XML解析详解|乐字节
大家好,乐字节的小乐又来了,Java技术分享哪里少的了小乐!上次我们说了可扩展标记语言XML之二:XML语言格式规范、文档组成,本文将介绍重点——XML解析。
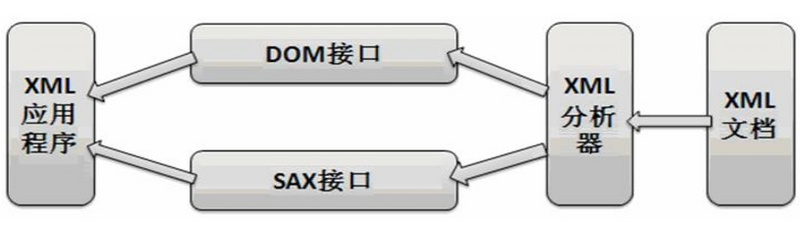
基本的解析方式有两种:一种叫 SAX,另一种叫 DOM。
SAX(Simple API for XML)是基于 事件流的解析,DOM(Document Object Model)是基于 XML 文档树结构的解析。SAX:效 率高,数据量小,仅一次获取 。
DOM:整颗树加载到内存中,耗内存,可多次获取。
一、DOM 解析
与 js 中的类似,使用 JAXP(Java API for XML Parsing),即:用于 XML 解析的 Java API.
DOM(Document Object Model, 文档对象模型),在应用程序中,基于 DOM 的 XML
分析器将一个 XML 文档转换成一个对象模型的集合(通常称为 DOM 树),应用程序正是通过对这个对象模型的操作,来实现对 XML 文档数据的操作。
XML 本身是以树状的形式出现的,所以 DOM 操作的时候,也将按章树的形式进行转换。 在整个 DOM 树种,最大的地方指的是 Document,表示一个文档,在这个文档中存在一个根节点。
注意:在使用 DOM 操作的时候,每一个文字的区域也是一个节点,称为文本节点。
1、核心操作接口
在 DOM 解析中有以下四个核心的操作接口
Document : 此接口代表了整个 XML 文档,表示的是整棵 DOM 树的根,提供了对文档中的数据进行访问和操作的入口,通过 Document 节点可以访问 XML 文件中所有的元素内容。
Node : 此接口在整个 DOM 树种具有举足轻重的低位,DOM 操作的核心接口中有很大 一部分接口是从 Node 接口继承过来的。例如:Document、Element 等接口,在 DOM 树种,每一个 Node 接口代表了 DOM 树种的一个节点。
NodeList : 此接口表示的是一个节点的集合,一般用于表示有顺序关系的一组节点,
例如:一个节点的子节点,当文档改变的时候会直接影响到 NodeList 集合。
NamedNodeMap : 此接口表示的是一组节点和其唯一名字对应的一一对应关系,本
接口主要用于属性节点的表示上。
2、DOM 解析过程
如果一个程序需要进行 DOM 解析读取操作的话,也需要按照如下的步骤进行:
① 建 立 DocumentBuilderFactory : DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
②建立 DocumentBuilder: DocumentBuilder builder = factory.newDocumentBuilder();
③建立 Document : Document doc = builder.parse(“要解析的文件路径”);
④建立 NodeList : NodeList nl = doc.getElementsByTagName(“读取节点”);
⑤进行 XML 信息读取
DOM 操作除了可以进行解析外,也可以进行文档的生成
如果想要生成 XML 文件,则在创建文档的时候,就应该使用 newDocument()方法
如果要将 DOM 的文档输出,本身是比较麻烦的 。一次编写多次 copy
public static void createXml() throws Exception{
//获取解析器工厂
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
//获取解析器
DocumentBuilder builder=factory.newDocumentBuilder();
//创建文档
Document doc=builder.newDocument();
//创建元素、设置关系
Element root=doc.createElement("people");
Element person=doc.createElement("person");
Element name=doc.createElement("name");
Element age=doc.createElement("age");
name.appendChild(doc.createTextNode("shsxt"));
age.appendChild(doc.createTextNode("10"));
doc.appendChild(root);
root.appendChild(person);
person.appendChild(name);
person.appendChild(age);
//写出去
// 获得变压器工厂
TransformerFactory tsf=TransformerFactory.newInstance();
Transformer ts=tsf.newTransformer();
//设置编码
ts.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//创建带有DOM节点的新输入源,充当转换Source树的持有者
DOMSource source=new DOMSource(doc);
//充当转换结果的持有者
File file=new File("src/output.xml");
StreamResult result=new StreamResult(file);
ts.transform(source, result);
}
二、SAX 解析
SAX(Simple API for XML)解析是按照 xml 文件的顺序一步一步的来解析。SAX 没有官方 的标准机构,它不属于任何标准阻止或团体,也不属于任何公司或个人,而是提供任何 人使用的一种计算机技术。
SAX(Simple API for XML,操作 XML 的简单接口),与 DOM 操作不同的是,SAX 采用的 是一种顺序的模式进行访问,是一种快速读取 XML 数据的方式。当使用 SAX 解析器进行操作的时候会触发一系列的事情,当扫描到文档(document)开始与结束、元素 (element)开始与结束时都会调用相关的处理方法,并由这些操作方法作出相应的操 作,直至整个文档扫描结束。
如果要想实现这种 SAX 解析,则肯定首先建立一个 SAX 的解析器
// 1、创建解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2、获得解析器
SAXParser parser = factory.newSAXParser();
// SAX解析器 ,继承 DefaultHandler
String path = new File("resource/demo01.xml").getAbsolutePath();
// 解析
parser.parse(path, new MySaxHandler());
三、DOM4j 解析
dom4j 是一个简单的开源库,用于处理 XML、 XPath 和 XSLT,它基于 Java 平台,使用 Java 的集合框架,全面集成了 DOM,SAX 和 JAXP。下载路径:
http://www.dom4j.org/dom4j-1....
http://sourceforge.net/projec...
可以使用 DOM4J 进行 XML 文件的读、写操作
DOM4J 与 JDOM 一样都属于一个免费的 XML 开源组建,但是由于现在的开发框架中使 用该技术较多,比如 Hibernate、Spring 等都使用 DOM4J 这个功能,所以作为介绍, 大家可以对该组件有一个了解。并没有谁好谁坏,一般框架使用 DOM4J 较多,而我们平时如果要用则 JDOM 较常见。 可以发现 DOM4J 发挥了很多新特性,比如输出格式就可以很好解析。
File file = new File("resource/outputdom4j.xml");
SAXReader reader = new SAXReader();
// 读取文件作为文档
Document doc = reader.read(file);
// 获取文档的根元素
Element root = doc.getRootElement();
// 根据跟元素找到全部的子节点
Iterator<Element> iter = root.elementIterator();
while(iter.hasNext()){
Element name = iter.next();
System.out.println("value = " + name.getText());
}
创建
// 使用DocumentHelper来创建 Document对象
Document document = DocumentHelper.createDocument();
// 创建元素并设置关系
Element person = document.addElement("person");
Element name = person.addElement("name");
Element age = person.addElement("age");
// 设置文本
name.setText("shsxt");
age.setText("10");
// 创建格式化输出器
OutputFormat of = OutputFormat.createPrettyPrint();
of.setEncoding("utf-8");
// 输出到文件
File file = new File("resource/outputdom4j.xml");
XMLWriter writer = new XMLWriter(new FileOutputStream(new
File(file.getAbsolutePath())),of);
// 写出
writer.write(document);
writer.flush();
writer.close();
四、JDOM 解析
下载路径: http://www.jdom.org/downloads...
JDOM 是一种使用 XML 的独特 Java 工具包,用于快速开发 XML 应用程序。JDOM 是一个开源项目,它基于树形结构,利用纯 Java 的技术对 XML 文档实现解析、生成、序列 化及多种操作。
JDOM 解析
掌握 JDOM 开发工具的使用及产生原理
可以使用 JDOM 进行读取或写入的操作
在 W3C 本身提供的 XML 操作标准,DOM 和 SAX,但是从开发角度上看,DOM 和 SAX
本身是各有特点的,DOM 可以修改,但不适合读取大文件,而 SAX 可以读取大文件,
但是本身不能修改所谓的 JDOM = DOM 的可修改 + SAX 的读取大文件 。
JDOM 本身是一个免费的开源组建,直接从 http://www.jdom.org 上下载 ,下载后解压,将 jdom.jar 包拷贝到 Tomcat 目录(项目)的 lib 中 。
JDOM 主要操作的类:
我们发现 JDOM 的输出操作要比传统的 DOM 方便得多,而且也更加直观,包括在输出
的时候都很容易了。
此时观察到的是 JDOM 对于 DOM 解析的支持,但是也说,JDOM 本身也支持了 SAX 的
特点;所以,可以使用 SAX 进行解析操作。
解析
// 获取SAX解析器
SAXBuilder builder = new SAXBuilder();
File file = new File("resource/demo01.xml");
// 获取文档
Document doc = builder.build(new File(file.getAbsolutePath()));
// 获取根节点
Element root = doc.getRootElement();
System.out.println(root.getName());
// 获取根节点下所有的子节点, 也可以根据标签名称获取指定的直接点
List<Element> list = root.getChildren();
System.out.println(list.size());
for(int x = 0; x<list.size(); x++){
Element e = list.get(x);
// 获取元素的名称和里面的文本
String name = e.getName();
System.out.println(name + "=" + e.getText());
System.out.println("==================");
}
创建
// 创建节点
Element person = new Element("person");
Element name = new Element("name");
Element age = new Element("age");
// 创建属性
Attribute id = new Attribute("id","1");
// 设置文本
name.setText("shsxt");
age.setText("10");
// 设置关系
Document doc = new Document(person);
person.addContent(name);
name.setAttribute(id);
person.addContent(age);
XMLOutputter out = new XMLOutputter();
File file = new File("resource/outputjdom.xml");
out.output(doc, new FileOutputStream(file.getAbsoluteFile()));
关于XML解析先讲到这里了,请继续关注乐字节,后续Java超级干货奉上,快快乐乐学Java。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

