《Java 8 in Action》Chapter 6:用流收集数据
1. 收集器简介
collect() 接收一个类型为 Collector 的参数,这个参数决定了如何把流中的元素聚合到其它数据结构中。Collectors 类包含了大量常用收集器的工厂方法,toList() 和 toSet() 就是其中最常见的两个,除了它们还有很多收集器,用来对数据进行对复杂的转换。
指令式代码和函数式对比:
要是做多级分组,指令式和函数式之间的区别就会更加明显:由于需要好多层嵌套循环和条件,指令式代码很快就变得更难阅读、更难维护、更难修改。相比之下,函数式版本只要再加上 一个收集器就可以轻松地增强
预定义收集器,也就是那些可以从Collectors类提供的工厂方法(例如groupingBy)创建的收集器。它们主要提供了三大功能:
- 将流元素归约和汇总为一个值
- 元素分组
- 元素分区
2. 使用收集器
在需要将流项目重组成集合时,一般会使用收集器(Stream方法collect 的参数)。再宽泛一点来说,但凡要把流中所有的项目合并成一个结果时就可以用。这个结果可以是任何类型,可以复杂如代表一棵树的多级映射,或是简单如一个整数。
3. 收集器实例
3.1 流中最大值和最小值
Collectors.maxBy和 Collectors.minBy,来计算流中的最大或最小值。这两个收集器接收一个Comparator参数来比较流中的元素。你可以创建一个Comparator来根据所含热量对菜肴进行比较:
System.out.println("找出热量最高的食物:");
Optional<Dish> collect = DataUtil.genMenu().stream().collect(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)));
collect.ifPresent(System.out::println);
System.out.println("找出热量最低的食物:");
Optional<Dish> collect1 = DataUtil.genMenu().stream().collect(Collectors.minBy(Comparator.comparingInt(Dish::getCalories)));
collect1.ifPresent(System.out::println);
3.2 汇总求和
Collectors类专门为汇总提供了一个工厂方法:Collectors.summingInt。它可接受一个把对象映射为求和所需int的函数,并返回一个收集器;该收集器在传递给普通的collect方法后即执行我们需要的汇总操作。举个例子来说,你可以这样求出菜单列表的总热量:
Integer collect = DataUtil.genMenu().stream().collect(Collectors.summingInt(Dish::getCalories));
System.out.println("总热量:" + collect);
Double collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.summingDouble(Double::doubleValue));
System.out.println("double和:" + collect1);
Long collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.summingLong(Long::longValue));
System.out.println("long和:" + collect2);
3.3 汇总求平均值
Collectors.averagingInt,averagingLong和averagingDouble可以计算数值的平均数:
Double collect = DataUtil.genMenu().stream().collect(Collectors.averagingInt(Dish::getCalories));
System.out.println("平均热量:" + collect);
Double collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.averagingDouble(Double::doubleValue));
System.out.println("double 平均值:" + collect1);
Double collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.averagingLong(Long::longValue));
System.out.println("long 平均值:" + collect2);
3.4 汇总合集
你可能想要得到两个或更多这样的结果,而且你希望只需一次操作就可以完成。在这种情况下,你可以使用summarizingInt工厂方法返回的收集器。例如,通过一次summarizing操作你可以就数出菜单中元素的个数,并得到热量总和、平均值、最大值和最小值:
IntSummaryStatistics collect = DataUtil.genMenu().stream().collect(Collectors.summarizingInt(Dish::getCalories));
System.out.println("int:" + collect);
DoubleSummaryStatistics collect1 = Arrays.asList(0.1, 0.2, 0.3).stream().collect(Collectors.summarizingDouble(Double::doubleValue));
System.out.println("double:" + collect1);
LongSummaryStatistics collect2 = Arrays.asList(1L, 2L, 3L).stream().collect(Collectors.summarizingLong(Long::longValue));
System.out.println("long:" + collect2);
3.5 连接字符串
joining工厂方法返回的收集器会把对流中每一个对象应用toString方法得到的所有字符串连接成一个字符串。
String collect = DataUtil.genMenu().stream().map(Dish::getName).collect(Collectors.joining());
请注意,joining在内部使用了StringBuilder来把生成的字符串逐个追加起来。幸好,joining工厂方法有一个重载版本可以接受元素之间的分界符,这样你就可以得到一个都好分隔的名称列表:
String collect1 = DataUtil.genMenu().stream().map(Dish::getName).collect(Collectors.joining(","));
4. 广义的归约汇总
所有收集器,都是一个可以用reducing工厂方法定义的归约过程的特殊情况而已。Collectors.reducing工厂方法是所有这些特殊情况的一般化。
它需要三个参数:
- 第一个参数是归约操作的起始值,也是流中没有元素时的返回值,所以很显然对于数值和而言0是一个合适的值。
- 第二个参数就是你在6.2.2节中使用的函数,将菜肴转换成一个表示其所含热量的int。
- 第三个参数是一个BinaryOperator,将两个项目累积成一个同类型的值。这里它就是对两个int求和。
下面两个是相同的操作:
Optional<Dish> collect = DataUtil.genMenu().stream().collect(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))); Optional<Dish> mostCalorieDish = menu.stream().collect(reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2));
5. 分组
用Collectors.groupingBy工厂方法返回的收集器就可以轻松地完成任务:
Map<Dish.Type, List<Dish>> collect = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType));
给groupingBy方法传递了一个Function(以方法引用的形式),它提取了流中每 一道Dish的Dish.Type。我们把这个Function叫作分类函数,因为它用来把流中的元素分成不同的组。分组操作的结果是一个Map,把分组函数返回的值作为映射的键,把流中所有具有这个分类值的项目的列表作为对应的映射值。
5.1 多级分组
要实现多级分组,我们可以使用一个由双参数版本的Collectors.groupingBy工厂方法创建的收集器,它除了普通的分类函数之外,还可以接受collector类型的第二个参数。那么要进行二级分组的话,我们可以把一个内层groupingBy传递给外层groupingBy,并定义一个为流中项目分类的二级标准:
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> collect1 = DataUtil.genMenu().stream().collect(
Collectors.groupingBy(Dish::getType,
Collectors.groupingBy(dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else return CaloricLevel.FAT;
}))
);
5.2 按子组收集数据
传递给第一个groupingBy的第二个收集器可以是任何类型,而不一定是另一个groupingBy。例如,要数一数菜单中每类菜有多少个,可以传递counting收集器作为groupingBy收集器的第二个参数:
Map<Dish.Type, Long> collect2 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType, Collectors.counting()));
还要注意,普通的单参数groupingBy(f)(其中f是分类函数)实际上是groupingBy(f, toList())的简便写法。
把收集器返回的结果转换为另一种类型,你可以使用 Collectors.collectingAndThen工厂方法返回的收集器,接受两个参数:要转换的收集器以及转换函数,并返回另一个收集器。
Map<Dish.Type, Dish> collect3 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(Dish::getType,
Collectors.collectingAndThen(
Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)),
Optional::get
)));
这个操作放在这里是安全的,因为reducing收集器永远都不会返回Optional.empty()。
常常和groupingBy联合使用的另一个收集器是mapping方法生成的。这个方法接受两个参数:一个函数对流中的元素做变换,另一个则将变换的结果对象收 起来。其目的是在累加之前对每个输入元素应用一个映射函数,这样就可以让接受特定类型元素的收 器适应不同类型的对象。我们来看一个使用这个收集器的实际例子。比方说你想要知道,对于每种类型的Dish, 菜单中都有哪些CaloricLevel。
Map<Dish.Type, Set<CaloricLevel>> collect4 = DataUtil.genMenu().stream().collect(Collectors.groupingBy(
Dish::getType, Collectors.mapping(
dish -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
} else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
} else return CaloricLevel.FAT;
}, Collectors.toSet()
)
));
6. 分区
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分类函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,于是它最多可以 分为两组——true是一组,false是一组。例如,如果想要把菜按照素食和非素食分开:
Map<Boolean, List<Dish>> collect = DataUtil.genMenu().stream().collect(Collectors.partitioningBy(Dish::isVegetarian));
System.out.println(collect.get(true));
partitioningBy 工厂方法有一个重载版本,可以像下面这样传递第二个收集器:
Map<Boolean, Map<Dish.Type, List<Dish>>> collect1 = DataUtil.genMenu().stream().collect(Collectors.partitioningBy(
Dish::isVegetarian, Collectors.groupingBy(Dish::getType)
));
分区看作分组一种特殊情况。
7. Collectors类的静态工厂方法
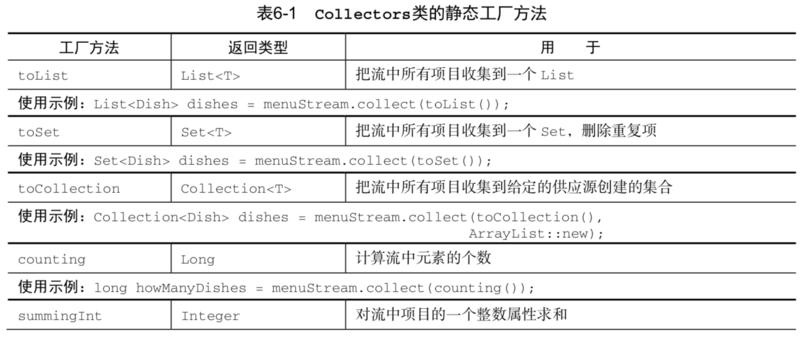
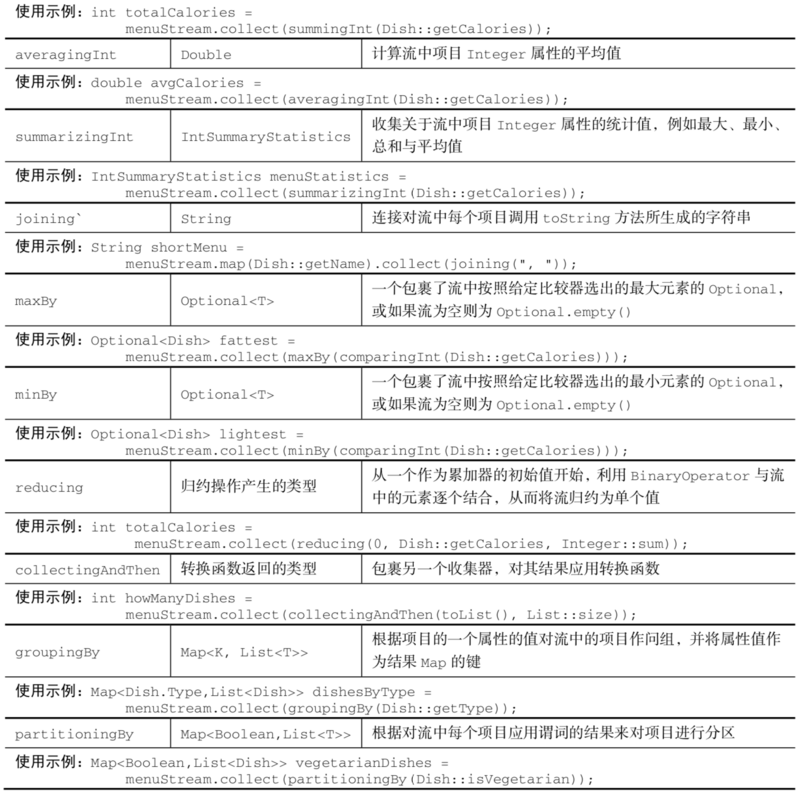
8. 收集器接口
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
Function<A, R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}
本列表适用以下定义:
- T是流中要收集的项目的泛型。
- A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
- R是手机操作得到的对象(通常但并不一定是集合)的类型。
8.1 建立新的结果容器:supplier方法
supplier方法必须返回一个结果为空的Supplier,也就是一个无参数函数,在调用时它会创建一个空的累加器实例,供数据收集过程使用。
8.2 将元素添加到结果容器:accumulator方法
accumulator方法会返回执行归约操作的函数。当遍历到流中第n个元素时,这个函数执行时会有两个参数:保存归约结果的累加器(已收集了流中的前n-1个项目),还有第n个元素本身。该函数将返回void,因为累加器是原位更新,即函数的执行改变了它的内部状态以体现遍历的元素的效果。
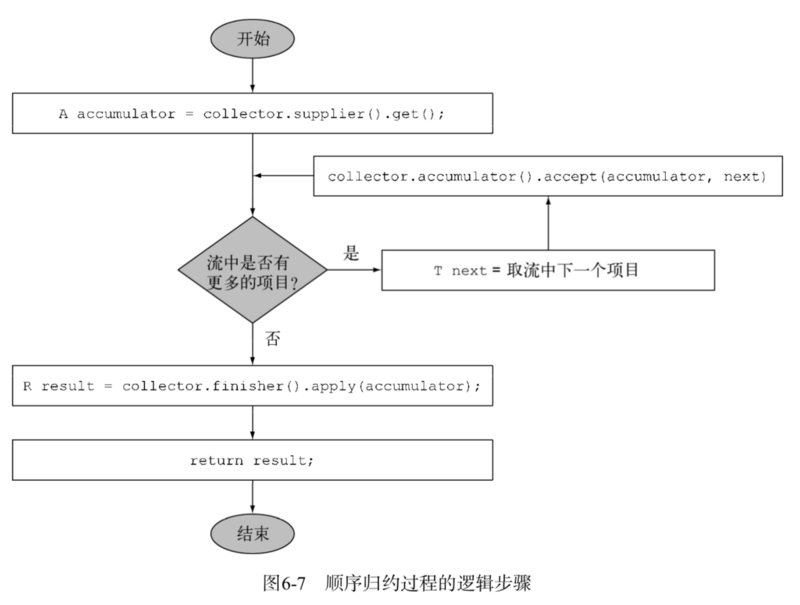
8.3 对结果容器应用最终转换:finisher方法
在遍历完流后,finisher方法必须返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果。
顺序归约过程的逻辑步骤:
8.4 合并两个结果容器:combiner方法
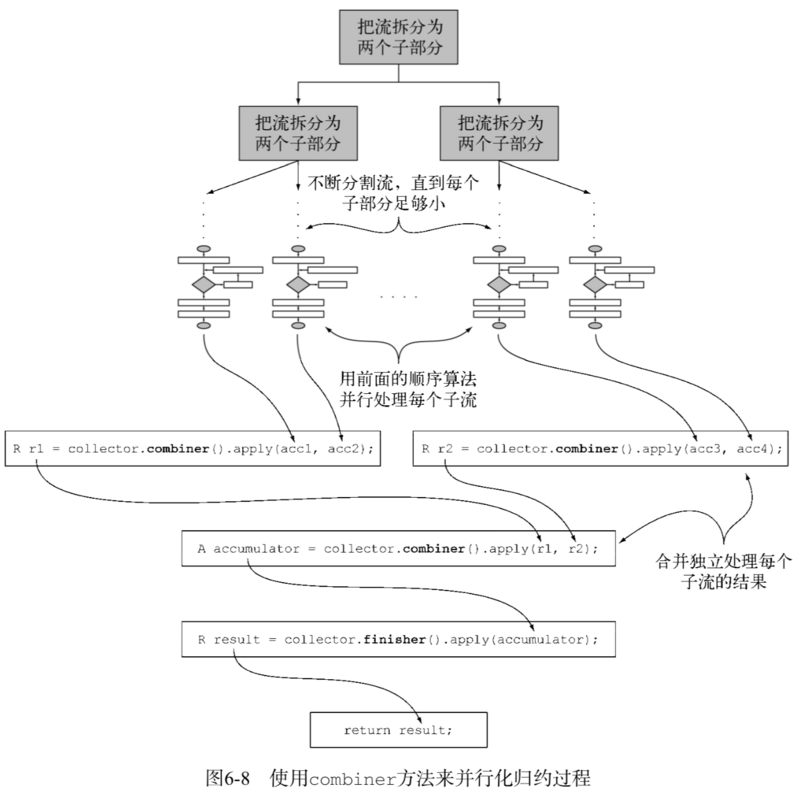
四个方法中的最后一个——combiner方法会返回一个供归约操作使用的函数,它定义了对流的各个子部分进行并行处理时,各个子部分归约所得的累加器要如何合并:
- 原始流会以递归方式拆分为子流,直到定义流是否需要进一步拆分的一个条件为非(如果分布式工作单位太小,并行计算往往比顺序计算要慢,而且要是生成的并行任务比处理器内核数多很多的话就毫无意义了)。
- 现在,所有的子流都可以并行处理,即对每个子流应用图6-7所示的顺序归约算法。
- 最后,使用收集器combiner方法返回的函数,将所有的部分结果两两合并。这时会把原始流每次拆分时得到的子流对应的结果合并起来
8.5 characteristics方法
最后一个方法——characteristics会返回一个不可变的Characteristics集合,它定义了收集器的行为——尤其是关于流是否可以并行归约,以及可以使用哪些优化的提示。
Characteristics是一个包含三个项目的枚举。
- UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响。
- CONCURRENT——accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为UNORDERED,那它仅在用于无序数据源时才可以并行归约。
- IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查地转换为结果R是安全的。
9. 小结
- collect是一个终端操作,它接受的参数是将流中元素累积到汇总结果的各种方式(称为收集器)。
- 预定义收集器包括将流元素归约和汇总到一个值,例如计算最小值、最大值或平均值。这些收集器总结在表6-1中。
- 预定义收集器可以用groupingBy对流中元素进行分组,或用partitioningBy进行分区。
- 收集器可以高效地复合起来,进行多级分组、分区和归约。
- 你可以实现Collector接口中定义的方法来开发你自己的收集器。
资源获取
- 公众号回复 : Java8 即可获取《Java 8 in Action》中英文版!
Tips
- 欢迎收藏和转发,感谢你的支持!(๑•̀ㅂ•́)و✧
- 欢迎关注我的公众号:庄里程序猿,读书笔记教程资源第一时间获得!

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

