java日志框架笔记-log4j-springboot整合
日志框架slf4j log4j logback之间的关系
简答的讲就是slf4j是一系列的日志接口,而log4j logback是具体实现了的日志框架。
SLF4J获得logger对象: private static final Logger logger = LoggerFactory.getLogger(Test.class); 复制代码
log4j vs logback
都是日志框架的具体实现
log4j是apache实现的一个开源日志组件。(Wrapped implementations) logback同样是由log4j的作者设计完成的,拥有更好的特性,用来取代log4j的一个日志框架。是slf4j的原生实现。(Native implementations)

logback是直接实现了slf4j的接口,而log4j不是对slf4j的原生实现,所以slf4j api在调用log4j时需要一个适配层。也就是说logback实现slf4j是不消耗内存和计算开销的。
log4j 配置
log4j支持两种配置文件格式,一种是XML格式的文件,一种是properties属性文件。下面以properties属性文件为例介绍log4j.properties的配置。
下面开始正式讲解配置
配置rootLogger
log4j.rootLogger = [ level ] , appenderName1, appenderName2, … 复制代码
- 第一个是日志的输出级别 比如测试环境就可以把 level 换成 DEBUG 级别。
- appenderName1 表示文件的输出“地方”。这个“地方” 需要在下面的配置上继续配置。
这是一个示例,表示开始DEBUG 级别的日志,然后输出三个日志 file,stdout,trace
log4j.rootLogger=DEBUG,file,stdout,trace复制代码
配置日志信息输出目的地Appender
Log4j提供的appender有以下5种,分别可以将日志信息输出到5个不同的平台
org.apache.log4j.ConsoleAppender(控制台) org.apache.log4j.FileAppender(文件) org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件) org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件) org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)复制代码
下面是一个示例

file 就是那个 AppenderName,第一行的就是上面的几种appender的配置,详细的每个appender配置看下文
ConsoleAppender
Threshold=WARN:指定日志消息的输出最低层次。 ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。 Target=System.err:默认情况下是:System.out,指定输出控制台复制代码
FileAppender
Threshold=WARN:指定日志消息的输出最低层次。 ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。 File=mylog.txt:指定消息输出到mylog.txt文件。 Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。复制代码
DailyRollingFileAppender
Threshold=WARN:指定日志消息的输出最低层次。 ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。 File=mylog.txt:指定消息输出到mylog.txt文件。 Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。 DatePattern=”.”yyyy-ww:每周滚动一次文件,即每周产生一个新的文件。 当然也可以指定按月、周、天、时和分。即对应的格式如下: 1)”.”yyyy-MM: 每月 2)”.”yyyy-ww: 每周 3)”.”yyyy-MM-dd: 每天 4)”.”yyyy-MM-dd-a: 每天两次 5)”.”yyyy-MM-dd-HH: 每小时 6)”.”yyyy-MM-dd-HH-mm: 每分钟复制代码
RollingFileAppender
Threshold=WARN:指定日志消息的输出最低层次。 ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。 File=mylog.txt:指定消息输出到mylog.txt文件。 Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。 MaxFileSize=100KB:后缀可以是KB, MB 或者是 GB. 在日志文件到达该大小时,将会自动滚动,即将原来的内容移到mylog.log.1文件。 MaxBackupIndex=2:指定可以产生的滚动文件的最大数。复制代码
配置日志信息的格式(布局)
注意到上面的示例中还有一个配置
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=${log4j.ConversionPattern}复制代码
这是就是布局
Log4j提供的layout有以下几种
org.apache.log4j.HTMLLayout(以HTML表格形式布局), org.apache.log4j.PatternLayout(可以灵活地指定布局模式), org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串), org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)复制代码
详细讲一下 PatternLayout 模式可以在配置文件增加下面这个配置
log4j.ConversionPattern=[account-service]%-d{yyyy-MM-dd HH:mm:ss SS} [%c:%L]-[%p] %m%n复制代码
下面是几个参数的结束
-X号: X信息输出时左对齐;
%p: 输出日志信息优先级,即DEBUG,INFO,WARN,ERROR,FATAL,
%d: 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,
比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%r: 输出自应用启动到输出该log信息耗费的毫秒数
%c: 输出日志信息所属的类目,通常就是所在类的全名
%t: 输出产生该日志事件的线程名
%l: 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及行数。
举例:Testlog4.main(TestLog4.java:10)
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%: 输出一个”%”字符
%F: 输出日志消息产生时所在的文件名称
%L: 输出代码中的行号
%m: 输出代码中指定的消息,产生的日志具体信息
%n: 输出一个回车换行符,Windows平台为”/r/n”,Unix平台为”/n”输出日志信息换行复制代码
某个日志太多不想看咋办
log4j调整某个包的日记级别
比如现在io.lettuce.core下面发现很多DEBUG的日志这时候可以在配置文件中加入
log4j.logger.io.lettuce.core=INFO复制代码
这就可以把日志级别到info
来一波独立的业务日志
在一些场景下,想用某些特殊的业务日志记录一些问题,又不想和其他日志混在一起这时候可以采用一些独立日志文件去记录。配置方式如下:
log4j.logger.traceLogger=INFO,trace复制代码
区别于 默认的 log4j.rootLogger。
log4j.logger.name 就是你需要记录的独立日志。
appender配置如下
log4j.appender.trace=org.apache.log4j.DailyRollingFileAppender
log4j.appender.trace.File=/logs/omp/service/omp-account-service-trace.log
log4j.appender.trace.DatePattern='.'yyyy-MM-dd
log4j.appender.trace.Threshold=INFO
log4j.appender.trace.layout=org.apache.log4j.PatternLayout
log4j.appender.trace.layout.ConversionPattern=[%d{yyyy-MM-dd HH:mm:ss.SSS}] - %X{mchId} - %X{mchName}- %m%n
# 不在其他的日志文件输出里面输出
log4j.additivity.traceLogger = false复制代码
代码中 使用
private static Logger traceLogger = LoggerFactory.getLogger("traceLogger");复制代码
实战 springboot 2.0 整合 log4j
maven
排除任何的springboot日志因为这个是 springboot是自带的logback相关日志。
<exclusions>
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>复制代码
或者利用利用idea工具排查一下看看相关的日志。 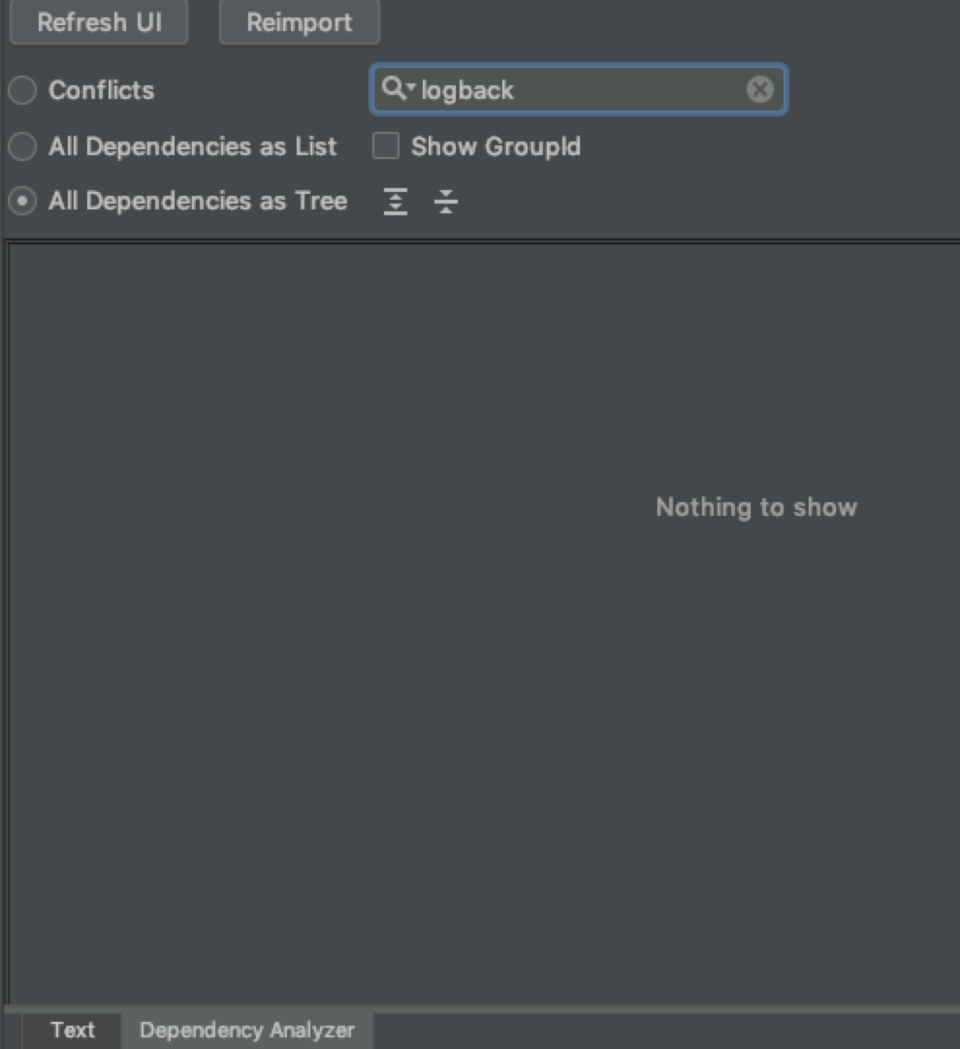
添加相关log4j依赖
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.28</version>
</dependency>复制代码
配置文件
# 表示开启debug级别 然后配置 三种默认输出,期中stdout控制台输出
log4j.rootLogger=DEBUG,file,stdout,err
# 日志输出的格式,详细上文说明
log4j.ConversionPattern=[account-service]%-d{yyyy-MM-dd HH:mm:ss-SS} [%l]-[%t]-[%p] %m%n
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=${log4j.ConversionPattern}
log4j.appender.file=org.apache.log4j.DailyRollingFileAppender
log4j.appender.file.File=/Applications/log/account-service.log
log4j.appender.file.DatePattern='.'yyyy-MM-dd
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=${log4j.ConversionPattern}
log4j.appender.err=org.apache.log4j.DailyRollingFileAppender
log4j.appender.err.File=/Applications/log/account-service-err.log
log4j.appender.err.DatePattern='.'yyyy-MM-dd
log4j.appender.err.Threshold=ERROR
log4j.appender.err.layout=org.apache.log4j.PatternLayout
log4j.appender.err.layout.ConversionPattern=${log4j.ConversionPattern}
# 自定义的业务日志
log4j.logger.traceLogger=INFO,trace
# 按照文件大小形式分类,没一个128M大小一共40个
log4j.appender.trace=org.apache.log4j.RollingFileAppender
log4j.appender.trace.File=/Applications/log/account-service-trace.log
log4j.appender.trace.MaxFileSize=128MB
log4j.appender.trace.Append=true
log4j.appender.trace.MaxBackupIndex=40
log4j.appender.trace.Threshold=INFO
log4j.appender.trace.layout=org.apache.log4j.PatternLayout
log4j.appender.trace.layout.ConversionPattern=${log4j.ConversionPattern}复制代码
假如拟采用的 lombok 可以这样在代码里面打印日志可以这样的优雅打印日志 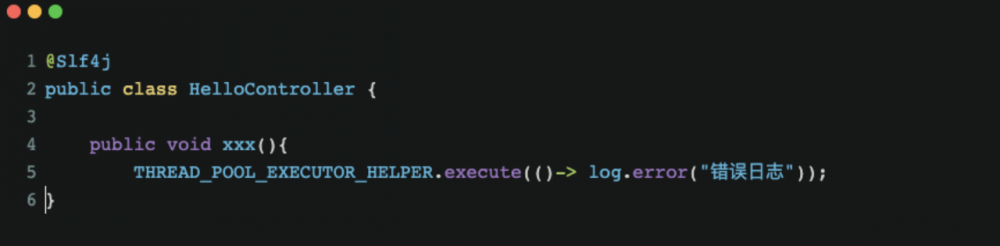
解决多线程log4j日志输出混乱的问题,每个线程输出独立的日志
可以注意到这里用的异步的方式在打印日志其实为了让大家看到另外的一个效果  OMP-ACTIVITY-THREAD-1 输出的就是线程名字。当时在配置线程池的时候给线程池配置的名字。这样子在多线程场景下,某一个线程输出的日志一目了然
OMP-ACTIVITY-THREAD-1 输出的就是线程名字。当时在配置线程池的时候给线程池配置的名字。这样子在多线程场景下,某一个线程输出的日志一目了然 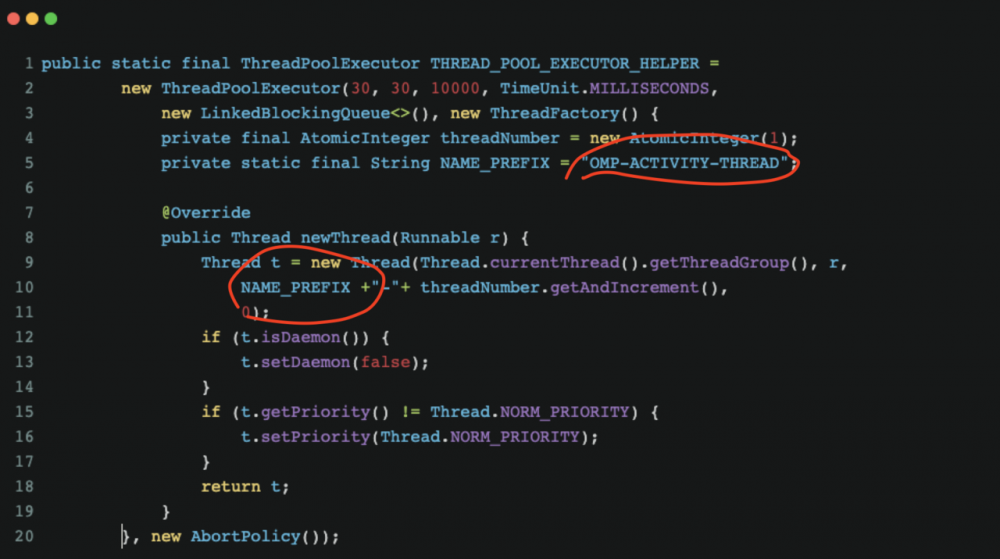 也就说 在多线程的场景下,可以采用配置线程名的方式,这样子就能看到多线程输出端日志了。
也就说 在多线程的场景下,可以采用配置线程名的方式,这样子就能看到多线程输出端日志了。
日志链路追踪
MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 和 logback 提供的一种方便在多线程条件下记录日志的功能。某些应用程序采用多线程的方式来处理多个用户的请求。在一个用户的使用过程中,可能有多个不同的线程来进行处理。典型的例子是 Web 应用服务器。当用户访问某个页面时,应用服务器可能会创建一个新的线程来处理该请求,也可能从线程池中复用已有的线程。在一个用户的会话存续期间,可能有多个线程处理过该用户的请求。这使得比较难以区分不同用户所对应的日志。当需要追踪某个用户在系统中的相关日志记录时,就会变得很麻烦。
一种解决的办法是采用自定义的日志格式,把用户的信息采用某种方式编码在日志记录中。这种方式的问题在于要求在每个使用日志记录器的类中,都可以访问到用户相关的信息。这样才可能在记录日志时使用。这样的条件通常是比较难以满足的。MDC 的作用是解决这个问题。
MDC 可以看成是一个与当前线程绑定的哈希表,可以往其中添加键值对。MDC 中包含的内容可以被同一线程中执行的代码所访问。当前线程的子线程会继承其父线程中的 MDC 的内容。当需要记录日志时,只需要从 MDC 中获取所需的信息即可。MDC 的内容则由程序在适当的时候保存进去。对于一个 Web 应用来说,通常是在请求被处理的最开始保存这些数据。
直接实战
一个工具类
import java.util.UUID;
import org.apache.log4j.MDC;
public class TraceUtil {
public static void traceStart() {
String traceId = generateTraceId();
MDC.put("traceId", traceId);
}
public static String getTraceId() {
return String.valueOf(MDC.get("traceId"));
}
public static void traceEnd() {
MDC.clear();
}
/**
* 生成跟踪ID
*/
private static String generateTraceId() {
return UUID.randomUUID().toString();
}
}
复制代码
演示效果
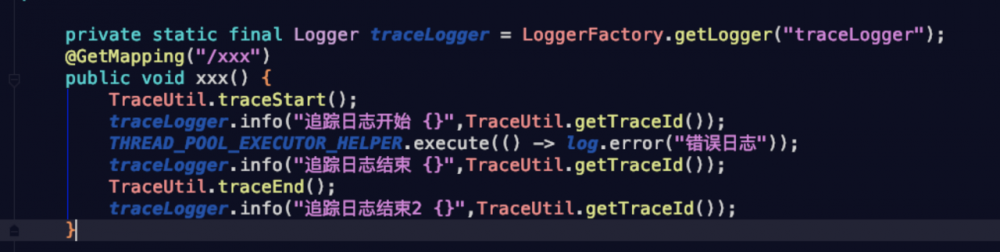
看一下打印的结果
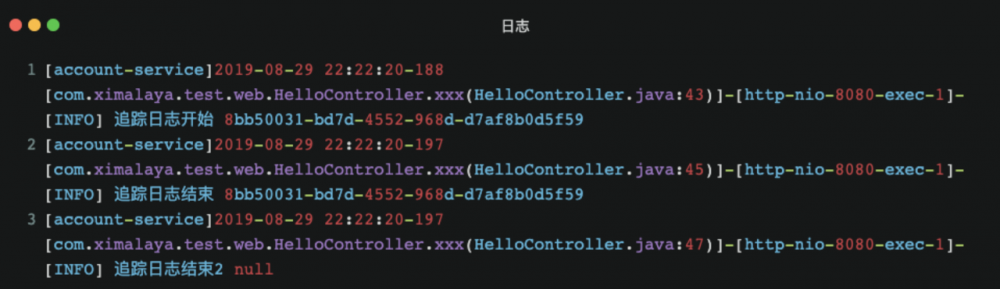
可以看到三行日志输出,在同一个线程最后释放后,日志链路id 是没有了。当然配合常用的一个过滤器,或者aop,就能跟踪到全链路的日志了。
更多文章进入
个人网站 [http://www.soulcoder.tech] (http://www.soulcoder.tech) 
正文到此结束
- 本文标签: value ACE springboot spring windows 网站 多线程 XML mmm id unix cat API DOM http AOP 测试 线程 IDE HTML core IO 服务器 tar 数据 App src Service rand root 调试 开源 线程池 Logback web https UI CTO final Logging 测试环境 apache servlet 配置 时间 参数 文章 bug java maven map 代码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

