MyBatis 二级缓存详解
我们在上一篇文章介绍了 MyBatis 的一级缓存的作用,如何开启,一级缓存的本质是什么,一级缓存失效的原因是什么?MyBatis 只有一级缓存吗?来找找答案吧!
MyBatis 二级缓存介绍
上一篇文章中我们介绍到了 MyBatis 一级缓存其实就是 SqlSession 级别的缓存,什么是 SqlSession 级别的缓存呢?一级缓存的本质是什么呢?以及一级缓存失效的原因?我希望你在看下文之前能够回想起来这些内容。
MyBatis 一级缓存最大的共享范围就是一个SqlSession内部,那么如果多个 SqlSession 需要共享缓存,则需要开启二级缓存,开启二级缓存后,会使用 CachingExecutor 装饰 Executor,进入一级缓存的查询流程前,先在CachingExecutor 进行二级缓存的查询,具体的工作流程如下所示
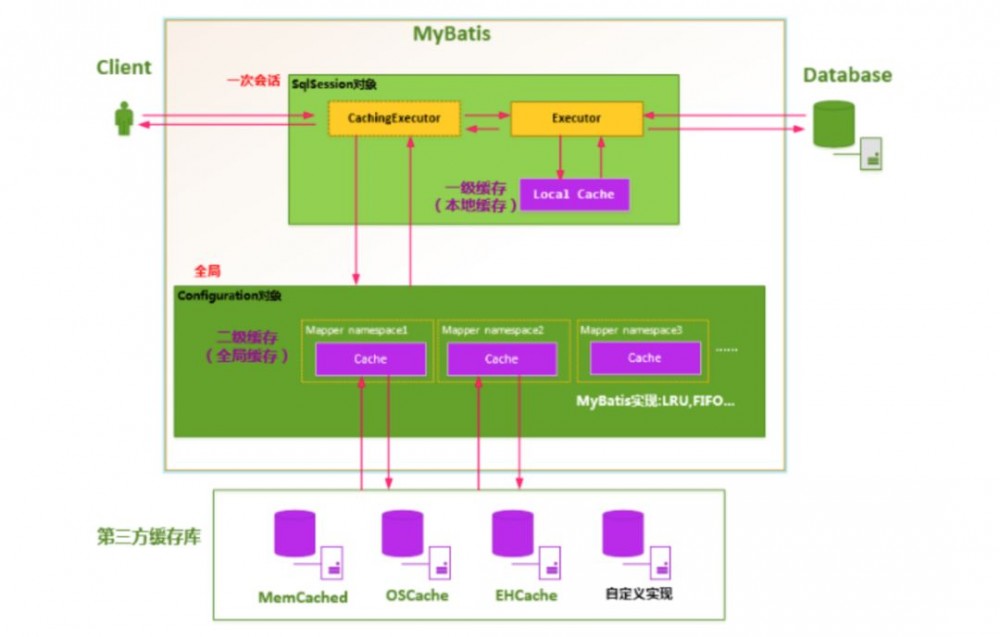
当二级缓存开启后,同一个命名空间(namespace) 所有的操作语句,都影响着一个 共同的 cache ,也就是二级缓存被多个 SqlSession 共享,是一个 全局的变量 。当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
二级缓存开启条件
二级缓存默认是不开启的,需要手动开启二级缓存,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。开启二级缓存的条件也是比较简单,通过直接在 MyBatis 配置文件中通过
<settings>
<setting name = "cacheEnabled" value = "true" />
</settings>
来开启二级缓存,还需要在 Mapper 的xml 配置文件中加入 <cache> 标签
设置 cache 标签的属性
cache 标签有多个属性,一起来看一些这些属性分别代表什么意义
-
eviction: 缓存回收策略,有这几种回收策略
-
LRU - 最近最少回收,移除最长时间不被使用的对象
-
FIFO - 先进先出,按照缓存进入的顺序来移除它们
-
SOFT - 软引用,移除基于垃圾回收器状态和软引用规则的对象
-
WEAK - 弱引用,更积极的移除基于垃圾收集器和弱引用规则的对象
默认是 LRU 最近最少回收策略
-
flushinterval 缓存刷新间隔,缓存多长时间刷新一次,默认不清空,设置一个毫秒值
-
readOnly : 是否只读; true 只读 ,MyBatis 认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。MyBatis 为了加快获取数据,直接就会将数据在缓存中的引用交给用户。不安全,速度快。 读写(默认) :MyBatis 觉得数据可能会被修改
-
size : 缓存存放多少个元素
-
type : 指定自定义缓存的全类名(实现Cache 接口即可)
-
blocking :若缓存中找不到对应的key,是否会一直blocking,直到有对应的数据进入缓存。
探究二级缓存
我们继续以 MyBatis 一级缓存文章中的例子为基础,搭建一个满足二级缓存的例子,来对二级缓存进行探究,例子如下(对 一级缓存的例子部分源码进行修改):
Dept.java
//存放在共享缓存中数据进行序列化操作和反序列化操作
//因此数据对应实体类必须实现【序列化接口】并提供 无参数的构造方法
public class Dept implements Serializable
myBatis-config.xml
在myBatis-config 中添加开启二级缓存的条件
<setting name="cacheEnabled" value="true"/>
DeptDao.xml
还需要在 Mapper 对应的xml中添加 cache 标签,表示对哪个mapper 开启缓存 <cache>
对应的二级缓存测试类如下:
public class MyBatisSecondCacheTest {
private SqlSession sqlSession;
SqlSessionFactory factory;
@Before
public void start() throws IOException {
InputStream is = Resources.getResourceAsStream("myBatis-config.xml");
SqlSessionFactoryBuilder builderObj = new SqlSessionFactoryBuilder();
factory = builderObj.build(is);
sqlSession = factory.openSession();
}
@After
public void destory(){
if(sqlSession!=null){
sqlSession.close();
}
}
@Test
public void testSecondCache(){
//会话过程中第一次发送请求,从数据库中得到结果
//得到结果之后,mybatis自动将这个查询结果放入到当前用户的一级缓存
DeptDao dao = sqlSession.getMapper(DeptDao.class);
Dept dept = dao.findByDeptNo(1);
System.out.println("第一次查询得到部门对象 = "+dept);
//触发MyBatis框架从当前一级缓存中将Dept对象保存到二级缓存
sqlSession.commit();
// 改成 sqlSession.close(); 效果相同
SqlSession session2 = factory.openSession();
DeptDao dao2 = session2.getMapper(DeptDao.class);
Dept dept2 = dao2.findByDeptNo(1);
System.out.println("第二次查询得到部门对象 = "+dept2);
}
}
测试二级缓存效果,提交事务, sqlSession 查询完数据后, sqlSession2 相同的查询是否会从缓存中获取数据。
测试结果如下:
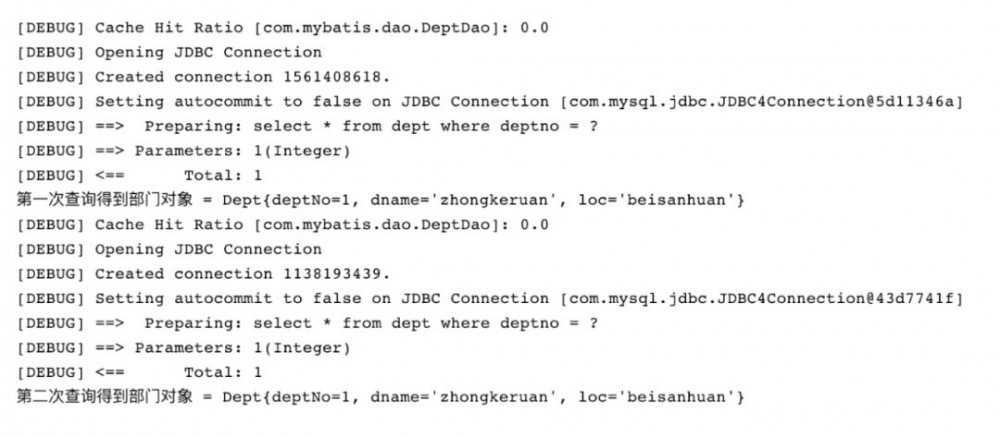
通过结果可以得知,首次执行的SQL语句是从数据库中查询得到的结果,然后第一个 SqlSession 执行提交,第二个 SqlSession 执行相同的查询后是从缓存中查取的。
用一下这幅图能够比较直观的反映两次 SqlSession 的缓存命中

二级缓存失效的条件
与一级缓存一样,二级缓存也会存在失效的条件的,下面我们就来探究一下哪些情况会造成二级缓存失效
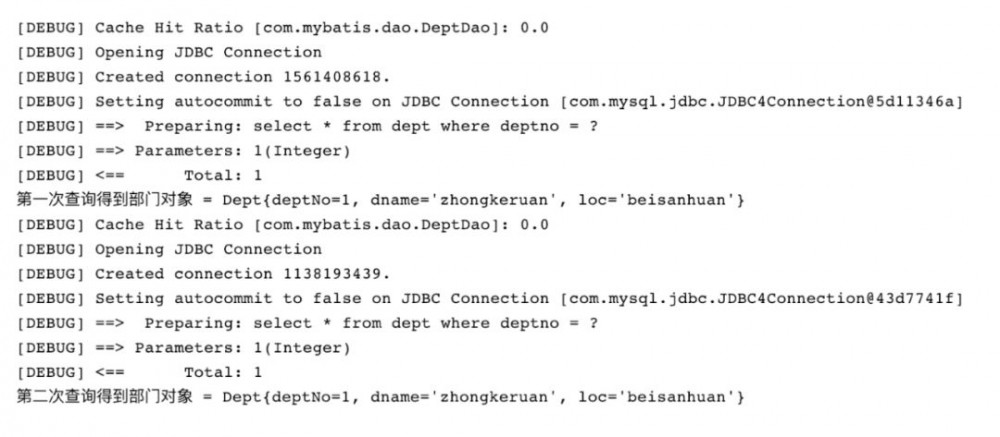
第一次SqlSession 未提交
SqlSession 在未提交的时候,SQL 语句产生的查询结果还没有放入二级缓存中,这个时候 SqlSession2 在查询的时候是感受不到二级缓存的存在的,修改对应的测试类,结果如下:
@Test
public void testSqlSessionUnCommit(){
//会话过程中第一次发送请求,从数据库中得到结果
//得到结果之后,mybatis自动将这个查询结果放入到当前用户的一级缓存
DeptDao dao = sqlSession.getMapper(DeptDao.class);
Dept dept = dao.findByDeptNo(1);
System.out.println("第一次查询得到部门对象 = "+dept);
//触发MyBatis框架从当前一级缓存中将Dept对象保存到二级缓存
SqlSession session2 = factory.openSession();
DeptDao dao2 = session2.getMapper(DeptDao.class);
Dept dept2 = dao2.findByDeptNo(1);
System.out.println("第二次查询得到部门对象 = "+dept2);
}
产生的输出结果:
更新对二级缓存影响
与一级缓存一样,更新操作很可能对二级缓存造成影响,下面用三个 SqlSession来进行模拟,第一个 SqlSession 只是单纯的提交,第二个 SqlSession 用于检验二级缓存所产生的影响,第三个 SqlSession 用于执行更新操作,测试如下:
@Test
public void testSqlSessionUpdate(){
SqlSession sqlSession = factory.openSession();
SqlSession sqlSession2 = factory.openSession();
SqlSession sqlSession3 = factory.openSession();
// 第一个 SqlSession 执行更新操作
DeptDao deptDao = sqlSession.getMapper(DeptDao.class);
Dept dept = deptDao.findByDeptNo(1);
System.out.println("dept = " + dept);
sqlSession.commit();
// 判断第二个 SqlSession 是否从缓存中读取
DeptDao deptDao2 = sqlSession2.getMapper(DeptDao.class);
Dept dept2 = deptDao2.findByDeptNo(1);
System.out.println("dept2 = " + dept2);
// 第三个 SqlSession 执行更新操作
DeptDao deptDao3 = sqlSession3.getMapper(DeptDao.class);
deptDao3.updateDept(new Dept(1,"ali","hz"));
sqlSession3.commit();
// 判断第二个 SqlSession 是否从缓存中读取
dept2 = deptDao2.findByDeptNo(1);
System.out.println("dept2 = " + dept2);
}
对应的输出结果如下

探究多表操作对二级缓存的影响
现有这样一个场景,有两个表,部门表dept(deptNo,dname,loc)和 部门数量表deptNum(id,name,num),其中部门表的名称和部门数量表的名称相同,通过名称能够联查两个表可以知道其坐标(loc)和数量(num),现在我要对部门数量表的 num 进行更新,然后我再次关联dept 和 deptNum 进行查询,你认为这个 SQL 语句能够查询到的 num 的数量是多少?来看一下代码探究一下
public class DeptNum {
private int id;
private String name;
private int num;
get and set...
}
public class DeptVo {
private Integer deptNo;
private String dname;
private String loc;
private Integer num;
public DeptVo(Integer deptNo, String dname, String loc, Integer num) {
this.deptNo = deptNo;
this.dname = dname;
this.loc = loc;
this.num = num;
}
public DeptVo(String dname, Integer num) {
this.dname = dname;
this.num = num;
}
get and set...
toString()...
}
public interface DeptDao {
// ...其他方法
DeptVo selectByDeptVo(String name);
DeptVo selectByDeptVoName(String name);
int updateDeptVoNum(DeptVo deptVo);
}
<select id="selectByDeptVo" resultType="com.mybatis.beans.DeptVo">
select d.deptno,d.dname,d.loc,dn.num from dept d,deptNum dn where dn.name = d.dname
and d.dname = #{name}
</select>
<select id="selectByDeptVoName" resultType="com.mybatis.beans.DeptVo">
select * from deptNum where name = #{name}
</select>
<update id="updateDeptVoNum" parameterType="com.mybatis.beans.DeptVo">
update deptNum set num = #{num} where name = #{dname}
</update>
DeptNum 数据库初始值:

/**
* 探究多表操作对二级缓存的影响
*/
@Test
public void testOtherMapper(){
// 第一个mapper 先执行联查操作
SqlSession sqlSession = factory.openSession();
DeptDao deptDao = sqlSession.getMapper(DeptDao.class);
DeptVo deptVo = deptDao.selectByDeptVo("ali");
System.out.println("deptVo = " + deptVo);
// 第二个mapper 执行更新操作 并提交
SqlSession sqlSession2 = factory.openSession();
DeptDao deptDao2 = sqlSession2.getMapper(DeptDao.class);
deptDao2.updateDeptVoNum(new DeptVo("ali",1000));
sqlSession2.commit();
sqlSession2.close();
// 第一个mapper 再次进行查询,观察查询结果
deptVo = deptDao.selectByDeptVo("ali");
System.out.println("deptVo = " + deptVo);
}
测试结果如下:

在对DeptNum 表执行了一次更新后,再次进行联查,发现数据库中查询出的还是 num 为 1050 的值,也就是说,实际上 1050 -> 1000 ,最后一次联查实际上查询的是第一次查询结果的缓存,而不是从数据库中查询得到的值,这样就读到了脏数据。
解决办法
如果是两个mapper命名空间的话,可以使用 <cache-ref> 来把一个命名空间指向另外一个命名空间,从而消除上述的影响,再次执行,就可以查询到正确的数据
二级缓存源码解析
源码模块主要分为两个部分:二级缓存的创建和二级缓存的使用,首先先对二级缓存的创建进行分析:
二级缓存的创建
二级缓存的创建是使用 Resource 读取 XML 配置文件开始的
InputStream is = Resources.getResourceAsStream("myBatis-config.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(is);
读取配置文件后,需要对XML创建 Configuration并初始化
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
调用 parser.parse() 解析根目录 /configuration 下面的标签,依次进行解析
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
其中有一个二级缓存的解析就是
mapperElement(root.evalNode("mappers"));
然后进去 mapperElement 方法中
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
继续跟 mapperParser.parse() 方法
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
这其中有一个 configurationElement 方法,它是对二级缓存进行创建,如下
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e);
}
}
有两个二级缓存的关键点
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
也就是说,mybatis 首先进行解析的是 cache-ref 标签,其次进行解析的是 cache 标签。
根据上面我们的 — 多表操作对二级缓存的影响 一节中提到的解决办法,采用 cache-ref 来进行命名空间的依赖能够避免二级缓存 ,但是总不能每次写一个 XML 配置都会采用这种方式吧,最有效的方式还是避免多表操作使用二级缓存
然后我们再来看一下cacheElement(context.evalNode("cache")) 这个方法
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
认真看一下其中的属性的解析,是不是感觉很熟悉?这不就是对 cache 标签属性的解析吗?!!!
上述最后一句代码
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
这段代码使用了构建器模式,一步一步构建Cache 标签的所有属性,最终把 cache 返回。
二级缓存的使用
在 mybatis 中,使用 Cache 的地方在 CachingExecutor 中,来看一下 CachingExecutor 中缓存做了什么工作,我们以查询为例
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 得到缓存
Cache cache = ms.getCache();
if (cache != null) {
// 如果需要的话刷新缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 委托模式,交给SimpleExecutor等实现类去实现方法。
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
其中,先从 MapperStatement 取出缓存。只有通过 <cache/>,<cache-ref/> 或 @CacheNamespace,@CacheNamespaceRef 标记使用缓存的Mapper.xml或Mapper接口(同一个namespace,不能同时使用)才会有二级缓存。
如果缓存不为空,说明是存在缓存。如果cache存在,那么会根据sql配置( <insert>,<select>,<update>,<delete> 的 flushCache 属性来确定是否清空缓存。
flushCacheIfRequired(ms);
然后根据xml配置的属性 useCache 来判断是否使用缓存(resultHandler一般使用的默认值,很少会null)。
if (ms.isUseCache() && resultHandler == null)
确保方法没有Out类型的参数,mybatis不支持存储过程的缓存,所以如果是存储过程,这里就会报错。
private void ensureNoOutParams(MappedStatement ms, Object parameter, BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
throw new ExecutorException("Caching stored procedures with OUT params is not supported. Please configure useCache=false in " + ms.getId() + " statement.");
}
}
}
}
然后根据在 TransactionalCacheManager 中根据 key 取出缓存,如果没有缓存,就会执行查询,并且将查询结果放到缓存中并返回取出结果,否则就执行真正的查询方法。
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
是否应该使用二级缓存?
那么究竟应该不应该使用二级缓存呢?先来看一下二级缓存的注意事项:
1. 缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响。
2. insert,update,delete操作会清空所在 namespace 下的全部缓存。
3. 通常使用MyBatis Generator生成的代码中,都是各个表独立的,每个表都有自己的 namespace 。
4. 多表操作一定不要使用二级缓存,因为多表操作进行更新操作,一定会产生脏数据。
如果你遵守二级缓存的注意事项,那么你就可以使用二级缓存。
但是,如果不能使用多表操作,二级缓存不就可以用一级缓存来替换掉吗?而且二级缓存是表级缓存,开销大,没有一级缓存直接使用 HashMap 来存储的效率更高,所以 二级缓存并不推荐使用 。
文章参考:
[聊聊MyBatis缓存机制](https://tech.meituan.com/2018/01/19/mybatis-cache.html)
[mybatis一级缓存二级缓存](https://www.cnblogs.com/happyflyingpig/p/7739749.html)
深入了解MyBatis二级缓存 https://blog.csdn.net/isea533/article/details/44566257
End
如有收获,请帮忙转发, 您的鼓励 是作者最大的动力!
欢迎长按下图关注公众号 Java极客技术 ,后台回复“ 资料 ”,获取作者独家秘制精品资料

Java 极客技术公众号,是由一群热爱 Java 开发的技术人组建成立,专注分享原创、高质量的 Java 文章。 如果您觉得我们的文章还不错,请帮忙赞赏、在看、转发支持,鼓励我们分享出更好的文章。

正文到此结束
- 本文标签: 代码 Select 开发 Action executor 本质 stream java 质量 sql SDN parse mybatis缓存 文章 cache 专注 zab 目录 db 安全 解析 参数 ACE plugin id 缓存 node cat NSA HTML mybatis http sqlsession 希望 Statement tab 数据库 IDE App list DDL mapper 垃圾回收 构造方法 源码 find 数据 CTO value src SqlSessionFactory IO equals 测试 tar UI 空间 key build SqlSessionFactoryBuilder 一级缓存 session root 配置 时间 XML provider bean 二级缓存 HashMap update https map
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

