详解JVM内存布局及GC原理,值得收藏
java发展历史上出现过很多垃圾回收器,各有各的适应场景,不仅仅是开发,作为运维也需要对这方面有一定的掌握,今天简单介绍一下java的内存布局以及各种垃圾回收器的原理。
JVM 内存布局
JVM从概念上大致分为6个(逻辑)区域:
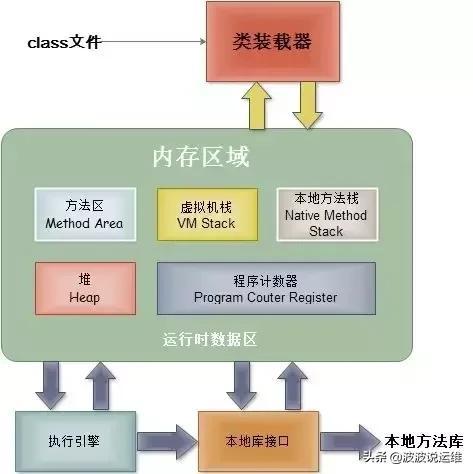
这6块区域按是否被线程共享,可以分为两大类:
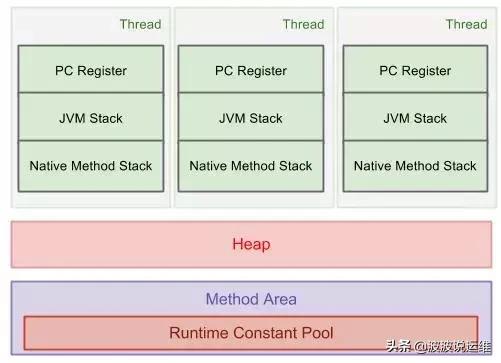
一类是每个线程所独享的:
- PC Register:也称为程序计数器, 记录每个线程当前执行的指令信。eg:当前执行到哪一条指令,下一条该取哪条指令。
- JVM Stack:也称为虚拟机栈,记录每个栈帧(Frame)中的局部变量、方法返回地址等。
- Native Method Stack:本地(原生)方法栈,顾名思义就是调用操作系统原生本地方法时,所需要的内存区域。
上述3类区域,生命周期与Thread相同,即:线程创建时,相应的区域分配内存,线程销毁时,释放相应内存。
另一类是所有线程共享的:
- Heap:即鼎鼎大名的堆内存区,也是GC垃圾回收的主站场,用于存放类的实例对象及Arrays实例等。
- Method Area:方法区,主要存放类结构、类成员定义,static静态成员等。
- Runtime Constant Pool:运行时常量池,比如:字符串,int -128~127范围的值等,它是Method Area中的一部分。
Heap、Method Area 都是在虚拟机启动时创建,虚拟机退出时释放。
总之,程序运行时,内存中的信息大致分为两类,一是跟程序执行逻辑相关的指令数据,这类数据通常不大,而且生命周期短;一是跟对象实例相关的数据,这类数据可能会很大,而且可以被多个线程长时间内反复共用,比如字符串常量、缓存对象这类。
将这两类特点不同的数据分开管理,体现了软件设计上“模块隔离”的思想。好比我们通常会把后端service与前端website解耦类似,也更便于内存管理。
GC垃圾回收原理
1. 哪些内存区域需要GC ?
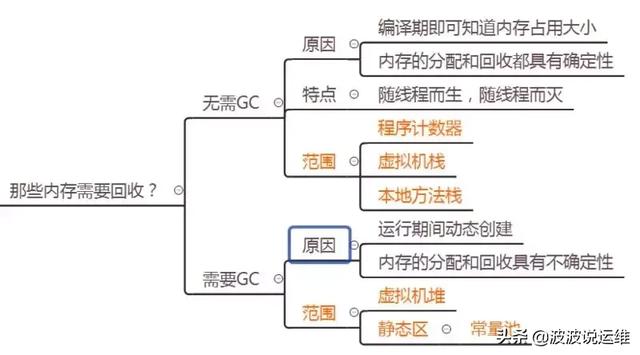
thread独享的区域:PC Regiester、JVM Stack、Native Method Stack,其生命周期都与线程相同(即:与线程共生死),所以无需GC。线程共享的Heap区、Method Area则是GC关注的重点对象。
2. 常用的GC算法
(1) mark-sweep 标记清除法
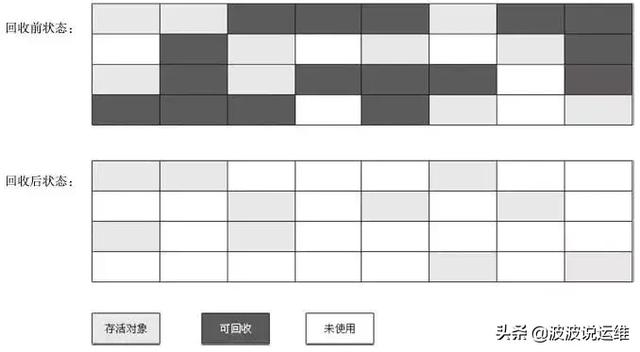
如上图,黑色区域表示待清理的垃圾对象,标记出来后直接清空。该方法简单快速,但是缺点也很明显,会产生很多内存碎片。
(2) mark-copy 标记复制法

思路也很简单,将内存对半分,总是保留一块空着(上图中的右侧),将左侧存活的对象(浅灰色区域)复制到右侧,然后左侧全部清空。避免了内存碎片问题,但是内存浪费很严重,相当于只能使用50%的内存。
(3) mark-compact 标记-整理(也称标记-压缩)法
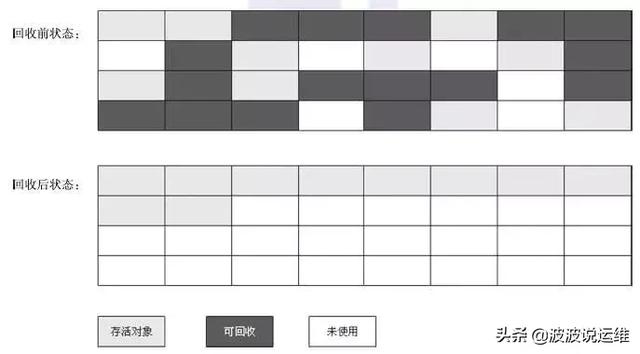
避免了上述两种算法的缺点,将垃圾对象清理掉后,同时将剩下的存活对象进行整理挪动(类似于windows的磁盘碎片整理),保证它们占用的空间连续,这样就避免了内存碎片问题,但是整理过程也会降低GC的效率。
(4) generation-collect 分代收集算法
上述三种算法,每种都有各自的优缺点,都不完美。在现代JVM中,往往是综合使用的,经过大量实际分析,发现内存中的对象,大致可以分为两类:有些生命周期很短,比如一些局部变量/临时对象,而另一些则会存活很久,典型的比如websocket长连接中的connection对象,如下图:
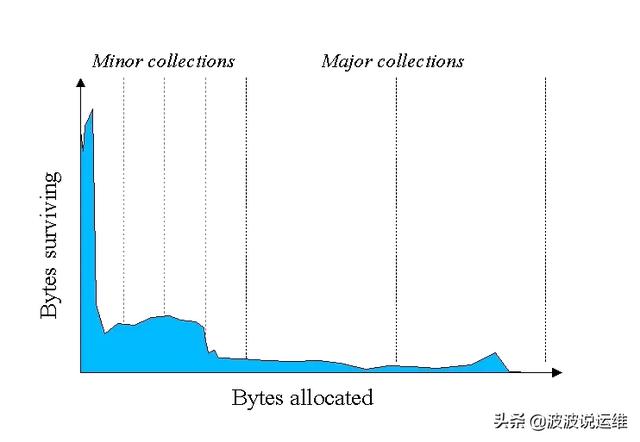
纵向y轴可以理解分配内存的字节数,横向x轴理解为随着时间流逝(伴随着GC),可以发现大部分对象其实相当短命,很少有对象能在GC后活下来。因此诞生了分代的思想,以Hotspot为例(JDK 7):
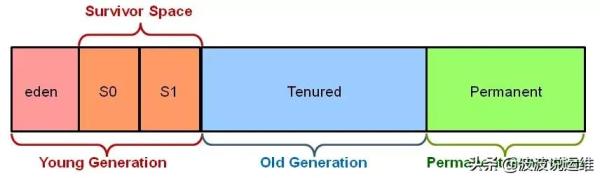
将内存分成了三大块:年青代(Young Genaration),老年代(Old Generation),永久代(Permanent Generation),其中Young Genaration更是又细为分eden,S0,S1三个区。
结合我们经常使用的一些jvm调优参数后,一些参数能影响的各区域内存大小值,示意图如下:
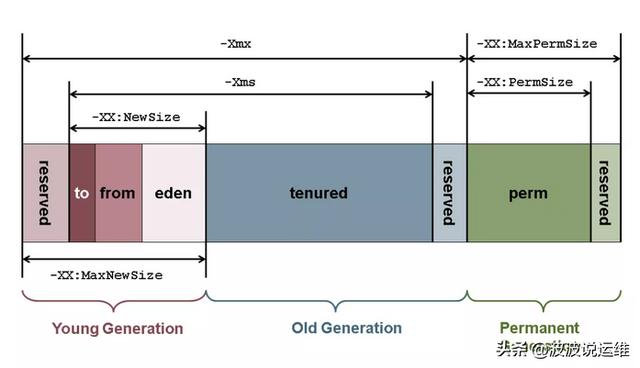
GC主要过程
下图引自阿里出品的《码出高效-Java开发手册》一书,梳理了GC的主要过程。
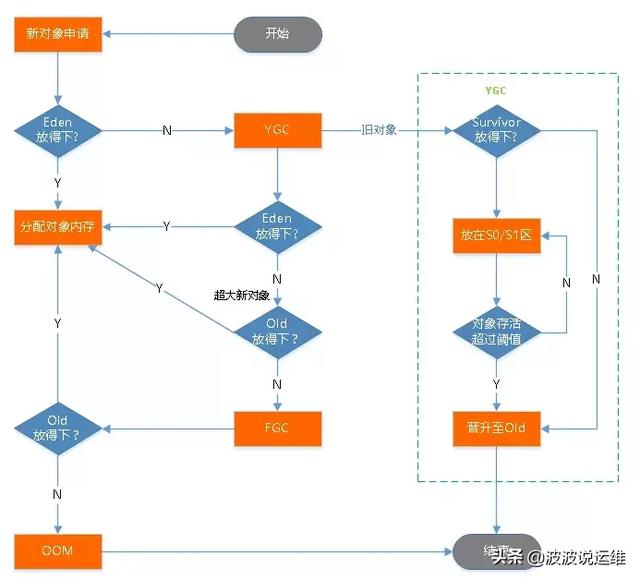
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

