JDK 13 快来了,JDK 8 的这几点应该看看

说明
jdk8虽然出现很久了,但是可能我们还是有很多人并不太熟悉,本文主要就是介绍说明一些jdk8相关的内容。
主要会讲解:
-
lambda表达式
-
方法引用
-
默认方法
-
Stream
-
用Optional取代null
-
新的日志和时间
-
CompletableFuture
-
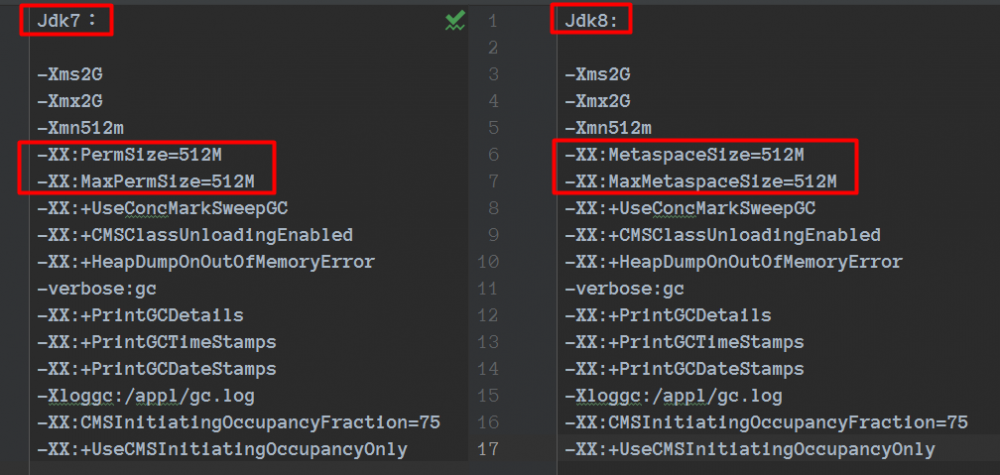
去除了永久代(PermGen) 被元空间(Metaspace)代替
我们来看看阿里规范里面涉及到jdk8相关内容:






jdk8开篇
https://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html

主要有:
1:lambda表达式:一种新的语言特性,能够把函数作为方法的参数或将代码作为数据。lambda表达式使你在表示函数接口(具有单个方法的接口)的实例更加紧凑。
2:方法引用 是lambda表达式的一个简化写法,所引用的方法其实是lambda表达式的方法体实现,这样使代码更容易阅读
3:默认方法:Java 8引入default method,或者叫virtual extension method,目的是为了让接口可以事后添加新方法而无需强迫所有实现该接口的类都提供新方法的实现。也就是说它的主要使用场景可能会涉及代码演进。
4:Stream 不是 集合元素,也不是数据结构,它相当于一个 高级版本的 Iterator,不可以重复遍历里面的数据,像水一样,流过了就一去不复返。它和普通的 Iterator 不同的是,它可以并行遍历,普通的 Iterator 只能是串行,在一个线程中执行。操作包括:中间操作 和 最终操作(只能操作一遍) 串行流操作在一个线程中依次完成。并行流在多个线程中完成,主要利用了 JDK7 的 Fork/Join 框架来拆分任务和加速处理。相比串行流,并行流可以很大程度提高程序的效率
5:用Optional取代null
6:新的日志和时间,可以使用Instant代替Date LocalDateTime代替Calendar DateTimeFormatter代替SimpleDateFormat
7:CompletableFuture:CompletableFuture提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,并且提供了函数式编程的能力,可以通过回调的方式处理计算结果,也提供了转换和组合 CompletableFuture 的方法。
8:去除了永久代(PermGen) 被元空间(Metaspace)代替 配置:-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=80m 代替 -XX:PermSize=10m -XX:MaxPermSize=10m
lambda
JDK8最大的特性应该非lambda莫属!

IDEA工具自动提示:

lambda语法结构 :
完整的Lambda表达式由三部分组成:参数列表、箭头、声明语句;
(Type1 param1, Type2 param2, ..., TypeN paramN) -> { statment1; statment2; //............. return statmentM;}
绝大多数情况,编译器都可以从上下文环境中推断出lambda表达式的参数类型,所以参数可以省略:
(param1,param2, ..., paramN) -> { statment1; statment2; //............. return statmentM;}
当lambda表达式的参数个数只有一个,可以省略小括号:
param1 -> { statment1; statment2; //............. return statmentM;}
当lambda表达式只包含一条语句时,可以省略大括号、return和语句结尾的分号:
param1 -> statment
在那里以及如何使用Lambda????
你可以在函数式接口上面使用Lambda表达式。
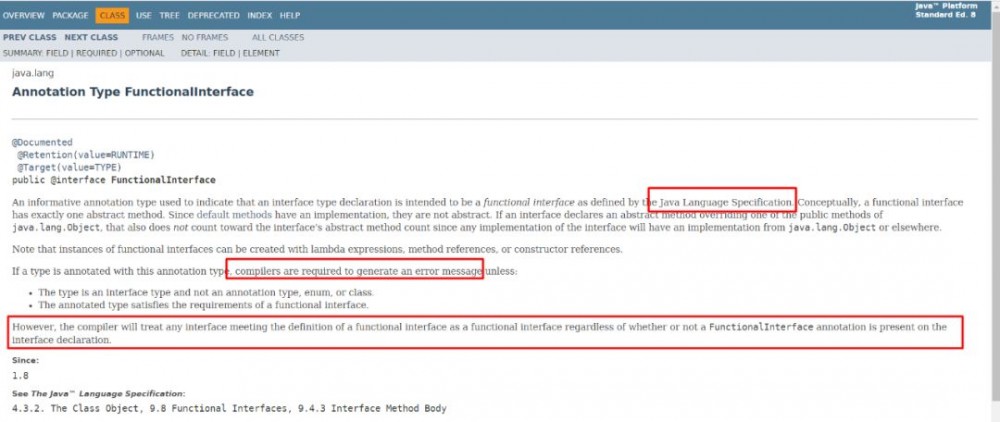
备注: JDK定义了很多现在的函数接口,实际自己也可以定义接口去做为表达式的返回,只是大多数情况下JDK定义的直接拿来就可以用了。
Java SE 7中已经存在的函数式接口:
-
java.lang.Runnable
-
java.util.concurrent.Callable
-
java.security.PrivilegedAction
-
java.util.Comparator
-
java.util.concurrent.Callable
-
java.io.FileFilter
-
java.beans.PropertyChangeListener
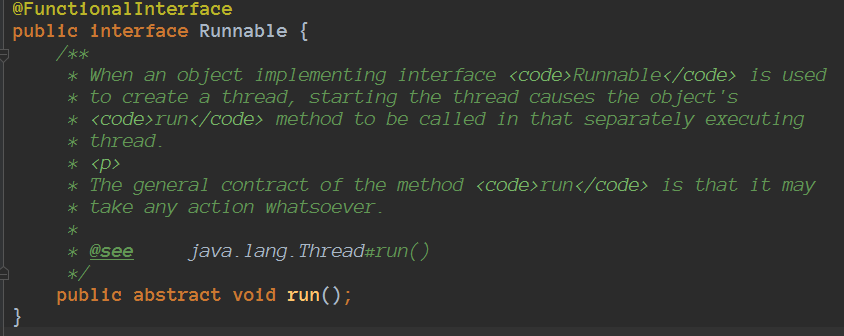
除此之外,Java SE 8中增加了一个新的包: java.util.function ,它里面包含了常用的函数式接口,例如:
-
Predicate——接收T对象并返回boolean -
Consumer——接收T对象,不返回值 -
Function——接收T对象,返回R对象 -
Supplier——提供T对象(例如工厂),不接收值
随便看几个:
默认方法
Java 8 引入了新的语言特性——默认方法(Default Methods)。
Default methods enable new functionality to be added to the interfaces of libraries and ensure binary compatibility with code written for older versions of those interfaces.
默认方法允许您添加新的功能到现有库的接口中,并能确保与采用旧版本接口编写的代码的二进制兼容性。
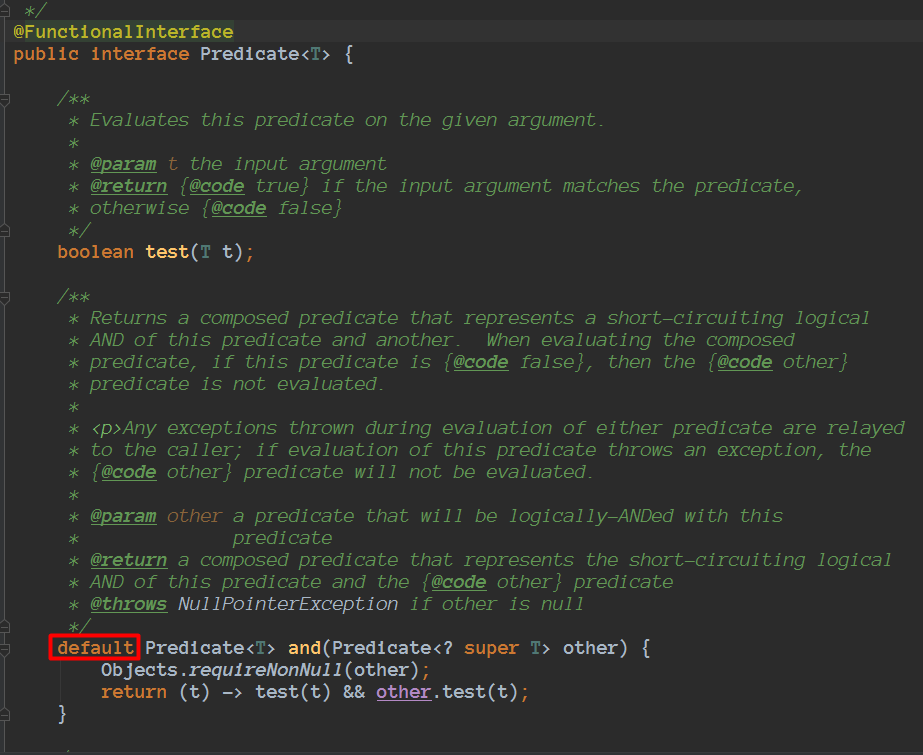
默认方法是在接口中的方法签名前加上了 default 关键字的实现方法。
为什么要有默认方法
在 java 8 之前,接口与其实现类之间的 耦合度 太高了(tightly coupled),当需要为一个接口添加方法时,所有的实现类都必须随之修改。默认方法解决了这个问题,它可以为接口添加新的方法,而不会破坏已有的接口的实现。这在 lambda 表达式作为 java 8 语言的重要特性而出现之际,为升级旧接口且保持向后兼容(backward compatibility)提供了途径。
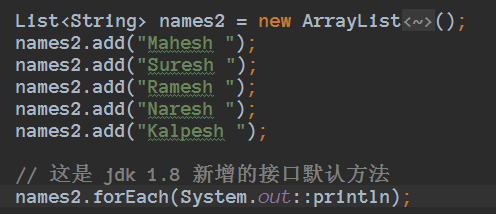
这个 forEach 方法是 jdk 1.8 新增的接口默认方法,正是因为有了默认方法的引入,才不会因为 Iterable 接口中添加了 forEach 方法就需要修改所有 Iterable 接口的实现类。

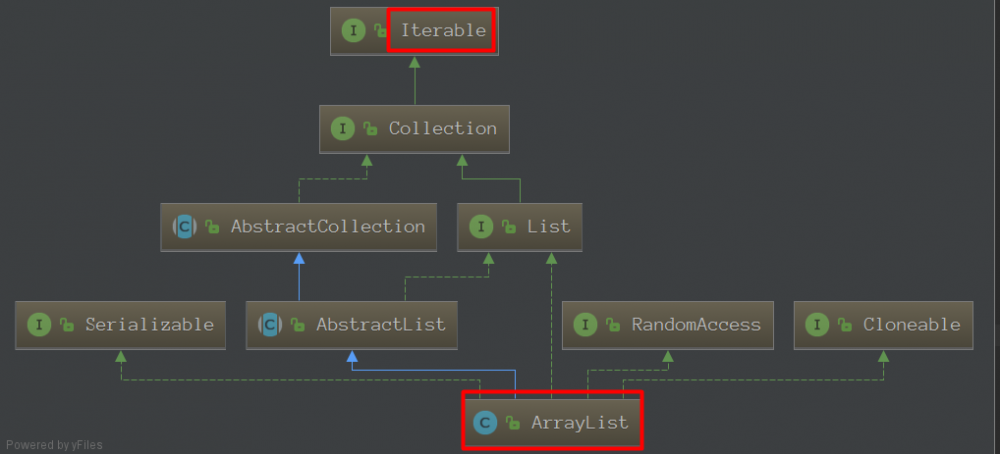
方法引用(Method references)
如果一个Lambda表达式仅仅是调用方法的情况,那么就可以用方法引用来完成,这种情况下使用方法引用代码更易读。
方法引用语法:
目标引用放在分隔符::前,方法的名称放在后面。

names2.forEach(System.out::println);//1
names2.forEach(s->System.out.println(s));//2
第二行代码的lambda表达式仅仅就是调用方法,调用的System.out的println方法,所以可以用方法引用写成System.out::println即可。
方法引用的种类(Kinds of method references)
方法引用有很多种,它们的语法如下:
-
静态方法引用:
ClassName::methodName -
实例上的实例方法引用:
instanceReference::methodName -
父类的实例方法引用:
super::methodName -
类型上的实例方法引用:
ClassName::methodName
备注:String::toString 等价于lambda表达式 (s) -> s.toString()
这里不太容易理解,实例方法要通过对象来调用,方法引用对应Lambda,Lambda的第一个参数会成为调用实例方法的对象。
-
构造方法引用:
Class::new -
数组构造方法引用:
TypeName[]::new
个人理解:方法引用,说白了,用更好,不用也可以,如果可以尽量用!!!
Stream
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式 ,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
-
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。
-
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
-
和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。
对stream的操作分为三类。
-
创建stream
-
中间操作(intermediate operations)【没有终止操作是不会执行的】
-
终止操作(terminal operations):

中间操作 会返回另一个流。可以用链式编程.的形式继续调用。在没有终止操作的时候,中间操作是不会执行的。
终止操作 不会返回流了,而是返回结果(比如返回void-仅仅System.out输出,比如返回总数 int,返回一个集合list等等)
例如:

流的创建
3种方式创建流,普通流调用
-
通过Stream接口的静态工厂方法
-
通过Arrays方法
-
通过Collection接口的默认方法
//通过Stream接口的静态工厂方法
Stream stream = Stream.of("hello", "world", "hello world");
String[] strArray = new String[]{"hello", "world", "hello world"};
//通过Stream接口的静态工厂方法
Stream stream1 = Stream.of(strArray);
//通过Arrays方法
Stream stream2 = Arrays.stream(strArray);
List<String> list = Arrays.asList(strArray);
//通过Collection接口的默认方法
Stream stream3 = list.stream();

本质都是StreamSupport.stream。
通过Collection接口的默认方法获取并行流。

或者通过stream流调用 parallel 获取并行流
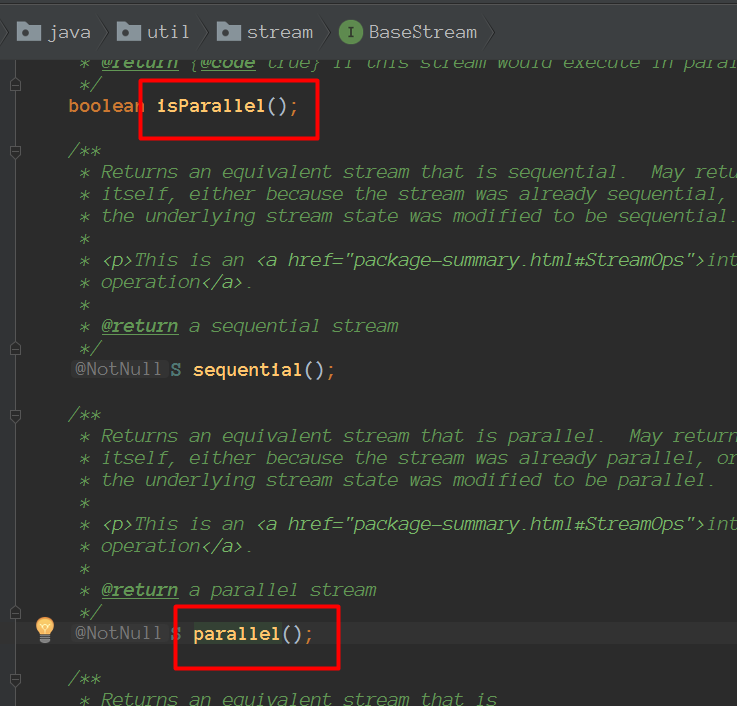
只需要对并行流调用 sequential 方法就可以把它变成顺序流
中间操作

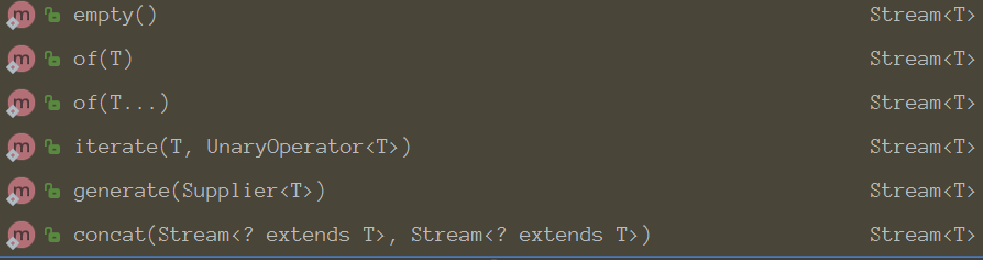
终止操作
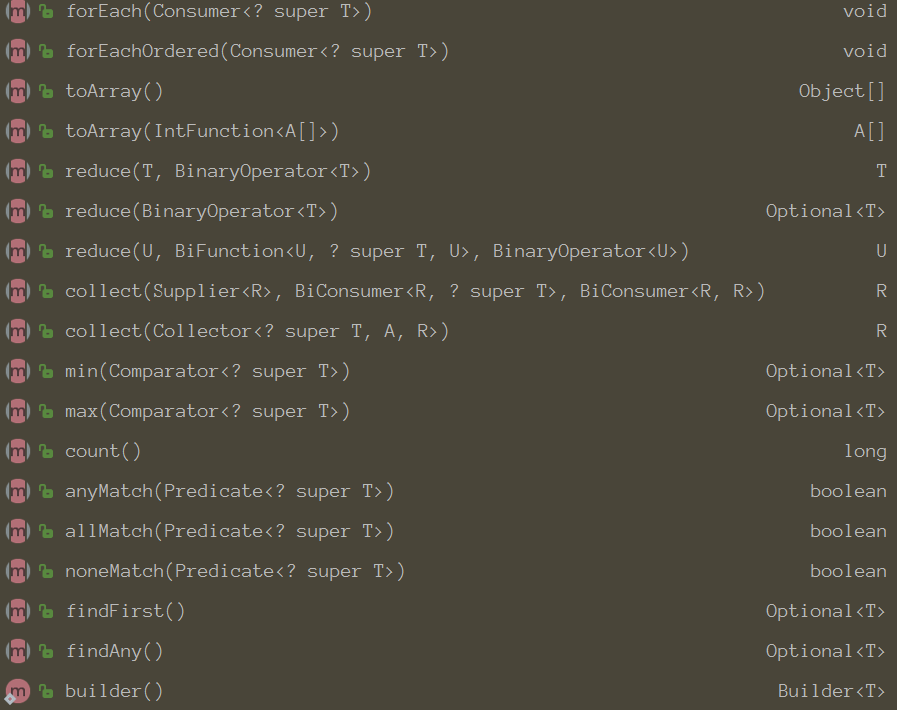
并行流
可以通过对收集源调用parallelStream方法来把集合转换为并行流。并行流就是一个把内容分成多个数据
块,并用不同的线程分别处理每个数据块的流。这样一来,你就可以自动把给定操作的工作负荷分配给多核处理器的所有内核,让它们都忙起来。

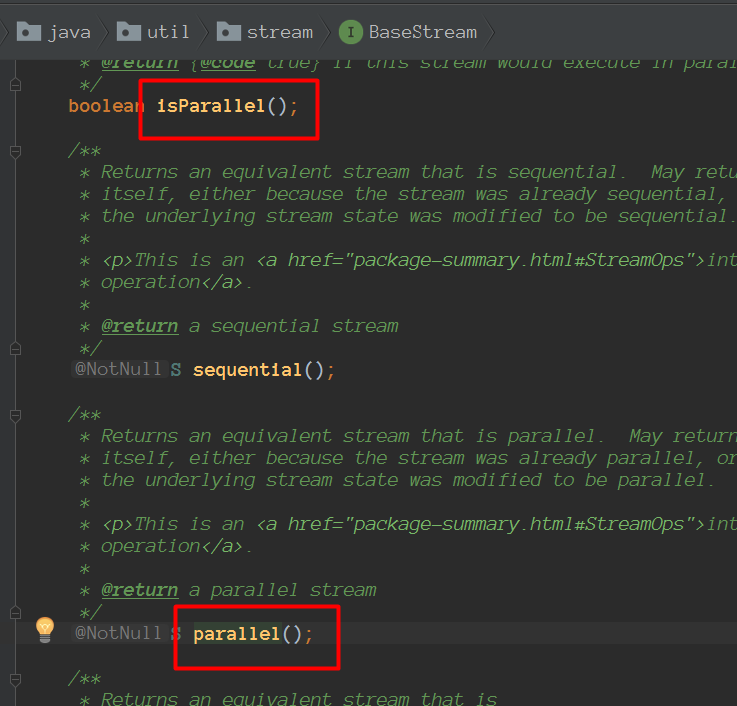
并行流用的线程是从哪儿来的?有多少个?怎么自定义这个过程呢?
并行流内部使用了默认的ForkJoinPool,它默认的线程数量就是你的处理器数量,这个值是由Runtime.getRuntime().availableProcessors()得到的。但是你可以通过系统属性 java.util.concurrent.ForkJoinPool.common. parallelism来改变线程池大小,如下所示:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");
这是一个全局设置,因此它将影响代码中所有的并行流。反过来说,目前还无法专门为某个
并行流指定这个值。一般而言,让ForkJoinPool的大小等于处理器数量是个不错的默认值,
除非你有很好的理由,否则我们强烈建议你不要修改它
测试并行流和顺序流速度
//Sequential Sort, 采用顺序流进行排序
@Test
public void sequentialSort(){
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.err.println("count = " + count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
//sequential sort took: 1932 ms
}
//parallel Sort, 采用并行流进行排序
@Test
public void parallelSort(){
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.err.println("count = " + count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
//parallel sort took: 1373 ms 并行排序所花费的时间大约是顺序排序的一半。
}

错误使用流
class Accumlator{
public long total = 0;
public void add(long value) {
total += value;
}
}
public class ParallelTest {
public static void main(String[] args) {
//错误使用并行流示例
System.out.println("SideEffect parallel sum done in :" + measureSumPerf(ParallelTest::sideEffectParallelSum, 1_000_000_0) + "mesecs");
System.out.println("=================");
//正确应该这样的
System.out.println("SideEffect sum done in :" + measureSumPerf(ParallelTest::sideEffectSum, 1_000_000_0) + "mesecs");
}
//错误使用并行流
public static long sideEffectParallelSum(long n) {
Accumlator accumlator = new Accumlator();
LongStream.rangeClosed(1, n).parallel().forEach(accumlator::add);
return accumlator.total;
}
//正确使用流
public static long sideEffectSum(long n) {
Accumlator accumlator = new Accumlator();
LongStream.rangeClosed(1, n).forEach(accumlator::add);
return accumlator.total;
}
//定义测试函数
public static long measureSumPerf(Function<Long, Long> adder, long n) {
long fastest = Long.MAX_VALUE;
//迭代10次
for (int i = 0; i < 2; i++) {
long start=System.nanoTime();
long sum = adder.apply(n);
long duration=(System.nanoTime()-start)/1_000_000;
System.out.println("Result: " + sum);
//取最小值
if (duration < fastest) {
fastest = duration;
}
}
return fastest;
}
}
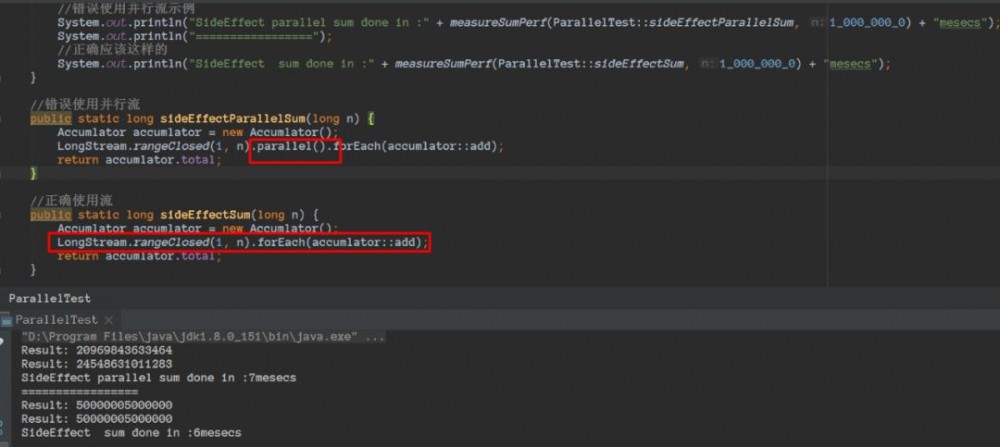
本质问题在于total += value;它不是原子操作,并行调用的时候它会改变多个线程共享的对象的可变状态,从而导致错误, 在使用并行流需要避免这类问题发生!

思考: 什么情况结果正常,但是并行流比顺序流慢的情况呢???
并行流中更新共享变量,如果你加入了同步,很可能会发现线程竞争抵消了并行带来的性能提升!
特别是limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大
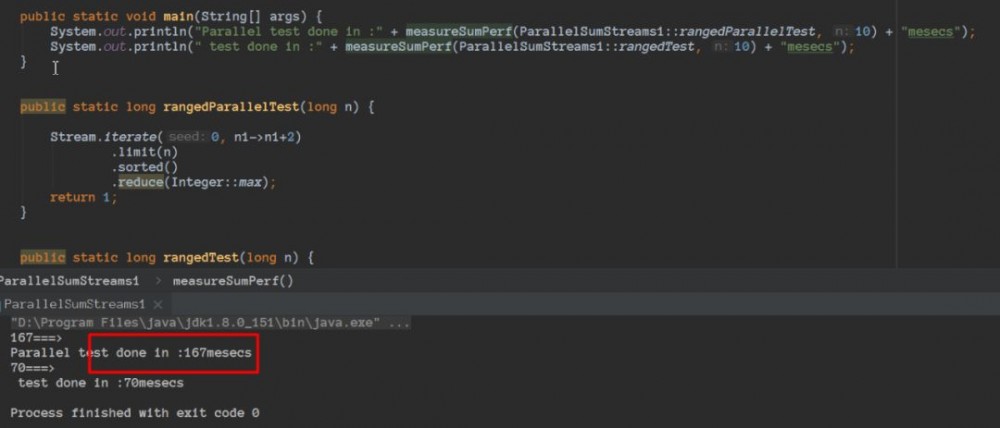
对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。

备注: sort或distinct等操作接受一个流,再生成一个流(中间操作),从流中排序和删除重复项时都需要知道所有集合数据,如果集合数据很大可能会有问题(如果数据大,都放内存,内存不够就会OOM了)。
使用并行流还是顺序流都应该应该测试,以及压测,如果在并行流正常的情况下,效率有提升就选择并行流,如果顺序流快就选择顺序流。
`CompletableFuture`异步函数式编程
引入CompletableFuture原因
Future模式的缺点
-
Future虽然可以实现获取异步执行结果的需求, 但是它没有提供通知的机制,我们无法得知Future什么时候完成 。
-
要么使用阻塞, 在future.get()的地方等待future返回的结果,这时又变成同步操作 。 要么使用isDone()轮询地判断Future是否完成,这样会耗费CPU的资源。
Future 接口的局限性
future接口可以构建异步应用,但依然有其局限性。 它很难直接表述多个Future 结果之间的依赖性。 实际开发中,我们经常需要达成以下目的:
-
将两个异步计算合并为一个——这两个异步计算之间相互独立,同时第二个又依赖于第
一个的结果。
-
等待 Future 集合中的所有任务都完成。
-
仅等待 Future 集合中最快结束的任务完成(有可能因为它们试图通过不同的方式计算同
一个值),并返回它的结果。
-
通过编程方式完成一个 Future 任务的执行(即以手工设定异步操作结果的方式)。
-
应对 Future 的完成事件(即当 Future 的完成事件发生时会收到通知,并能使用 Future
计算的结果进行下一步的操作,不只是简单地阻塞等待操作的结果)
新的CompletableFuture将使得这些成为可能。


CompletableFuture 提供了四个静态方法用来创建CompletableFuture对象:
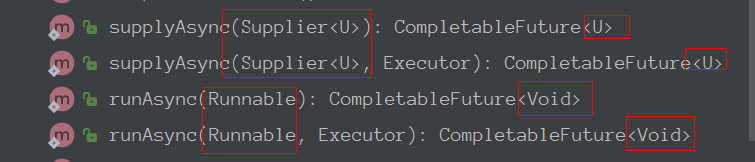
方法入参和返回值有所区别。
里面有非常多的方法,返回为CompletableFuture之后可以用链式编程.的形式继续调用,最后调用一个不是返回CompletableFuture的介绍,和流式操作里面的中间操作-终止操作。
日期
/**
* 可以使用Instant代替Date
* LocalDateTime代替Calendar
* DateTimeFormatter代替SimpleDateFormat
*/
public static void main(String args[]) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime now = LocalDateTime.now();
System.out.println(now.format(formatter));
//10分钟前
String d1 = now.minusMinutes(10).format(formatter);
//10分钟后
String d2 = now.plusMinutes(10).format(formatter);
System.out.println(d1);
System.out.println(d2);
LocalDateTime t5 = LocalDateTime.parse("2019-01-01 00:00:00", formatter);
System.out.println(t5.format(formatter));
}
JVM方面改变
去除了永久代(PermGen) 被元空间(Metaspace)代替 配置: -XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=80m 代替 -XX:PermSize=10m -XX:MaxPermSize=10m
用Optional取代null
Optional对象创建
1、 创建空对象
Optional<String> optStr = Optional.empty();
上面的示例代码调用empty()方法创建了一个空的Optional
2、 创建对象: 不允许为空
Optional提供了方法of()用于创建非空对象,该方法要求传入的参数不能为空,否则抛NullPointException,示例如下:
Optional<String> optStr = Optional.of(str); // 当str为null的时候,将抛出NullPointException
3、创建对象: 允许为空
如果不能确定传入的参数是否存在null值的可能性,则可以用Optional的ofNullable()方法创建对象,如果入参为null,则创建一个空对象。示例如下:
Optional<String> optStr = Optional.ofNullable(str); // 如果str是null,则创建一个空对象
常用方法

String str = null;
len = Optional.ofNullable(str).map(String::length).orElse(0); //不会报NullPointerException
END
如果读完觉得有收获的话,欢迎点【好看】,关注【匠心零度】,查阅更多精彩历史!!!

让我“ 好看 ” 
正文到此结束
- 本文标签: API 遍历 同步 ACE ORM 静态方法 编译 Oracle IDE HTML consumer Word bean JVM java find 数据 App 开发 删除 Action 本质 rmi tar UI 空间 参数 http Property 专注 2019 配置 时间 list ECS 函数式编程 id 并发 https map 需求 value src 处理器 MQ stream mina cat 代码 实例 lib Security Collection lambda tab 多线程 parse dist 线程池 IO 构造方法 测试 线程
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

