JAVA集合框架的特点及实现原理简介
1.集合框架总体架构
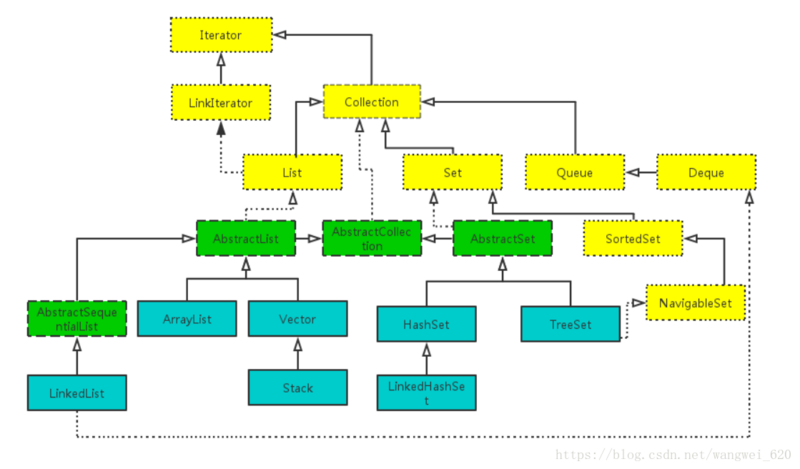
- 集合大致分为Set、List、Queue、Map四种体系,其中List,Set,Queue继承自Collection接口,Map为独立接口
- Set的实现类有:HashSet,LinkedHashSet,TreeSet...
- List下有ArrayList,Vector,LinkedList...
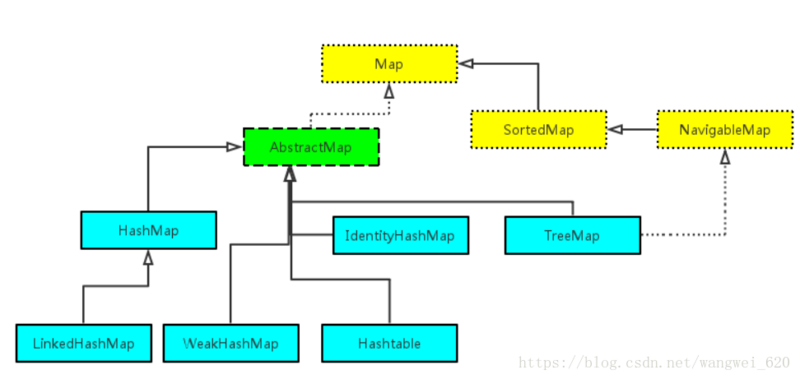
- Map下有Hashtable,LinkedHashMap,HashMap,TreeMap...
| list | 有序,可重复 | ArrayList:数组,查询快,增删慢。线程不安全. Vector:数组,查询快,增删慢。线程安全. LinkedList:链表,查询慢,增删快。线程不安全 |
| set | 无序(不严谨),唯一 | HashSet:无序,唯一,哈希表实现,通过hashCode()和equals()保证唯一。 LinkedHashSet:继承自hashset,底层是链表和哈希表。(FIFO插入有序,唯一) TreeSet:底层是红黑树。(唯一,有序) |
| map | KV形式的键值对 | TreeMap:有序,不是线程安全的。 HashMap:无序,不是线程安全的,HashMap允许null值(key和value都允许) HashTable:无序,线程安全的,不允许null值, |
2. Set
Set 接口继承Collection,用于存储不含重复元素的集合。
HashSet
底层是哈希表,当插入元素时,HashSet会调用该对象的hashCode()方法得到hashCode,然后根据hashCode决定该对象在哈希表中的存储位置。 (这里有个问题,如果hashcode不是均匀分布的,而是集中在一个区域,极端情况下,hash表会变成链表)
HashSet去重原理:通过equals()方法比较,且其hashCode()方法返回值也相等。 (可以通过覆写hashCode和equals方法改变其去重规则,进行自定义去重)
TreeSet
TreeSet底层是红黑树;加入元素时,必须加入同类型的对象,否则会发生ClassCastException异常,因为TreeSet会调用集合元素的compareTo()方法来比较元素之间的大小关系(自然排序)。
compareTo()方法的返回值决定了顺序:
- -1 表示放在红黑树的左边,即逆序输出;
- 1 表示放在红黑树的右边,即顺序输出;
- 0 表示元素相同,仅存放第一个元素自然排序(treeset去重的原理);
其次,TreeSet也可以通过比较器排序。
LinkedHashSet
继承自HashSet,底层是链表和哈希表。
- 由链表保证元素有序(插入顺序)。
- 由哈希表保证元素唯一
TreeSet, LinkedHashSet and HashSet 的区别
- 都实现Set接口,不包含重复元素
- 都不是线程安全的,如果要使用线程安全可以Collections.synchronizedSet()
- TreeSet的主要功能用于排序
- LinkedHashSet的主要功能用于保证FIFO,即有序的集合(先进先出)
- HashSet只是通用的存储数据的集合
- 插入速度: HashSet>LinkHashSet>TreeSet(内部实现排序)
- HashSet不保证顺序,LinkHashSet保证FIFO(先进先出),TreeSet安装内部实现排序,也可以自定义排序规则
- HashSet和LinkHashSet允许null, (只能有一个null) 但TreeSet中插入null时会报NullPointerException
3. List
list的实现类有ArrayList,Vector,LinkedList...其中ArrayList和Vector很相似,均是以数组作为底层实现,不同之处在于Vector是线程安全的。
ArrayList
ArrayList基于数组实现,不是线程安全的,内部维护了一个可变长的对象数组,集合内所有元素存储于这个数组中,并实现该数组长度的动态伸缩。
ArrayList使用数组拷贝来实现指定位置的插入和删除。
LinkedList
LinkedList内部以链表的形式来保存元素,因此随机访问集合时性能较差,但插入,删除元素时性能较好。
LinkedList不仅实现了List接口,还实现了Deque接口,可以被当成双端队列来使用,即可被当成“栈”来使用,也可以当成队列使用。
ArrayList 和LinkedList比较
- 两者都是List接口的实现类,都不是线程安全。List的另外一个实现类vector是线程安全的。
- ArrayList是基于动态数组的数据结构,而LinkedList是基于链表的数据结构。
- 对于随机访问get和set(查询操作),ArrayList要优于LinkedList.(LinkedList要移动指针)
- 对于增删操作(add和remove),LinkedList优于ArrayList。
4. Map
Map集合用于保存映射关系的数据,Map集合中保存了两组值,一组是 key, 一组是 value。
Map的key不能重复。
key和value之间存在单向一对一的关系, 通过key,能找到唯一确定的value。
Map将key和value封装至一个叫做Entry的对象中,Map中存储的元素实际是Entry。只有在keySet()和values()方法被调用时,Map才会将keySet和values对象实例化。
HashMap
key 是通过hash表来存储,value是通过链表来存储。
HashMap将Entry对象存储在一个数组中,并通过哈希表来实现对Entry的快速访问。 (通过key的哈希值计算Entry在数组中的index,以此访问value) (拉链法,解决hash碰撞)
HashTable
几乎和HashMap一样,都是通过数组存储Entry,以key的哈希值计算Entry在数组中的index,用拉链法解决哈希冲突。二者最大的不同在于, Hashtable是线程安全的,其提供的方法几乎都是同步的。
ConcurrentHashMap
ConcurrentHashMap是HashMap的线程安全版,提供比Hashtable更高效的并发性能。
Hashtable 在进行读写操作时会锁住整个Entry数组,这就导致数据越多性能越差。
ConcurrentHashMap使用分离锁的思路解决并发性能,其将 Entry数组拆分至16个Segment中,以哈希算法决定Entry应该存储在哪个Segment。这样就可以实现在写操作时只对一个Segment 加锁,大幅提升了并发写的性能。
在进行读操作时,ConcurrentHashMap在绝大部分情况下都不需要加锁,其Entry中的value是volatile的,这保证了value被修改时的线程可见性,无需加锁便能实现线程安全的读操作。
ConcurrentHashMap它不能保证读操作的绝对一致性。ConcurrentHashMap保证读操作能获取到已存在Entry的value的最新值,同时也能保证读操作可获取到已完成的写操作的内容,但如果写操作是在创建一个新的Entry,那么在写操作没有完成时,读操作是有可能获取不到这个Entry的。
HashMap和HashTable,ConcurrentHashMap的区别
- 三者在数据存储层面的机制原理基本一致
- HashMap不是线程安全的
- Hashtable是线程安全的,能保证绝对的数据一致性
- ConcurrentHashMap 也是线程安全的,使用分离锁和volatile等方法极大地提升了读写性能,同时也能保证在绝大部分情况下的数据一致性。但其不能保证绝对的数据一致性,在一个线程向Map中加入Entry的操作没有完全完成之前,其他线程有可能读不到新加入的Entry
- HashTable不允许使用null作为key和value,如果放入null将引发NullPointerException异常,但HashMap可以使用null作为key或value(只能有一个key为null,可以多个value为null)。
- 如果在遍历的同时,修改HashTable的大小,容易应发异常。可以用代替,ConcurrentHashMap是HashMap的线程安全版,提供比Hashtable更高效的并发性能
参考资料:
JAVA集合框架中的常用集合及其特点、适用场景、实现原理简介
java集合框架总结以及源码分析正文到此结束
- 本文标签: 源码 UI list queue ConcurrentHashMap java 安装 value 删除 HashTable HashSet map key http HashMap 并发 安全 Collections src 一致性 哈希算法 线程 实例 同步 id synchronized 遍历 总结 Java集合 equals https CTO 锁 Collection ArrayList tab 数据 volatile IO LinkedList
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

