总结一下最近的面试问题

-
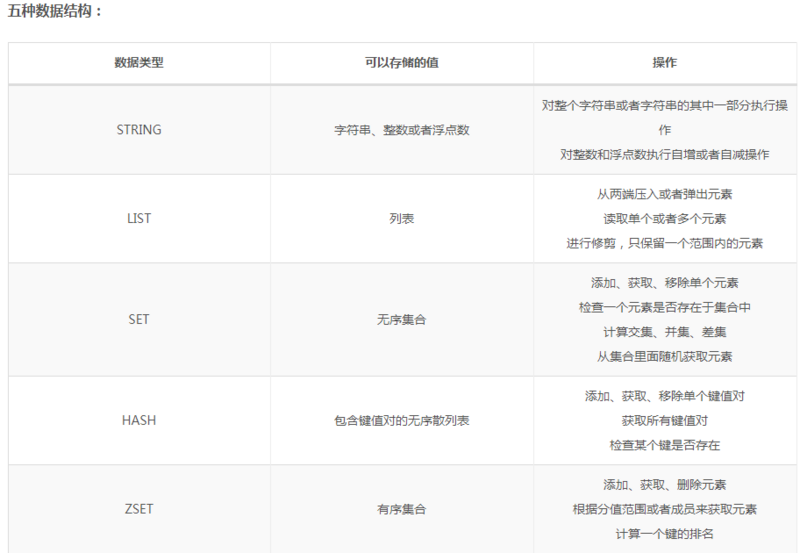
spring原理:Spring的两个核心概念是IOC(控制反转)和AOP(面向切面编程)。IOC(控制翻转)是一种编程范式,可以在一定程度上解决复杂系统对象耦合度太高的问题,并不是Spring的专利。IOC最常见的方式是DI(依赖注入),可以通过一个容器,将Bean维护起来,方便在其他地方直接使用,而不是重新new。可以说,IOC是Spring最基本的概念,没有IOC就没有Spring。AOP简单来说,它可以让编程人员在不修改对象代码的情况下,为这个对象添加额外的功能或者限制。这就是代理模式。Spring AOP之所以能够为动态生成的Bean提供代理,得益于PostProcessor接口。AOP流程图如下:

-
redis应用场景:1、 缓存
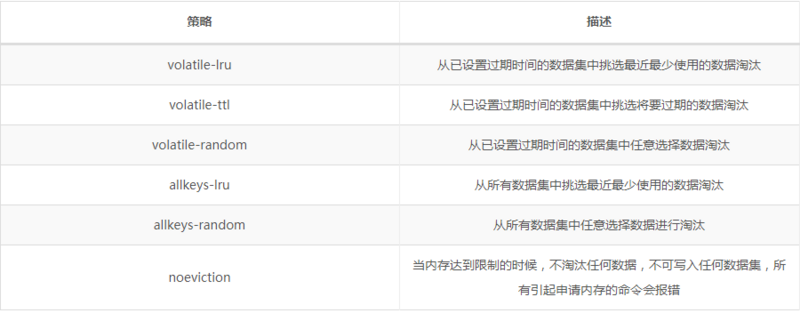
:合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能(超过指定时间的键会自动被删除),也提供了灵活的键淘汰策略(Redis支持6种策略)。
 2、 排行榜
:很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
2、 排行榜
:很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
 3、计数器:什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。incr命令为键key储存的数字值加上一。如果键key不存在,那么它的值会先被初始化为0,然后再执行INCR 命令。如果键 key储存的值不能被解释为数字,那么 INCR 命令将返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。INCR 命令会返回键 key在执行加一操作之后的值。
3、计数器:什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。incr命令为键key储存的数字值加上一。如果键key不存在,那么它的值会先被初始化为0,然后再执行INCR 命令。如果键 key储存的值不能被解释为数字,那么 INCR 命令将返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。INCR 命令会返回键 key在执行加一操作之后的值。
 4、 分布式会话
:集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。5、 分布式锁
:在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。setnx命令只在键 key 不存在的情况下,将键key的值设置为value。若键key已经存在,则 SETNX 命令不做任何动作。SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
4、 分布式会话
:集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。5、 分布式锁
:在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。setnx命令只在键 key 不存在的情况下,将键key的值设置为value。若键key已经存在,则 SETNX 命令不做任何动作。SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
 6、 社交网络
:点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。7、 最新列表
:Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。这样列表永远为N个ID,无需查询最新的列表,直接根据ID去到对应的内容页即可。8、 消息系统
:消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。
6、 社交网络
:点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。7、 最新列表
:Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。这样列表永远为N个ID,无需查询最新的列表,直接根据ID去到对应的内容页即可。8、 消息系统
:消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。 - mysql查询索引:SHOW INDEX FROM table_name;
- 消息队列应用场景:异步处理,应用解耦,流量削锋,日志处理和消息通讯。具体可见 https://segmentfault.com/a/11...
-
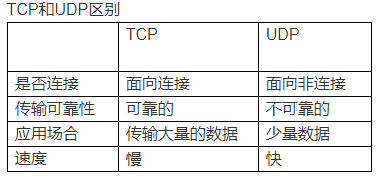
tcp udp区别:
- 泛型的好处:1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。没有泛型,这些假设就只存在于程序员的头脑中(或者如果幸运的话,还存在于代码注释中)。2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。3,潜在的性能收益。 泛型为较大的优化带来可能。在泛型的初始实现中,编译器将强制类型转换(没有泛型的话,程序员会指定这些强制类型转换)插入生成的字节码中。但是更多类型信息可用于编译器这一事实,为未来版本的 JVM 的优化带来可能。由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改。所有工作都在编译器中完成,编译器生成类似于没有泛型(和强制类型转换)时所写的代码,只是更能确保类型安全而已。
- 感谢以下几篇文章: https://m.php.cn/redis/422103... https://crazyfzw.github.io/20... https://www.jianshu.com/p/c40...
正文到此结束
- 本文标签: GitHub 字节码 key git ActiveMQ 安全 rabbitmq TCP spring 电商网站 压力 IO 管理 JVM 消息队列 tab 文章 京东 分布式 注释 浏览量 总结 数据库 ioc redis 索引 代码注释 编译 删除 集群 id 时间 并发 mysql 锁 bean 数据 session 程序员 PHP http 网站 MQ 代码 缓存 value https 社交网络 sql 分布式锁 UDP java src 互联网 AOP
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

