ArrayList源码分析-JDK1.8
1.概述
ArrayList 本质上是一个数组,它内部通过对数组的操作实现了 List 功能,所以 ArrayList 又被叫做动态数组.每个 ArrayList 实例都有容量,会自动扩容.它可添加 null ,有序可重复,线程不安全. Vector 和 ArrayList 内部实现基本是一致的,除了 Vector 添加了 synchronized 保证其线程安全.
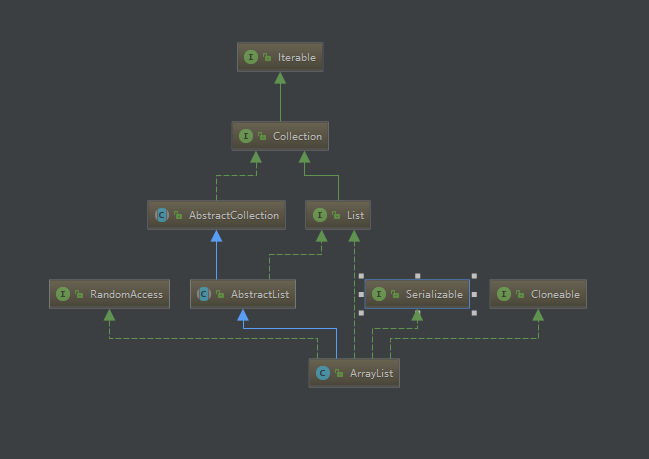
1.1继承体系
2.源码解析
2.1属性
/**
* 默认初始容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 初始容量为0时,elementData指向此对象(空元素对象)
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 调用ArrayList()构造方法时,elementData指向此对象(默认容量空元素对象)
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 用于存储集合元素,非private类型能够简化内部类的访问(在编译阶段)
*/
transient Object[] elementData;
/**
* 包含的元素个数
*/
private int size;
为什么 DEFAULT_CAPACITY 这种变量为什么要声明为 private static final 类型
private 是为了把变量的作用范围控制在类中.
static 修饰的变量是静态变量. JVM 只会为静态变量分配一次内存.这样无论对象被创建多少次,此变量始终指向的都是同一内存地址.达到节省内存,提升性能的目的.
final 修饰的变量在被初始化后,不可再被指向别的内存地址,以防变量的地址被篡改.
2.2构造方法
无参构造方法
public ArrayList() {
//无参构造器方法,将elementData指向DEFAULTCAPACITY_EMPTY_ELEMENTDATA
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
指定容量构造方法
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//initialCapacity大于0时,将elementData指向新建的initialCapacity大小的数组.
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//initialCapacity为空时,将elementData指向EMPTY_ELEMENTDATA
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: " +
initialCapacity);
}
}
指定集合构造方法
public ArrayList(Collection<? extends E> c) {
//将elementData指向c转换后的数组
elementData = c.toArray();
if ((size = elementData.length) != 0) {
//c.toArray 可能不会返回Object[],所以需要手动检查下.关于这点,会单独讲解下,看3.3
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
//如果elementData.length为0,将elementData指向EMPTY_ELEMENTDATA.
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList 的无参构造方法使用频率是非常高的,在第一次添加元素时,会将 capacity 初始化为10.在我们知道 ArrayList 中需要存储多少元素时,使用指定容量构造方法,可避免扩容带来的运行开销,提高程序运行效率.当我们需要复用 Collection 对象时,使用指定集合构造方法.
2.3插入
2.3.1添加元素到列表尾部
add(E e) 源码
//将指定的元素添加到列表的末尾
public boolean add(E e) {
//确保内部容量,如果容量不够则计算出所需的容量值.
ensureCapacityInternal(size + 1);
//将元素插入到数组尾部,size加一.
elementData[size++] = e;
return true;
}
add(E e) 方法的平均时间复杂度是 O(1) .它的流程大体上分为两步:
- 保证内部容量可用;
- 将元素添加到数组尾部;
第一步就是自动扩容机制,具体分析参看 2.3.3 .
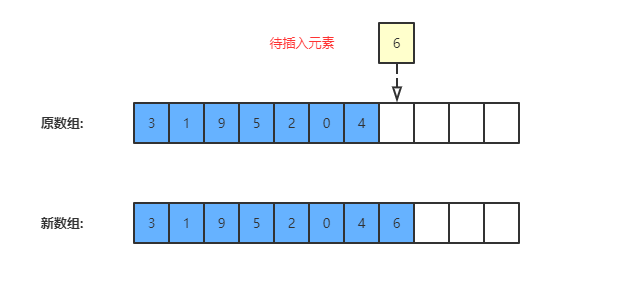
第二步则是在确保有可用容量的基础上,在尾部添加元素,如下图:
2.3.2将元素插入到指定位置
add(int index, E element) 源码
//在列表的指定位置上添加指定元素,在添加之前将在此位置上的元素及其后面的元素向右移一位.
public void add(int index, E element) {
//检查索引是否越界
rangeCheckForAdd(index);
//确保内部容量,如果容量不够则计算出所需的容量值.
ensureCapacityInternal(size + 1); // Increments modCount!!
//将index及index之后的元素向右移一位.
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//将新元素插入到index处.
elementData[index] = element;
//元素个数加一.
size++;
}
//检查索引是否越界
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
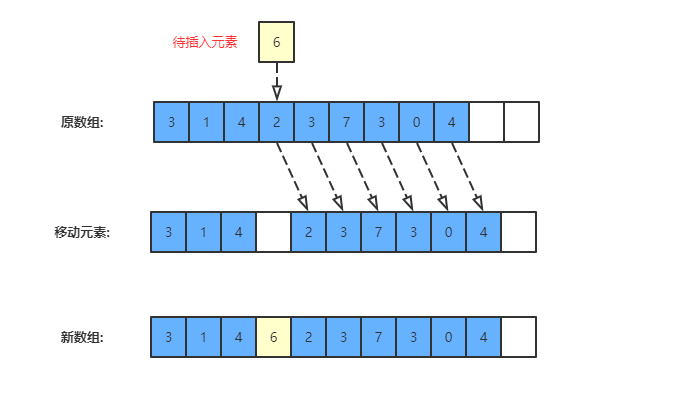
add(int index, E element) 的平均时间复杂度是 O(N) .所以在大容量的集合中不要频繁使用此方法,否则可能会产生效率问题.在指定位置添加元素的流程如下图所示:
2.3.3自动扩容
ensureCapacityInternal(int minCapacity) 源码
//是否需要扩容
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
//计算容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//如果elementData指向DEFAULTCAPACITY_EMPTY_ELEMENTDATA,返回DEFAULT_CAPACITY和minCapacity中的较大值.
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//否则直接返回minCapacity
return minCapacity;
}
//确保明确的容量
private void ensureExplicitCapacity(int minCapacity) {
//修改次数加一
modCount++;
//如果minCapacity大于elementData数组长度,那么进行扩容.
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//要分配的最大数组大小
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 增加容量确保数组至少能够容纳最小容量参数指定的元素个数.
*
* @param minCapacity 所需的最小容量
*/
private void grow(int minCapacity) {
//声明oldCapacity为elementData长度
int oldCapacity = elementData.length;
//将newCapacity声明为oldCapacity的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果newCapacity小于minCapacity,将newCapacity指向minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果newCapacity超出了最大数组长度,调用hugeCapacity()方法计算newCapacity.
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//根据newCapacity生成一个新的数组,并将elementData老数据放入elementData中.
elementData = Arrays.copyOf(elementData, newCapacity);
}
/**
*
* @param minCapacity 最小容量
* @return 计算后的容量
*/
private static int hugeCapacity(int minCapacity) {
//如果minCapacity小于0,抛出内存溢出异常.
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//比较得出所需容量
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
自动扩容的流程参看上面代码,总结几个要点:
- 如果使用的是
new ArrayList()构造方法,在添加第一个元素时,容量会被设置为DEFAULT_CAPACITY(10)大小. - 容量会被扩容为之前的1.5倍
- 如果扩容后的容量大于
MAX_ARRAY_SIZE,那么将Integer.MAX_VALUE作为容量.
2.4删除
remove(int index)
//移除指定索引位置元素
public E remove(int index) {
//index越界检查
rangeCheck(index);
modCount++;
//获取将要删除的元素
E oldValue = elementData(index);
//获取将要移动的元素个数
int numMoved = size - index - 1;
if (numMoved > 0)
//将index之后的元素向左移一位
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
//size减一,并将elementData数组最后一个元素指向null,让GC进行操作
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
remove(Object o)
//删除指定元素
public boolean remove(Object o) {
//如果对象为null,删除数组中的第一个为null的元素.没有null元素的话则不会变化
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
//删除数组中的第一个为o的元素,没有则不操作.
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//省略了越界检查,而且不会返回被删除的值,反映了JDK将性能优化到极致.
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
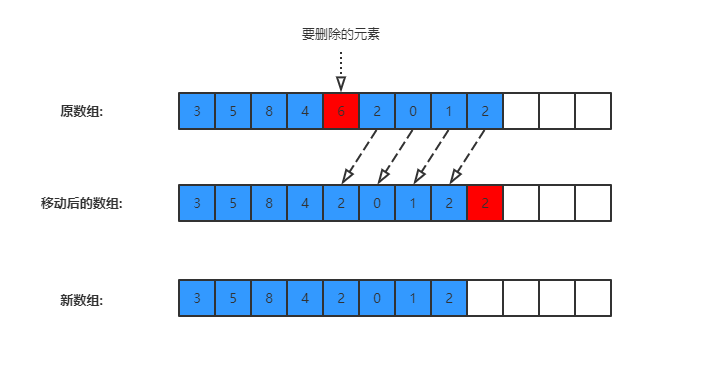
删除操作的平均时间复杂度是 O(N) ,其主要步骤是:
null size
具体步骤如下图所示:
2.5遍历
ArrayList 实现了 RandomAccess 接口. RandomAccess 是标识接口,标识实现类能够快速随机访问存储元素.因为 ArrayList 的底层是数组,通过下标 index 访问.所以在 ArrayList 元素量较大时,应当使用普通 for 循环,也就是通过下标进行访问.而 LinkedList 此层是链表,不具备快速随机访问的能力,因此没有实现 RandomAccess 接口,推荐使用 forEach 遍历(也就是 Iterator 遍历).
测试代码:
@Test
public void test6() {
//实现了RandomAccess接口,底层是数组的ArrayList测试
List<Long> arrayList = new ArrayList<>(150000000);
Random random = new Random();
//为了更好的展示测试结果,避免程序运行时间过长,arrayList和linkedList添加元素的个数不同.
for (int i = 0; i < 100000000; i++) {
arrayList.add(random.nextLong());
}
System.out.println("======ArrayList======");
traverseByLoop(arrayList);
traverseByIterator(arrayList);
System.out.println("======LinkedList======");
//没有实现RandomAccess接口,底层是链表的LinkedList测试
LinkedList<Long> linkedList = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
linkedList.add(random.nextLong());
}
traverseByLoop(linkedList);
traverseByIterator(linkedList);
}
//普通for循环进行遍历
public void traverseByLoop(List<Long> list) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println("RandomAccess遍历用时:" + (endTime - startTime) + "ms");
}
//Iterator遍历
public void traverseByIterator(List<Long> list) {
long startTime = System.currentTimeMillis();
Iterator<Long> iterator = list.iterator();
while (iterator.hasNext()) {
iterator.next();
}
long endTime = System.currentTimeMillis();
System.out.println("Iterator遍历用时:" + (endTime - startTime) + "ms");
}
运行 test6() 方法,控制台输出:
======ArrayList====== RandomAccess遍历用时:4ms Iterator遍历用时:10ms ======LinkedList====== RandomAccess遍历用时:5572ms Iterator遍历用时:3ms
3.其它细节
3.1 fail-fast 机制
在 Iterator 被创建后,如果 List 对象不是调用 iterator 的 remove() 或 add(Object obj) 方法更改内部结构. iterator 就会抛出 ConcurrentModificationException .以此避免在迭代过程中 List 对象不可知的变化.这个机制只能用来侦测异常的操作,并不能作为并发操作的保障.在 JDK1.5 新增的 forEach 循环,其本质就是用迭代器遍历.下面用 forEach 语法来对 fail-fast 机制进行测试.
@Test
public void test1() {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 3));
for (Integer num : list) {
if (1 == num) {
list.remove(num);
}
}
System.out.println(list);
}
由于在遍历过程中调用了 List 的 remove() 方法,导致程序检测到非法修改,抛出异常.
3.2 fail-fast 失效
在 forEach 中删除 List 的倒数第二个元素, fail-fast 不会生效.
@Test
public void test2() {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 2));
for (Integer num : list) {
if (1 == num) {
list.remove(num);
}
}
System.out.println(list);
}
forEach 是 java 的语法糖,为了搞清楚为啥出现上面的问题,我们将上面的代码转换为 Iterator 遍历.
@Test
public void test3() {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 2));
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
if (1 == next) {
list.remove(next);
}
}
System.out.println(list);
}
首先看看 list.iterator() 的源码,看看这个 Iterator 是啥?
public Iterator<E> iterator() {
return new Itr();
}
Itr 类是 ArrayList 的内部类,咱来看看源码.
private class Itr implements Iterator<E> {
//下一个要返回元素的索引,默认为0.
int cursor;
//之前返回元素的索引,默认为-1.
int lastRet = -1;
//保存创建时modCount的值
int expectedModCount = modCount;
Itr() {
}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
//fail-fast检测
checkForComodification();
//将i值声明为cursor
int i = cursor;
//index越界检查
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
//如果i值大于等于当前数组的长度,fail-fast
if (i >= elementData.length)
throw new ConcurrentModificationException();
//光标加一
cursor = i + 1;
//对lastRet赋值并返回值.
return (E) elementData[lastRet = i];
}
//每次操作时比较expectedModCount和modCount的值,若不一致,抛出ConcurrentModificationException
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
从 while (iterator.hasNext()) 开始分析,第一次进入 hasNext() 方法. cursor 为0, size 为2,返回 true ,进入循环体.然后进入 next() 方法,正常执行, cursor 变为1 , lastRet 变为0.然后开始执行 ArrayList 的 remove() 方法, modCount 变为1, size 变为1 .这时候再进入第二次循环,执行 hasNext() 方法, cursor 是1 , size 也是1 ,返回 false ,退出循环体.因此 fail-fast 失效.所以不要在 forEach 循环中使用非 Iterator 的方法进行增删操作, fail-fast 也不能完全避免数据被更改的风险,从源头规避风险是首选.
3.3 c.toArray() 返回非 Object[]
在 ArrayList 的集合构造器源码中有 c.toArray might (incorrectly) not return Object[] 这句注释.就上网查了下这个问题.我们先来看下代码:
@Test
public void test5() {
//获取并输出Object数组类型
Object[] objArr = new Object[0];
//class [Ljava.lang.Object;
System.out.println(objArr.getClass());
//通过Arrays.asList()方法构建List对象.该对象的class不是Object[]类型.
List<Integer> list1 = Arrays.asList(1, 2, 3);
//class [Ljava.lang.Integer;
System.out.println(list1.toArray().getClass());
//通过new ArrayList构造器创建List对象
ArrayList<Integer> list2 = new ArrayList<>(Arrays.asList(4, 5, 6));
//class [Ljava.lang.Object;
System.out.println(list2.toArray().getClass());
}
控制台输出:
class [Ljava.lang.Object; class [Ljava.lang.Integer; class [Ljava.lang.Object;
可以看到通过 Arrays.asList(1, 2, 3) 创建的对象 class 不是 Object[] 类型.至于具体原因不再分析,感兴趣的朋友研究下哈.
3.4 elementData 为啥定义为 transient
ArrayList 自己根据 size 序列化真实的元素,而不是根据数组的长度序列化元素,减少了空间占用.
4.参考
田小波-ArrayList 源码分析
彤哥读源码-死磕 java集合之ArrayList源码分析
IT从业者说-RandomAccess 这个空架子有何用?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

