Java容器类
Java提供的容器类如List、Set、Map是语言的基础,熟练掌握是必备技能,本文就Java中容器相关的坑与知识做一个总结整理。本文涉及的代码摘自 OpenJDK jdk9-b94 ,部分逻辑在不同版本的实现有所差异。
List
- ArrayList :非线程安全,由数组实现,擅长随机访问
- Vector :同ArrayList,但是添加了线程安全支持
- LinkedList :非线程安全,由
双向链表实现(JDK1.6之前为循环链表),擅长插入、删除操作,不擅长随机访问 - CopyOnWriteArrayList :通过Immutable方式实现了线程安全,由数组实现,性质类似于ArrayList,但是由于CopyOnWrite的逻辑所以不适合大数据量使用
在内存使用方面,ArrayList会在结尾留有一定空闲余量,而LinkedList则是每个节点的内存使用量都比ArrayList大。LinkedList不是线程安全的,如果需要链表实现的线程安全的数据结构建议使用ConcurrentLinkedQueue、ConcurrentLinkedDeque。
Set
- HashSet :无序、唯一、允许Null、非线程安全。底层使用HashMap保存数据
- LinkedHashSet :有序(按插入顺序)、唯一、允许Null、非线程安全。继承自HashSet,内部由LinkedHashMap实现
- TreeSet :有序(可自定义compare顺序)、唯一、不允许Null,非线程安全。由红黑树实现
- CopyOnWriteArraySet :内部由CopyOnWriteArrayList实现,性质类似CopyOnWriteArrayList,但是做了Key的判断
Java没有提供Concurrent开头支持线程安全的Set类型,如果需要使用线程安全的Set我们可以通过线程安全的Map实现相关逻辑,如ConcurrentHashMap,通过put值相同的key来实现key的set属性。
当把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
Map
- HashMap :无序、唯一、允许Null、非线程安全。JDK1.8之前由数组+链表组成,1.8之后引入了当链表长度大于阈值(默认8)的时候将链表转为红黑的操作来优化哈希冲突时的搜索效率
- LinkedHashMap :有序(按插入顺序)、唯一、允许Null、非线程安全。继承自HashMap,在HashMap之外按插入顺序维护了一个双向链表以保证遍历对象的有序性
- TreeMap :有序(可自定义compare顺序)、唯一、不允许Null,非线程安全。由红黑树实现
- Hashtable :不允许Null,线程安全。数组+链表实现,为线程安全加了会锁住这个对象的全局锁,性能有较大牺牲,一般不使用
- ConcurrentHashMap :更高效线程安全的Map实现。底层数据结构于HashMap一致。线程安全方面在JDK1.8之前使用Segment对象将数据根据hash值分段,只锁部分数据性能更好。JDK1.8之后摒弃了Segment锁,使用synchronized和CAS来操作,性能进一步提升
HashMap中怎么计算Key的hash
HashMap通过key的hashCode经过扰动函数处理过后得到hash值,然后通过扰动函数 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的hash值以及key是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。所谓扰动函数指的就是HashMap的hash方法。使用hash方法也就是扰动函数是为了防止一些实现比较差的hashCode()方法以减少碰撞。下面是JDK 1.8以后 HashMap 的 hash 方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
哈希结果的取值范围是int,也就是-2147483648到2147483647,我们显然不能初始化着么长的数组,第一想到的就是对哈希结果除以key数组长度取余数,而取余操作在除数是2的整数次幂的时候正好有 hash%length==hash&(length-1) ,所以HashMap的长度总是2的整数次幂以确保hash函数的高性能。
如何选用集合
主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap.当我们只需要存放元素值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。
ArrayList的扩容
ArrayList默认构造的数组大小为0,每次扩容会添加当前容量的一半。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 计算新容量的大小
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
HashMap的扩容与拉链算法
上面说到HashMap的容量默认要求为2的整数次幂,jdk中HashMap默认大小为16,当当前数据大小大于 容量xloadFactor 时将出发扩容,扩容需要对所有数据进行rehash,是一个比较耗费资源的操作。另外当hash对应的链表元素大于 TREEIFY_THRESHOLD(默认为8)时会将链表转化为红黑树,当hash对应的链表元素小于 UNTREEIFY_THRESHOLD(默认为6)时会将红黑树转化为链表。
向HashMap中添加数据时会调用 putMapEntries 方法:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
// 容量超过threshold 时进行扩容
// 每次扩容时会重新计算 threshold = capacity x loadFactor
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
找到节点hash对应的链表或红黑树位置后, putVal 方法负责将值插入到相应结构中。如果定位到的数组位置没有元素就直接插入。如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
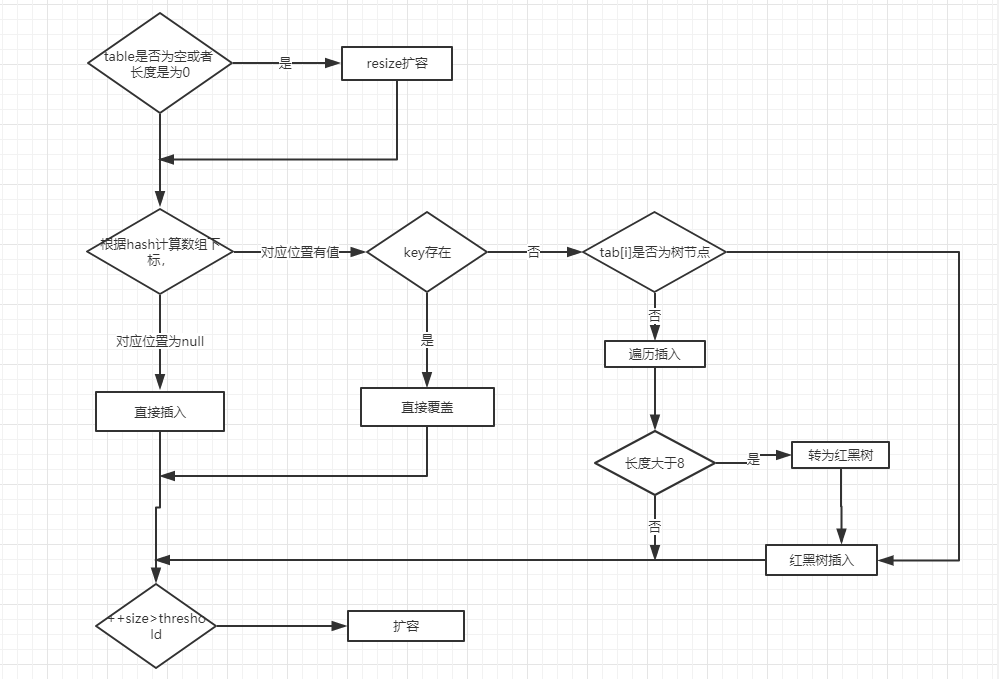
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
remove方法则是上述过程的逆过程。
正文到此结束
- 本文标签: 删除 ConcurrentHashMap tab 数据 key http HashTable 2019 java UI Collections src HashMap tk map 遍历 总结 id HashSet 安全 App final MQ synchronized 线程 CTO 锁 Collection equals CEO IO ArrayList https 代码 list queue LinkedList node 大数据 value
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

