Java 并发——基石篇(下)
Object wait 和 notify 的实现机制
Java Object 类提供了一个基于 native 实现的 wait 和 notify 线程间通讯的方式,这是除了 synchronized 之外的另外一块独立的并发基础部分,有关 wait 和 notify 的部分内容,我们在上面分析 monitor 的 exit 的时候已经有一些涉及,但是并没有过多的深入,导致留下了不少的疑问,下面本小节会详细分析一下在 HotSpot JVM 中的 wait 和 notify 的实现逻辑。
如果你打开 JDK 中的 Object 类的代码,你会看到 wait 和 notify/notifyAll 的实现全部是采用采用 native 实现的,并且在 Object 的开头有如下代码:
复制代码
privatestaticnativevoidregisterNatives();
static{
registerNatives();
}
这里是不是和前面的 Thread 类如出一辙,因此查找 JVM 中的本地实现函数也是一样的手段。所以这里就省略这个查找的部分,相信聪明的你已经知道怎么在 JVM 代码中找实现的函数了。如果一路查找的话,你会发现 wait 和 notify/notifyAll 还是在 src/hotspot/share/runtime/objectMonitor.cpp 中实现的。因此我们还是会在这个文件中进行分析。
wait 实现
ObjectMonitor 类中的 wait 函数实现如下:
复制代码
voidObjectMonitor::wait(jlong millis, bool interruptible, TRAPS) {
...
if(interruptible &&Thread::is_interrupted(Self,true) && !HAS_PENDING_EXCEPTION) {
...
// 抛出异常,不会直接进入等待
THROW(vmSymbols::java_lang_InterruptedException());
...
}
...
ObjectWaiter node(Self);
node.TState = ObjectWaiter::TS_WAIT;
Self->_ParkEvent->reset();
OrderAccess::fence();
Thread::SpinAcquire(&_WaitSetLock,"WaitSet - add");
AddWaiter(&node);
Thread::SpinRelease(&_WaitSetLock);
if((SyncFlags &4) ==0) {
_Responsible =NULL;
}
...
// exit the monitor
exit(true,Self);
...
if(interruptible && (Thread::is_interrupted(THREAD,false) || HAS_PENDING_EXCEPTION)) {
// Intentionally empty
}elseif(node._notified ==0) {
if(millis <=0) {
Self->_ParkEvent->park();
}else{
ret =Self->_ParkEvent->park(millis);
}
}
// 被 notify 唤醒之后的善后逻辑
...
}
wait 函数的实现也比较长,但是我们关心的核心功能部分就是上面列出的。首先会判断一下当前线程是否为可中断并且是否已经被中断,如果是的话会直接抛出 InterruptedException 异常,而不会进入 wait 等待,否则的话,就需要执行下面的等待的过程。首先会根据 Self 当前线程新建一个 ObjectWaiter 对象节点,这个对象我们在前面分析 monitor 的 enter 的时候就已经见到过了。生成一个新的节点之后就是需要将这个节点放到等待队列中,通过调用 AddWaiter 函数实现 node 的入队操作,不过在入队操作之前需要获得互斥锁以保证并发安全:
复制代码
voidThread::SpinAcquire(volatileint* adr,constchar * LockName) {
if(Atomic::cmpxchg (1, adr,0) ==0) {
return;// normal fast-path return
}
// Slow-path : We've encountered contention -- Spin/Yield/Block strategy.
TEVENT(SpinAcquire - ctx);
intctr =0;
intYields =0;
for(;;) {
while(*adr !=0) {
++ctr;
if((ctr &0xFFF) ==0|| !os::is_MP()) {
if(Yields >5) {
os::naked_short_sleep(1);
}else{
os::naked_yield();
++Yields;
}
}else{
SpinPause();
}
}
if(Atomic::cmpxchg(1, adr,0) ==0)return;
}
}
从函数的名称就能看出这是一个自旋锁的实现,并不会「立即」使得线程陷入等待状态,从实现上看,这里是通过一个死循环不断通过 cas 检查判断是否获得锁。这里开始会通过一个 cas 检查看下是否能够成功,如果成功的话就不用进行下面比较重量级的 spin 过程。如果获取失败,就需要进入下面的 spin 过程,这里的 spin 逻辑是一个比较有意思的算法。这里定义了一个 ctr 变量,其实就是 counter 计数器的意思,(ctr & 0xFFF) == 0 || !os::is_MP() 这个条件比较有意思,意思是说如果我尝试的次数大于 0xfff,或者当前系统是一个单核处理器系统,那么就执行下面的逻辑。可以看到这里的 spin 是有一定的限度的。首先开始的时候,如果是多核系统,会直接执行 SpinPause ,我们看下 SpinPause 函数的实现,这个函数是实现 CPU 的忙等待,因此会有不同系统和 CPU 架构的对应实现:
我们这里依然只关心 linux 平台上的 64 bit 架构的实现:
复制代码
intSpinPause() {
return0;
}
是的,你没有看错,这里的实现就是没有实现,只是返回一个 0 就完事!其实你想想,通过调用一个立即返回的空函数不就实现了 CPU 的忙等待了么?只不过这种实现方式比较不太优雅罢了~我们再来看 SpinAcquire 函数的实现,如果我们尝试的次数已经到了 0xFFF 次的话,那就表示我们需要使用另外一种机制来实现忙等了,因为这里尝试获取锁不能预测多久可以获得,因此不可能无限期地执行上面调用空函数,这是对资源的一种极大的浪费。如果尝试了 0xFFF 次还没有成功的话,就通过如下方式实现等待:
复制代码
if(Yields >5) {
os::naked_short_sleep(1);
}else{
os::naked_yield();
++Yields;
}
首先会尝试通过 yield 函数来将当前线程的 CPU 执行时间让出来,如果让了 5 次还是没有获得锁,那就只能通过 naked_short_sleep 来实现等待了,这里的 naked_short_sleep 函数从名字就能看出来是短暂休眠等待,通过每次休眠等待 1ms 实现。我们现在看下 naked_yield 的实现方式,同样这个函数也有很多系统平台的实现,我们老规矩只看 linux:
复制代码
voidos::naked_yield() {
sched_yield();
}
可以看到这里的实现是比较简单的,直接通过 pthread 的 sched_yield 函数实现线程的时间片让出。下面在看下 naked_short_sleep 的实现(依旧是 linux 平台):
复制代码
voidos::naked_short_sleep(jlong ms) {
struct timespec req;
assert(ms <1000,"Un-interruptable sleep, short time use only");
req.tv_sec =0;
if(ms >0) {
req.tv_nsec = (ms %1000) *1000000;
}else{
req.tv_nsec =1;
}
nanosleep(&req, NULL);
return;
}
这里我们通过 nanosleep 系统调用实现线程的 timed waiting。
到这里我们大致分析了 SpinAcquire 函数的实现,现在我们需要说明下这个函数中为啥需要判断 os:: is_MP (),逻辑是这样的:如果是单核处理器就通过 yield 或者 sleep 实现等待,如果是多核处理器的话就通过调用空实现函数来忙等待。为啥需要这样呢?因为如果是单核 CPU 的话,你通过调用空实现函数实现忙等待是不科学的,因为只有一个核,你却通过这个核来实现忙等待,那么原本需要释放锁的线程得不到执行,那就可能造成饥饿等待,我们的 CPU 一直在转动,但是没有解决任何问题。所以如果是单核 CPU 系统的话,我们不能通过调用空函数来实现等待。相反,如果是多核的话,那就可以在另外一个空闲的 CPU 上实现忙等待一增加系统吞吐量,可以看出在 jVM 中为了增加系统的系统和保证系统的兼容性,做了多少的努力和实现啊!
上面的 SpinAcquire 函数返回之后,就表示我们获得了锁,现在可以将我们的 node 放到等待队列中了:
复制代码
inline void ObjectMonitor::AddWaiter(ObjectWaiter*node) {
assert(node!= NULL,"should not add NULL node");
assert(node->_prev== NULL,"node already in list");
assert(node->_next== NULL,"node already in list");
// putnodeatend of queue (circular doubly linked list)
if (_WaitSet == NULL) {
_WaitSet =node;
node->_prev =node;
node->_next =node;
} else{
ObjectWaiter* head = _WaitSet;
ObjectWaiter* tail = head->_prev;
assert(tail->_next == head,"invariant check");
tail->_next =node;
head->_prev =node;
node->_next = head;
node->_prev= tail;
}
}
这里的实现其实非常简单,就是将 node 插入双向链表 _WaitSet 的尾部。插入链表完毕之后,需要通过 SpinRelease 将锁释放。
现在我们已经将新建的 node 节点加入到 WaitSet 队列中了,我们继续看 wait 函数接下来的逻辑,现在我们就要执行如下内容:
复制代码
//exitthe monitor exit(true, Self);
是的,你肯定知道 Java Object 的 wait 操作会释放 monitor 锁,释放操作就是这里实现的!
释放了 monitor 锁之后,我们就需要将当前线程进行 park 等待了:
复制代码
if(interruptible && (Thread::is_interrupted(THREAD,false) || HAS_PENDING_EXCEPTION)) {
// Intentionally empty
}elseif(node._notified ==0) {
if(millis <=0) {
Self->_ParkEvent->park();
}else{
ret= Self->_ParkEvent->park(millis);
}
}
在正式 park 之前,还会再一次看下是否有 interrupted,如果有的话就会跳过 park 操作,否则就会进行 park 阻塞。因为 wait 操作可以带时间,表示阻塞的时间,这里会根据需要阻塞的时间给 park 函数不同的参数。park 函数我们前面在分析 monitor 的 enter 的时候已经分析过了,因此这里就不再赘述了。
在 wait 接下来的函数,就是 park 阻塞唤醒之后的善后逻辑,对于我们的分析不是十分重要,这里就跳过。接下来,我们重点分析一下 notify 唤醒的逻辑。
notify 实现
notify 函数的实现如下:
复制代码
void ObjectMonitor::notify(TRAPS) {
CHECK_OWNER();
if(_WaitSet==NULL) {
TEVENT(Empty-Notify);
return;
}
DTRACE_MONITOR_PROBE(notify,this,object(), THREAD);
INotify(THREAD);
OM_PERFDATA_OP(Notifications,inc(1));
}
可以看到,首先会检查 WaitSet 队列,如果队列为空的话,表示没有线程执行了 wait,也就没有必要执行接下来的操作了,直接返回即可。
如果 WaitSet 队列不为空,表示有线程在这个 monitor 上 wait 了,因此就需要唤醒某个线程,这里是通过调用 INotify 函数实现:
复制代码
voidObjectMonitor::INotify(Thread*Self) {
const int policy = Knob_MoveNotifyee;
Thread::SpinAcquire(&_WaitSetLock,"WaitSet - notify");
ObjectWaiter * iterator = DequeueWaiter();
if(iterator !=NULL) {
ObjectWaiter *list= _EntryList;
if(policy ==0) {
// prepend to EntryList
if(list==NULL) {
...
}else{
...
}
}elseif(policy ==1) {
// append to EntryList
if(list==NULL) {
...
}else{
...
}
}elseif(policy ==2) {
// prepend to cxq
if(list==NULL) {
...
}else{
...
}
}elseif(policy ==3) {
// append to cxq
...
}else{
...
}
...
}
Thread::SpinRelease(&_WaitSetLock);
}
我们先不深入理解代码的细节,先来把握一下 INotify 函数的框架。可以看到这里的操作都是在 _WaitSetLock 保护下的,首先会从 WaitSet 队列中出队一个节点,然后针对这个节点根据 Knob_MoveNotifyee 来决定执行不同策略逻辑,并且策略中的逻辑框架就是一样的,根据 _EntryList 是否为空执行不同操作(策略 3 除外,下面会单独分析)。
那么,Knob_MoveNotifyee 是什么呢?其实从定义的地方可以看出:
复制代码
// notify() - disposition of notifyee staticintKnob_MoveNotifyee =2;
从注释中可以看出,这个就是 notify 唤醒的策略定义。从上面的 INotify 函数的注释中可以看出总共有如下几种模式:
- 策略 0:将需要唤醒的 node 放到 EntryList 的头部
- 策略 1:将需要唤醒的 node 放到 EntryList 的尾部
- 策略 2:将需要唤醒的 node 放到 CXQ 的头部
- 策略 3:将需要唤醒的 node 放到 CXQ 的尾部
在分析不同策略的逻辑之前,我们先看下 WaitSet 的出队逻辑的实现,这是 INotify 函数开始会执行的事情:
复制代码
inlineObjectWaiter* ObjectMonitor::DequeueWaiter() {
// dequeue the very first waiter
ObjectWaiter* waiter = _WaitSet;
if(waiter) {
DequeueSpecificWaiter(waiter);
}
returnwaiter;
}
从注释中可以看出,这里将 WaitSet 队列中的第一个 node 出队,下面直接返回 WaitSet 队列的指针也就是队头,然后删除出队节点:
复制代码
inline void ObjectMonitor::DequeueSpecificWaiter(ObjectWaiter* node) {
assert(node != NULL,"should not dequeue NULL node");
assert(node->_prev != NULL,"node already removed from list");
assert(node->_next != NULL,"node already removed from list");
// when the waiter has woken up because of interrupt,
// timeout or other spurious wake-up, dequeue the
// waiter from waiting list
ObjectWaiter* next = node->_next;
if(next == node) {
assert(node->_prev == node,"invariant check");
_WaitSet = NULL;
}else{
ObjectWaiter* prev = node->_prev;
assert(prev->_next == node,"invariant check");
assert(next->_prev == node,"invariant check");
next->_prev = prev;
prev->_next = next;
if(_WaitSet == node) {
_WaitSet = next;
}
}
node->_next = NULL;
node->_prev = NULL;
}
这样我们就完成了从 WaitSet 双向链表队列中的队头出队逻辑。
如果我们自己看下 INotify 函数的实现,你会发现这里全是队列的操作,并没有唤醒线程。是的,唤醒线程不在这里,这里只是将需要唤醒的线程放到 EntryList 队列中,然后在 exit 函数中唤醒。而 exit 函数我们已经很详细地分析过了,相信这时的你已经有一个深入的理解了吧~那为啥 notify 不直接唤醒呢?因为 wait 等待的线程是 synchronized 同步块中的呀!它需要拿到 monitor 才能继续执行啊,什么时候才能拿到 monitor 呢?也就是别人 exit 的时候你才能啊~这就解释了为毛 notify 不直接唤醒而是在 exit 的时候唤醒。
上面,我们看到了 JVM 的默认策略是 2,下面我们分别分析一下不同的策略逻辑。
唤醒策略 0
策略 0 的执行逻辑如下:
复制代码
if(list==NULL) {
iterator->_next = iterator->_prev =NULL;
_EntryList = iterator;
}else{
list->_prev = iterator;
iterator->_next =list;
iterator->_prev =NULL;
_EntryList = iterator;
}
如果 EntryList 为空的话,表示之前没有线程被 notify 唤醒,已经直接将当前节点放到 EntryList 中即可。否则的话,就将当前节点放到 EntryList 的头部。
下面我们通过一个实验来验证我们的结论。
实验的 java 代码:
复制代码
Thread t0 = new Thread(newRunnable() {
@Override
public void run() {
System.out.println("Thread 0 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 0 end!!!!!!");
}
}
});
Thread t1 = new Thread(newRunnable() {
@Override
public void run() {
System.out.println("Thread 1 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 1 end!!!!!!");
}
}
});
Thread t2 = new Thread(newRunnable() {
@Override
public void run() {
System.out.println("Thread 2 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 2 end!!!!!!");
}
}
});
Thread t3 = new Thread(newRunnable() {
@Override
public void run() {
System.out.println("Thread 3 start!!!!!!");
synchronized (lock) {
for (inti =0; i < 3; i++) {
try {
System.in.read();
} catch (Exceptione) {
}
lock.notify();
}
System.out.println("Thread 3 end!!!!!!");
}
}
});
t0.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t1.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t2.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t3.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
在我按下三次回车键之前的 WaitSet 状态如下:
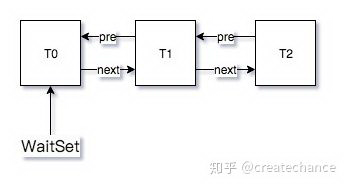
当我依次按下三次回车键的之后,WaitSet 链表就为空,此时 EntryList 如下:
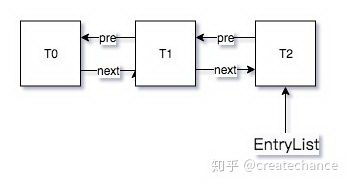
我们将 Knob_MoveNotifyee 的默认值修改 0,然后重新编译 JVM,执行上面的 java 代码结果如下:
复制代码
Thread0start!!!!!! Thread1start!!!!!! Thread2start!!!!!! Thread3start!!!!!! Thread3end!!!!!! Thread2end!!!!!! Thread1end!!!!!! Thread0end!!!!!!
可以看到线程结束运行的顺序和我们分析的一样,就是 2 -> 1 -> 0。
唤醒策略 1
策略 1 和策略 0 逻辑是相似,只是这里将节点放到尾部:
复制代码
if(list==NULL) {
iterator->_next = iterator->_prev =NULL;
_EntryList = iterator;
}else{
// CONSIDER: finding the tail currently requires a linear-time walk of
// the EntryList. We can make tail access constant-time by converting to
// a CDLL instead of using our current DLL.
ObjectWaiter * tail;
for(tail =list; tail->_next !=NULL; tail = tail->_next) {}
assert(tail !=NULL&& tail->_next ==NULL,"invariant");
tail->_next = iterator;
iterator->_prev = tail;
iterator->_next =NULL;
}
这里的注释很有意思,说是可以将 EntryList 做成循环双向队列(CDLL)可以优化操作,因为 CDLL 查找 tail 节点的时间是常量时间的,大家有兴趣可以修改下这里的实现,兴许你可以给 JVM 提交一个 patch,然后你也是 JVM 源码贡献者之一呢。。。
下面我们看下上面策略 0 的代码执行的结果:
复制代码
Thread0start!!!!!! Thread1start!!!!!! Thread2start!!!!!! Thread3start!!!!!! Thread3end!!!!!! Thread0end!!!!!! Thread1end!!!!!! Thread2end!!!!!!
可以看到,这里的结束的顺序和策略 0 是相反的。
唤醒策略 2——默认策略
策略 0 和策略 1 是将需要唤醒的节点放到 EntryLIst 中,而策略 2 和策略 3 是将节点放到 cxq 队列中,只不过策略 2 放到 cxq 的头部,策略 3 放到 cxq 的尾部。
策略 2 是默认策略,也就是说大家手上的 JVM 行为是将唤醒的节点放到 cxq 队列的头部。你还记得 cxq 队列吧?就是 synchronized 的等待队列啊,希望你还没有忘记。
为了验证我们的结论,我们需要使用一个不一样的 java 代码,我们需要结合 synchronized 阻塞队列才能看出效果:
复制代码
Thread t0 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 0 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 0 end!!!!!!");
}
}
});
Thread t1 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 1 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 1 end!!!!!!");
}
}
});
Thread t2 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 2 start!!!!!!");
synchronized (lock) {
try {
lock.wait();
} catch (Exceptione) {
}
System.out.println("Thread 2 end!!!!!!");
}
}
});
Thread t3 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 3 start!!!!!!");
synchronized (lock) {
try {
System.in.read();
} catch (Exceptione) {
}
lock.notify();
lock.notify();
lock.notify();
System.out.println("Thread 3 end!!!!!!");
}
}
});
Thread t4 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 4 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 4 end!!!!!!");
}
}
});
Thread t5 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 5 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 5 end!!!!!!");
}
}
});
Thread t6 =newThread(newRunnable() {
@Override
publicvoidrun() {
System.out.println("Thread 6 start!!!!!!");
synchronized (lock) {
System.out.println("Thread 6 end!!!!!!");
}
}
});
t0.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t1.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t2.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t3.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t4.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t5.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exceptione) {
}
t6.start();
我们启动了 6 个线程,其中 0 ~ 2 是会 wait 到 WaitSet 中的,4 ~ 6 是等待在 cxq 中的。
好的,下面我们看下策略 2,也就是默认策略的执行逻辑:
复制代码
if(list==NULL) {
iterator->_next = iterator->_prev =NULL;
_EntryList = iterator;
}else{
iterator->TState = ObjectWaiter::TS_CXQ;
for(;;) {
ObjectWaiter * front = _cxq;
iterator->_next = front;
if(Atomic::cmpxchg(iterator, &_cxq, front) == front) {
break;
}
}
}
首先如果发现 EntryList 为空的话,也就是第一个被 notify 唤醒的线程会进入到 EntryList,而 WaitSet 中剩下的节点会依次插入到 cxq 的头部,然后更新 cxq 指针指向新的头节点。
以上面的 java 代码为例,在我按下回车键之前的状态如下:

当我按下回车之后状态如下:
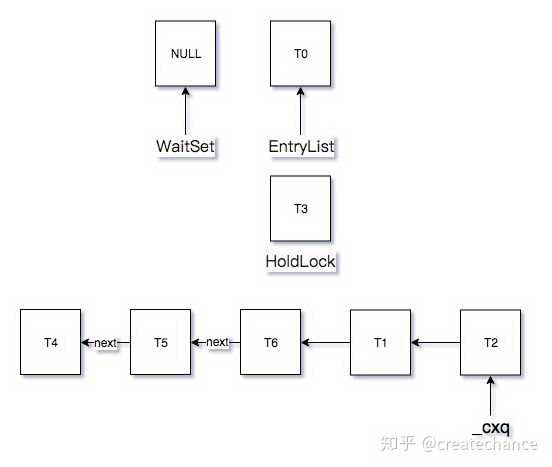
因此,在 exit 的时候,在默认状态下会实现唤醒 EntryList 中线程,然后在唤醒 cxq 中的,所以唤醒的顺序是:0 -> 2 -> 1 -> 6 -> 5 -> 4。
下面我们执行代码,验证我们的猜想:
复制代码
Thread0start!!!!!! Thread1start!!!!!! Thread2start!!!!!! Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread0end!!!!!! Thread2end!!!!!! Thread1end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!!
可以看到,和我们的猜想完全一样。
唤醒策略 3
策略 3 的逻辑和策略 2 比较相似,只是策略 3 会将节点放到 cxq 尾部:
复制代码
iterator->TState = ObjectWaiter::TS_CXQ;
for(;;) {
ObjectWaiter * tail = _cxq;
if(tail ==NULL) {
iterator->_next =NULL;
if(Atomic::replace_if_null(iterator, &_cxq)) {
break;
}
}else{
while(tail->_next !=NULL) tail = tail->_next;
tail->_next = iterator;
iterator->_prev = tail;
iterator->_next =NULL;
break;
}
}
这里不会判断 EntryList 是否为空,而是直接将节点放到 cxq 的尾部,这一点和前面几个策略不一样,需要注意下。
所以我们可以预测,上面策略 3 验证代码中的唤醒顺序是:6 -> 5 -> 4 -> 0 ->1 -> 2,下面执行下代码看看结果:
复制代码
Thread0start!!!!!! Thread1start!!!!!! Thread2start!!!!!! Thread3start!!!!!! Thread4start!!!!!! Thread5start!!!!!! Thread6start!!!!!! Thread3end!!!!!! Thread6end!!!!!! Thread5end!!!!!! Thread4end!!!!!! Thread0end!!!!!! Thread1end!!!!!! Thread2end!!!!!!
可以看到,和我们的预测结果依然是一样的。
到这里我们就完整分析完毕了 notify 的实现逻辑,整体上的实现还是比较简单的,只是根据不同的策略执行不同的唤醒出队逻辑,同时这里的逻辑会和 exit 中的出队逻辑协调起来,上面我们已经通过实际的例子验证了这一点。
notifyAll 实现
notifyAll 的实现其实和 notify 实现大同小异:
复制代码
void ObjectMonitor::notifyAll(TRAPS){
CHECK_OWNER();
if(_WaitSet==NULL) {
TEVENT(Empty-NotifyAll);
return;
}
DTRACE_MONITOR_PROBE(notifyAll,this,object(), THREAD);
inttally =0;
while(_WaitSet != NULL) {
tally++;
INotify(THREAD);
}
OM_PERFDATA_OP(Notifications,inc(tally));
}
可以看到,其实就是根据 WaitSet 长度,反复调用 INotify 函数,相当于多次调用 notify,因此这里就不在赘述了。
Volatile 语义
Volatile 这个话题是并行计算领域一个非常有意思的话题,涉及到非常多的细节。在 C/C++ 和 Java 中都有 volatile 这个关键字,在实际探讨这个关键字的语义之前,我们先看下这个词的字面含义,下面是柯林斯高阶词典中的含义:
A situation that is volatile is likely to change suddenly and unexpectedly.
这里的解释有三个重要的含义:
- likely:可能的,这意味着被 volatile 形容的对象「可能」发生改变,因此我们不应该针对这个变量的值作出任何假设
- suddenly:突然地,这意味着这个变量有可能会在瞬间很快的发生变化
- unexpectedly:不可预期地,这其实与 likely 的含义一致,意味着这个变量可能随时随地发生变化,我们不能依赖于它的状态
因此,在编程语言中使用这个关键字修饰我们的变量,就意味着:这个变量可能会在任何时候改变为任何值,任何使用方必须实时关注这个值的变化,并且不能作出任何假设。
在实际探讨 Java 中的 volatile 关键字的语义之前,我们首先看下 C/C++ 中的关键字的语义,理解了 C/C++ 的 volatile 语义对于理解 volatile 非常有帮助。
C/C++ volatile 语义
查看 C volatile 的语义最简单的方式就是看 CPP Reference 中的介绍:
Every access (both read and write) made through an lvalue expression of volatile-qualified type is considered an observable side effect for the purpose of optimization and is evaluated strictly according to the rules of the abstract machine (that is, all writes are completed at some time before the next sequence point). This means that within a single thread of execution, a volatile access cannot be optimized out or reordered relative to another visible side effect that is separated by a sequence point from the volatile access.
从这里的描述我们可以看出在 C 中对 volatile 的访问规则如下:
- 不允许被优化消失(optimized out)
- 不被编译器优化乱序(reorder)
下面我们通过一个简单的例子来了解下 C 中的 volatile 关键字。
下面是一段简单的 c 程序:
复制代码
staticinta =12345;
staticintt =9090;
intmain(void)
{
intb = a;
intc = a;
inte = t;
returnb + c + e;
}
我们通过如下命令将上面的 c 代码编译成 .s 汇编代码:
复制代码
gcc -S -O3 main.c-o main.s
得到如下汇编代码:
复制代码
.section__TEXT,__text,regular,pure_instructions .macosx_version_min10, 13 .globl_main## -- Begin function main .p2align4, 0x90 _main:## @main .cfi_startproc ## %bb.0: pushq %rbp .cfi_def_cfa_offset16 .cfi_offset%rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register%rbp movl $33780, %eax## imm = 0x83F4 popq %rbp retq .cfi_endproc ## -- End function .subsections_via_symbols
可以看到,这里编译器已经帮我们将需要 return 的结果计算出来了,无需再进行取值然后计算了。也就是说,gcc 编译器已经针对我们的变量作出内存上的假设。现在我们将变量 a 和 t 使用 volatile 来修饰:
复制代码
staticvolatileinta =12345;
staticvolatileintt =9090;
intmain(void)
{
intb = a;
intc = a;
inte = t;
returnb + c + e;
}
可以得到如下汇编:
复制代码
.section__TEXT,__text,regular,pure_instructions .macosx_version_min10, 13 .globl_main## -- Begin function main .p2align4, 0x90 _main:## @main .cfi_startproc ## %bb.0: pushq %rbp .cfi_def_cfa_offset16 .cfi_offset%rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register%rbp movl _a(%rip), %eax addl _a(%rip), %eax addl _t(%rip), %eax popq %rbp retq .cfi_endproc ## -- End function .section__DATA,__data .p2align2## @a _a: .long12345## 0x3039 .p2align2## @t _t: .long9090## 0x2382 .subsections_via_symbols
可以很清晰地看到,这里加上 volatile 之后 gcc 就不会对变量的值作出任何假设,只能老老实实地按部就班读取然后计算。
以上的一个小例子就验证了上面我们讲到的 c 中的 volatile 第一个特性:防止被优化消失。至于第二个特点:不被编译器优化乱序,则是保证了被 volatile 修饰的变量在编译之后生成的机器码顺序肯定和原始代码中的顺序是一样的。
但是这里仅仅是保证了编译之后的机器指令码是有序的,但是我们都知道现代的 CPU 会乱序执行指令,只要保证最终的结果正确即可。因此,这里的 volatile 只能保证编译阶段不被乱序优化,不能保证执行阶段的乱序优化。如果想要保证执行阶段的乱序优化必须使用系统提供的内存屏障技术来实现。
更多关于 C++ 语义的分析,可以参考这篇博文(文末参考资料中有): C/C++ 中的 volatile 语义
Java volatile 语义
上面我们简单滴了解了在 c 中的 volatile 的语义,我们对 volatile 有了一个大致上的认识。那么在 java 中的 volatile 的语义又是什么呢?基本上如下:
- 保证在修改之后,其他的线程立即可见,这一点和 C 中的不对变量内存做任何假设是一致的
- 保证指令不会乱序执行,也就是说,执行到 volatile 变量的时候,在此之前的指令必须全部完成。这一点比 c 中的 volatile 更加彻底,因为 java 中的 volatile 实现底层采用了内存屏障技术保证了这一点
上面的第一个语义相信大家都了解,也很容易通过例子来验证。下面我们重点看下第二个特性是怎么保证的。我们知道 JVM 为了加快执行的效率,通常会采用 JIT 来优化代码执行的速度,也就是说,经过 JIT compile 之后的代码,就不会再执行字节码了,而是直接执行对应的底层机器码。如果我们能够有办法拿到 JIT 执行的对应机器码,我们不就能窥探到 JVM 底层在执行 volatile 变量的存取时的执行逻辑了吗?是的,我们真的可以获取到 JVM 底层的 JIT 机器代码,在 OpenJDK 的源码中提供了一个非常强大的工具:hsdis,关于这个工具的介绍可以参考源码中的 README:/src/utils/hsdis/README。我们需要编译下这个工具,编译的时候需要 binutils 这个 GNU 工具集合的源码,我们只要将下载好的 binutils 代码放到同一个目录下,然后执行如下命令即可编译 hsdis:
复制代码
makeBINUTILS=binutils-2.17ARCH=amd64CFLAGS="-Wno-error"
因为我的机器是 64 bit 的,所以这里执行 ARCH 为 amd64,又因为我是在 mac 平台上编译的,默认使用 clang(apple xcode 工具链),这个工具比 gcc 检查要严格地多,因此需要加上 CFLAGS="-Wno-error",不然很多 binutils 中的 warning 全成了错误而无法编译。另需要说明的是,这里最好使用 2.17 版本的 binutils,别的版本我都编译失败了,因为接口不兼容了,这一点其实在 README 中也有说到。
如果我们顺利编译,可以在当前目录下的 build/macosx-amd64 目录下看到如下内容:
复制代码
-rw-r--r--1gaochao staff289K72313:39Makefile drwxr-xr-x90gaochao staff2.8K72315:50bfd -rw-r--r--1gaochao staff2.6K72313:39config.cache -rw-r--r--1gaochao staff5.1K72313:39config.log -rwxr-xr-x1gaochao staff9.5K72315:50config.status -rwxr-xr-x1gaochao staff587K72313:40hsdis-amd64.dylib drwxr-xr-x10gaochao staff320B72315:50intl drwxr-xr-x64gaochao staff2.0K72315:50libiberty drwxr-xr-x26gaochao staff832B72315:50opcodes -rw-r--r--1gaochao staff13B72313:39serdep.tmp
这里的 hsdis-amd64.dylib 就是我们要的结果,我们将这个动态库拷贝到如下目录:
build/macosx-x86_64-normal-server-fastdebug/jdk/lib
这是 JVM 源码编译输出的目录,因为我编译的是 fastdebug 版本的 JVM,因此放到这里。这样,我们就可以通过 java 命令使用这个插件了。
下面我们定义一个如下的测试 java 代码:
复制代码
publicclassCount{
privatevolatileintcount=0;
privatevolatileinttest =0;
publicvoidtestMethod() {
count++;
test++;
}
}
定义个 Counter,其中计数通过 volatile 实现。然后我们在测试代码中调用这个 Counter:
复制代码
publicclassHello {
publicstaticvoidmain(String[] args) {
Countcount=newCount();
for(inti =0; i <100000; i++) {
count.testMethod();
}
}
}
注意,为了能够触发 JIT 优化,这里强制将 testMethod 方法执行 100000,这样才能将 JVM 中的代码跑热以生成 JIT 代码。
然后编译如上代码,然后在命令行执行如下命令来执行代码:
复制代码
java -XX:+PrintAssembly -XX:CompileCommand=dontinline,Count.testMethod -XX:CompileCommand=compileonly,Count.testMethod Hello > out
这里解释一下上面的命令,首先我们使用 -XX:+PrintAssembly 参数使用 hsdis 插件获取 JIT 机器码,然后通过 XX:CompileCommand 参数指定不要将我们的代码内联优化,并且只编译 Count.testMethod 方法,其他方法我们不关心。
如果上面的命令顺利执行,我们会得到 out 输出文件,这个文件非常长,这里我们只看 testMethod 方法执行的机器码:
复制代码
0x00000001116b1234: mov0xc(%rsi),%edi ;*getfield count {reexecute=0rethrow=0return_oop=0}
; - Count::testMethod@2(line6)
0x00000001116b1237: inc %edi
0x00000001116b1239: mov %edi,0xc(%rsi)
0x00000001116b123c: lock addl $0x0,0xffffffffffffffc0(%rsp)
;*putfield count {reexecute=0rethrow=0return_oop=0}
; - Count::testMethod@7(line6)
0x00000001116b1242: mov0x10(%rsi),%edi ;*getfield test {reexecute=0rethrow=0return_oop=0}
; - Count::testMethod@12(line7)
0x00000001116b1245: inc %edi
0x00000001116b1247: mov %edi,0x10(%rsi)
0x00000001116b124a: lock addl $0x0,0xffffffffffffffc0(%rsp)
;*putfield test {reexecute=0rethrow=0return_oop=0}
; - Count::testMethod@17(line7)
0x00000001116b1250: add $0x30,%rsp
0x00000001116b1254: pop %rbp
0x00000001116b1255: mov0x120(%r15),%r10
0x00000001116b125c: test %eax,(%r10) ; {poll_return}
我们在代码中针对变量进行 ++ 自增操作,因此可以看到首先通过 mov 读取原始值,然后通过 inc 指令将值增加 1,然后再通过 mov 指令将新的值推送到栈中,然后通过一个 lock addl 指令将 rsp 栈中的数据加 0,然后 ++ 自增操作就完毕了。前面的三个步骤我们都能明白,只是最后一个 lock addl 将 rsp 加 0 不太好理解,这里将一个值加 0 不相当于什么都没做吗?这句话是废话吗?其实不是的,我们需要了解下 lock 这个指令前缀是在做什么,我们需要查阅下 intel 的 IA32 指令开发者手册看下这个指令前缀的定义(LOCK—Assert LOCK# Signal Prefix 小节):

可以看到这里描述,是说通过 lock 可以在共享内存的系统上使得被修饰的指令成为一个排他性指令,也就是说只要这个指令在执行了可以保证如下两件事情:
- 修改完成的内容值,其他 CPU 核心可以立即看到
- 修改的时候,其他 CPU 不能操作这个值,并且在 lock 之前的指令不能重排到这句话的后面
这其实就是 java 中的 volatile 的语义啊~
还有一个疑问,那就是为啥使用 lock 修饰 addl,而不是 nop 指令呢?其实上面的开发者手册说的很清楚,lock 后面不能跟 nop 的,只能跟 add 之类的指令。因此,JVM 就采用了 lock addl 将一个栈中的值加 0 这种人畜无害的操作实现 volatile 的语义。
通过上面的分析,我们也就知道了,在 java 中的 volatile 关键字修饰的变量的访问在 intel x86 CPU 上是通过 lock 修饰的 addl 指令实现的。
后记
到这里我们就全部介绍完毕了关于 Java 并发基石部分的内容了,我们从共享内存多核系统设计讲起,然后介绍了 Java 的内存模型,接着介绍了 JVM 创建一个线程的过程。然后重点介绍了 synchonized 和 wait/notify 的实现机制,最后我们介绍了下 volatile 关键字的语义以及 java 的实现方案。
探索底层技术是复杂的,也是枯燥的,因为这部分的内容有如下困难:
- 原理复杂
- 网上的资料及其稀少甚至没有,只能自己实验,不断尝试,不断失败,不断努力才能获得知识
但是,一旦你学会了研究底层技术的基本套路,那么你的技术发展道路将会出现不一样的风景,你不会对新技术感到迷茫,因为你知道这些东西知识换汤不换药,基本的机制和理论已经稳定了若干年了,在理论没有突破的情况下,技术上的突破是很难的。
底层技术好比内功心法,虽然不能立即增加你的功力,但是经过日积月累,你会犹如九阳神功护体,天下武功过眼即会,并且百毒不侵。与君共勉,祝你成功。
本文转载自知乎。
原文链接:
https://zhuanlan.zhihu.com/p/75533893
正文到此结束
- 本文标签: 插件 build queue id CST linux node find 内存模型 list 详细分析 下载 希望 并发 tab tar IDE value 同步 ACE IO synchronized 源码 数据 App 锁 删除 cache 字节码 测试 突破 开发者 Apple volatile http ORM JVM 编译 https UI 开发 DDL constant Lua ssh struct 安全 注释 参数 src 处理器 bug java ip cat 时间 快的 lib Atom 模型 tk 目录 shell 线程 代码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

