程序员楼下闲聊:某次jvm崩溃排查
大望路某写字楼下。 猿A:上家公司的时候,我们组那个项目,每天半夜会跑个大批量数据处理的定时任务,然后程序经常崩溃。 我:哦?那怎么处理的 猿A:当时的架构有点水,说让调整“伊甸园”和“from-to”的比例……崩溃和这个就没关系 我:少年,你成功引起了我的注意。来来来,请你喝饮料,好好聊聊当时的情况。
业务场景
“猿A”是我的同事兼死党,和他详聊后大概明白了当时的场景。
据我理解,那个定时任务,会从 hive 里拿出超多的数据(据说2亿左右),按具体业务做数据整合和处理,最终推送到es(elasticsearch)中。(hive什么的我没搞过,但不妨碍要讨论的东西)
业务处理部分,使用了线程池 FixedThreadPool 。
模拟解决过程
问题定位
猿A:那时候怀疑是内存OOM导致的jvm崩溃,进而怀疑大量对象GC回收不了,于是打了GC日志。 我:嗯,没用hs_err_pid_xxx.log分析吗? 猿A:当时小,还不会这个技能……
死党“猿A”当时的解决过程比较粗暴,有了怀疑就直接在启动参数增加了 -XX:+PrintGC 。此命令会打印GC日志,姑且认为生产环境使用GC是CMS,写个demo模拟当时的场景。
public class CMSGCLogs {
//启动参数:-Xmx10m -Xms10m -Xmn4M -XX:+PrintGC -XX:+UseConcMarkSweepGC
public static void main(String[] args) throws InterruptedException {
// 线程数设置为1,起名`T-1`
ExecutorService es = Executors.newFixedThreadPool(1, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"T-1");
}
});
boolean flag = true;
while (flag){
es.execute(()->{
try {
byte[] bytes = new byte[1024*1000*1]; //模拟从hive中读取了大量数据(1M)
TimeUnit.MILLISECONDS.sleep(50L); //模拟写入es过程
} catch (Exception e) {
e.printStackTrace();
}
});
}
es.shutdown();
}
}
先背一段线程池的处理过程。
线程池接收请求,小于核心线程数时,会创建线程,直到等于核心线程数。 之后,核心线程数消化不了的请求放入阻塞队列中。 再后,阻塞队列也放满了,再继续创建线程,直到最大线程数。 最大线程也扛不住依然汹涌的请求,执行拒绝策略。
fixed线程池,作为线程池家族中的一员,也满足上述规则。
差别在于它的 核心线程数=最大线程数,然后阻塞队列(LinkedBlockingQueue)是无界的 。
# 源码中fixed线程池创建
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
运行一下,demo执行结果大概长这样:
[GC (Allocation Failure) 3302K->1174K(9856K), 0.0037023 secs]
[GC (Allocation Failure) 3664K->1541K(9856K), 0.0014799 secs]
[Full GC (Allocation Failure) 1541K->1446K(9856K), 0.0039197 secs]
[Full GC (Allocation Failure) 1446K->1387K(9856K), 0.0037783 secs]
## 线程T-1 OOM
Exception in thread "T-1" java.lang.OutOfMemoryError: Java heap space
at com.evolution.gc.CMSGCLogs.lambda$main$0(CMSGCLogs.java:44)
at com.evolution.gc.CMSGCLogs$$Lambda$1/233530418.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
...
[Full GC (Allocation Failure) 9676K->9676K(9856K), 0.0253352 secs]
[Full GC (Allocation Failure) 9676K->9676K(9856K), 0.0190795 secs]
## 线程T-1 OOM
Exception in thread "T-1" java.lang.OutOfMemoryError: Java heap space
Exception in thread "T-1" java.lang.OutOfMemoryError: Java heap space
...
[GC (CMS Initial Mark) 9855K(9856K), 0.0051677 secs]
## 线程main OOM
Exception in thread "main" [Full GC (Allocation Failure) 9855K->9855K(9856K), 0.0211383 secs]
[Full GC (Allocation Failure) 9855K->9855K(9856K), 0.0203374 secs]
[Full GC (Allocation Failure) 9855K->9855K(9856K), 0.0433360 secs]
[GC (CMS Initial Mark) 9855K(9856K), 0.0029999 secs]
[Full GC (Allocation Failure) java.lang.OutOfMemoryError: Java heap space
9855K->9855K(9856K), 0.0249560 secs]
[Full GC (Allocation Failure) 9855K->9854K(9856K), 0.0244291 secs]
[GC (CMS Initial Mark) 9854K(9856K), 0.0063567 secs]
[Full GC (Allocation Failure) 9854K->9854K(9856K), 0.0208301 secs]
[Full GC (Allocation Failure) 9854K->9854K(9856K), 0.0346616 secs]
[Full GC (Allocation Failure) 9855K->1147K(9856K), 0.0067034 secs]
*** java.lang.instrument ASSERTION FAILED ***: "!errorOutstanding" with message can't create byte arrau at JPLISAgent.c line: 813
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "T-1"
Exception: java.lang.OutOfMemoryError thrown from the UncaughtExceptionHandler in thread "main"
其实对fixed线程池熟悉的朋友,在看到使用的是这位爷的时候,就能猜出问题是什么了——Fixed线程池的无界队列,会使试图无限存储任务,直到内存溢出。
从GC日志来看也确实是这个路数,还很贴心的指出了哪个线程,哪个对象,甚至是哪行异常了( at com.evolution.gc.CMSGCLogs$$Lambda$1/233530418.run(Unknown Source) ,当然我这里用了内部类和函数式,所以看着稍微费劲些)。
支线任务1:子线程OOM问题
但有一点和我想象的不一样,日志中 线程T-1 崩溃了多次,程序依然坚挺了一阵,才迎来了线程main的崩溃。
这就奇怪了,堆内存不是公用的吗? 子线程T-1都崩溃了,为什么没带动整个JVM崩溃?
因此,我用VisualVM观察了内存情况:
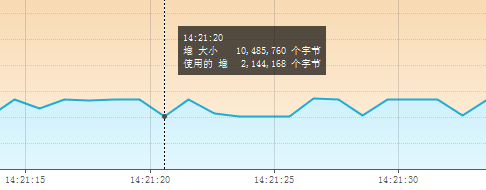
图中的断崖处就是线程T-1 OOM的时候,再求证了相关资料后,得出结论: 当某一线程 (T-1) OOM的时候,会把该线程占用的内存释放,而不影响其它线程 (main)!
详细过程是这样的:
-
线程T-1业务处理较慢(TimeUnit.MILLISECONDS.sleep(50L);),任务又大量的涌过来,致使fixed线程池的阻塞队列疯狂储备待执行任务,内存逐渐吃紧; -
线程T-1每次执行又会占用1M内存(byte[] bytes = new byte[1024 1000 1];),由于内存不足(内存被阻塞队列占据了,已不足1M),线程T-1无奈宣告崩溃; - 随着
线程T-1的崩溃,会把资源释放出来,重新进入循环(下一轮循环,线程T-1继续崩溃……),直到某个契机把线程main也搞崩溃了,整个JVM才崩溃退出
支线任务2:CMS的STP
我在demo调试时,无意间改大过模拟写入es的时间,表示耗时更长(如下):
while (flag){
es.execute(()->{
try {
byte[] bytes = new byte[1024*1000*1];
TimeUnit.HOURS.sleep(50L); ## 直接把单位从`MILLISECONDS`改成`HOURS`了
} catch (Exception e) {
e.printStackTrace();
}
});
}
原本以为这样会使jvm崩溃的更快——线程T-1 50个小时才能执行完,任务又无尽积压,jvm理应更快的走向灭亡。
结果却事与愿违!
程序执行的效果变成了这样:
31.949: [GC (CMS Initial Mark) 9855K(9856K), 0.0033049 secs] 31.966: [GC (CMS Final Remark) 9855K(9856K), 0.0046193 secs] 32.401: [Full GC (Allocation Failure) 9855K->9855K(9856K), 0.0243874 secs] 32.425: [Full GC (Allocation Failure) 9855K->9855K(9856K), 0.0240275 secs] 32.450: [GC (CMS Initial Mark) 9855K(9856K), 0.0033793 secs] 32.466: [GC (CMS Final Remark) 9855K(9856K), 0.0048207 secs] 34.473: [GC (CMS Initial Mark) 9855K(9856K), 0.0033645 secs] 34.485: [GC (CMS Final Remark) 9855K(9856K), 0.0046805 secs] 36.491: [GC (CMS Initial Mark) 9855K(9856K), 0.0032574 secs] ... 109.890: [GC (CMS Initial Mark) 9855K(9856K), 0.0038242 secs] 109.902: [GC (CMS Final Remark) 9855K(9856K), 0.0053191 secs] 111.909: [GC (CMS Initial Mark) 9855K(9856K), 0.0106591 secs] 111.945: [GC (CMS Final Remark) 9855K(9856K), 0.0059029 secs]
我得到了无尽的 CMS Initial Mark 和 CMS Final Remark 。
VisualVM的分析图长这样:
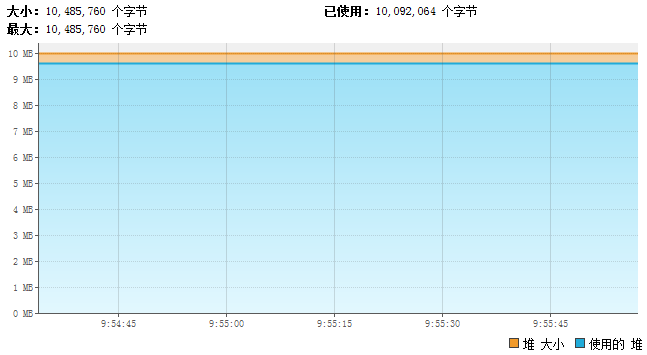
内存将将满,就是等不到“压倒骆驼的最后一根稻草”。
仔细思考了一番,想起 CMS执行过程中有两个stop the world(STP)的环节,似乎就是初始标记(CMS Initial Mark)和最终标记(CMS Final Remark) 两兄弟?
那这个现象就能解释通了:
随着堆内存的占满,CMS收集器开始执行,但两个标记环节怎么执行都发现没有能回收的资源。(1M的bytes不能回收,因为50小时的休眠后还能用到;阻塞队列中的任务也不能回收,jvm觉得总会执行这些任务的)
因此,内存吃紧jvm崩溃前夕,CMS就不断执行初始标记和最终标记,而两个命令会导致用户线程(线程T-1)停止,没机会再给jvm添堵。
于是就这样微妙的保持了诡异的平衡……
解决方案
以上两个支线任务是我demo模拟中遇到的魑魅魍魉,猿A同志并没有搞出这么多弯弯绕(当然他可能有其它际遇)。
既然已经定位到了问题产生于 FixedThreadPool ,那么换掉它就好,自己 new ThreadPoolExecutor 。
- 参数指定 有界队列
- 修改拒绝策略为 ThreadPoolExecutor.CallerRunsPolicy
拒绝策略默认是 ThreadPoolExecutor.AbortPolicy ,表现为 丢弃任务并抛出异常 ;而 ThreadPoolExecutor.CallerRunsPolicy 则不劳烦线程池, 直接交由原线程执行任务 (demo中就是不麻烦线程T-1了,线程main顶上)
Tip:这里给出全部策略,做个参考 ↓↓↓
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
修改之后的demo代码:
public class CMSGCLogs {
//-Xmx10m -Xms10m -Xmn4M -XX:+PrintGC -XX:+UseConcMarkSweepGC
public static void main(String[] args) throws InterruptedException {
BlockingQueue list = new ArrayBlockingQueue(20); //修改1:有界队列
ExecutorService es = new ThreadPoolExecutor(1, 1,
0, TimeUnit.MILLISECONDS, list, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"T-1");
}
},
new ThreadPoolExecutor.CallerRunsPolicy()); //修改2:更换拒绝策略
boolean flag = true;
while (flag){
es.execute(()->{
try {
byte[] bytes = new byte[1024*1000*1];
TimeUnit.MILLISECONDS.sleep(50L);
System.out.println(String.format("curThread=%s,run task!",Thread.currentThread())); //打印执行线程
} catch (Exception e) {
e.printStackTrace();
}
});
}
es.shutdown();
}
}
看下执行效果:
53.422: [GC (Allocation Failure) 6615K->3550K(9856K), 0.0006514 secs] curThread=Thread[main,5,main],run task! curThread=Thread[main,5,main],run task! curThread=Thread[T-1,5,main],run task! 53.473: [GC (Allocation Failure) 6615K->3550K(9856K), 0.0003791 secs] curThread=Thread[main,5,main],run task! curThread=Thread[T-1,5,main],run task! curThread=Thread[main,5,main],run task! curThread=Thread[T-1,5,main],run task! 53.573: [GC (Allocation Failure) 6615K->3550K(9856K), 0.0003733 secs] curThread=Thread[main,5,main],run task! curThread=Thread[T-1,5,main],run task! 53.623: [GC (Allocation Failure) 6615K->3550K(9856K), 0.0009536 secs] curThread=Thread[main,5,main],run task! curThread=Thread[T-1,5,main],run task! curThread=Thread[main,5,main],run task! curThread=Thread[T-1,5,main],run task! 53.724: [GC (Allocation Failure) 6615K->3550K(9856K), 0.0004394 secs]
我们发现 程序已经能够平稳的运行了 ,再观察此时的jvm堆内存,一切正常:
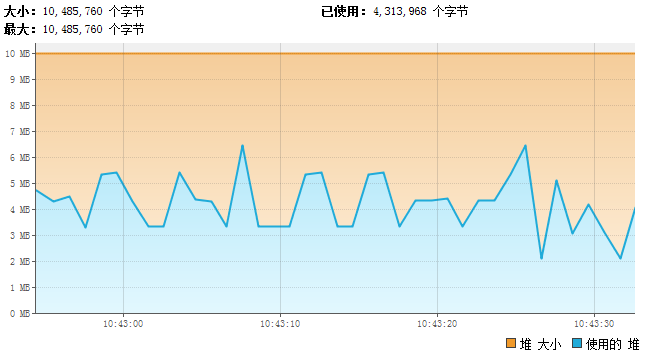
新生代各区比例的作用
问题解决了,回顾下架构师当时的提议:
猿A:当时的架构有点水,说让调整“伊甸园”和“from-to”的比例……崩溃和这个就没关系
“架构”说的是设定 -XX:NewRadio 参数来调整新生代各模块比例。
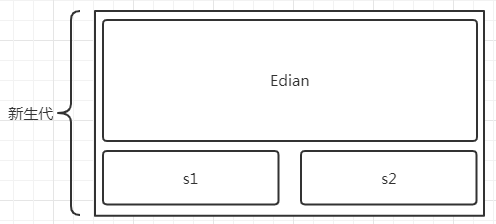
这个 比例默认为8:1:1 ,我们来看下调整这个参数产生的影响。
- 极端一些,把
Edian调的很大

新生代GC时, 对象是否进入老年代主要取决于两个因素——对象年龄和对象大小 。
如果对象大小超出了某界限,对象就直接进入老年代。如此,会给老年代的GC会增加更多压力,有可能产生更多的STP。
- 反向极端,把
Edian调的很小
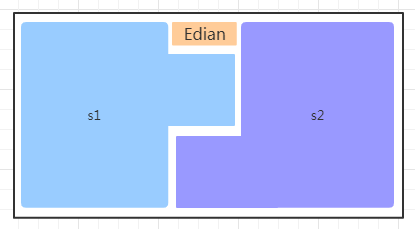
因为 s1 和 s2 两个区域总有1个是空的 ,这样调整会浪费更多的内存,并更频繁的触发的新生代GC。
我们感性的理解了这个比例的作用,那么架构师的提议和猿A遇到的问题有关吗?答案是没有,所以那个架构是真的水……
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

