从fastjson漏洞谈防御式编程
最近,fastjson又爆出一个 漏洞 ,在解析特殊字符的时候,直接OOM:
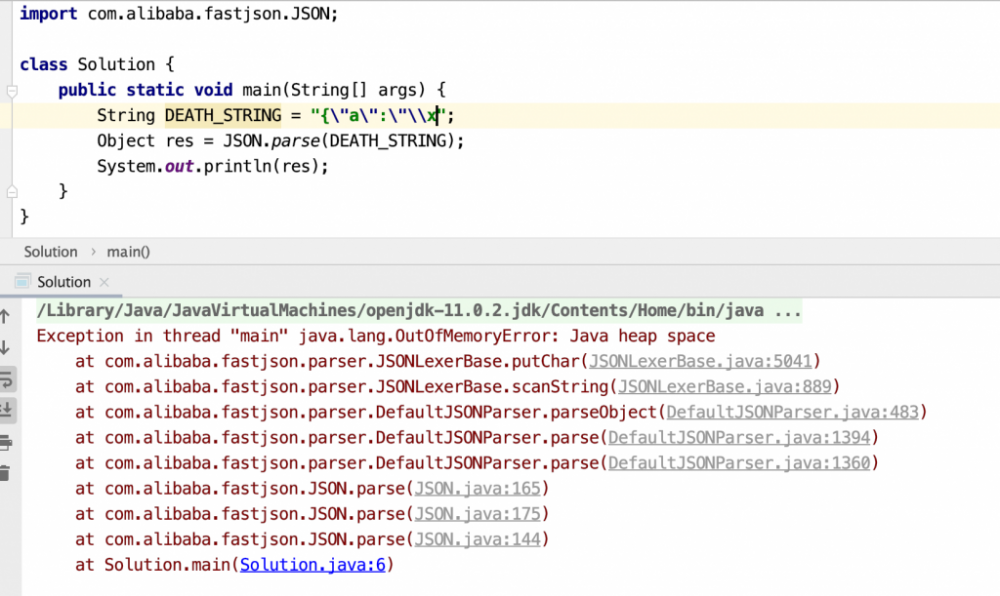
首先分析一下整体流程:
在scanString时,会直接读取两个字符:

而在next方法中,每次读取都会将bp的值加一(即使没有从输入中读取字符):
public final char next() {
int index = ++bp;
return ch = (index >= this.len ? //
EOI //
: text.charAt(index));
}
在处理完/x之后,继续解析剩下的字符。由于没有更多字符了,所以读到的总是EOI,然后进入如下分支:
if (ch == EOI) {
if (!isEOF()) {
putChar((char) EOI);
continue;
}
throw new JSONException("unclosed string : " + ch);
}
本来到这一步,isEOF应该是true了,但是isEOF是这样的:
public boolean isEOF() {
return bp == len || ch == EOI && bp + 1 == len;
}
刚刚多读了两个字符,已经导致bp(读到的字符数)超过了len(总的字符数),所以这个isEOF永远返回false,进而永远执行putChar。
问题在哪儿
当然,在这儿的问题在于,fastjson没有考虑到/x后面直接没有字符的情况。
但是,再多问一句, 为什么这种输入会导致这么严重的问题?
一般来说,这种不合理的情况后面,肯定会有很多不合理的小问题。
防御式编程
显然isEOF函数考虑不周到,读取超出了总长度,这种情况显然是EOF了,但是这个函数没有判断。
当然,很多时候,工程师会说这种情况不会发生,但是工程师确实不知道其他工程师会干出什么事来。 (另外,在fastjson中,这种情况会发生)
所以,这才有了防御式编程:不要相信其他的工程师
要是当时isEOF是这样的,那这次问题就不会这么严重了:
public boolean isEOF() {
return bp == len || ch == EOI && bp + 1 >= len;
}
变量应该符合语义
我真的不知道bp是什么的缩写…… 但是通过上面isEOF的判断,bp是已读取的字符数量,这样就可以通过bp和len的关系判断是否EOF了。
但是看下next的实现:
public final char next() {
int index = ++bp;
return ch = (index >= this.len ? //
EOI //
: text.charAt(index));
}
已读取的字符数量,在没有实际读取字符的情况下,还加一了???变量值不符合语义,维护上迟早会出问题的吧。
fastjson是如何修复的
看下fastjson官方的 修复 :

嗯,简单直接。
但是,谁知道还会不会因为bp和len变量的关系导致新的漏洞呢?
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

