DockOne微信分享(二二四):基于Kubernetes的DevOps平台实战
【编者的话】Kubernetes的出现让容器的调度管理变的简单,但是Kubernetes本身的“部署难”又让很多人止步,对该技术的普及也有一定的影响。文章首先,从Kubernetes的架构角度,为大家讲解一下从零部署一个生产可用的Kubernetes集群,并对Kubelet TLS Bootstrapping的原理进行讲解。
先说一下我们生产环境Kubernets集群部署,为方便后期维护及减少一层Docker封装,我们选择采用二进制方式部署Kubernetes集群。(kubeadm方式部署全部运行在Docker容器中、证书时长限制等;虽然降低部署门槛,但屏蔽了很多细节,遇到问题很难排查等。)
Kubernets集群部署流程:
- 网络、主机等规划
- 规划集群网络
- 规划主机集群架构(如节点多机房灾备等)
- 主机系统初始化
- 主机名
- 软件源
- 关闭swap
- 关闭防火墙
- 关闭SELinux
- 配置Chrony
- 安装依赖软件包
- 加载相关内核模块
- 内核优化
- 配置数据盘
- 签发集群证书
- 签发ca证书
- 签发etcd证书
- 签发admin证书
- 签发apiserver证书
- 签发metrics-server证书
- 签发controller-manager证书
- 签发scheduler证书
- 签发kube-proxy证书
- 部署etcd高可用集群
- etcd集群部署
- etcd数据备份
- apiserver的高可用配置
- haproxy+keepalived
- 部署Master节点
- 生成kuberctl kubeconfig,配置kubectl
- 安装配置kube-apiserver
- 安装配置kube-controller-mannager
- 安装配置kube-scheduler
- 部署Node节点
- 安装配置Docker
- 安装配置kubelet
- 安装配置kube-proxy
- 部署Calico
Kubernetes集群部署要点:
- 关闭非安全端口,通过--anonymous-auth=false关闭匿名请求,所有通信使用证书认证,防止请求被篡改;通过证书认证和授权策略(x509、token、RBAC)。
- 开启bootstrap token认证,动态创建token,而不是在apiserver中静态配置。
- 使用TLS bootstrap机制自动生成kubelet client和server证书,过期自动轮转(部分集群部署使用admin证书签发kubelet.kubeconfig,这样集群非常不安全)。
- etcd、master证书指定节点IP,限制访问,即便某个节点证书泄漏,在其他机器上也无法使用。
- 网络使用calico ipip
我已经将Kubernetes集群安装过程写成ansible-playbook,实现一键部署、扩容Kubernets 高可用集群 。Playbook包含了系统初始化、签发证书、部署etcd、部署Kubernetes、替换集群证书等。
我们DevOps平台对接了Ansible Playbook,可在DevOps平台上操作部署、扩容,配合工单系统,完成全自动化流程。
DevOps平台操作部署、扩容Kubernetes集群流程:
- 填写申请机器工单
- 选择用途为Kubernetes新建或者扩容
- 选择对应角色
- 工单审批通过后,自动申请机器
- 调用Ansible Playbook开始进行系统初始化
- 调用Ansible Playbook开始进行证书签发
- 调用Ansible Playbook开始进行etcd集群部署
- 调用Ansible Playbook开始进行节点扩容
同时也可以使用以下命令进行操作:
通过以下命令即可将一批刚刚安装好系统、配置好网络的机器部署为一套生产可用的Kubernetes集群:
ansible-playbook k8s.yml -i inventory
扩容Master节点:
ansible-playbook k8s.yml -i inventory -t init -l master ansible-playbook k8s.yml -i inventory -t cert,install_master
扩容Node节点:
ansible-playbook k8s.yml -i inventory -t init -l node ansible-playbook k8s.yml -i inventory -t cert,install_node
通过Playbook部署集群,可以在很短的时间内完成集群扩容。生产上使用本Playbook最高一次性扩容过50个Node节点。
这里先简单介绍下Kubelet TLS Bootstrapping和etcd的自动备份,其他部分就不再进一步讲解,具体详细部署大家可参考《 Kubernetes高可用集群之二进制部署 》。
Kubelet TLS Bootstrapping
在Kubernetes集群中,工作节点上的组件(kubelet和kube-proxy)需要与Kubernetes主组件通信,特别是kube-apiserver。为了确保通信保持私密,不受干扰,并确保群集的每个组件与另一个受信任组件通信,我们强烈建议在节点上使用客户端TLS证书。
引导这些组件的正常过程,特别是需要证书的工作节点,因此它们可以与kube-apiserver安全地通信,这可能是一个具有挑战性的过程,因为它通常超出了Kubernetes的范围,需要大量的额外工作。反过来,这可能会使初始化或扩展集群变得具有挑战性。
为了简化流程,从版本1.4开始,Kubernetes引入了证书请求和签名API以简化流程。
Kubernetes开启TLS认证后,每个N ode节点的kubelet都要使用由kube-apiserver的CA签发证书,才能与kube-apiserver进行通信,如果接入比较多的节点,为每个节点生成证书不太现实,Bootstrapping就是让kubelet先使用一个低权限用户连接到kube-apiserver,然后由kube-controller-manager为kubelet动态签发证书。再配合RBAC指定用户拥有访问哪些API的权限。
CSR请求
kubelet启动后会发起CSR请求,kube-apiserver收到CSR请求后,对其中的Token进行认证,认证通过后将请求的user设置为 system:bootstrap:<Token ID> ,group设置为 system:bootstrappers ,这一过程称为Bootstrap Token Auth。
kubelet发起的CSR请求都是由kube-controller-manager来做实际签发的,对于kube-controller-manager来说,TLS bootstrapping下kubelet发起的CSR请求大致分为以下三种:
- nodeclient:kubelet以
O=system:nodes和CN=system:node:(node name)形式发起的CSR请求 - selfnodeclient:kubelet client renew自己的证书发起的CSR请求(与上一个证书就有相同的O和CN)
- selfnodeserver:kubelet server renew自己的证书发起的CSR请求
使用Bootstrap Token时整个启动引导过程:
- 配置apiserver使用
Bootstrap Token Secret,替换以前使用token.csv文件 - 在集群内创建首次TLS Bootstrap申请证书的ClusterRole、后续renew Kubelet client/server的ClusterRole,以及其相关对应的ClusterRoleBinding;并绑定到对应的组或用户
- 配置controller-manager,使其可以自动签发相关证书和自动清理过期的TLS Bootstrapping Token
- 生成特定的包含TLS Bootstrapping Token的
bootstrap.kubeconfig以供kubelet启动时使用 - 配置kubelet,使其首次启动加载
bootstrap.kubeconfig并使用其中的 TLS Bootstrapping Token 完成首次证书申请 - controller-manager签发证书,并生成kubelet.kubeconfig,kubelet自动重载完成引导流程
- 后续kubelet自动renew相关证书
- 集群搭建成功后立即清除
Bootstrap Token Secret,或等待Controller Manager待其过期后删除,以防止被恶意利用
下面讲一下etcd备份。
etcd备份
etcd是Kubernetes集群中的一个十分重要的组件,用于保存集群所有的网络配置和对象的状态信息。一旦出现问题或者数据丢失,影响将无法估计。所以,我们一定要做好etcd的数据备份。
这里利用Kubernetes的cronjob对etcd进行备份,并挂载外部存储,将数据备份在外部存储上。
以下是使用cronjob备份的yaml:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: etcd-backup
spec:
schedule: "10 1 * * *"
concurrencyPolicy: Allow
failedJobsHistoryLimit: 3
successfulJobsHistoryLimit: 3
jobTemplate:
spec:
template:
spec:
containers:
- name: etcd-backup
imagePullPolicy: IfNotPresent
image: k8sre/etcd:v3.3.15
env:
- name: ENDPOINTS
value: "https://172.16.70.131:2379,https://172.16.70.132:2379,https://172.16.70.133:2379"
command:
- /bin/bash
- -c
- |
set -ex
ETCDCTL_API=3 /opt/etcd/etcdctl /
--endpoints=$ENDPOINTS /
--cacert=/certs/ca.pem /
--cert=/certs/etcd.pem /
--key=/certs/etcd.key /
snapshot save /data/backup/snapshot-$(date +"%Y%m%d").db
volumeMounts:
- name: etcd-backup
mountPath: /data/backup
- name: etcd-certs
mountPath: /certs
restartPolicy: OnFailure
volumes:
- name: etcd-backup
persistentVolumeClaim:
claimName: etcd-backup
- name: etcd-certs
secret:
secretName: etcd-certs
下面来讲一下,我们的CI/CD是如何实现的。
先给大家看下我们大概的架构图:
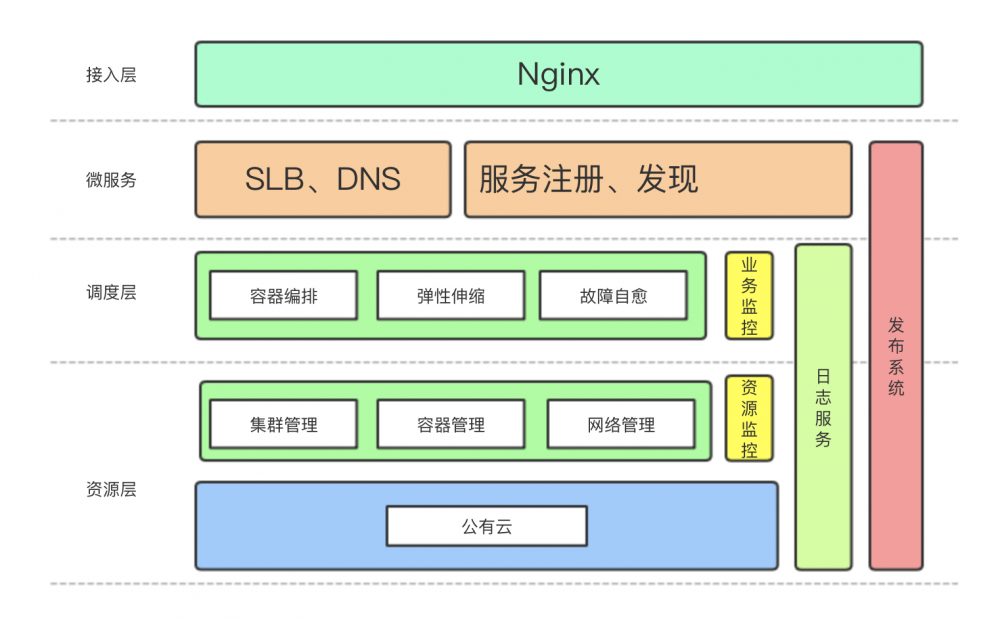
我们业务主要的开发语言包含Java、PHP、Golang、NodeJs以及少部分Python,涉及开发语言较广,CI、CD需求各种各样等原因,我们选择使用Jenkins Pipeline来完成CI、CD的相关工作,全部逻辑通过Groovy语言编写。并通过Jenkins Agent的方式适配公司所有开发语言代码的CICD。同时支持虚拟机和Kubernetes部署。
Jenkins Master及所有agent都部署在Kubernetes集群,并使用PVC挂载一块极速NAS作为数据同步。下面给大家看下我们部分部署yaml:
jenkins-master.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins-master
namespace: jenkins
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: jenkins-master
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: jenkins-master
namespace: jenkins
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: jenkins-master
namespace: jenkins
spec:
serviceName: "jenkins-master"
replicas: 1
selector:
matchLabels:
app: jenkins-master
template:
metadata:
labels:
app: jenkins-master
spec:
serviceAccount: jenkins-master
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: app
operator: In
values:
- jenkins
containers:
- name: jenkins
image: k8sre/jenkins:master
imagePullPolicy: Always
securityContext:
runAsUser: 0
privileged: true
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 50000
name: agentport
protocol: TCP
resources:
limits:
cpu: 2
memory: 4Gi
requests:
cpu: 2
memory: 4Gi
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 10
timeoutSeconds: 3
periodSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 10
timeoutSeconds: 3
periodSeconds: 5
volumeMounts:
- name: jenkins-data
mountPath: /data/jenkins
- name: sshkey
mountPath: /root/.ssh/id_rsa
subPath: id_rsa
readOnly: true
- name: jenkins-docker
mountPath: /var/run/docker.sock
- name: jenkins-maven
mountPath: /usr/share/java/maven-3/conf/settings.xml
subPath: settings.xml
readOnly: true
volumes:
- name: sshkey
configMap:
defaultMode: 0600
name: sshkey
- name: jenkins-docker
hostPath:
path: /var/run/docker.sock
type: Socket
- name: jenkins-maven
configMap:
name: jenkins-maven
- name: jenkins-data
persistentVolumeClaim:
claimName: jenkins
---
apiVersion: v1
kind: Service
metadata:
name: jenkins-master
namespace: jenkins
spec:
ports:
- name: web
port: 8080
protocol: TCP
targetPort: 8080
- name: agent
port: 50000
protocol: TCP
targetPort: 50000
selector:
app: jenkins-master
agent-go.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: agent-go
namespace: jenkins
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: agent-go
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: agent-go
namespace: jenkins
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: agent-go
namespace: jenkins
spec:
serviceName: "agent-go"
replicas: 1
selector:
matchLabels:
app: agent-go
template:
metadata:
labels:
app: agent-go
spec:
serviceAccount: agent-go
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- jenkins
containers:
- name: jenkins
image: k8sre/jenkins:go
imagePullPolicy: Always
securityContext:
runAsUser: 600
privileged: true
env:
- name: "ENV_NAME"
value: "go"
- name: "JKS_SECRET"
value: "xxxxxxxxxxxxxx"
- name: "JKS_DOMAINNAME"
value: "https://ci.k8sre.com"
- name: "JKS_ARGS"
value: "-Xmx4g -Xms4g"
- name: "JKS_DIR"
value: "/data/jenkins"
volumeMounts:
- mountPath: /data/jenkins
name: jenkins-data
volumes:
- name: jenkins-data
persistentVolumeClaim:
claimName: jenkins
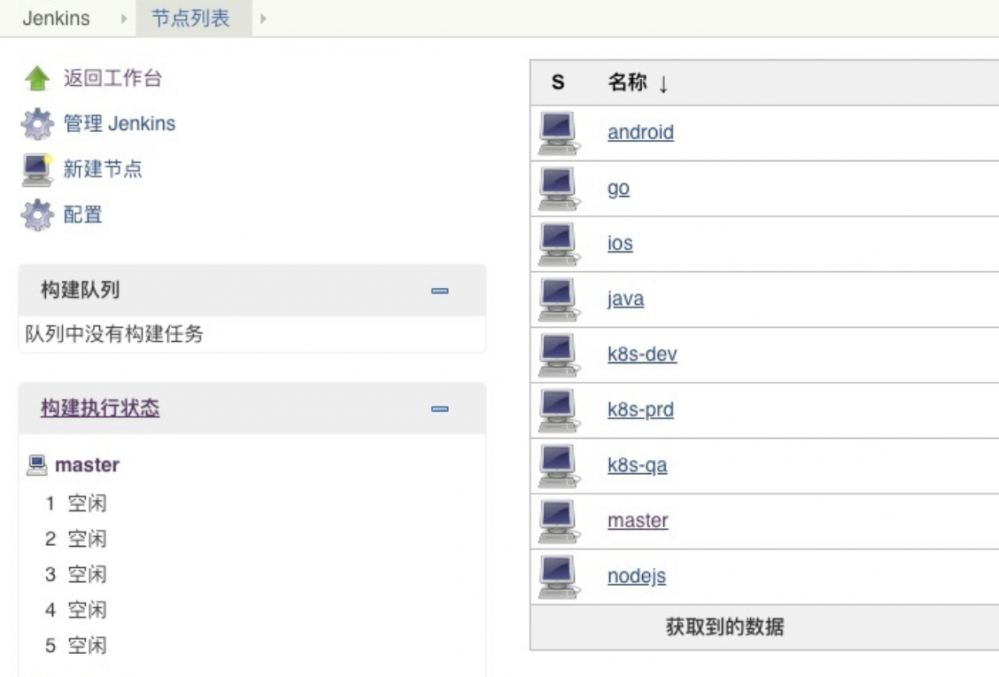
下图是我们目前Jenkins在使用的节点:
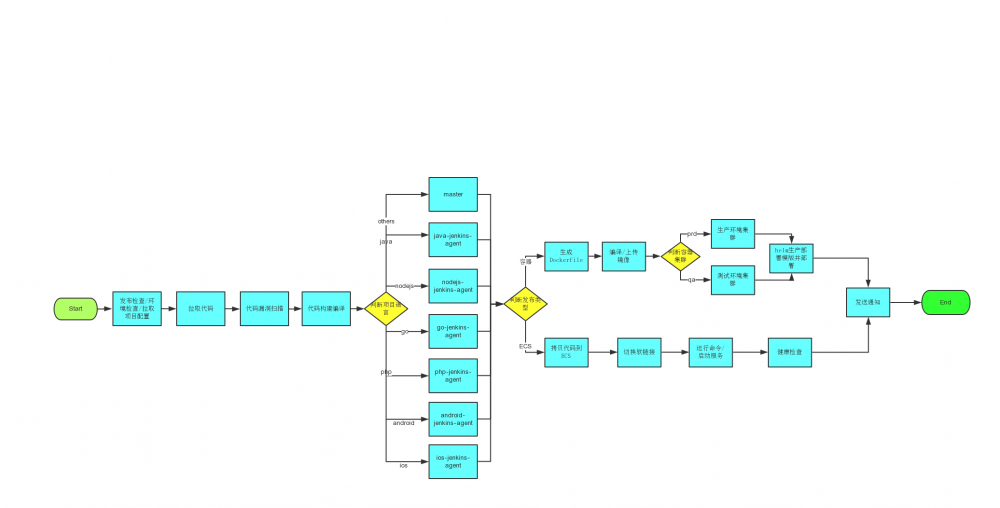
我们CI/CD的流程:
- ---> 在DevOps平台创建项目(DevOps平台提供项目管理、配置管理、JOB处理、日志查看、监控信息、Kubernetes容器Web Terminal等管理功能,CICD后续流程全部为Jenkins处理)
- --->选择是容器部署or虚机部署
- --->按照提示填写相关配置(包含开发语言、GIT仓库、编译命令、域名、容器内可写目录、运行命令、运行端口、资源限制、健康检查等)
- --->保存配置
- --->触发JOB
- --->发布前检查/拉取项目配置(同时对项目配置进行校验是否符合规范)
- --->拉取业务代码
- --->漏洞扫描
- --->编译构建
- --->根据配置选择对应语言的编译节点
- --->判断虚机还是容器部署,选择不同的部署流程
- ---> 容器部署会根据项目配置生成Dockerfile并构建上传镜像(适配所有业务Dockerfile自动生成,并支持自定义)
- --->选择环境(prd or pre or qa or dev )
- --->helm使用模版替换项目配置进行部署(Helm Chart模版适配了所有业务需求,并支持自定义。默认部署Deployment、Service、Ingress、HPA)
- --->部署结束后发送部署详情通知
以下是CI/CD的流程图:
Jenkins Pipeline测试环境阶段视图:

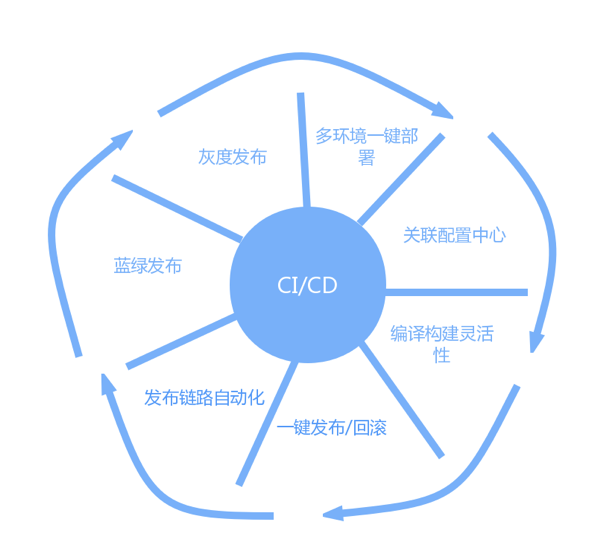
一些亮点功能:
有很多案例使用gitlab-ci实现的CI/CD,我们通过调研发现gitlab-ci有一定的侵入性,而且Pipeline支持比较弱。我们使用Jenkins Pipeline完成了公司全部的CI/CD需求,其中还包含了运维相关系统的部署、安卓打包及渠道包打包、IOS打包,并提供了二维码展示,方便测试或运营人员快速下载安装。
使用Groovy完成整套流程,方便、易用便于维护,但是其中处理逻辑相对复杂,需要对业务非常了解,并且掌握Groovy语言。同时选择使用Helm部署也遇到不少问题,Release名称在不同namespace不能重用(helm3已经支持),模版使用APIVersion与实际部署资源对象APIVersion不一致(影响不大),同版本代码部署不更新(通过添加自定义annotation实现支持)等等。另外,我也测试了Helm 3,前期bug太多,属于完全不可用状态,最近新出了alpha2版本,修复了很多bug,可以考虑测试使用了。
未来工作
- 目前Kubernetes配置建议使用yaml配置文件进行配置,参数形式即将删除,后期逐步一一替换。
- apiserver的健康检查问题,目前使用4层代理,无法对服务状态进行校验,后续需要对服务健康状态进行校验。
- 拆分CI/CD,增加制品库;改造编译节点动态创建Pod进行编译,任务完成后删除Pod,提高资源利用率,提高编译构建的并发量。
- 使用helm repo,将chart保存在repo,让部署更简洁。
Q&A
Q:请问是通过Jenkinsfile来控制版本管理吗,是否使用了Jenkins library,多个环境的情况下,是部署一个Jenkins Master,还是每个Kubernetes集群都带有一个Jenkins Master?
A:Jenkinsfile实现整个CI/CD流程,使用Git对Jenkinsfile代码进行版本管理;目前没有使用Jenkins library,但是Jenkins library的方式正在重写过程中,还没有完成;多环境的实现是只在一个集群部署一套Jenkins Master+Jenkins Agent,不同的环境通过不同Agent实现。
Q:每个Jenkins的Job里写一个Jenkinsfile的repo?这样是不是太浪费了。每个repo就一个Jenkinsfile文件(多环境可能有多个分支)。我们是直接写成了Jenkinsfile模板,然后Jenkins构建参数传入的。不知道老师是如何权衡的?
A:不是的,所有Job使用一个Jenkinsfile。每个Job就是传递一些基础参数,大多数配如编译命令,部署配置等,都是在DevOps平台先行配置好之后,触发Job构建之后从DevOps拉取参数配置。
Q:为什么拉取代码后就要进行Sonar代码扫描呢?研发的代码都没有集成编译验证,扫描代码有什么意义?
A:不是拉取代码前进行的扫描,是拉取代码完成后进行的扫描。方便对接多语言。这个看取舍的,我们因为涉及语言种类比较多,不太容易顾全所有的语言,而且前期我们PHP语言的业务较多。
Q:你们生产环境也关闭防火墙了吗?不用防火墙吗?还是你们用的其他的安全措施?
A:我们生产环境防火墙是关闭的,因为我们使用的是公有云环境,策略都是通过公有云安全组实现的。
Q:同Ansible集成那部分怎么实现的?中间涉及到传参数,例如IP地址,端口号,服务名称,是通过什么控制的?
A:基础环境信息,都在inventory里维护。其他的一些参数放在一个group_vars中。
Q:Node节点使用的是动态token还是apiserver内置的静态的token进行Bootstrap的?
A:动态token,不在apiserver的配置里指定token.csv。
Q:Jenkinsfile使用文档较少,可以提供在此遇到的坑列举几个典型吗?谢谢!
A:使用的话,可以去参考有一本Groovy的书。遇到的坑的话,大多数是CI/CD逻辑的问题,比如说,我们会有一个容器运行用户的配置,实际业务场景中有使用root的,有使用普通用户的,还会针对不同的环境适配不同的用户配置,逻辑处理出错就会导致实际部署后,Pod运行异常。
Q:请问主机系统初始化这一块对系统的发行版和内核版本有什么要求和建议?看到一些Docker的问题是因为系统内核版本太低 (3.10内核kmem account泄漏bugs导致节点NotReady),请问你们是如何选择的?
A:目前仅支持Redhat、CentOS,内核版本是3.10,没有进行升级。以我们集群运行这么长时间看,虽然有NotReady现象,但是概率比较小,固没对考虑对内核升级。
Q: 请问下集群规模是怎么样的,Node节点是怎么做资源保护的?
A:目前600个Node节点,我们目前是监控整体集群水位,在达到60%左右就会对集群进行扩容。
Q:如何实现灰度发布以及蓝绿部署?
A:基于Ingress实现的,部分是使用公有云的负载均衡,通过API实现切换。
Q:目前我们使用的gitlab-ci-runner部署于Kubernetes之外实现CI/CD。发现gitlab-ci在实际使用中,经常会遇到卡死报错。请问下,相比Jenkins 做CI/CD是会有什么优势,之前并没有使用过Jenkins?
A:gitlab-ci生产环境中,我们也没有使用,我们调研的结果是:1、有侵入性;2、Pipeline功能较弱,但是有一个好处是遇到错误好像还可以继续执行。Jenkins遇到错误会中断流程。
Q:基于kubeadm+Calico,空闲时CPU占用达到30-40%是否正常?
A:实际使用中没有使用过kubeadm部署,因为封装东西太多,不易于排查问题。空闲时CPU到30-40,需要具体情况分析。
Q:600个Node节点都遇到过什么问题, 有什么需要注意的?
A:前期网络上遇到的问题比较多,还包含calico bug。后面多数是一些业务使用上导致的问题,还有业务增量之后引发的各种问题。
Q:请问是怎么配置的多个不同功能的Jenkins-slave Pod的还有Jenkins-slave镜像怎么做的,还有一个任务中有发布和回滚怎么做呢,老师的CI/CD人工干预的地方在哪里?
A:Jenkins-slave镜像实际就是把Jenkins的agent.jar运行在容器中。发布就如同前面所讲。回滚最终是调用helm rollback。CI/CD人工干预的话都是通过配置项来控制的。
以上内容根据2019年9月3日晚微信群分享内容整理。 分享人 马松林,现任DaoCloud交付架构师,负责Kubernetes、DCE、DMP、中间件、EFK平台的架构设计、技术方案评审等 。 DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiese,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。
正文到此结束
- 本文标签: Select REST 运营 下载 IO token java 2019 编译 maven tar 配置 需求 DOM 软件 src 文章 自动生成 灰度发布 rmi 部署 自动备份 jenkins 安装 代码 Kubernetes 二维码 lib python Service Dockerfile 目录 并发 备份 自动化 负载均衡 map API App 组织 client 项目管理 Security bug 云 测试环境 安装配置 db js 安全 管理 CTO value Uber ACE Authorization 高可用 linux Agent root node https apr 漏洞 域名 key 同步 删除 Jobs id Proxy PHP 端口 git centos Bootstrap TCP XML 开发 http Job Master 架构师 web 认证 ip 集群 数据 Docker 参数 主机 IOS Haproxy 架构设计 ssh 测试 mina swap UI 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

