
sys_update_user = VALUES(sys_update_user)
复制代码
4.5 编写Spring Batch的组件
Spring Batch
文件结构如下:
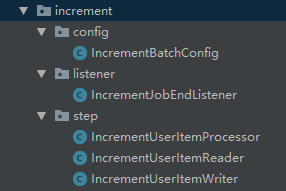
4.5.1 ItemReader
此处与之前的一致,只需要把 getOriginUser
函数改为 getOriginIncreUser
即可。
4.5.2 ItemWriter
此处与之前的一致,只需要把sql的ID由 user.insertUser
改为 user.insertIncreUser
即可。
4.5.3 添加 IncrementJobEndListener
由于数据同步完后,最后一步就是要更新临时表的最后时间数据。如下:
@Slf4j
public class IncrementJobEndListener extends JobExecutionListenerSupport {
@Autowired
private CdcTempService cdcTempService;
@Autowired
private TargetUserRepository targetUserRepository;
@Override
public void afterJob(JobExecution jobExecution) {
BatchStatus status = jobExecution.getStatus();
Date latestDate = targetUserRepository.selectMaxUpdateTime();
cdcTempService.updateCdcTempAfterJob(SyncConstants.CDC_TEMP_ID_USER,status,latestDate);
}
}
复制代码
说明:
-
先查询当前数据库中数据最后时间(
selectMaxUpdateTime) -
更新中间表数据
cdc_temp中的last_update_time
4.5.4 添加任务启动时参数初始化
在数据同步的第一步,需要先初始化临时表中的数据最后更新时间,因此在任务启动前,先要进行任务参数设置,以便于把时间参数传到任务中,在任务执行时使用。如下:
public JobParameters initJobParam(){
CdcTemp currentCdcTemp = cdcTempService.getCurrentCdcTemp(getCdcTempId());
//若未初始化,则先查询数据库中对应的最后时间
if(SyncConstants.STR_STATUS_INIT.equals(currentCdcTemp.getStatus())
|| SyncConstants.STR_STATUS_FAILED.equals(currentCdcTemp.getStatus())){
Date maxUpdateTime = selectMaxUpdateTime();
//若没有数据,则按初始时间处理
if(Objects.nonNull(maxUpdateTime)){
currentCdcTemp.setLastUpdateTime(maxUpdateTime);
}
}
return JobUtil.makeJobParameters(currentCdcTemp);
}
复制代码
4.5.5 组装完整任务
最后,需要一个 IncrementBatchConfig
配置把读、处理、写、监听组装起来,值得一提的是,在配置读组件时,由于需要使用动态参数,此处需要添加 @StepScope
注解,同时在参数中使用 spEL
获取参数内容,如下所示:
@Bean
@StepScope
public ItemReader incrementItemReader(@Value("#{jobParameters['lastUpdateTime']}") String lastUpdateTime) {
IncrementUserItemReader userItemReader = new IncrementUserItemReader();
//设置参数,当前示例可不设置参数
Map<String,Object> params = CollUtil.newHashMap();
params.put(SyncConstants.STR_LAST_UPDATE_TIME,lastUpdateTime);
userItemReader.setParams(params);
return userItemReader;
}
复制代码
4.5.6 测试
参考上一文章的 BeetlsqlJobTest
,编写 IncrementJobTest
测试文件。由于需要测试增量同步,测试流程如下所示:
-
测试前增量添加数据
测试前,源数据表和目标数据表已经有数据,在源数据表中,执行代码中的
sql/user-data-new.sql添加新的用户。注意,由于sys_create_time和sys_update_time定义如下:
sys_create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `sys_update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, 复制代码
从而达到数据插入时自动生成时间,修改时也自动更新时间。
-
运行测试 以单元测试运行
incrementJob。 -
查看结果 运行完成后,结果如下:
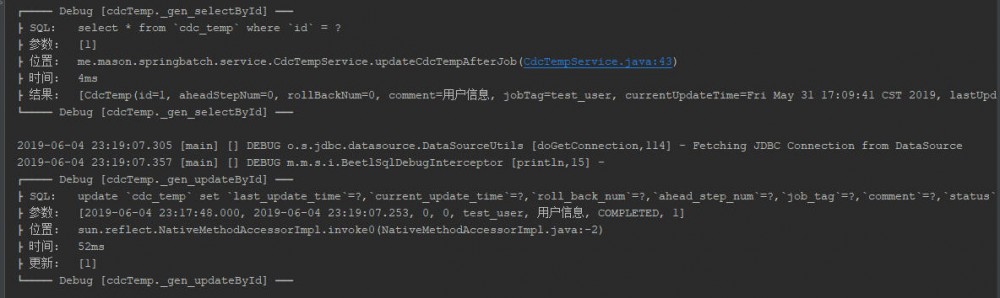
增量同步后,数据如下:

5.总结
本文先对增量同步做了一个简单的介绍,列出当前一般使用的增量同步方法,然后使用 Spring Batch
和 BeetlSql
使用基于时间戳的方式实现增量同步,本示例具有一定的实用性,希望能对做数据同步或相关批处理的开发者有帮助。
正文到此结束
- 本文标签: 配置 id value 测试 删除 tar bean 代码 equals 总结 maven Spring Batch map 希望 key 2019 update http constant IDE 索引 开发 db 下载 sql IO Select tag spring src CDN Service 数据 HashMap 参数 tab 文章 cat 自动生成 App Logback mysql 同步 https Listeners 开发者 Spring Boot list 源码 ACE 数据库 mapper 时间 单元测试 开源 mail Job
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

