并发编程之java锁的升级与对比
前言:
一、文章导图
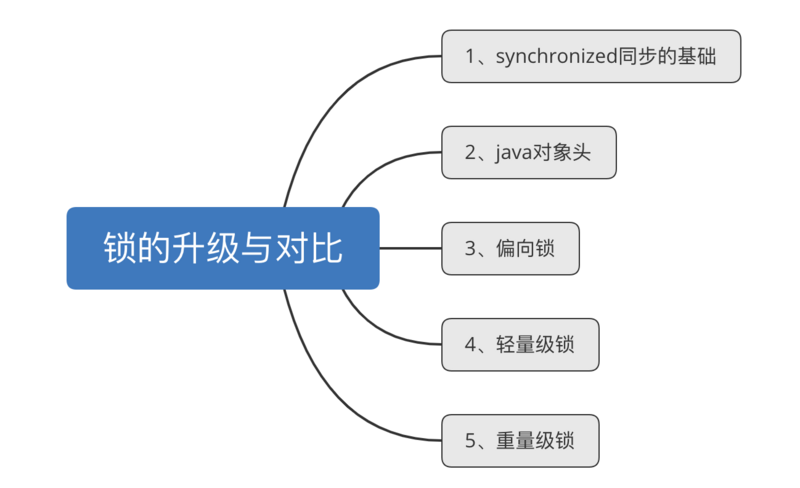
二、锁的升级与对比
1、synchronized实现同步的基础
java中每个对象都可以作为一个锁,具体的表现有以下三种形式:
- 普通方法同步,锁为当前实例对象
- 静态方法同步,锁为当前类的Class对象
- 方法块同步,锁为synchronized后括号中填写的对象
当一个线程试图访问同步代码块时,必须首先获取到锁,退出同步代码块时或抛出异常必须释放锁。
JVM基于进入与退出Monitor对象实现方法同步与代码块同步,不过两者的实现细节不太一样,可参见如下字节码所示。
public class SynchronizedDemo {
/**
* 同步方法
*/
public synchronized void testSynchronizedMethod () {
System.out.println("test synchronized method");
}
/**
* 同步静态方法
*/
public synchronized static void testSynchronizedStaticMethod () {
System.out.println("test synchronized static method");
}
/**
* 方法同步块
*/
public void testSynchronizedMethodBlock() {
synchronized (this) {
System.out.println("test synchronized method block");
}
}
}
进入java文件所在目录,通过命令行进行编译:javac SynchronizedDemo.java
然后同目录下通过如下命令,进行查看编译后字节码的详细信息:javap -verbose SynchronizedDemo.class
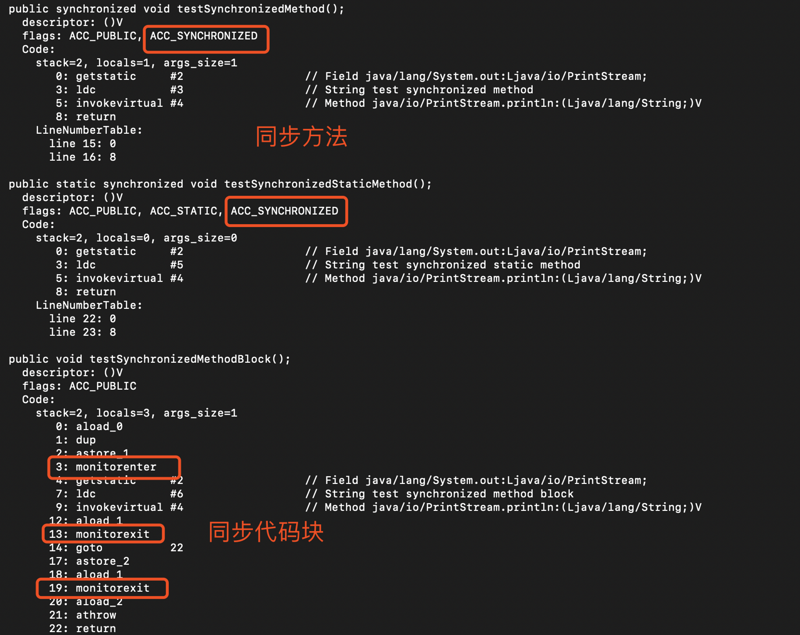
如图,任何对象有一个Monitor与之对应,线程执行到monitorenter时会尝试获取Monitor对象的所有权,即尝试获取对象上的锁。
Monitor作为操作系统的一种原语,具体由相应的编程语言实现。每个Monitor对象又包括:
- _owner:记录当前持有的锁的线程,也可以了理解成锁的临界区
- _entrySet:一个队列,记录所有阻塞等待锁的线程
- _waitSet:一个队列,记录所有调用wait未被唤醒的线程
当一个线程访问Object锁时,会被放入_entrySet中等待,如果该线程获取到锁,成为当前锁的_owner;期间,线程逻辑上缺少外部条件时,线程通过调用wait方法释放锁,进入到_waitSet队列,等到条件满足时,又被唤醒与_entrySet一起竞争_owner;这个外部条件在monitor机制中称为条件变量。
2、java对象头
Java对象包括了对象头、属性字段、补齐区域等。
对象头在最前端,包括了两部分(非数组类型)或三部分(数组类型,多存在数据的长度),结构如下所示
| 长度(32位机/64位机 bit) | 内容 | 说明 |
|---|---|---|
| 32/64 | Mark Word | 存储对象的hashCode和锁信息等 |
| 32/64 | Class Metadata Address | 存储到对象类型数据的指针 |
| 32/32 | Array Length | 数组的长度(如果对象是数组) |
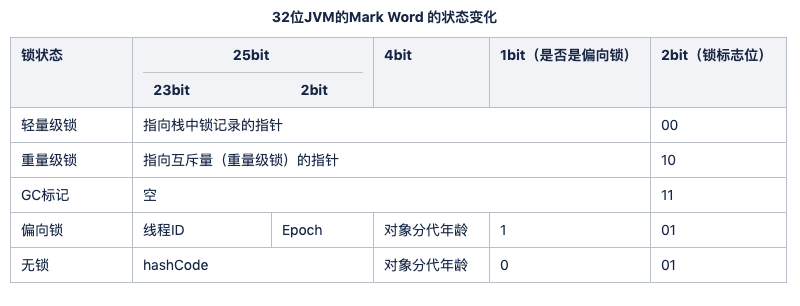
对象头的Mark Word会有指向管程Monitor的指针。
其中Mark Word的存储数据随着锁标志的变化如下:
3、偏向锁
java SE 1.6引入偏向锁与轻量级锁后,锁一共有4中状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁和重量级锁状态。且锁会随着竞争情况逐步升级,但不可降级(基于JVM的一个假定:“假定一旦破坏了上一级锁的升级,就认为该假定以后也不成龙”)。
为了让线程获取锁的代价更低而引入偏向锁,因为多线程中,有些情况下,获取锁的线程同时只会有一个。
如下,线程1演示了偏向锁初始化的流程,线程2演示了偏向锁撤销的流程。
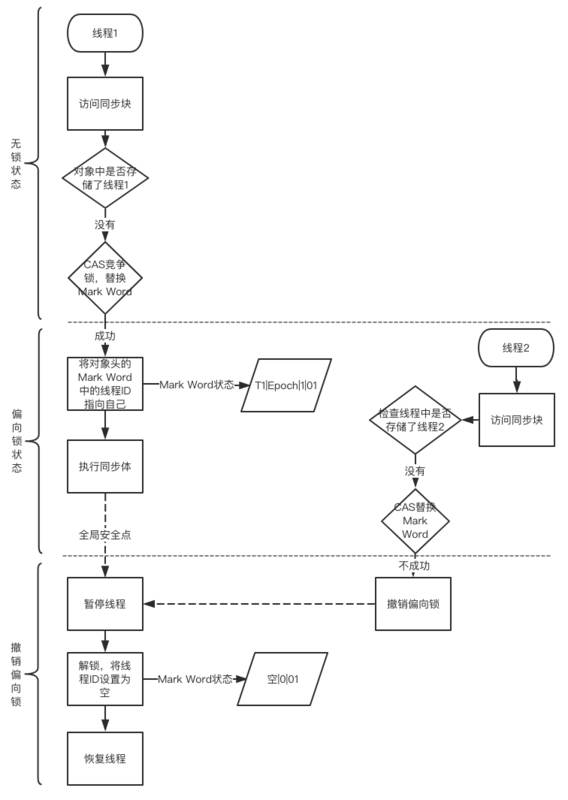
- 线程1访问同步代码块,确定锁的标志为01,非偏向对象时,会尝试CAS竞争
- 竞争成功后,将锁对象头的Mark Word中的线程ID指向自己,此时锁的标志为01,为偏向锁
- 执行访问体
- 此时线程2访问同步块,确定锁的标志为01,为偏向对象时,会尝试CAS将对象头的偏向锁指向当前线程2
- 替换失败(线程1偏向锁),开始撤销偏向锁
- 待到全局安全点,暂停线程1(原持有偏向锁的线程),如果线程1方法体执行完或处于未活动状态,则将线程ID置空,此时处于无锁状态
- 恢复线程1(原持有偏向锁的线程);偏向锁偏向线程2。
偏向锁默认是开启的,可使用JVM参数关闭:-XX:-UseBiasedLocking,那么程序默认会进入轻量级锁
4、轻量级锁
引入轻量级锁,为了不申请互斥量,包括系统调用引起的内核态与用户态的切换、线程阻塞造成的线程切换等。
在线程中,虚拟机会在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称Displaced Mark Word。
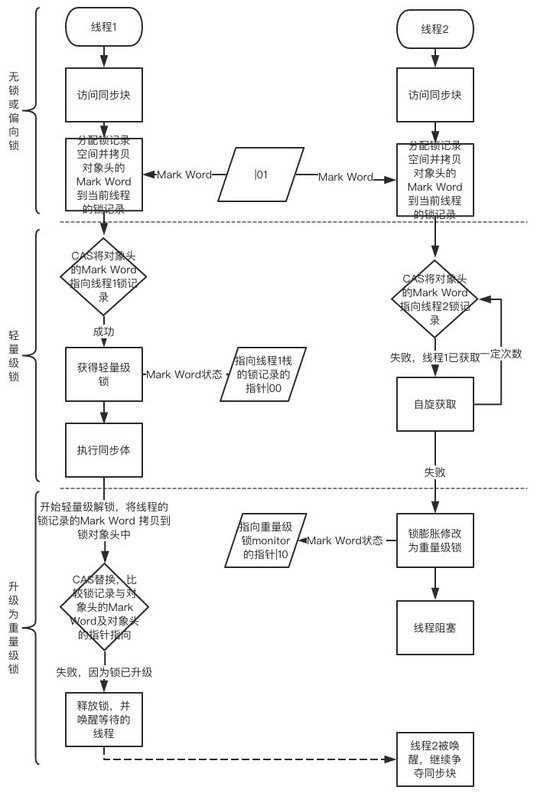
- 线程1访问同步代码块,确定锁的标志为01(偏向锁升级或偏向锁关闭),进行获取轻量级锁,线程2同理
- 线程1分配本线程栈的锁记录空间,并拷贝锁对象的Mark Word到当前线程栈的锁记录中
- 线程2分配本线程栈的锁记录空间,并拷贝锁对象的Mark Word到当前线程栈的锁记录中
- 线程1尝试使用CAS替换锁对象头的Mark Word指向锁记录的指针,成功后,线程1获取到轻量级锁
- 线程2尝试使用CAS替换锁对象头的Mark Word指向锁记录的指针,失败,因为线程已获得锁,此时线程2自旋
- 线程2自旋一定次数后,失败,锁膨胀为重量级锁,并阻塞本线程(线程2)
- 线程1同步方法体执行完,CAS替换Mark Word,失败,因为线程2在竞争锁资源
- 线程1释放锁并唤醒等待的线程,等待的线程2被唤醒,重新争夺访问同步块。
5、重量级锁
内置锁在java中被抽象为监视器锁(monitor),对于重量级锁,监视器锁直接对应底层操作系统中的互斥量(mutex),这种同步成本非常高,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等。
关于不同锁的优缺点对比,如下所示
| 锁 | 有点 | 缺点 | 使用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法时相比仅存在纳秒级的差距;毕竟仅第一执行CAS操作 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步的场景 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度;相比偏向锁,获取和释放锁均执行一次CAS操作 | 如果使用得不到锁竞争的线程,会使用自旋会消耗CPU资源 | 追求响应时间,同步块执行速度非常快 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量,同步块执行速度较长 |
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

