Guava 布隆过滤器
在 Guava 项目的11.0版中,一个新的类添加了进来—— BloomFilter(布隆过滤器)类。布隆过滤器是一种独特的数据结构,用以表明元素是否被保存在一个集合(Set)中。有趣的是,布隆过滤器能够明确指出元素 绝对 不存在于一个集合中,或是 可能 存在于一个集合中。由于布隆过滤器从不漏报的特性,使得它成为避免不必要和昂贵操作的约束条件的极好选择。 近来对布隆过滤器的关注开始增多,如要使用它,你可以自己写代码,也可以谷歌之。编写自己的布隆过滤器的问题在于使用正确的哈希函数来确保过滤器生效。鉴于 Guava 是使用 Murmur Hash 来实现的,仅需一个库,你就能获得这个非常有效的布隆过滤器。
http://codingjunkie.net/guava-bloomfilter/
布隆过滤器速成
布隆过滤器在本质上是二进制向量。在高层级上,布隆过滤器以下面的方式工作:
-
添加元素到过滤器。
-
对元素进行几次哈希运算,当索引匹配哈希的结果时,将该位设置为 1 的。
如果要检测元素是否属于集合,使用相同的哈希运算步骤,检查相应位的值是1还是0。这就是布隆过滤器明确元素不存在的过程。如果位未被设置,则元素绝不可能存在于集合中。当然,一个肯定的答案意味着,要不就是元素存在于集合中,要不就是遇见了哈希冲突。这里有一份很好的对布隆过滤器细节的描述,还有一份很好的教程。依据维基百科,谷歌在 BigTable 中使用了布隆过滤器,以避免在硬盘中寻找不存在的条目。另一个有趣的用法是使用布隆过滤器优化SQL查询。
使用 Guava 的布隆过滤器
Guava 的布隆过滤器通过调用 BloomFilter 类中的静态函数创建, 传递一个 Funnel 对象以及一个代表预期插入数量整数。同样来自于 Guava 11 中的 Funnel 对象,用于将数据发送给一个接收器(Sink)。 下面的例子是一个默认的实现,有着3%的误报率。Guava 提供的 Funnels 类拥有两个静态方法提供了将CharSequence 或byte数组插入到过滤器的 Funnel 接口的实现。
//Creating the BloomFilter BloomFilter bloomFilter = BloomFilter.create(Funnels.byteArrayFunnel(), 1000); //Putting elements into the filter //A BigInteger representing a key of some sort bloomFilter.put(bigInteger.toByteArray()); //Testing for element in set boolean mayBeContained = bloomFilter.mayContain(bitIntegerII.toByteArray());
更新:根据来自 Louis Wasserman 的回复,下面是如何为 BigIntegers 创建一个带有自定义 Funnel 实现的布隆过滤器:
//Create the custom filter
class BigIntegerFunnel implements Funnel<BigInteger> {
@Override
public void funnel(BigInteger from, Sink into) {
into.putBytes(from.toByteArray());
}
}
//Creating the BloomFilter
BloomFilter bloomFilter = BloomFilter.create(new BigIntegerFunnel(), 1000);
//Putting elements into the filter
//A BigInteger representing a key of some sort
bloomFilter.put(bigInteger);
//Testing for element in set
boolean mayBeContained = bloomFilter.mayContain(bitIntegerII);
注意事项
正确估计预期插入数量是非常关键的。当插入的数量接近或高于预期值的时候,布隆过滤器将会填满,这样的话,它会产生很多无用的误报点。这里有另一个版本的 BloomFilter.create 方法,它额外接收一个参数,一个代表假命中概率水平的双精度数字(必须大于零且小于1)。假命中概率等级影响哈希表储存或搜索元素的数量。百分比越低,哈希表的性能越好。
BloomFilterTest
package bbejeck.guava.hash;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.PrimitiveSink;
import org.junit.Before;
import org.junit.Test;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import static org.hamcrest.CoreMatchers.is;
import static org.junit.Assert.assertThat;
/**
* Created by IntelliJ IDEA.
* User: bbejeck
*/
public class BloomFilterTest {
private BloomFilter<BigInteger> bloomFilter;
private Random random;
private int numBits;
private List<BigInteger> stored;
private List<BigInteger> notStored;
@Before
public void setUp() {
numBits = 128;
random = new Random();
stored = new ArrayList<BigInteger>();
notStored = new ArrayList<BigInteger>();
loadBigIntList(stored, 1000);
loadBigIntList(notStored, 100);
}
@Test
public void testMayContain() {
setUpBloomFilter(stored.size());
int falsePositiveCount = 0;
for (BigInteger bigInteger : notStored) {
boolean mightContain = bloomFilter.mightContain(bigInteger);
boolean isStored = stored.contains(bigInteger);
if (mightContain && !isStored) {
falsePositiveCount++;
}
}
assertThat(falsePositiveCount < 5, is(true));
}
@Test
public void testMayContainGoOverInsertions() {
setUpBloomFilter(50);
int falsePositiveCount = 0;
for (BigInteger bigInteger : notStored) {
boolean mightContain = bloomFilter.mightContain(bigInteger);
boolean isStored = stored.contains(bigInteger);
if (mightContain && !isStored) {
falsePositiveCount++;
}
}
assertThat(falsePositiveCount, is(notStored.size()));
}
private void setUpBloomFilter(int numInsertions) {
bloomFilter = BloomFilter.create(new BigIntegerFunnel(), numInsertions);
addStoredBigIntegersToBloomFilter();
}
private BigInteger getRandomBigInteger() {
return new BigInteger(numBits, random);
}
private void addStoredBigIntegersToBloomFilter() {
for (BigInteger bigInteger : stored) {
bloomFilter.put(bigInteger);
}
}
private void loadBigIntList(List<BigInteger> list, int count) {
for (int i = 0; i < count; i++) {
list.add(getRandomBigInteger());
}
}
private class BigIntegerFunnel implements Funnel<BigInteger> {
@Override
public void funnel(BigInteger from, PrimitiveSink into) {
into.putBytes(from.toByteArray());
}
}
}
背景
原有的去重方案是:
-
使用linux命令去重
-
缺点
-
优点
-
实现简单
-
一般功能稳定
-
出现问题只能重来,控制粒度很粗。
-
程序与操作系统过渡耦合,如果系统中sort或者uniq命令出现问题,则去重功能不能使用。
-
使得push opt的用户数据以文件的形式存在,不方便多主机、操作系统共享,妨碍后期push opt多主节点发展。
-
使用tair去重
-
缺点
-
优点
-
一般不会出现问题;
-
访问迅速;
-
接近
O(1)时间复杂度得知哪条重复。 -
适合分布式系统中去重
-
浪费大量珍贵的内存资源
-
不一定可靠,也可能丢失数据
-
tair出现问题后,用户去重功能彻底不能使用。
为什么使用布隆过滤器
原理
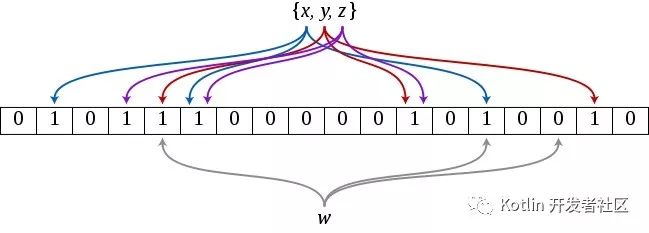

初始化:对于x,y,z三个数,经过{k1,k2,k3}三个hash函数,将向量空间中的某些位置标记为1,作为初始向量空间。
判断:当新进入一个数据,w,进过{k1,k2,k3}hash函数,在向量空间上所有位置均为1,表示命中这个数,这个数已经在bloomfilter中。如果部分为1或者全为0,表示这个数不在bloomfilter中。
性能分析
参考:https://blog.csdn.net/jiaomeng/article/details/1495500
如果hash函数个数为k个,那么bloom过滤器插入和判断一个数的时间复杂度是 O(k) ,空间复杂度为 O(size) 。size为bloomfilter的位数组大小。
优缺点分析
-
优点:常数时间复杂度,占用很少的内存。
-
缺点:不会漏判一个已经发送过的token,但是可能误判一个每发送过的为发送了。此时发生了hash冲突。但是当hash空间一定大的时候,是可以降低冲突的。还有发送push,少发了几个是可以容忍的。(类似tair丢失极少量数据是可以容忍的)
使用
Guava的布隆过滤器通过调用 BloomFilter 类的静态函数创建,传递一个 Funnel 对象以及一个代表预期插入数量的整数。
Funnel 对象的作用,将数据发送给一个接收器( Slink )。
package guava;
import com.google.common.base.Strings;
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.PrimitiveSink;
import org.junit.Before;
import org.junit.Test;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
* Created by hgf on 16/8/25.
*/
public class BloomFilterTest {
private BloomFilter<String> bloomFilter;
private final static String TOKEN = "token-[0-9]+";
private final static String prefix = "token-";
private List<String> tokens = Lists.newArrayList();
private Map<String, Integer> map = Maps.newHashMap();
private Map<String, Integer> reflect = Maps.newHashMap();
@Before
public void init() {
Random random = new Random();
for (int i = 0; i < 10000; i++) {
tokens.add(prefix + random.nextInt(10000));
}
try {
writeSource();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void test() {
//此处使用的是自定义funnel,可以使用guava默认实现的funnel。
//全部实现在Funnels中。Funnels.stringFunnel(Charset.defaultCharset())
//注意此处布隆过滤器大小,应估算的稍大
bloomFilter = BloomFilter.create(stringFunnel(), tokens.size());
int repeatTimes = 0;
for (String token : tokens) {
//参照数据
Integer tmp = reflect.get(token);
if (tmp == null) {
reflect.put(token, 1);
} else {
reflect.put(token, tmp + 1);
}
//布隆过滤器数据
boolean hasToken = bloomFilter.mightContain(token);
if (hasToken) {
Integer times = map.get(token);
if (times == null) {
map.put(token, 2);
} else {
map.put(token, times + 1);
}
repeatTimes++;
} else {
bloomFilter.put(token);
}
}
System.out.println("随机token中重复次数:" + repeatTimes);
// //打印重复的token
// System.out.println("bloom filter 判断为重复的token数:" + map);
compareResult();
}
private void compareResult() {
int wrongCount = 0;
for (String token : map.keySet()) {
Integer tmp = map.get(token);
if (!(tmp != null && tmp.intValue() == reflect.get(token).intValue())) {
wrongCount++;
System.out.println("错误统计:/t" + token + "/t" + tmp + "/t" + reflect.get(token));
}
}
System.out.println("总统计出错,对比结果:" + wrongCount+"次");
}
private void writeSource() throws IOException {
File file = new File("source.txt");
try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(file))) {
for (String token : tokens) {
bufferedWriter.write(token);
bufferedWriter.newLine();
}
}
}
public static Funnel<String> stringFunnel() {
return StringFunnel.INSTANCE;
}
private enum StringFunnel implements Funnel<String> {
INSTANCE;
@Override
public void funnel(String from, PrimitiveSink into) {
if (isToken(from)) {
into.putString(from, Charset.defaultCharset());
}
}
private boolean isToken(String token) {
return (!Strings.isNullOrEmpty(token) && token.matches(TOKEN));
}
}
}
输出结果
随机token中重复次数:3709 错误统计: token-7746 2 1 错误统计: token-5714 2 1 错误统计: token-1718 3 2 错误统计: token-7065 3 2 错误统计: token-8875 4 3 错误统计: token-3599 2 1 错误统计: token-8563 2 1 总统计出错,对比结果:7次
注意点
预期插入数量 是很关键的一个参数。当插入的数量接近或高于预期值的时候,布隆过滤器将会填满,这样的话,它会产生很多无用的误报点。
有另一个版本的 BloomFilter.create 方法,它额外接收一个参数,一个代表 假命中概率水平 的双精度数字(必须大于零且小于1)
假命中概率等级影响哈希表储存或搜索元素的数量。百分比越 低 ,哈希表的 性能越好 。
场景
适用判断一个元素是否在某个集合(该集合往往数据量庞大)出现,并允许一定小概率错误的场景。
例如:判断一个url或者邮件地址或者token,是否出现在给定集合中。
-
做缓存的时候,使用bloomfilter,不给只访问过一次的数据做缓存,数据量大但是大多都只需要访问一次。
-
对大型分布式的NOSQL,使用布隆过滤器判断某一行数据是否存在,避免无谓的磁盘读写和查找。HBASE,BIGTABLE
-
判断恶意网址。
-
避免爬虫爬取同样的url,陷入爬取旋涡。
-
推荐网站避免给用户推送同样的url。
与Tair方案对比
优势:
-
判断重复节约大量内存空间。
劣势:
-
在分布式场景中,目前需要自己包装服务。
原文:https://my.oschina.net/hgfdoing/blog/739858
正文到此结束
- 本文标签: 代码 REST http token rand java sql SDN 谷歌 主机 本质 BigInteger linux HBase Google list 统计 分布式系统 junit 网站 IDE value core 分布式 缓存 cat 数据 key src id 静态方法 UI DOM final IO ArrayList https 空间 操作系统 NIO 索引 db map 时间 参数 ACE HashMap tab NOSQL
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

