告别“纷纷扰扰”—小米OLAP服务架构演进

本文从元数据和权限管理两方面介绍了小米OLAP服务的架构演进。
往期文章回顾: 了解uid和gid如何在Docker容器中工作
背景
> > > >
What’s OLAP?
如果你是一名数据分析师,或者是一位经常和 SQL 打交道的研发工程师,那么 OLAP这个词对你一定不陌生。 你或许听说过 OLAP、OLTP 技术,但是今天文章的主角OLAP 是由云技术平台提供的一款分布式数据分析服务,下面先简单介绍一下它。
小米 OLAP 是集存储计算于一体的分布式数据分析型数据库服务,通过 Kudu 实现“热数据”的实时写入和更新,通过自定义窗口定期迁移“冷数据”到HDFS,并以Parquet 格式存储,实现了冷热数据分离的架构,最终通过 SparkSQL 引擎提供同时对实时数据和历史数据进行分析的能力。
> > > >
OldArchitecture & Drawbacks
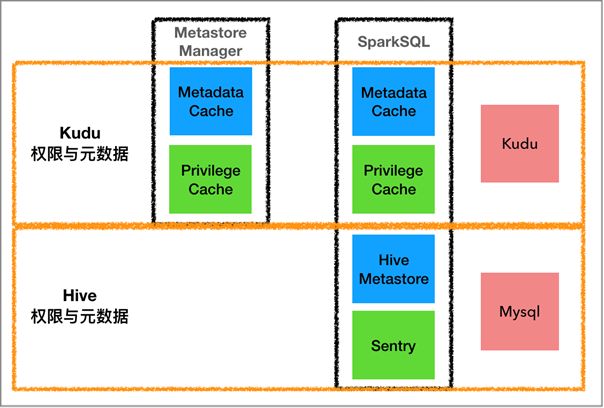
图1. OLAP 1.0元数据与权限管理
过去究竟有哪些“纷纷扰扰”呢,让我们先从 OLAP1.0 版本的元数据与权限管理图说起。 可以看到,在旧版的架构中,Kudu表相关的权限和元数据与Hive表相关的权限和元数据,无论在实现上还是底层存储上都是分离的。 前者通过我们自己实现的Metadata Cache 和 Privilege Cache 与 OLAP 服务的组件 Metastore Manager 及SparkSQL 引擎进行交互,数据存储在 Kudu 上; 后者则使用了独立的服务 Hive Metastore(HMS) 和 Sentry 分别进行元数据与权限的管理,底层数据存储在 MySQL 数据库。 了解完旧版本的架构,就可以更彻底地了解这样的架构带来了的问题:
1、用户角度:
(1)用户使用 OLAP 服务时,如果要访问 Kudu 表,需要对 SparkSQL队列进行特殊配置,以开启对 Kudu 数据源的支持。
(2)虽然早期架构在代码层对meta 做了合并,但是并未从根本上解决权限分离的情况。 比如用户通过 Hive 授权的某个数据库A,通过 OLAP 系统授权了某个数据库B,在 OLAP 系统是无法看到数据库A的相关表信息的。 还会出现用户有Kudu表权限但没有 Hive 表权限的情况。 上述情况不利于用户数据的打通,还会让用户在使用过程中产生疑惑。 同时,用户需要切换队列配置重启服务,使用上也不够友好。
2、开发角度:
Metadata Cache 和 Privilege Cache 在实现上存在冗余,其和底层元数据的交互在两个组件都存在。 其维护和开发成本比较高,没有统一入口和规范。 同时,底层分离的元数据和权限并不利于后续统一的 SQL Proxy 的开发。
可以看到,无论从用户的角度,还是开发者的角度,进行底层元数据和权限的架构整合都非常必要。
和“纷纷扰扰”说再见
介绍完了过往的“纷纷扰扰”,让我们看看如何和“纷纷扰扰”说再见。 从图1可以看出,解决这种分离的最简单方法就是复用现有的 HMS 和 Sentry 组件,将原有的元数据和权限数据迁移到 MySQL 数据库,同时更改上层组件的在元数据和权限部分的交互方法,包括 SparkSQL 层和 OLAP 服务端组件(OLAP Server、Metastore Manager 和 Dynamic Manager)。
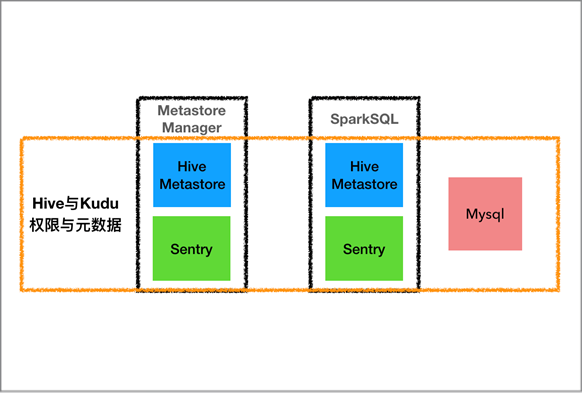
图2. OLAP 2.0元数据与权限管理
更改后的元数据与权限管理图如上所示。 下面我们分为两部分来介绍相关的工作。
> > > >
MetadataFederation
元数据整合方面,我们引入了 Kudu Storage Handler,其实现了 Hive Meta Hook的接口,继承了 DefaultStorageHandler 类,可以与 HMS 进行交互,完成了对 Kudu meta 的相关操作。 在原版的基础上,我们补充了分区和表的相关操作,以及一些必要的rollup操作来保证 meta 的一致性。
在 SparkSQL 层,对 Kudu meta 的调用方式转化为了直接使用 Kudu Storage Handler,原有的 Kudu 相关模块的功能直接整合进 Hive 模块,包括了查询、建表、删除表、修改表、展示建表语句等操作。 我们大体兼容了旧版本的 DML 语法,并通过 tblproperties 来传递各种 Kudu 相关的信息,比如表名、range 分区信息、hash分区信息等,同时,我们自定义的信息和数据流部分信息也存在表属性里,供上层程序使用,比如是否 OLAP 表、 OLAP 窗口值等。
在 OLAP 服务端,我们对所有元数据相关的部分做了重构。 原有的 Metadata Cache被移除,有关的元数据的操作通过调用 HMS Client 提供的 API 来实现。 同时,我们把系统相关的数据从 Kudu 迁移到 MySQL 数据库,使整个服务端不再对 Kudu Client有直接的依赖。
经过上述整合,所有的meta操作统一到了 Hive MetastoreClient 层,通过 Kudu Storage Handler 实现,数据存储在 MySQL,和对 Hive meta 的操作一致。 对于开发者,这种架构整体上更为清晰,在修改和维护上也更方便。 对于用户来说,通过beeline 去操作 Kudu 表和 Hive 表除了在建表语法上不同,其他基本操作和 Hive 没有区别,用户在建表后基本不需要关心底层存储介质,体验上更加一致。
> > > >
PrivilegeFederation
权限整合的前提是 Kudu 相关元数据已经整合到了 HMS 中,这样才能借助 Sentry 进行权限管理。 基于此,我们需要实现鉴权和授权两条通路。
在 SparkSQL 层,由于本身 Hive 模块就已经集合了 Sentry 用来做权限鉴定,所以元数据迁移过来以后,beeline 的操作都会通过 Sentry 进行鉴权,而授权部分目前SparkSQL 的语法还不支持。
在 OLAP 服务端,我们对原有权限相关的操作进行了重构。 原有的 Privilege Cache 被移除,所有权限相关的操作通过调用 Sentry Client API 实现,包括鉴权、授权、移除权限和权限展示。 在权限展示方面,由于 Sentry 本身的模型限制,提供的 AP I无法满足需求,我们根据自身需要进行了定制化开发,如增加了相应的 API 实现基于用户角色的权限获取等。
经过权限上的整合,Kudu 和 Hive 的所有权限就打通了,并可以通过 Sentry 统一提供权限相关的服务。
总结与展望
> > > >
小结
经过元数据与权限的整合,OLAP 服务的元数据范围和权限范围都扩大了,同时意味着查询的范围也扩大了。 新的架构如下图所示,meta 相关的服务最终都由 Hive Metastore 来提供,权限相关的服务最终都由 Sentry 来提供,我们只需要在各层通过客户端接口进行调用即可。
New Architecture
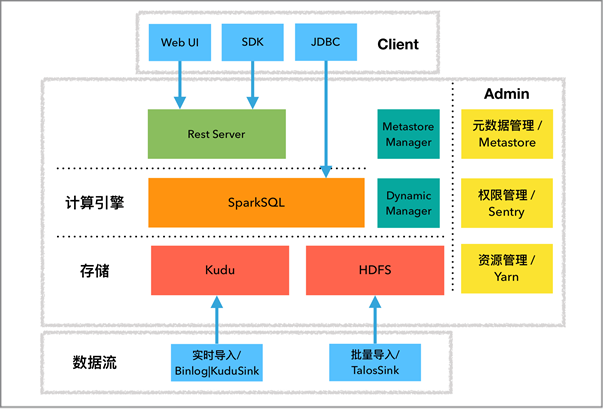
图3. OLAP 2.0架构图
> > > >
展望
基于整合后的架构,未来我们可以提供更多的能力,比如基于HMS的元数据服务,基于Sentry的权限服务。 未来,我们计划 支持更多的数据源 ,比如MySQL数据源, 整合更多的SQL引擎 ,比如 Hive、Kylin 致力于打造统一的SQL引擎服务。

我就知道你“在看”

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

